- The paper introduces a self-evolving power flow agent that translates natural language intents into verifiable simulation actions.
- It demonstrates robust retrieval-augmented performance with 100% pass rates in key benchmark scenarios and dynamic error repair.
- The agent's modular design ensures reproducible, traceable workflows and continuous improvement without retraining.
PFAgent: A Tractable and Self-Evolving Power-Flow Agent for Interactive Grid Analysis
Agent Architecture and Design Paradigms
PFAgent establishes a comprehensive pipeline for translating natural-language power system study intents into verifiable simulator actions and structured, machine-checkable outputs. The agent’s modular architecture decomposes the workflow into distinct stages: intent parsing, knowledge retrieval, tool execution, and structured reporting. This tractable structuring localizes failure management and facilitates stateful multi-turn interaction, with persistent cumulative modifications and state continuity.
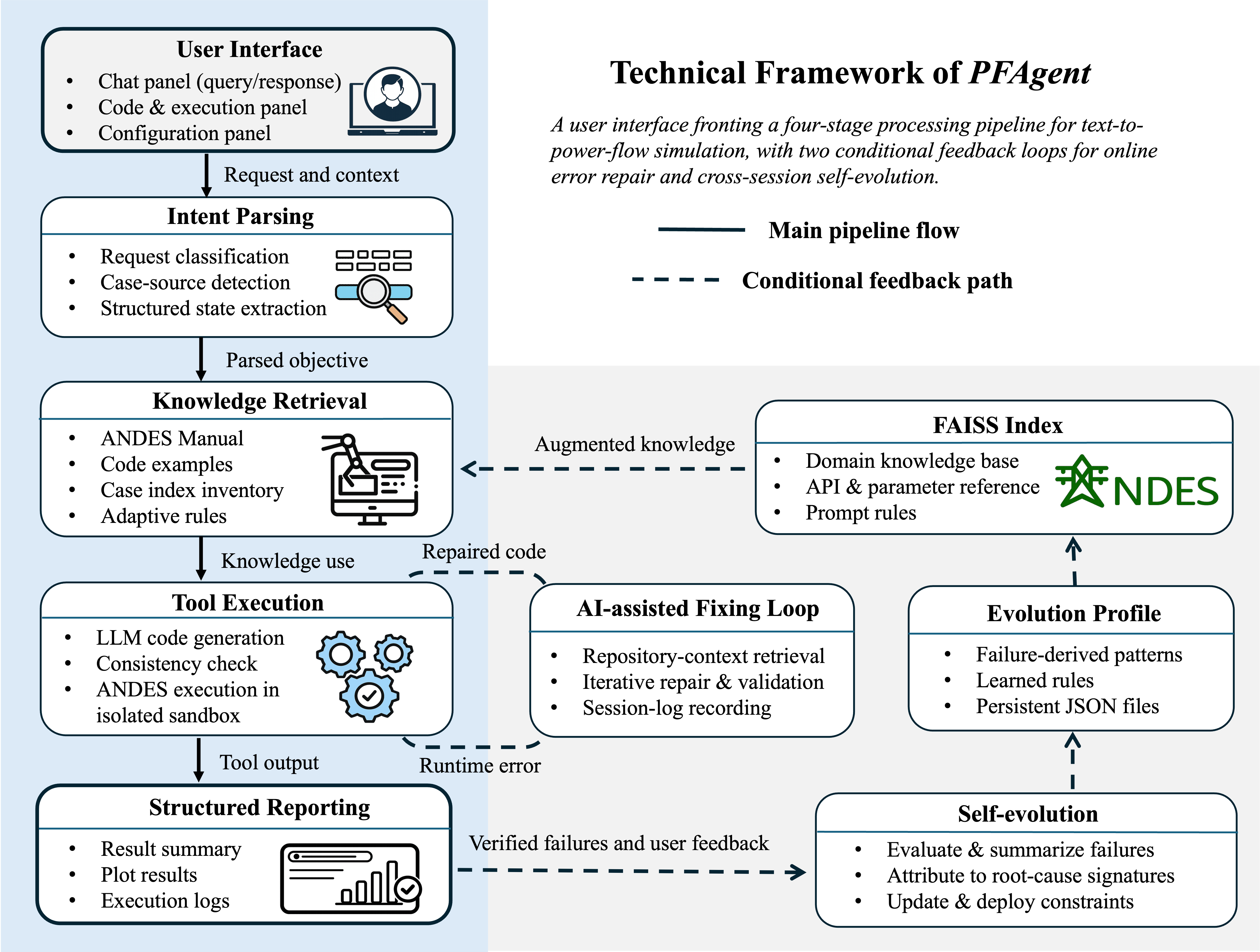
Figure 1: Technical framework of PFAgent: the left column (blue) is the session query pipeline; the right column (gray) contains the feedback loops for error repair and self-evolution.
