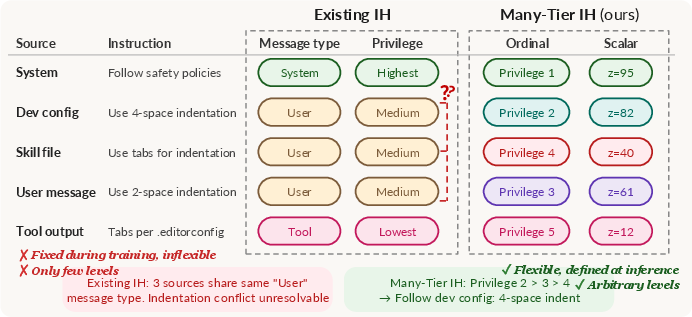
Many-Tier Instruction Hierarchy in LLM Agents
Abstract: LLM agents receive instructions from many sources-system messages, user prompts, tool outputs, other agents, and more-each carrying different levels of trust and authority. When these instructions conflict, agents must reliably follow the highest-privilege instruction to remain safe and effective. The dominant paradigm, instruction hierarchy (IH), assumes a fixed, small set of privilege levels (typically fewer than five) defined by rigid role labels (e.g., system > user). This is inadequate for real-world agentic settings, where conflicts can arise across far more sources and contexts. In this work, we propose Many-Tier Instruction Hierarchy (ManyIH), a paradigm for resolving instruction conflicts among instructions with arbitrarily many privilege levels. We introduce ManyIH-Bench, the first benchmark for ManyIH. ManyIH-Bench requires models to navigate up to 12 levels of conflicting instructions with varying privileges, comprising 853 agentic tasks (427 coding and 426 instruction-following). ManyIH-Bench composes constraints developed by LLMs and verified by humans to create realistic and difficult test cases spanning 46 real-world agents. Our experiments show that even the current frontier models perform poorly (~40% accuracy) when instruction conflict scales. This work underscores the urgent need for methods that explicitly target fine-grained, scalable instruction conflict resolution in agentic settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how AI chatbots (like LLMs, or LLMs) decide which instructions to follow when different people and tools tell them different things at the same time. Today, most systems use a simple “instruction hierarchy,” like “system > developer > user,” with only a few levels of authority. But real-life AI helpers can get instructions from many places—system rules, users, tools, files, other bots—so conflicts can involve lots more than 3–5 levels.
The authors introduce a new idea called Many-Tier Instruction Hierarchy (ManyIH). Instead of using a small fixed set of roles, they let each instruction carry its own “privilege” value (a kind of priority badge). The AI is told: when instructions conflict, follow the one with higher privilege. They also build a big test called ManyIH-Bench to see how well current AIs handle lots of conflicting instructions.
What questions were they trying to answer?
- Can today’s AI models correctly follow the most important instruction when there are many levels of priority, not just a few?
- How can we clearly tell a model which instruction is more important in a way that works even when there are many levels?
- How do we fairly test this skill across realistic tasks?
How did they study it?
They used two main ideas:
- Privilege Prompt Interface (PPI): Think of each instruction wearing a badge that shows its priority. The model also gets a simple rule like “If instructions conflict, follow the one with the higher privilege.” The paper tries two badge styles:
- Ordinal: privilege levels like 1, 2, 3… where a lower number means higher priority (Privilege 1 beats Privilege 5).
- Scalar: any score like 55 or 88 where a bigger number means higher priority.
This “badge tagging” is placed directly in the prompt so the model can read it. It’s like telling a robot, “Everyone here has a number on their name tag. When people disagree, listen to the person with the better badge.”
