- The paper establishes a multimodal pipeline for immersive volumetric video by synchronizing 39-camera capture and dynamic light field reconstruction.
- It employs spatio-temporal Gaussian splats with flow-guided initialization and joint calibration to achieve robust free-viewpoint rendering and high image fidelity.
- The study integrates real-time, training-free sound field synthesis validated by expert user studies, enhancing multisensory 6-DoF VR interactions.
A Multimodal Pipeline for Immersive Volumetric Video and 6-DoF VR: An Expert Summary
Overview and Motivation
The paper "Realizing Immersive Volumetric Video: A Multimodal Framework for 6-DoF VR Engagement" (2604.09473) establishes both a formal definition for Immersive Volumetric Videos (IVV) and the practical means to create high-fidelity, large-scale dynamic audiovisual experiences deployable in six-degrees-of-freedom (6-DoF) virtual and augmented reality. The work bridges persistent gaps in view synthesis, scene capture, and multimodal interaction, introducing a benchmark dataset (ImViD) and a novel, tightly integrated pipeline for spatiotemporally consistent audiovisual reconstruction.
Key technical contributions include a synchronized multi-camera and microphone capture strategy, a spatio-temporally aware light field reconstruction method leveraging Gaussian primitives, and a plug-and-play sound field synthesis model. The resulting platform supports robust free-viewpoint exploration with dynamic, multisensory content, a capability previously unavailable at this level of spatial, temporal, and sensory fidelity.
Capture System and the ImViD Benchmark Dataset
The study introduces a custom-built, mobile multi-camera platform incorporating 39 outward-facing GoPro units on a hemispherical rig capable of synchronized video and audio capture at 5K resolution and 60 FPS. This hardware supports both static and dynamically-moving acquisition strategies, enabling extensive coverage of both spatial and temporal scene evolution. Static image acquisition offers over 1,000 viewpoints for 360° backgrounds, while dynamic sequences cover large volumes through cart-based movement.
All devices synchronize at the millisecond level via world time codes. Calibration uses multi-level geometric registration and iterative manual refinement. The result is a dataset, ImViD, with seven diverse scenes (indoor and outdoor), each containing 1-5 minute synchronized audiovisual sequences exhibiting complex, realistic person-object interaction, intricate background evolution, and high ambient fidelity.
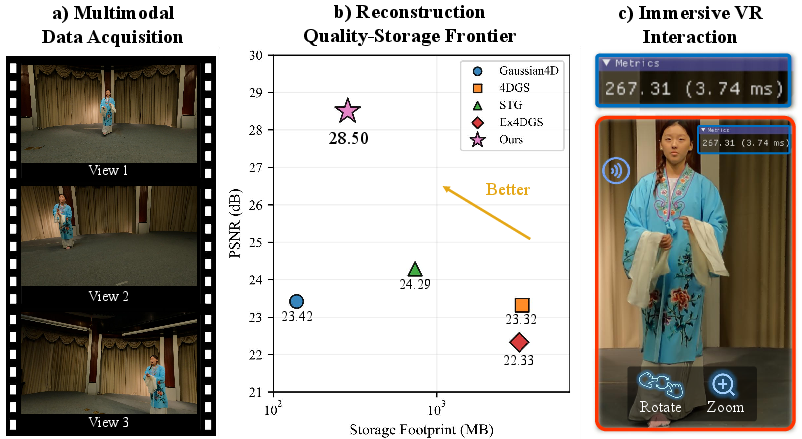
Figure 1: Modular pipeline: multimodal capture, state-of-the-art audiovisual field reconstruction, and seamless 6-DoF VR interaction for high-fidelity IVV construction.

Figure 2: ImViD dataset captures dynamic scenes with rich, calibrated, multi-view, and multi-modal data.
Figure 3: The custom capture rig supports both stationary and mobile strategies for high-res, high-frame-rate, 360° dynamic data.