The agent’s design principles address several domain-specific requirements:
- Tractability: Each operational stage exposes structured outputs that can be inspected, corrected, or rerun independently, minimizing systemic propagation of errors.
- Interactivity: Conversational modifications persist unless explicitly overridden, with real-time access to code, logs, and repairs, tightly integrated in a user-centric interface.
- Reproducibility: Every output is backed by executable scripts, ensuring deterministic re-execution and audit trails.
- Self-Evolution: The agent is designed to improve continuously, using attributed and verified failures to update prompt rules, parser vocabularies, and constraint packs on-the-fly.
Self-Evolution Mechanism and AI-Assisted Error Repair
The core innovation lies in the closed-loop self-evolution mechanism. The agent utilizes both pre-deployment benchmark failures and real-world user-sourced failures, attributing errors to a structured set of root-cause signatures encompassing prompt, execution, and human feedback patterns.
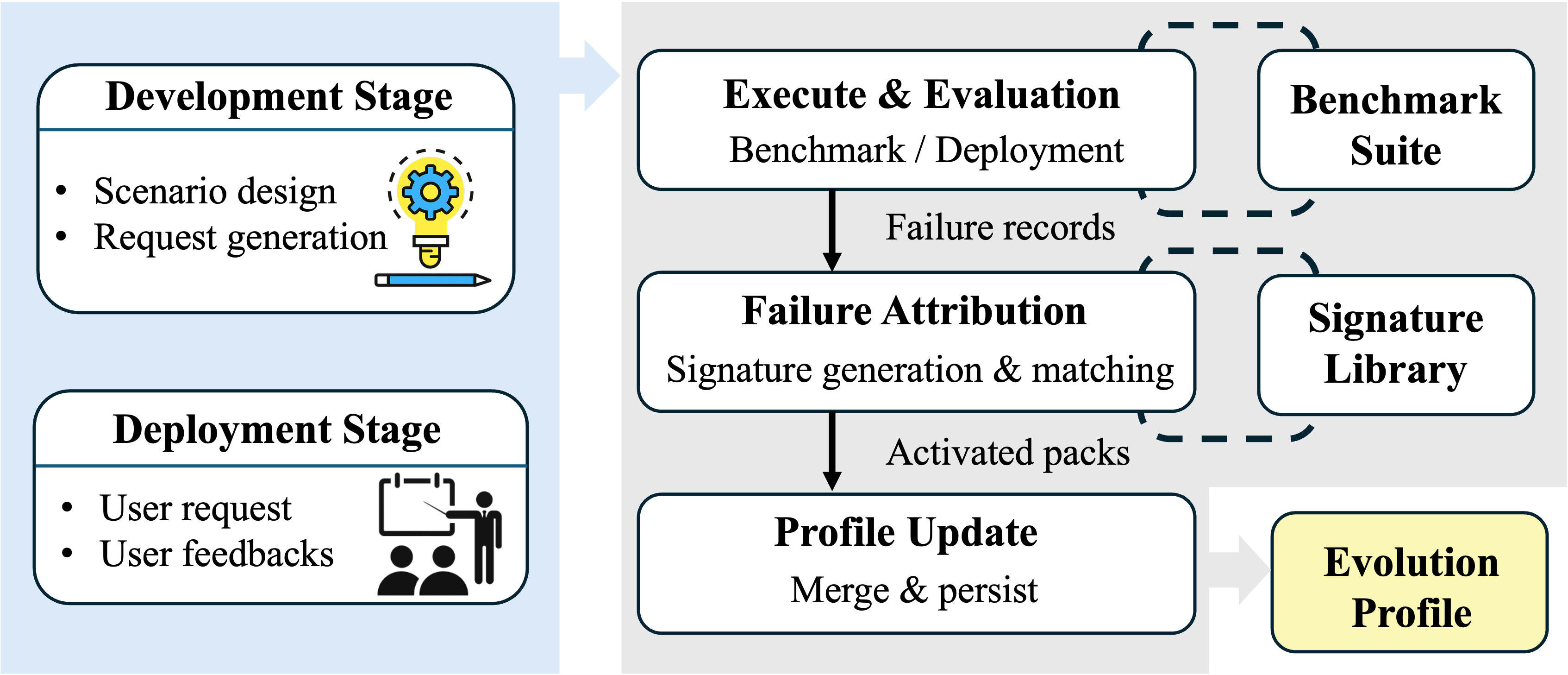
Figure 2: Self-evolution mechanism allowing the agent to automatically update its evolution profile in response to verified failures in both benchmark and deployment phases.