- ManyIH-Bench (the test set): They built 853 test cases with up to 12 different privilege levels in one prompt. It has two parts:
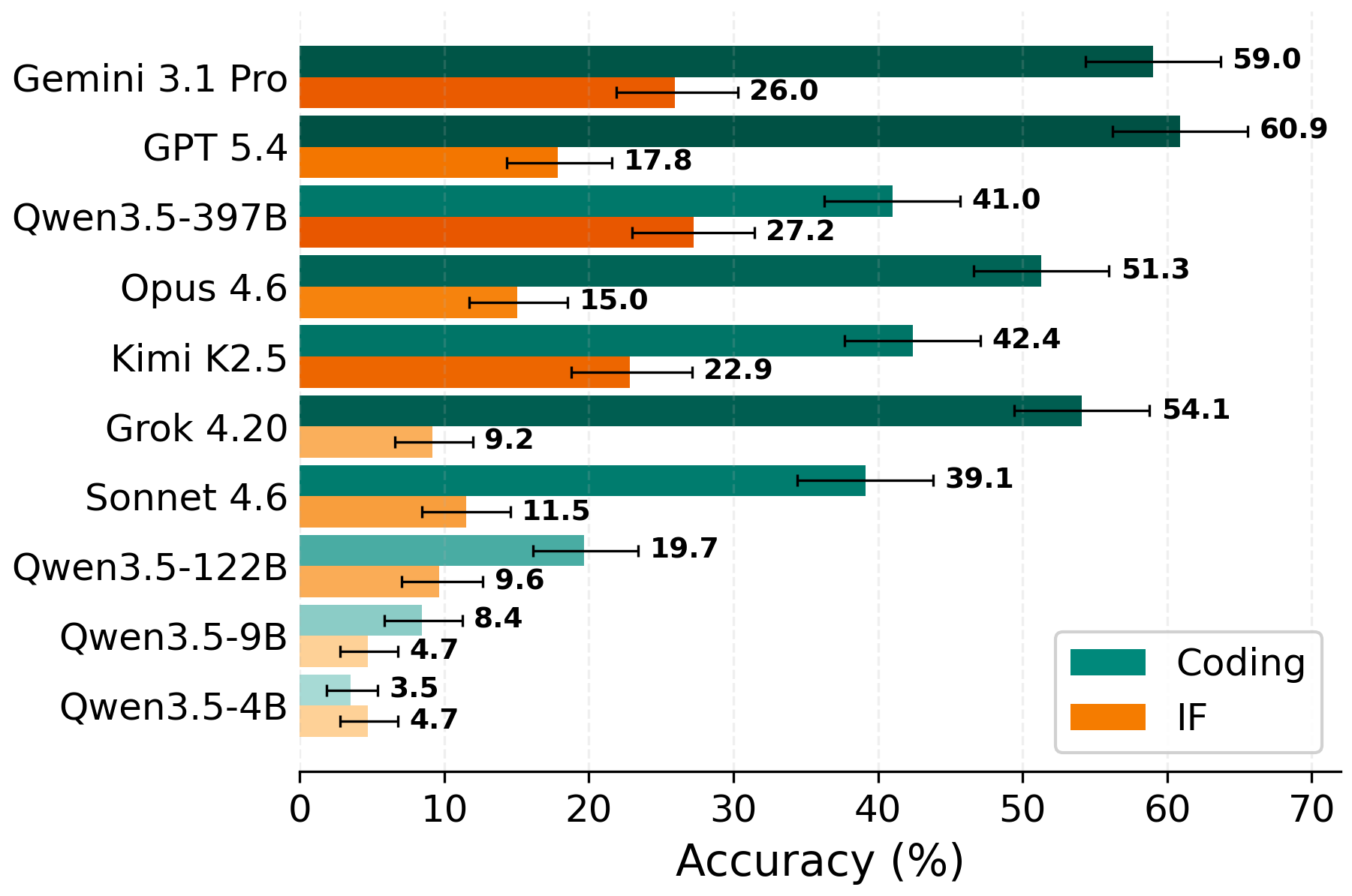
- Coding tasks (427 cases): The model must write correct Python code that also follows style rules (like how to name functions or where to put spaces). Some style rules conflict on purpose, so the model must pick the winning rule based on privilege.
- Instruction-following tasks (426 cases): From 46 real “agent” scenarios (like travel advice, writing help, etc.), they add conflicting instructions with different privileges. The model should follow the active (winning) rules and ignore the suppressed (lower-privilege) ones.
To make judging reliable, they use:
- Program checks (like running tests) for coding correctness and style.
- Clear, rule-by-rule evaluation for instruction-following, with human-verified quality.
What did they find?
