- The paper demonstrates an LLM-driven system that automatically generates and debugs MATPOWER scripts to lower entry barriers in power grid analysis.
- It integrates retrieval-augmented generation, asynchronous MCP interfacing, and multi-tiered error correction (static, dynamic, semantic) to boost script accuracy.
- Experimental ablation studies show up to a 30% performance drop without semantic validation, underlining the importance of structured documentation.
Automatic Code Generation and Agentic Error Correction for Power Grid Static Analysis
System Overview and Motivation
This paper addresses the automation of power grid static analysis via LLM agents capable of generating and debugging MATPOWER scripts directly from natural language prompts. The proposed agent integrates retrieval-augmented generation (RAG), sophisticated error-correction mechanisms, and a Model Context Protocol (MCP) interface to streamline the pipeline from user intent to executable MATLAB code. The motivation lies in the high entry barrier for scripting industrial-grade simulations and the considerable tedium and error-proneness associated with manual authoring and debugging of such workflows, especially in complex contingency and reliability analysis scenarios. Existing commercial solutions require significant scripting expertise, while the proliferation of agentic LLMs enables delegation of these tasks to automated pipelines.
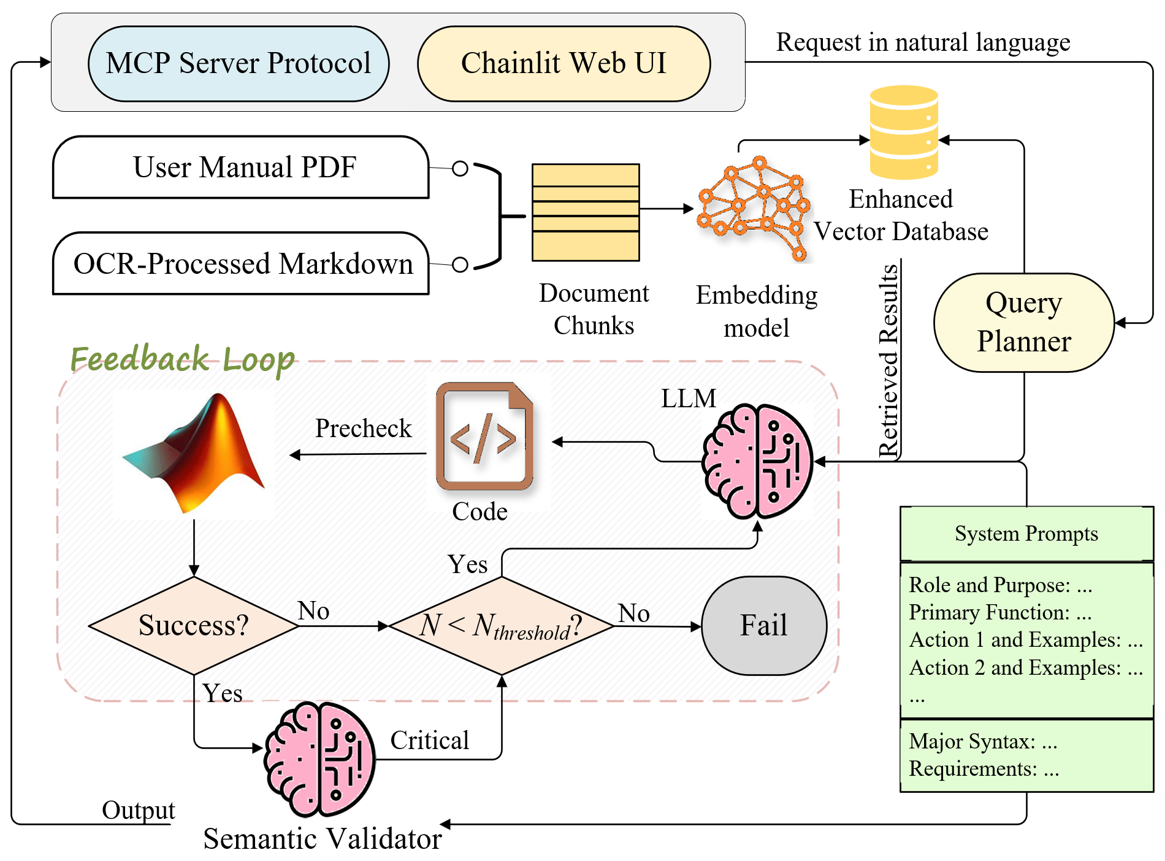
Figure 1: Overall system architecture incorporating RAG, MCP, and multi-stage error correction.