Upon error detection, the agent’s AI-assisted fixing loop composes a comprehensive context bundle—including user query, failed code, error trace, ANDES case state, and retrieved repository-level documentation—and prompts a dedicated repair model. The result is an iterative repair-validation cycle that continues until semantic and executional correctness is satisfied or limits are reached. Successful or failed iterations are logged to the session for subsequent integration in the evolution profile.
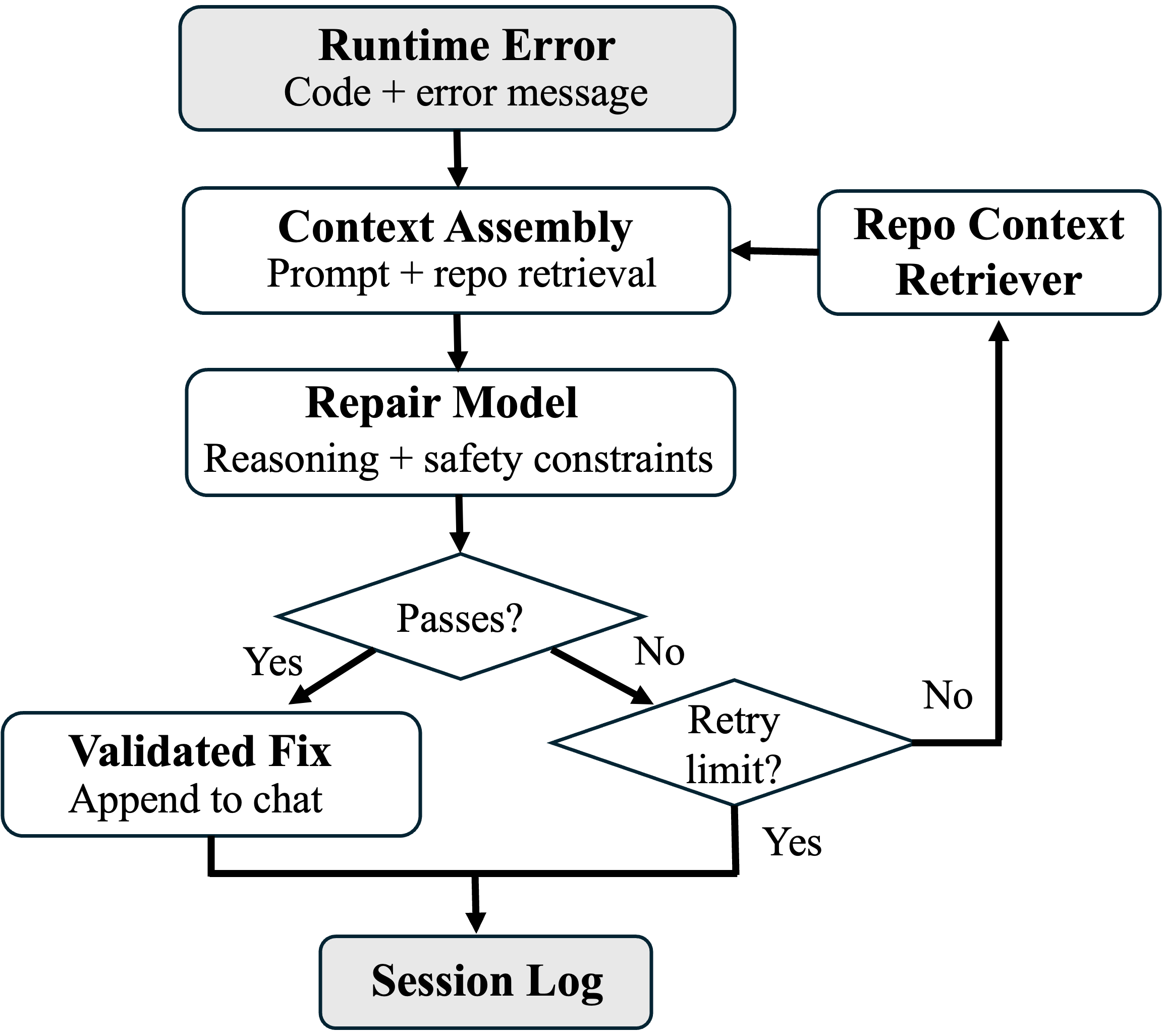
Figure 3: AI-assisted fixing loop that harnesses conversational context, code, and runtime errors for context-aware code repair and validation.