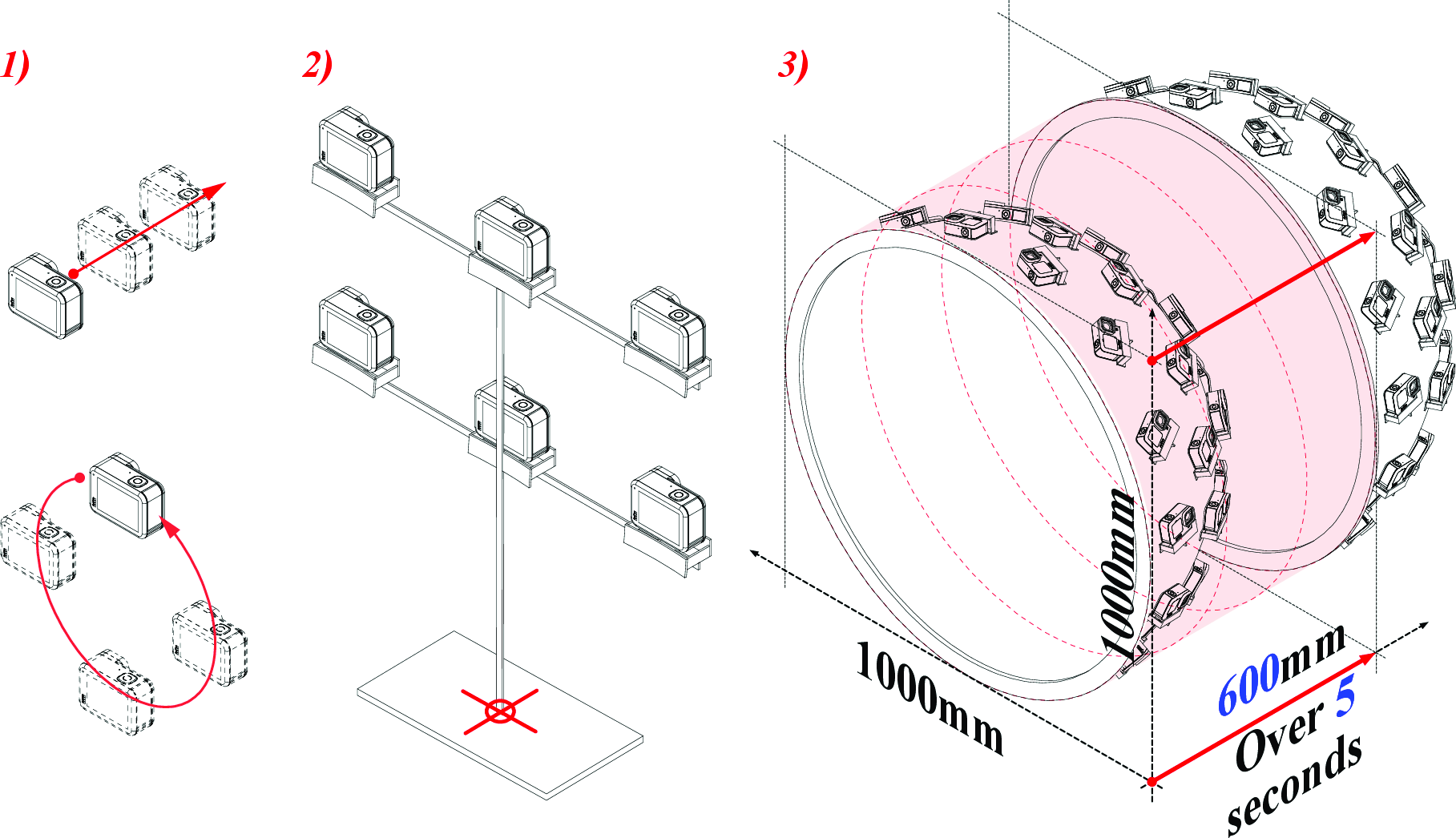
Figure 4: Spatiotemporal capture density metric highlights volumetric coverage advantages of the mobile rig.
Dynamic Light Field Reconstruction: Gaussian-Based Spatio-Temporal Representation
Central to the method is the dynamic light field reconstruction pipeline based on spatio-temporal Gaussian splats (extensions of 3DGS). Each Gaussian primitive simultaneously encodes position, scale, appearance (via SH), velocity, and a temporal visibility envelope. Static and dynamic regions are decoupled during initialization using view-consistent optical flow magnitudes, reducing redundancy and improving convergence.
Critical technical features:
- Flow-Guided Sparse Initialization: Classifies and instantiates dynamic Gaussians per-frame; static Gaussians are globally persistent, yielding compact, discriminative representations.
- Joint Camera Temporal Calibration: Explicitly optimizes unique sub-frame time offsets per camera, compensating for hardware-level millisecond desynchronization—essential for mitigating ghosting artifacts in agile, multi-view dynamic scenarios.