Architectural Design
Retrieval-Augmented Generation and Vector Database Construction
A core challenge is enabling LLM agents to accurately generate domain-specific, syntactically sound MATLAB scripts that interact with the MATPOWER toolbox without hallucination or semantic drift. The framework resolves this by deploying a RAG pipeline built on an enhanced vector database constructed from multi-modal documentation. Specifically, DeepSeek-OCR is used for preprocessing the MATPOWER user manual, converting complex layout-rich PDFs into structured Markdown, preserving both semantic granularity and row/column logic essential for API comprehension.


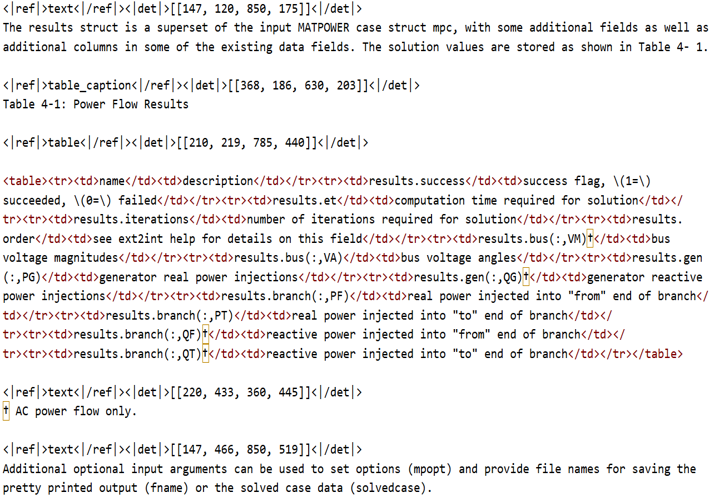
Figure 2: Raw PDF table input before DeepSeek-OCR transformation.
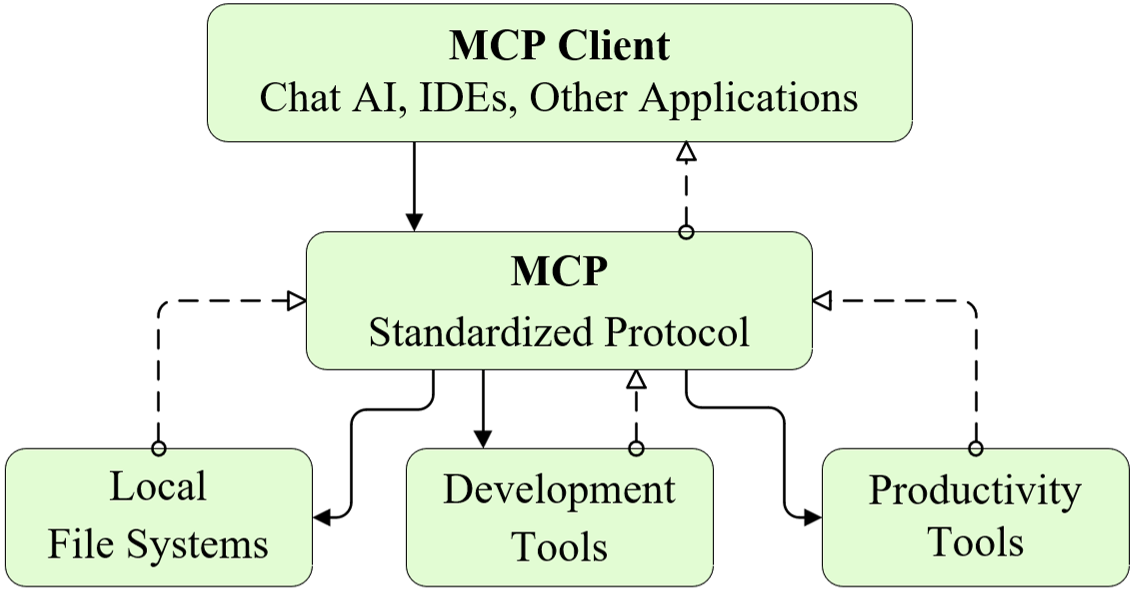
Figure 3: Model Context Protocol (MCP) enables standardized integration with AI agents and external toolchains.