This dual-pathway feedback structure—session-local repair and cross-session evolutionary improvement—complements LLM grounding and mitigates the static-template limitations observed in prior agent frameworks.
User Interface and Pipeline Integration
The practical utility of PFAgent is manifested in a fully interactive, reproducible web interface that consolidates scenario configuration, conversational dialogue, code inspection, error handling, and result visualization.
Figure 4: User interface of PFAgent showing (a) configuration panels and (b) interactive chat panels for scenario initiation and result interpretation.
The design supports multi-stage queries with cumulative modifications typical in power engineering studies (e.g., baseline analysis, sequential load or topology changes, contingency responses).
Evaluation Metrics, Benchmarking, and Ablation
A rigorous, multi-dimensional evaluation framework is defined—each task is a multi-turn (three-step) scenario, with comprehensive scoring per turn for format, ANDES API grounding, continuity, runtime execution, semantic consistency, and artifact production. A passing turn requires full marks on all six dimensions, and an aggregated scenario pass necessitates completely passing all turns.
Four agent modes are benchmarked: Base LLM (no domain knowledge), Fine-tuned LLM, Retrieval-Augmented Generation (RAG), and Fine-tuned+RAG. This enables detailed ablation to isolate the contribution of domain-specific training and retrieval adaptation.
Numerical Results and Analysis
PFAgent was evaluated on two deterministic suites: an initial 100-scenario set for early development and an expanded 164-scenario set for evolved task coverage. Strong findings are reported:
- Retrieval-augmented modes (RAG and Fine-tuned+RAG) achieve 100% scenario and turn-level pass rates, with perfect numerical and semantic scores across all dimensions.
- Fine-tuned LLM alone yields 58% (100-scenario) and 35% (164-scenario) scenario pass rates, with marked degradation across sequential turns due to limited continuity awareness and cumulative context retention.
- Base LLMs—absent retrieval and fine-tuning—fail completely on code execution and semantics, underscoring the necessity of domain adaptation.
- Fine-tuned+RAG recovers from 60.98% to 100% on the 164-scenario set after a single self-evolution prompt adjustment, with no model retraining required, i.e., failure attribution and constraint injection alone overcome grounding failures in API usage for contingency analysis.
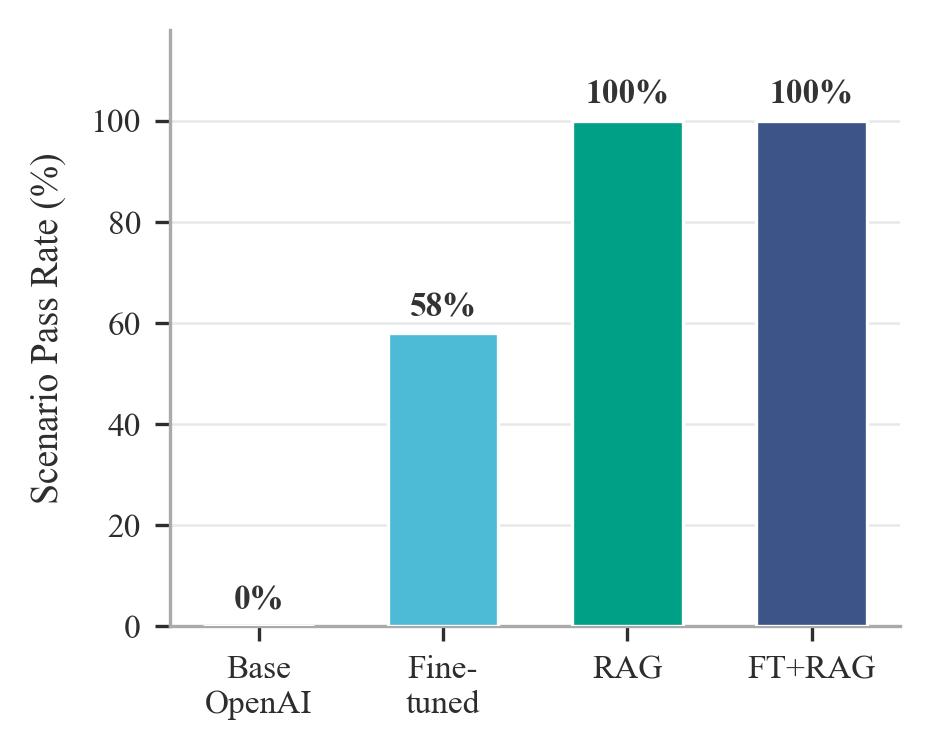
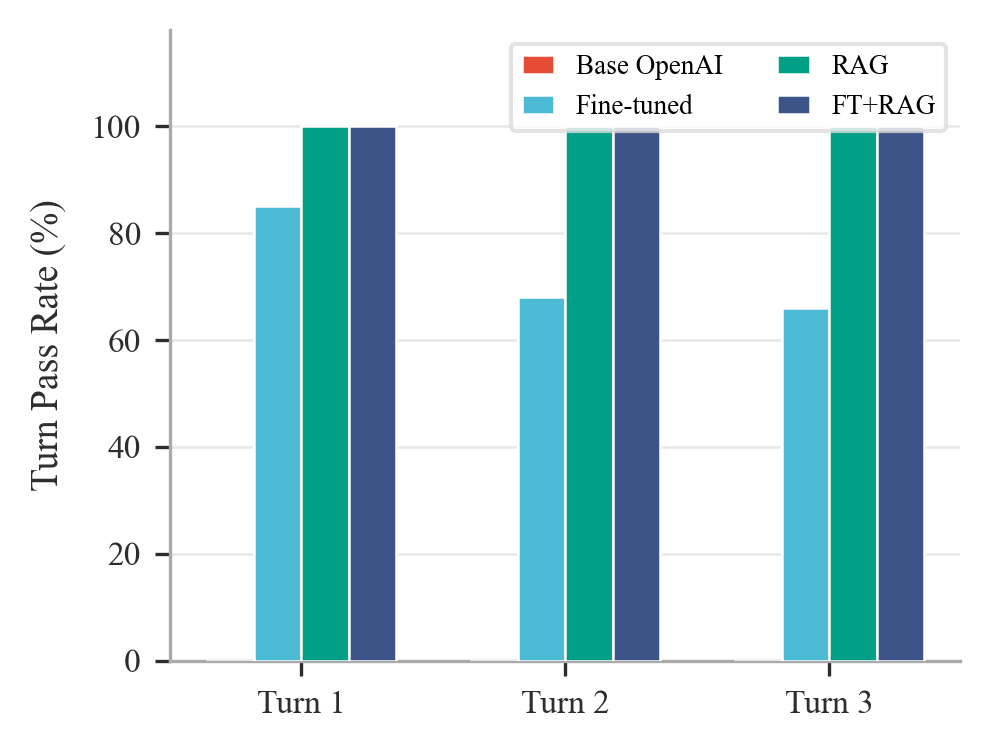
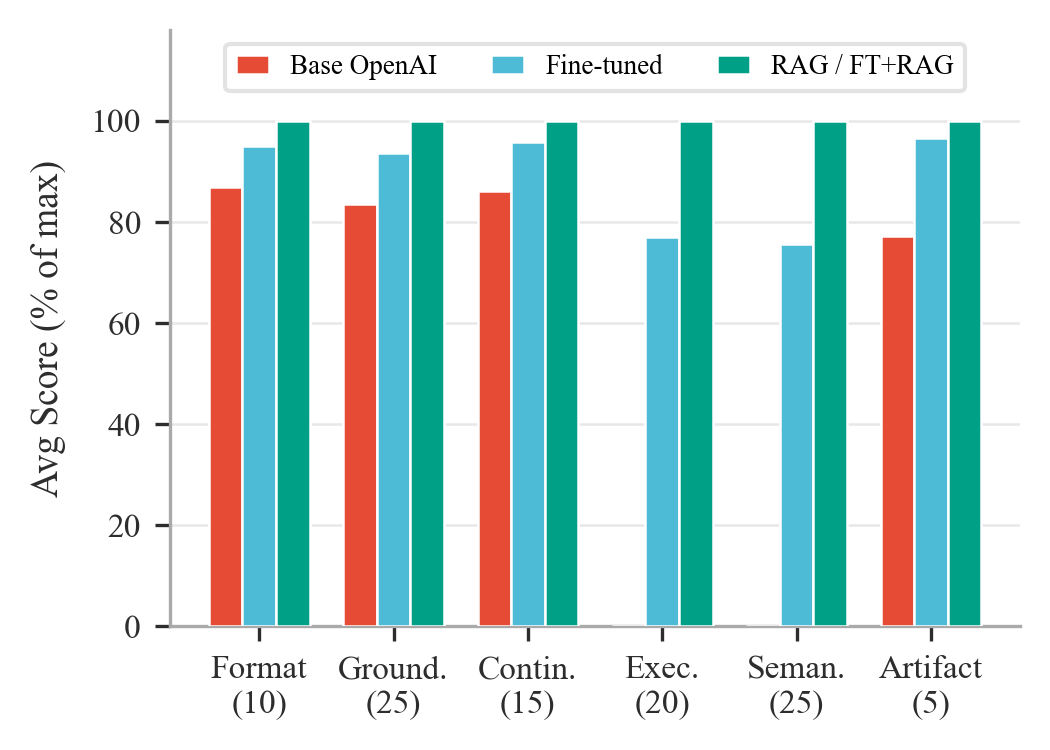
Figure 5: 100-scenario benchmark results—(a) scenario pass rate by agent mode, (b) per-turn pass rates, (c) detailed performance across evaluation dimensions.