- Spatio-Temporal Supervision: Multi-term loss combines photometric, geometric (monocular depth guided), and motion (optical-flow-based) signals. This enforces photometric consistency, penalizes geometry drift, and constrains 3D primitive velocity projections to align with observed 2D flow—crucial for stabilizing reconstructions in poorly textured or ambiguously dynamic regions.
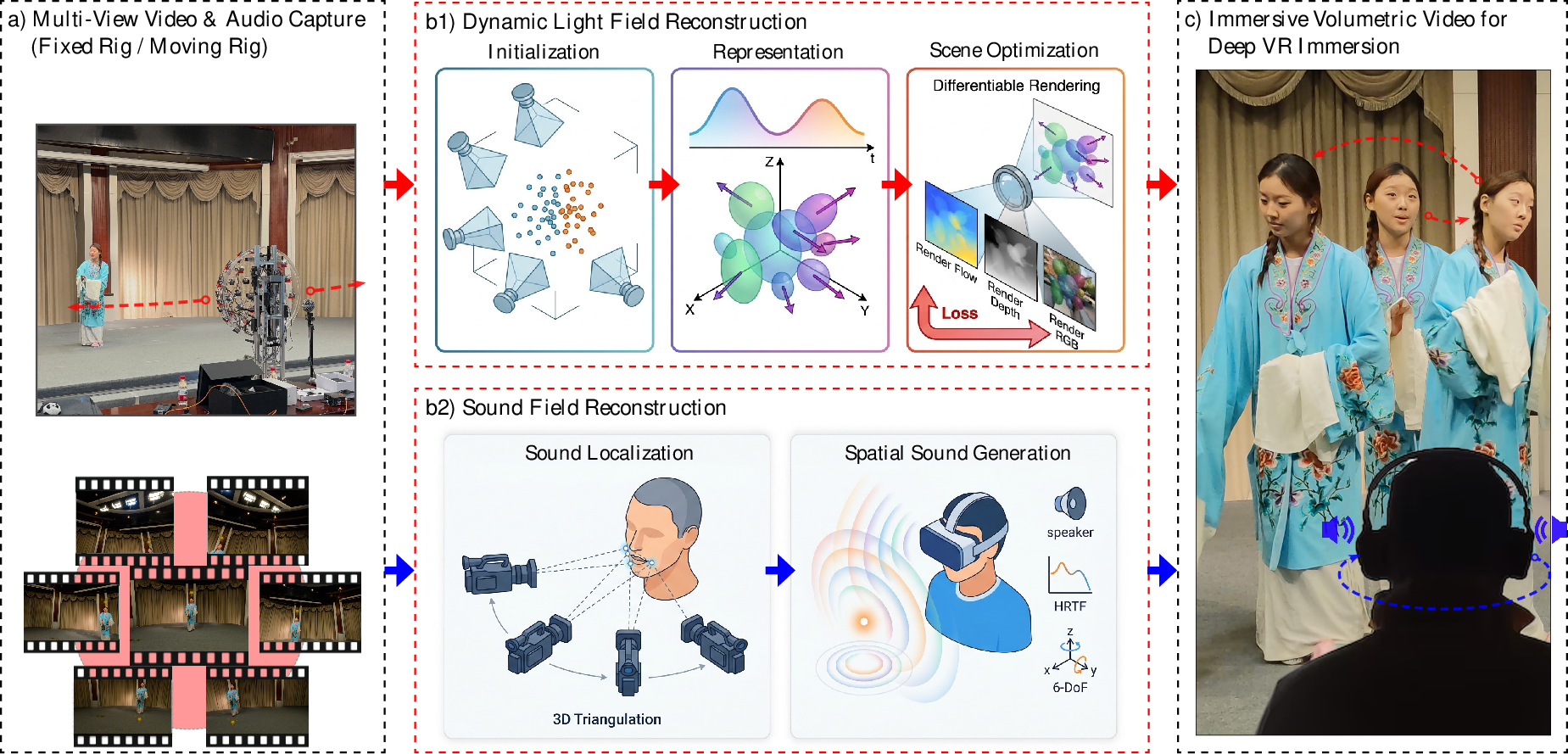
Figure 5: End-to-end pipeline for immersive 6-DoF VR—multi-modal capture, dynamic light field reconstruction, sound field synthesis, and VR rendering.
