- The paper shows that native Czech speakers nearly failed to distinguish between AI and human poetry, with accuracy around 45.8%.
- The experiment reveals an authorship bias where poems perceived as AI-authored received lower aesthetic scores despite comparable textual quality.
- Results indicate that AI can effectively mimic stylistic features of both modern and nonsense Czech poetry, challenging traditional notions of creative authorship.
Reception and Evaluation of AI- and Human-Authored Czech Poetry
Experimental Framework and Rationale
This study investigates the perceptual indistinguishability and aesthetic evaluation of AI-generated versus human-authored poetry in Czech—a morphologically complex, low-resource language for LLM training. The experiment utilized 32 critical poems, each forming human/AI-authored pairs, sourced from modern and nonsense Czech poetry. AI continuations employed GPT-4.5 Preview in chat mode, prompted as a proficient Czech poet, with no post-editing, thus simulating minimal-effort online content generation as expected in current digital ecosystems.
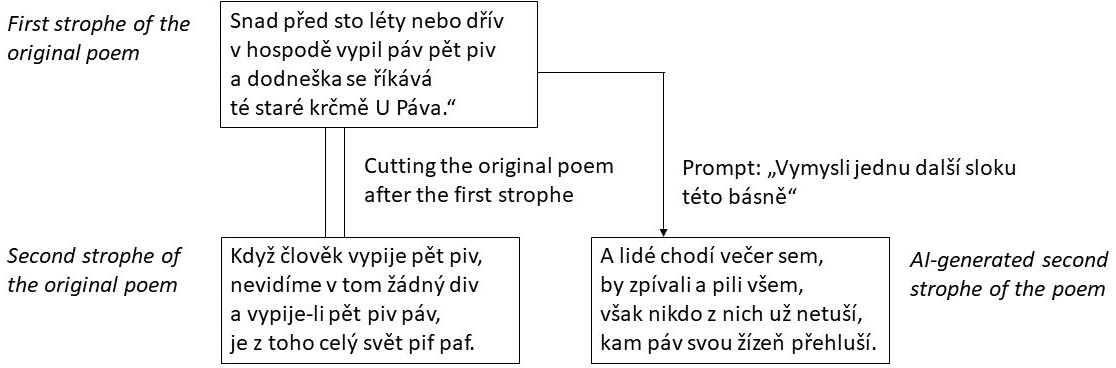
Figure 1: A scheme of creating the experiment materials.
Participants (N=126) were native Czech speakers, covering a demographic spread without overrepresentation of literary professionals. Each participant rated 16 poems on authorship (human/AI), confidence, and several evaluative scales (liking, rhyme, playfulness, imaginativeness, sense-making, seriousness).
Participants performed near chance in identifying poem authorship, with an overall accuracy of 45.8% (CI: 43.3–48.3%). Recognition was marginally better for nonsense poetry (51.4%) than modern poetry (40.2%). The logistic regression confirmed poem type (nonsense vs. modern) and human authorship as significant predictors of correct classification (p=.045 and p=.019, respectively), with participants more likely to correctly recognize human-poems than AI-generated ones. No significant effects emerged from demographic variables or participants' familiarity and engagement with poetry, indicating that domain expertise or exposure does not enhance authorship discrimination.
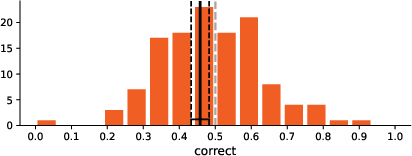
Figure 2: Distribution of correctness rates across participants.
Crucially, higher liking and perceived seriousness negatively correlated with correct identification, while perceived playfulness positively correlated. Confidence ratings were non-informative—self-reported confidence did not predict actual accuracy.
Authorship Bias in Aesthetic Judgment
A systematic bias was observed in aesthetic judgments dependent on perceived authorship. Poems judged as AI-authored received lower aesthetic scores, regardless of true authorship. In contrast, when actual authorship was considered, AI-generated Czech poems were rated equally or sometimes more favorably than human-authored poems across several attributes, including overall liking, imaginativeness, and sense-making.
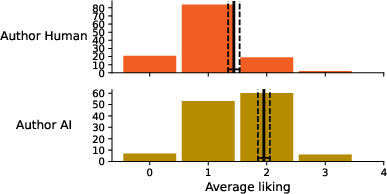
Figure 3: Average liking according to poem authorship.
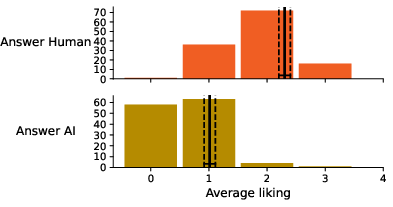
Figure 4: Average liking according to perceived poem authorship.
The bias extended to imaginativeness and sense-making metrics: participants rated poems as more imaginative and meaningful when believed to be human-authored, independently of actual provenance.