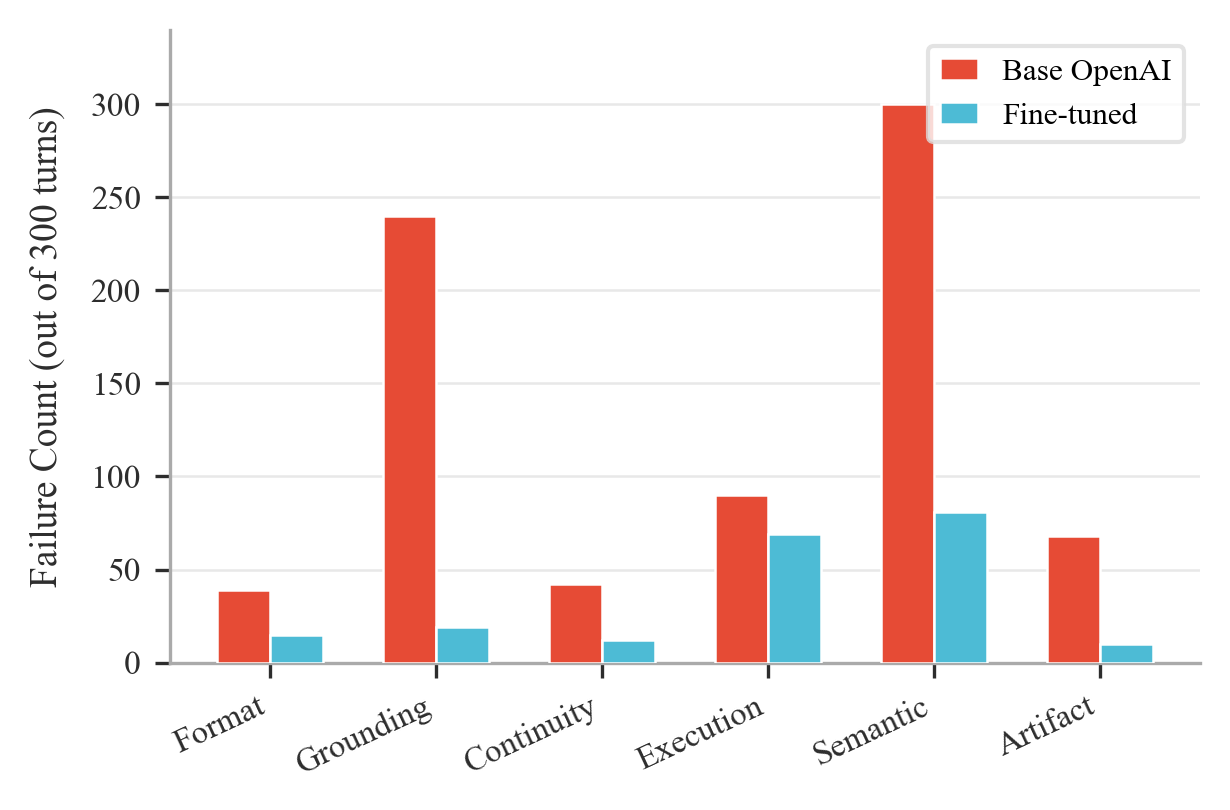
Figure 6: Failure-category distribution for non-retrieval modes (Base OpenAI and Fine-tuned) identifying dominant error sources.