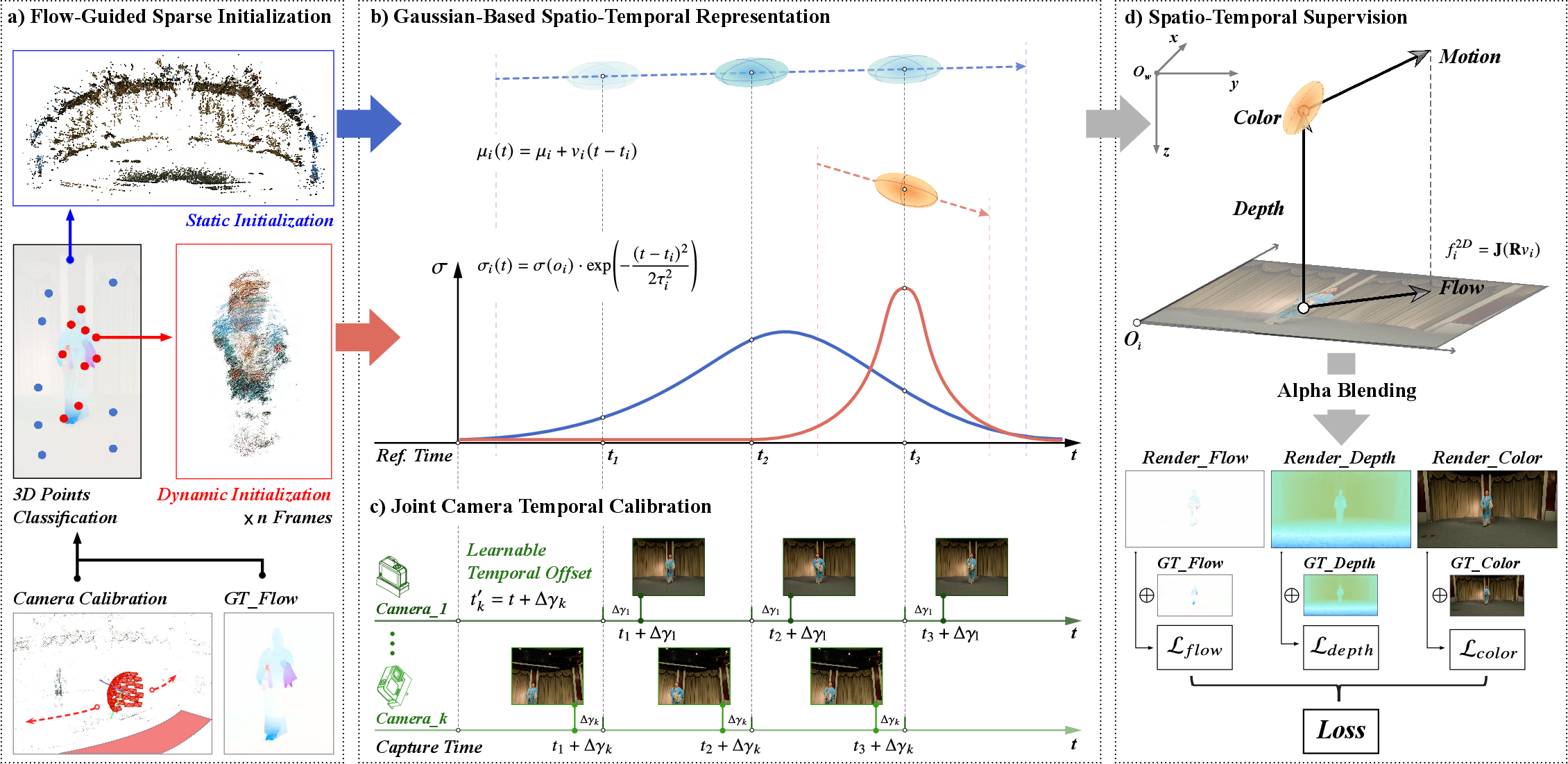
Figure 6: Overview of the dynamic light field framework: initialization, Gaussian-based spatio-temporal encoding, temporal calibration, and multi-faceted supervision.