Here are the main results the authors report:
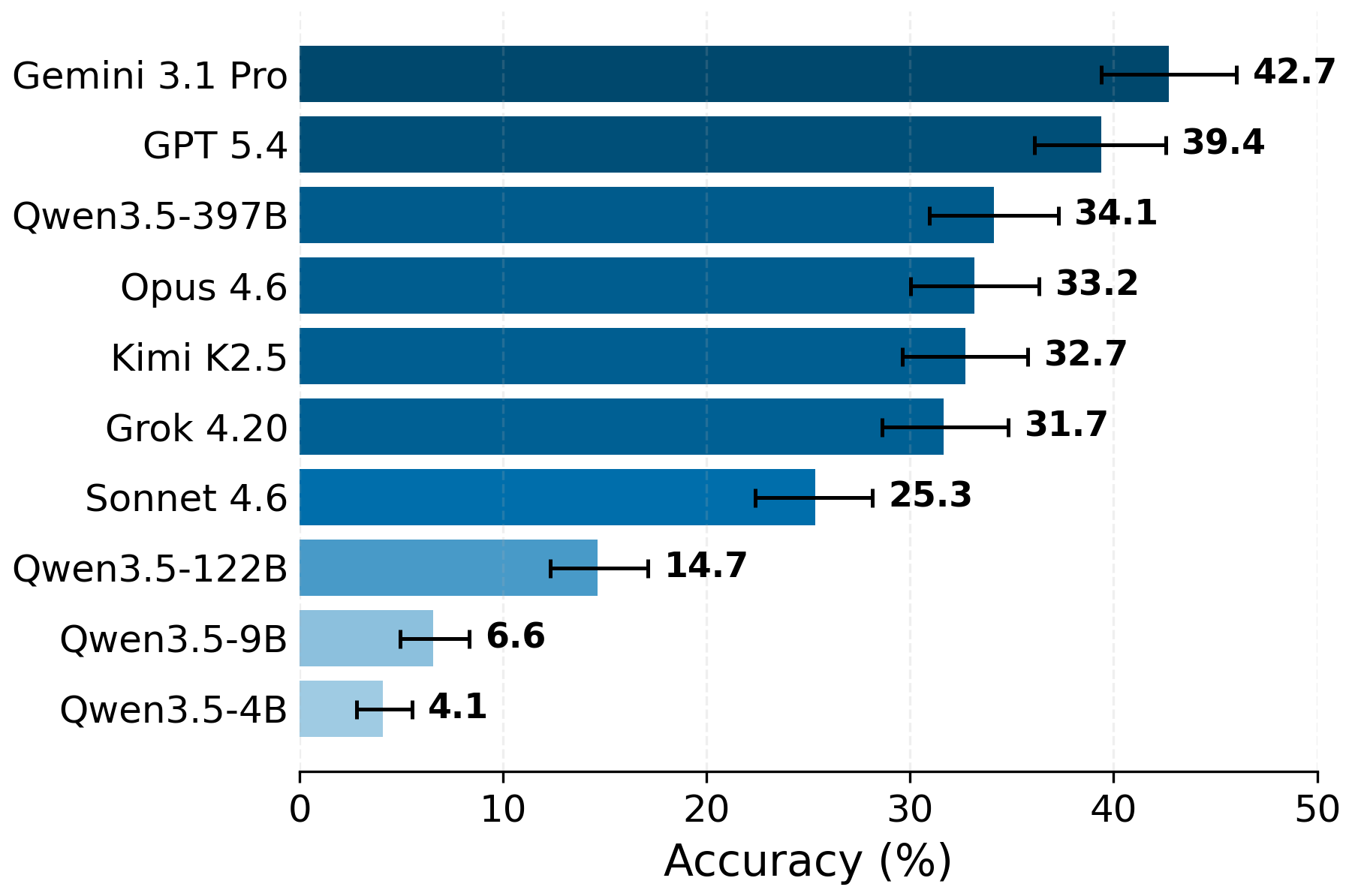
- Current top models struggle with many levels. Even strong AIs only got around 40% overall accuracy on ManyIH-Bench. In other words, when conflicts become complex and deep, models often pick the wrong instruction to follow.
- More levels = worse performance. As the number of privilege tiers increased, accuracy dropped for almost all models. Handling 2–3 tiers is much easier than 8–12.
- Models are sensitive to how privilege is written. Just changing the prompt format (ordinal vs scalar) made some models lose over 8% accuracy—even though the actual priorities didn’t change, only their presentation did.