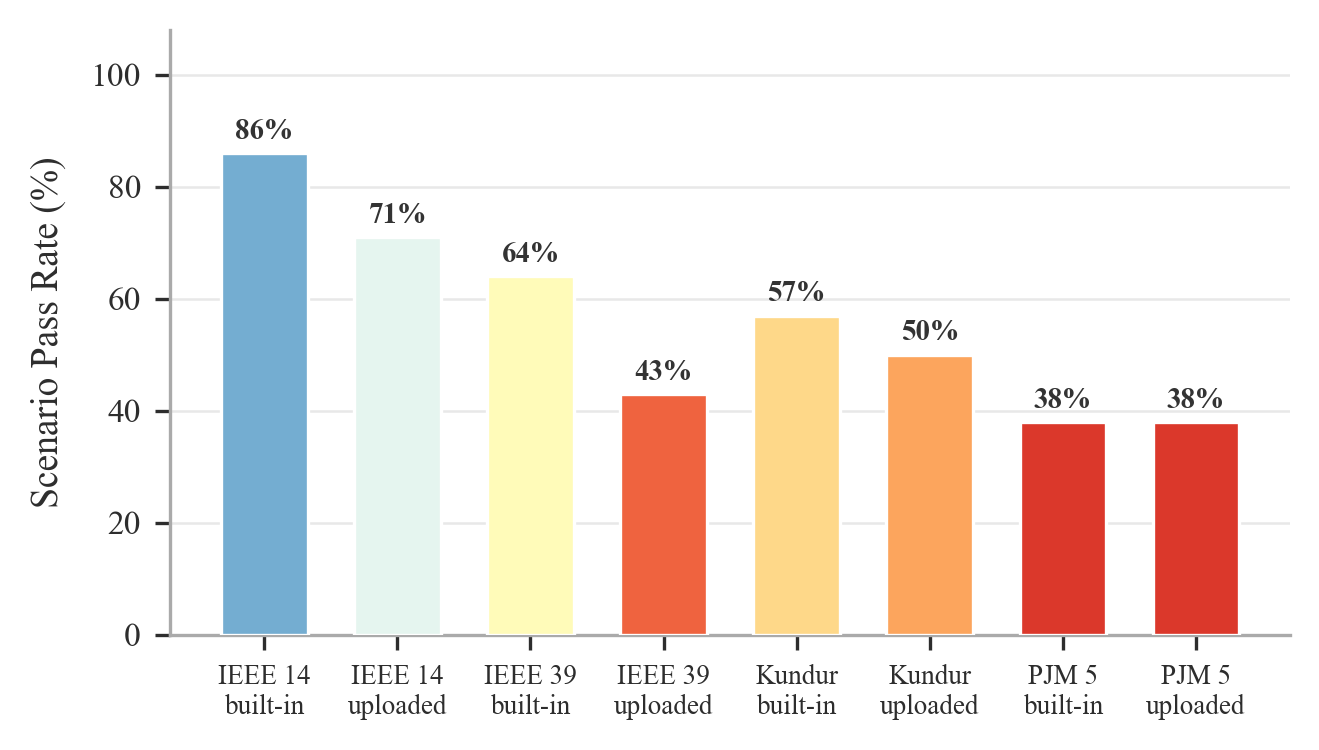
Figure 7: Family-level pass rate for Fine-tuned mode, with clear source-specific deficiencies, especially for user-uploaded cases.
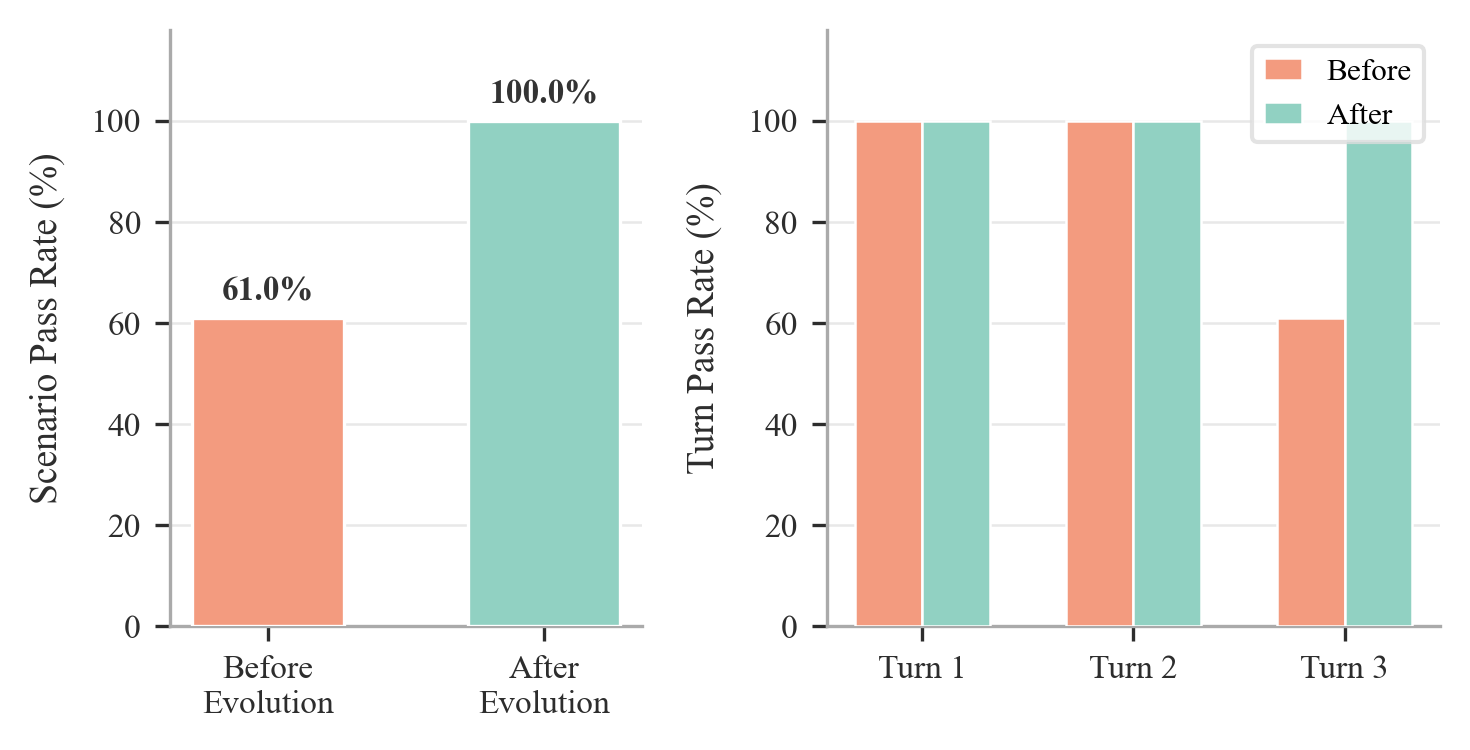
Figure 8: Pre- and post-self-evolution performance on the 164-scenario benchmark, demonstrating full recovery after targeted constraint updates.
Key insights include:
- Retrieval/prompt-engineering is the dominant factor, resolving execution, grounding, and context-persistence limitations present in fine-tuning alone.
- Retrieval granularity (window-level passage vs. sentence chunking) is critical to context-aware code generation.
- Multi-turn continuity and state persistence require explicit context injection; LLM memory alone is inadequate for complex procedural modifications.
- Self-evolution via verified failure-driven prompt updates provides robust continual agent improvement without model retraining.
Theoretical and Practical Implications
PFAgent demonstrates that tractable, execution-grounded, and self-evolving agents are feasible for domain-specific scientific simulation, provided that retrieval pipelines are domain-curated and prompt constraints are systematically maintained and updated in production. The approach circumvents the main limitations of static LLM prompting, manual error repair, and brittle code generation that have plagued earlier code-generation agents in power engineering and similar domains.