Sound Field Reconstruction: Real-Time, Training-Free Approach
The paper introduces the first practical solution for view-dependent spatial audio synthesis from multi-view audiovisual capture. The system detects 3D source positions by triangulating tracked speaker mouth locations across views using keypoint estimation. It then renders binaural cues via head-related transfer functions (HRTF) modulated by relative direction and distance scaling, assuming a dominant, omnidirectional sound source. A virtual VR listener's pose drives adaptive binaural renderings, synchronized with real-time viewpoint changes.
This solution is robust to both static replays and live, interactive VR use, providing a plausible, dynamically consistent auditory scene.
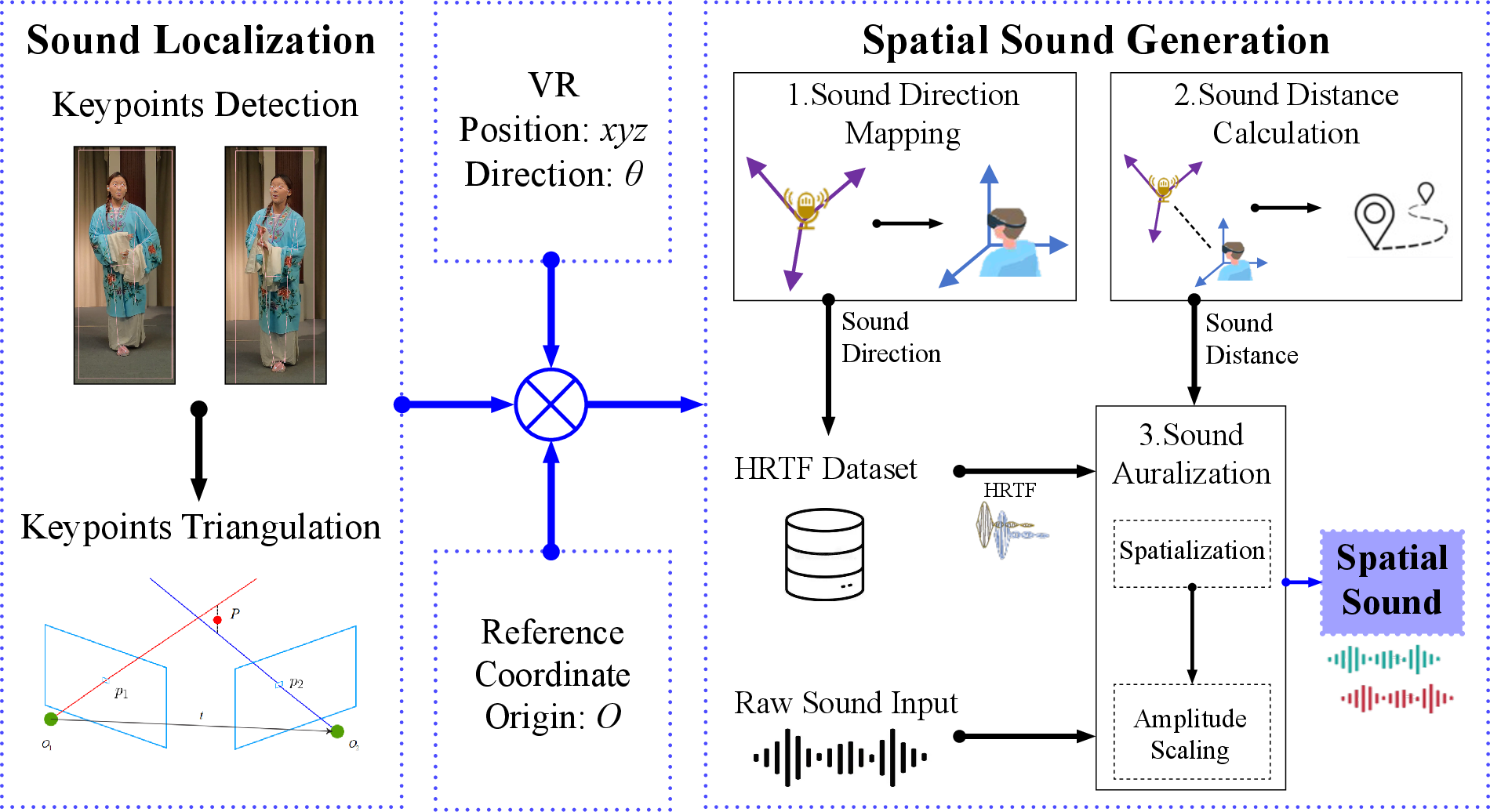
Figure 7: Sound field reconstruction pipeline: 3D sound source localization, binaural audio synthesis matched to VR user pose.