Text segments from both OCR-enhanced and raw PDFs are embedded into a high-dimensional space using pretrained transformer models and indexed using FAISS. Retrieval is sub-request-driven, where user intents decompose into keywords to query relevant documentation chunks, providing the LLM with authoritative grounded context before code generation.
Model Context Protocol and Execution Pipeline
The MATPOWER agent is encapsulated as an MCP server for seamless invocation by external ecosystems. The MCP interface utilizes an asynchronous architecture combining Python subprocesses with explicit output protocols to prevent system blocking during MATLAB executions. Inter-process communication occurs via JSON packets instrumented with unique identifiers for robust segregation from verbose MATLAB logs.

Figure 4: MCP architecture detailing asynchronous, modular process flow and data encapsulation.
MATPOWER agent workflow is structured in layers: high-level role and language constraints, injected context/top-k documentation, and user/task instruction/few-shot exemplars. Code is generated and dispatched to the MATLAB engine; execution logs, warnings, and error stacks are captured for downstream analysis.
Automated Error Correction: Static, Dynamic, Semantic
The framework introduces a tripartite error correction stack:
- Static Pre-Check: Prior to execution, scripts are statically analyzed using domain heuristics—fuzzy matching for typos and automated injection of boilerplate (e.g.,
define_constants;)—to eliminate elementary errors.
- Dynamic Feedback Loop: On runtime failure, execution traces are combined with contextual hints and the prior code state to generate detailed prompts for LLM-guided correction. This process iterates up to a preset threshold.
- Semantic Validator: An auxiliary LLM module compares final scripts to user requests post-execution. Semantically critical deviations trigger another correction pass; minor mismatches raise warnings but do not halt workflow.
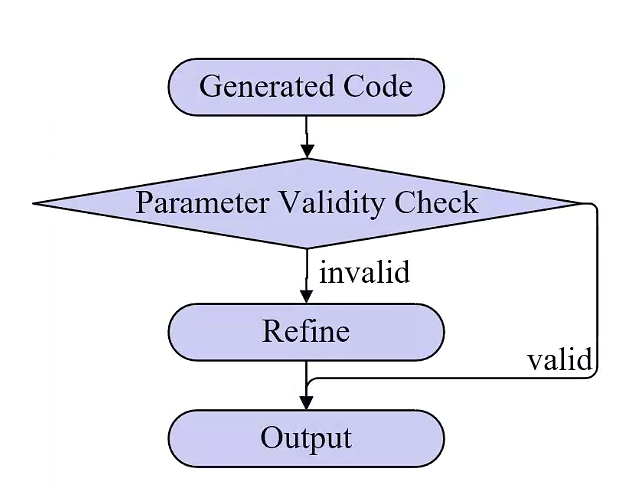
Figure 5: Static Pre-check module catches typographical and logic omissions before code execution.