Practically, this model enables rapid, deterministic, and transparent study preparation, diagnosis, and reporting for power system analysis, reducing expert intervention in simulation scripting, debugging, and reproducibility management. The self-evolution design establishes a methodology for continuous post-deployment improvement, suggesting that human-in-the-loop feedback, coupled with granular failure-cause attribution and dynamic constraint systems, can alleviate the need for frequent LLM retraining as simulator APIs and workflows evolve.
Theoretically, PFAgent’s feedback-loop mechanisms, ablation findings, and benchmarking methodology provide a template for developing tractable, auditable, and improvable agent architectures in other scientific or technical simulation domains, where text-to-action reliability supersedes conversational fluency as the central metric.
Conclusion
PFAgent realizes a tractable, interactive, and self-evolving agent for power flow analysis on the ANDES platform, achieving robust automation of complex, stateful simulation workflows. Retrieval-augmented prompt engineering is identified as the primary enabler of high reliability, with the self-evolution mechanism closing the improvement loop through dynamic prompt constraint updates. These findings signal that LLM-powered agents for scientific simulation must be designed as modular, continuously-verifiable systems with explicit state, provenance, and constraint adaptation, not as static LLMs with black-box reasoning.
Future research will entail expanding PFAgent to optimal power flow, dynamic and stability studies, and mixed-simulator or hybrid agent deployments, with extended benchmarking and integration with end-to-end power system planning and operation workflows.
Reference: "PFAgent: A Tractable and Self-Evolving Power-Flow Agent for Interactive Grid Analysis" (2604.10846)