Experimental Validation and Numerical Results
The pipeline is extensively benchmarked against contemporary dynamic Gaussian-based representations (e.g., 4DGS, Gaussian4D, STG, Ex4DGS) on ImViD and four public datasets (N3V, MPEG-GSC, MeetRoom, Google Immersive). Results demonstrate that the proposed approach achieves:
- Superior Peak Signal-to-Noise Ratio (PSNR): On ImViD, a mean improvement of 4.21 dB above the strongest baseline.
- Lower Perceptual Error: LPIPS reduced from 0.153 (baseline) to 0.078.
- High Frame-Rate Rendering: >200 FPS on RTX 4090-class hardware.
- Efficient Storage: Only ~285 MB per scene, about half the storage of competing approaches at higher reconstruction fidelity.
Ablation experiments confirm the necessity of each pipeline component—flow-guided initialization, joint temporal calibration, and spatio-temporal geometric and motion supervision—for robust dynamic scene reconstruction and artifact suppression.
For the sound field reconstruction, user studies with 21 experts report that 90% describe the system as "immersive" and ~62% as "excellent" for spatialized perception, validating the practical efficacy of the non-trainable synthesis baseline.
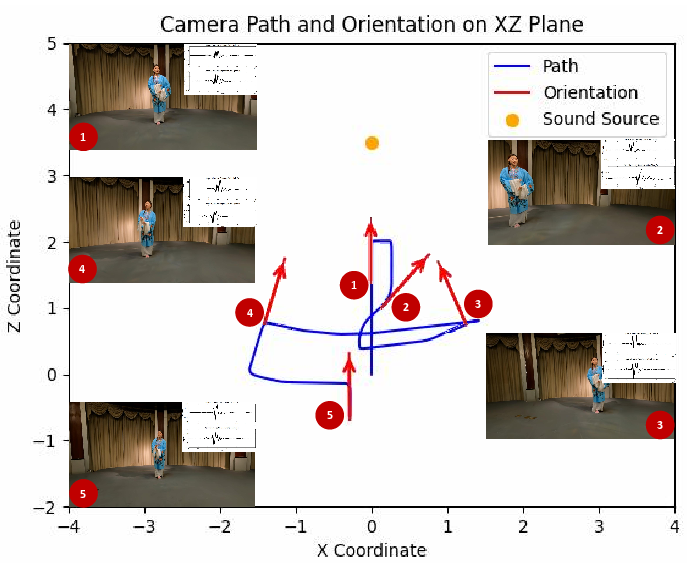
Figure 8: Visualization of 6-DoF interaction and corresponding multimodal feedback; the audiovisual feedback dynamically adapts to user pose and trajectory.
Implications and Future Prospects
The presented framework and dataset establish a new practical foundation for immersive scene reconstruction, fusing dynamic 4D visual and acoustic modalities into a coherent, high-quality multisensory VR experience. The technical advances—especially in spatio-temporal light field supervision and hardware-aware calibration—directly address historical bottlenecks in free-viewpoint dynamic rendering.
Implications include:
- Data-Driven, Scene-Level VR Content Creation: Paves the way toward democratized, scene-accurate VR without reliance on synthetic or generative model hallucination.
- Advancement in Multimodal Scene Understanding/Generation: The coupling of real synchronized audio and visual fields enhances opportunities for self-supervised learning and dataset-driven research in holistic perception, including embodied and language-grounded AI.
- Benchmarks for Dynamic Scene Fidelity and Multisensory Alignment: ImViD sets a new standard for evaluating spatiotemporal and multimodal consistency.
Real-world capture scale and viewpoint density still pose challenges for broader deployment; hardware and compute constraints remain relevant, especially for long sequences. Further work may integrate more scalable training (e.g., streaming, distributed optimization), hybrid generative-prior-driven rendering, or cross-modal end-to-end learning.
Conclusion
This paper delivers a comprehensive, modular pipeline—backed by a new dataset—for constructing and deploying immersive volumetric video in dynamic, naturalistic scenes with synchronized 6-DoF video and audio. Methodologically rigorous and empirically validated, the work establishes both a practical and conceptual framework for large-scale, multimodal VR/AR content reconstruction and interaction, and will catalyze future research into holistic, multisensory scene representation and generation.