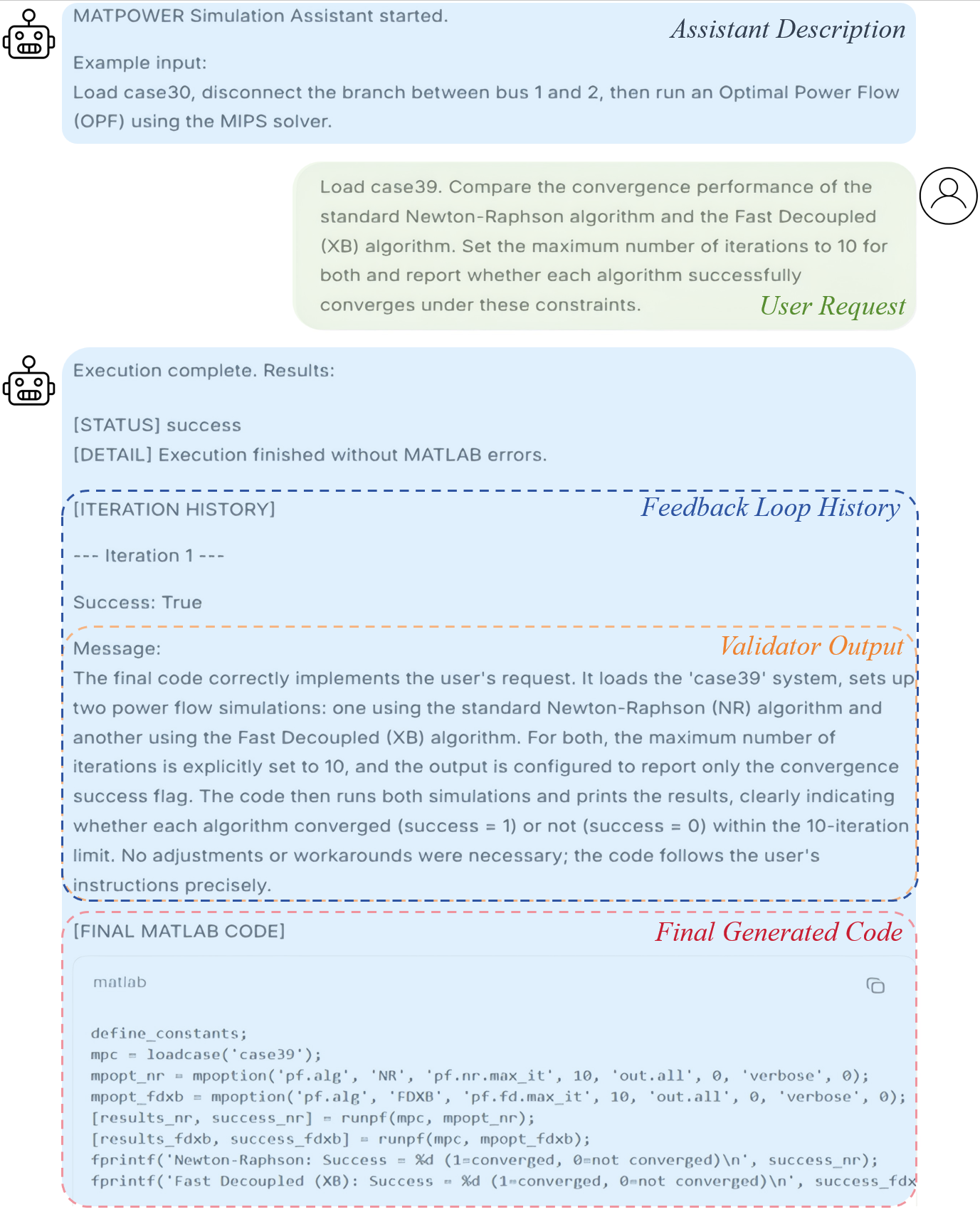
Figure 6: System output visualization with intermediate agent decision states for end-user auditability.
Empirical Evaluation
Benchmarking and Ablation Analysis
The system is validated across ten simulation tasks with systematically increasing logical complexity, ranging from standard power flows to multi-stage, synchronously manipulated optimization runs (e.g., constrained OPF and dynamic reconfiguration). Four main retrieval configurations (No RAG, OCR-Markdown only, PDF vector only, Enhanced Vector DB/RAG+) and multiple ablation settings (removing planner/validator/feedback components) are rigorously assessed.
The fidelity metric, Code Generation Semantic Generation Fidelity (CSGF), fuses execution success, logic audit, and iteration efficiency, while the Global Code Generation Accuracy (GCA) aggregates these outcomes.
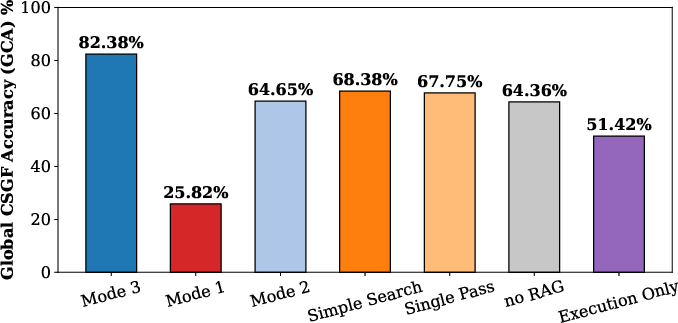
Figure 7: Overall system accuracy (GCA) across configurations, highlighting the performance gains with full-component Enhanced Vector DB (RAG+).