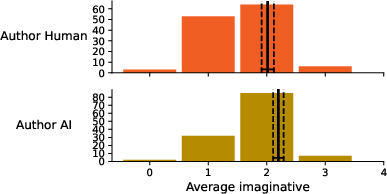
Figure 5: Average imaginativeness according to poem authorship.
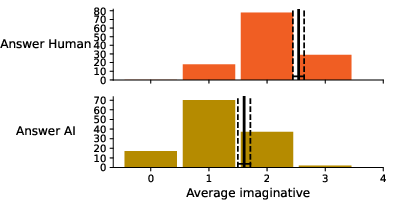
Figure 6: Average imaginativeness according to perceived poem authorship.
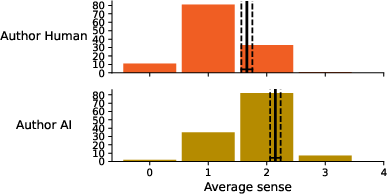
Figure 7: Average making sense according to poem authorship.
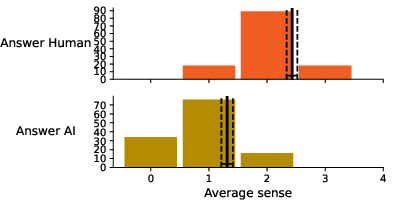
Figure 8: Average making sense according to perceived poem authorship.
Comparative Genre Analysis: Modern vs. Nonsense Poetry
AI mimicked the stylistic attributes of nonsense poetry with notable fidelity, as assessed by playfulness and imaginativeness. Playfulness scores for AI-authored nonsense poems approached human-authored counterparts (AI M=2.40, CI: 2.29–2.50; Human M=2.56, CI: 2.44–2.68), matching theoretical expectations for the genre. Imaginativeness showed parity across modern and nonsense genres, with AI modern poems even rated somewhat more imaginative than human equivalents.
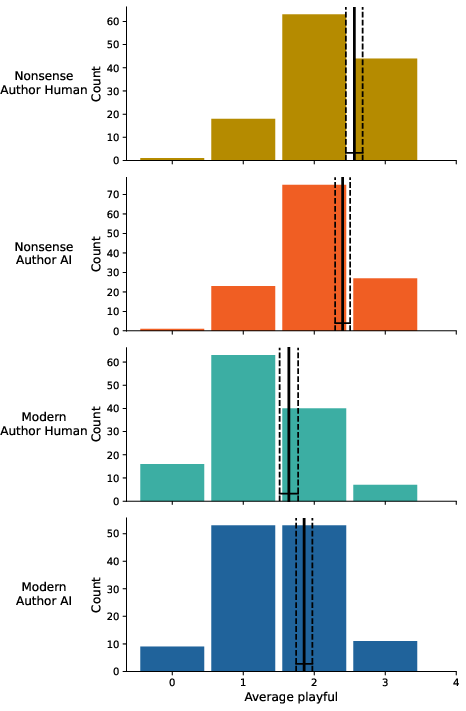
Figure 9: Average playful according to poem authorship.
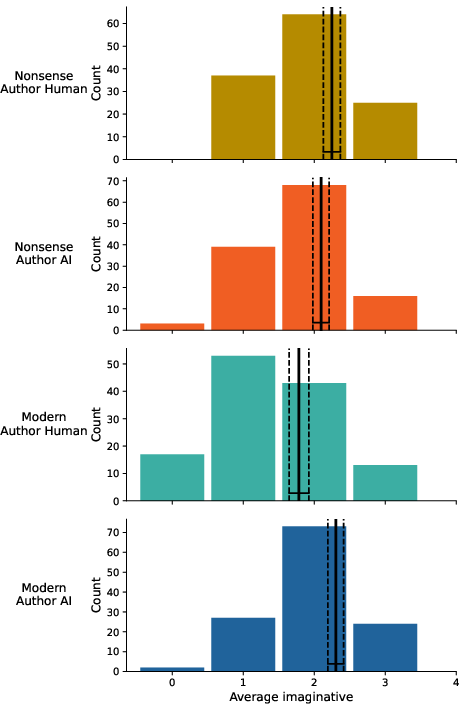
Figure 10: Average imaginative according to poem authorship.
However, the making-sense and seriousness scales, theoretically presumed to distinguish modern from nonsense poetry, did not yield strong genre separation in human-authored material, but AI nonsense poems were rated lower for sense-making and seriousness (AI nonsense M=1.80, CI: 1.69–1.92; Human nonsense M=1.71, CI: 1.59–1.83).
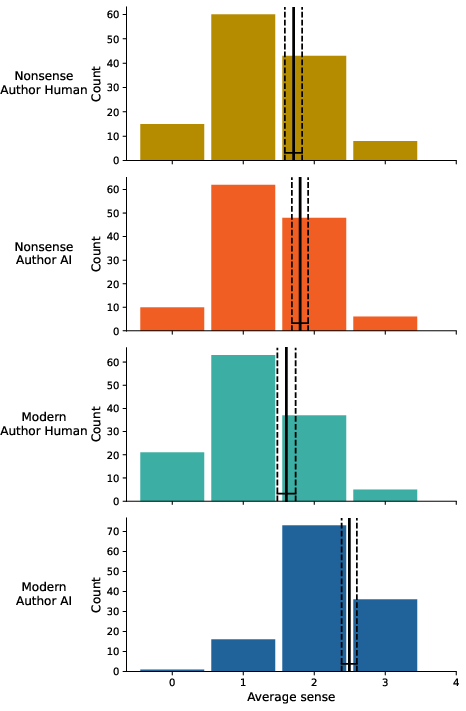
Figure 11: Average making sense according to poem authorship.