The full model (Enhanced Vector DB with all error-correction modules) achieves 82.38% GCA, a marked improvement over PDF-only (64.65%) and OCR-only strategies (~perfect on easy, 16% on hard). Structured documentation, rather than fragmented or unstructured text, is established as a key driver for high-fidelity code generation, especially for tasks with tangled logic or multi-entity state synchronization.
Ablating the semantic validator (Execution Only) leads to syntactically correct but semantically inconsistent outputs and a GCA collapse to 51.42%. Notably, more than 30% of such code is executable yet fails user intent—a direct quantification of LLM hallucination when post-hoc validation is unavailable.
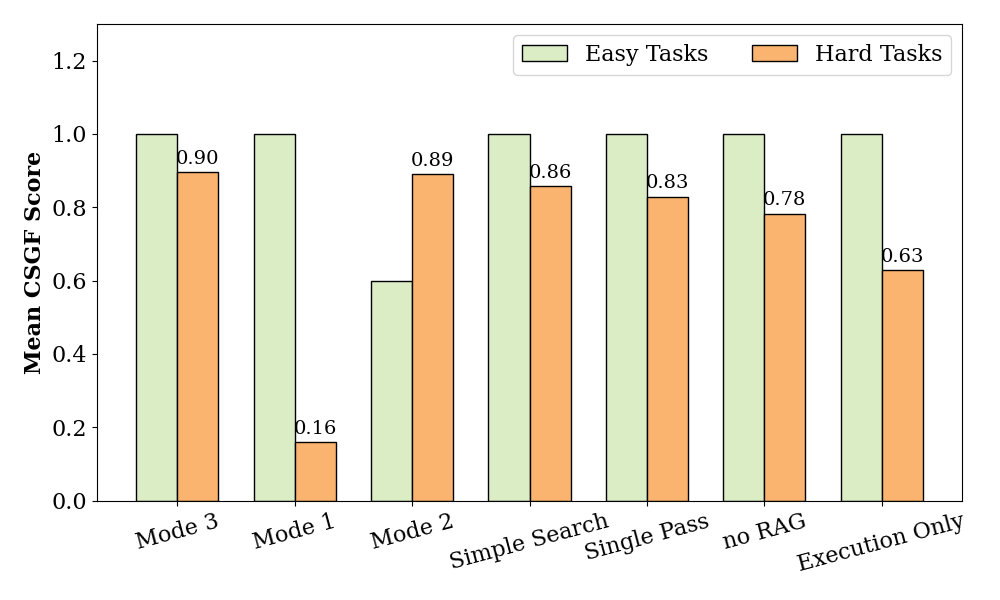
Figure 8: CSGF variance by task complexity, demonstrating severe degradation in agentic performance without enhanced vector retrieval for hard scenarios.
Practical and Theoretical Implications
The pipeline showcases agentic orchestration of complex simulation workflows in critical infrastructure domains, reducing required user expertise and interaction to a single natural language prompt. Error correction loops—both symbolic and semantic—substantially improve reliability and user trustworthiness, supporting deployment in operationally sensitive environments. The documented improvement in code fidelity attributable to OCR-enhanced, structured knowledge bases offers a generalizable paradigm for domain-specific agentic automation, suggesting that agentic LLMs’ effectiveness is ultimately bounded by retrieval quality and post-generation semantic auditing.
On a theoretical level, this work quantifies the role of structured technical documentation and agentic feedback for reducing hallucination and improving program synthesis in LLM-augmented automation. The three-tiered error correction pipeline further characterizes failure modalities in agentic workflows and proposes solutions for their remediation.
Conclusion
This research systematically addresses code synthesis fidelity and error correction for LLM-driven agentic workflows in power grid static analysis. By integrating RAG on structured, OCR-enhanced documentation, asynchronous MCP interfacing, and multi-tiered error correction, the system attains robust performance in both simple and complex analysis tasks. These contributions offer a foundation for advanced agentic automation in infrastructure simulation, and future directions include extending this framework to other toolboxes and simulation domains.