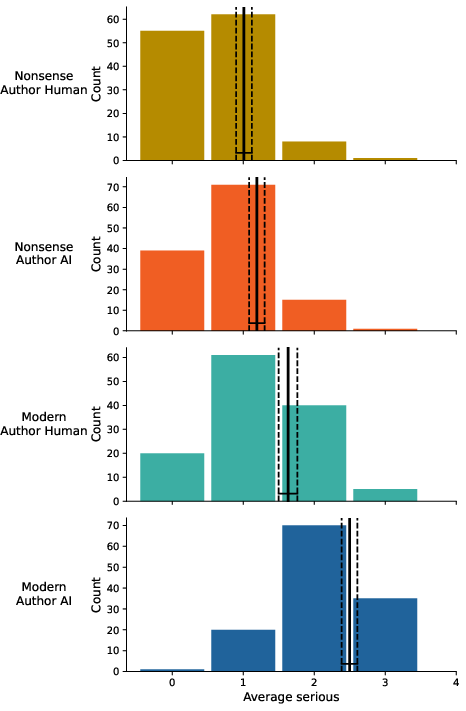
Figure 12: Average serious according to poem authorship.
Rhyme analysis confirmed the model's capacity to produce rhyming Czech poetry when prompted by rhyming human precedents, achieving comparable ratings to human nonsense poems.
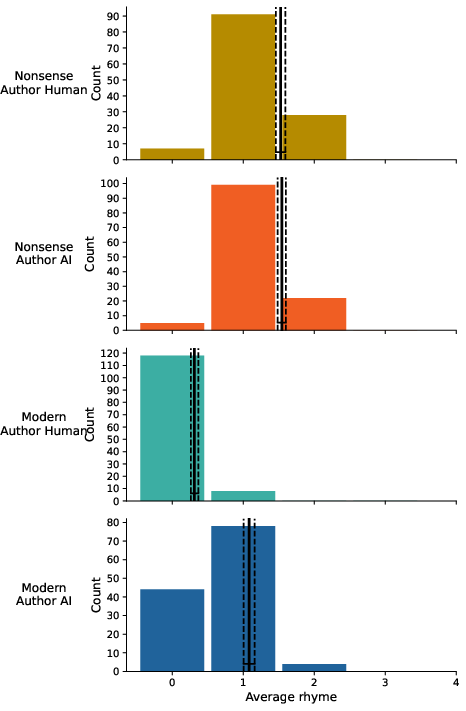
Figure 13: average rhyme according to poem authorship.
Implications and Theoretical Reflections
The empirical indistinguishability of AI-generated Czech poetry demonstrates LLM capacity for creative production in morphologically rich, low-resource languages, contrary to expectations based on training data bias (2511.21629).
Authorship bias in evaluation suggests an entrenched cognitive linkage between perceived authorship and aesthetic valuation—a phenomenon echoing Barthes' conceptualization of the reader's centrality in meaning-making, yet contradicting his hypothetical dismissal of the author's role. The directionality of this bias (whether attribution influences liking or vice versa) remains unresolved, with evidence pointing toward a feedback loop where negative evaluation and presumed artificiality reinforce each other.
The absence of a correlation between literary background and recognition accuracy implies that stylometric sophistication or professional expertise do not suffice to distinguish AI-generated poetry at current LLM capability levels. This finding has both epistemic and practical consequences for literary criticism and authorship verification processes in digital publishing.
Genre-wise, AI successfully simulates both modern and nonsense Czech poetry, although modern poetry presents less challenge, aligning with findings in other languages ([PorterMachery2024], [HITSUWARI2023107502]. The experiment also highlights challenges for interpretability and valuation in genres predicated upon linguistic play and ambiguity.
The results have theoretical implications for the study of authorship, perception, and digital art, challenging the assumption that authorial provenance can be rendered moot in reception. Practically, they forecast probable confusion and author-centric bias in literary discourse as AI-written poetry proliferates.
Conclusion
This experiment affirms that state-of-the-art LLMs are proficient in producing Czech poetry that is perceptually and aesthetically competitive with human-authored texts, reinforcing the urgency for further inquiry in underrepresented languages. The findings show a persistent authorship bias in aesthetic judgment, independent of textual quality, and a lack of improved discrimination even among poetry aficionados. The implications concern not only the practical future of literary creation and critique in the AI era, but also deepen theoretical debates regarding the place and perception of authorship in literary reception. Future studies should extend cross-linguistic evaluation and probe the causality and remediation of authorship bias in aesthetic contexts.