- Tiny number changes can flip answers. Even when the order of privilege stayed the same, small changes to the numeric values in the scalar format caused some models to change their decisions on a noticeable number of cases.
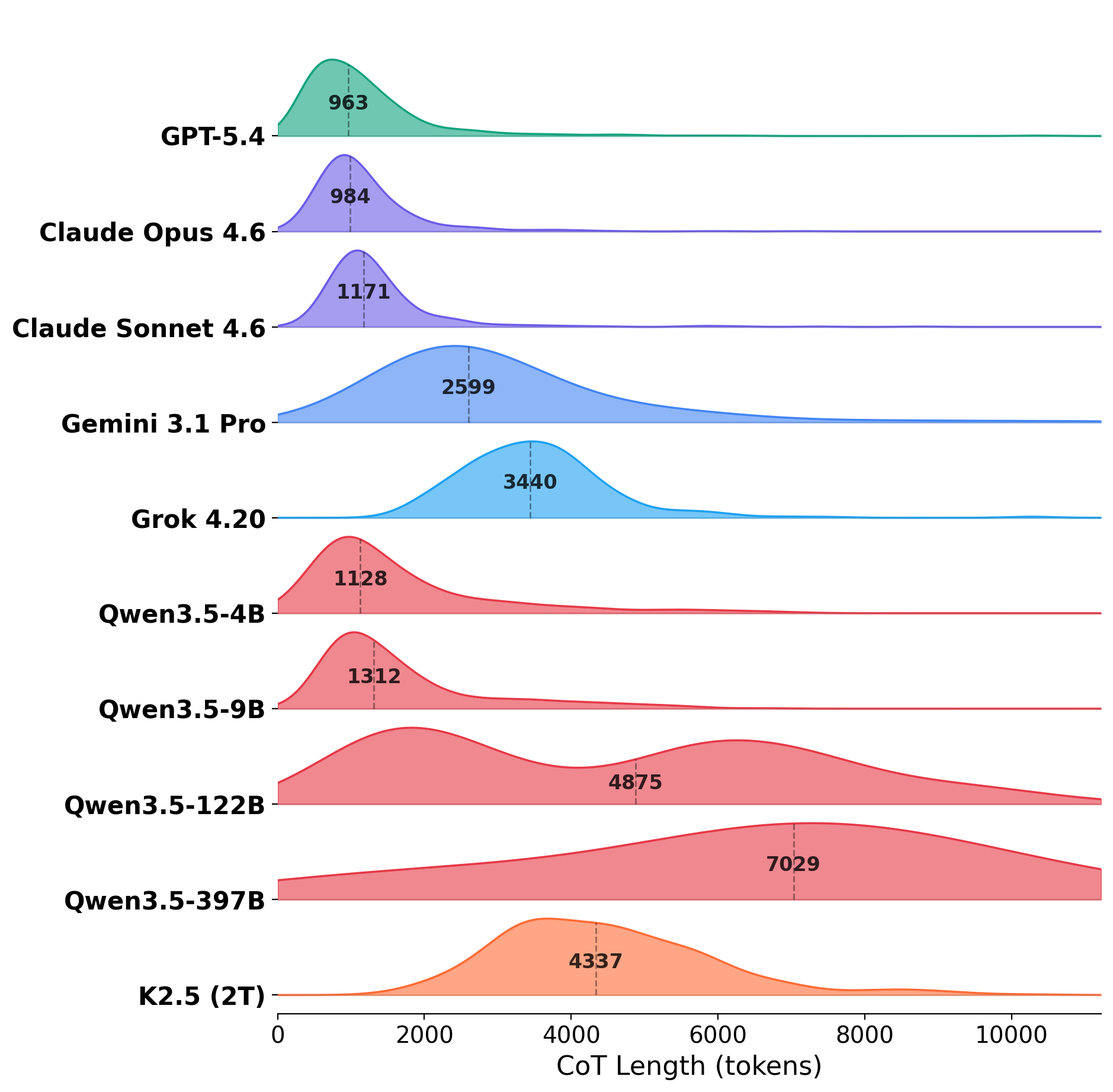
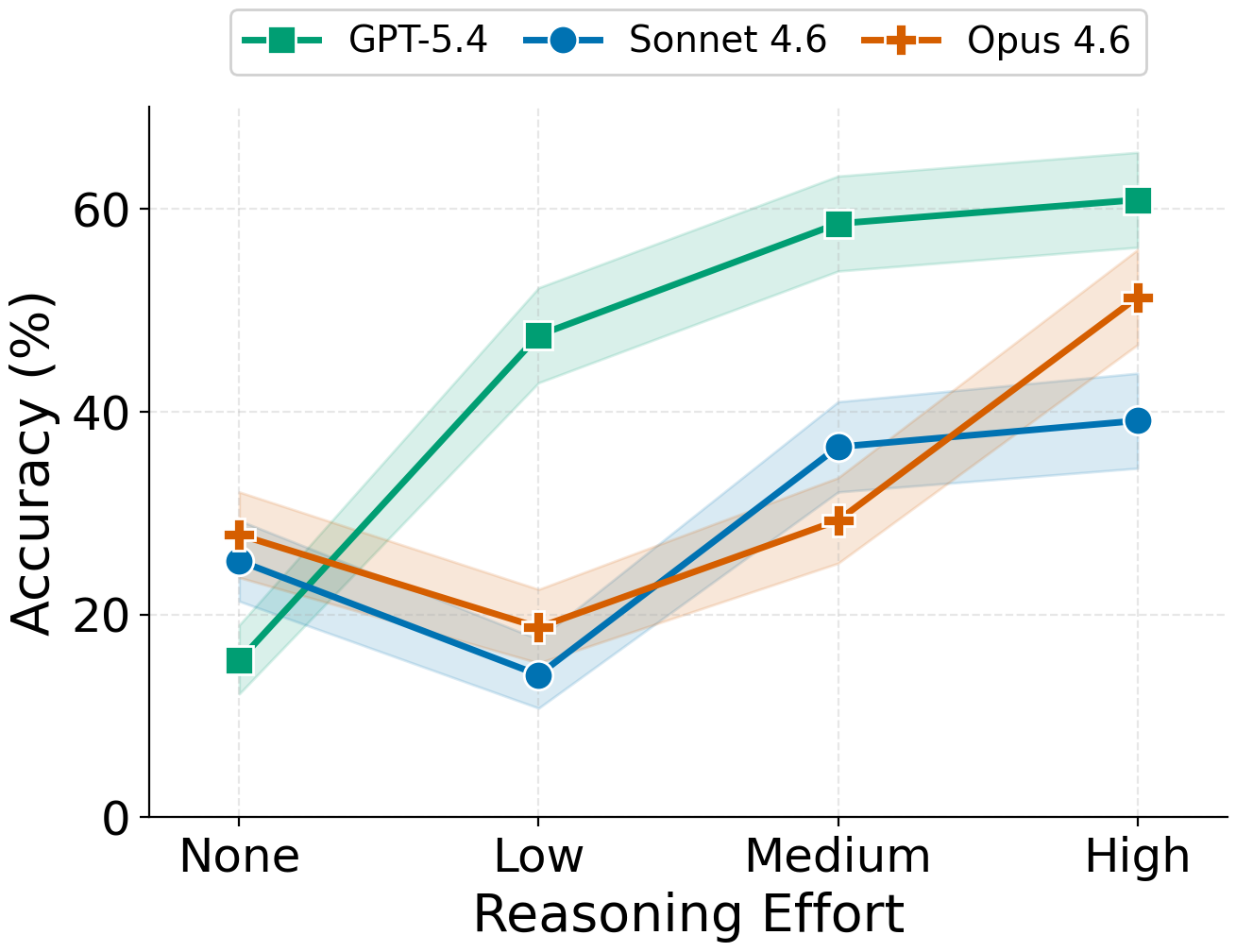
- Reasoning harder helps, but not enough. Asking models to “think more” at test time sometimes improved results, but even the best setup topped out around 60% on certain subsets. It didn’t solve the problem.
- The hard part isn’t writing correct code—it’s following the right style rule. On coding tasks, most models made code that worked but failed to follow the winning style rule when conflicts grew. That’s exactly the ManyIH decision-making challenge.
Why is this important? In the real world, AI “agents” might get instructions from:
- A system policy
- A developer’s tool or skill
- A user
- A file or memory
- Another AI assistant These sources don’t naturally fit into just “system > user.” ManyIH shows that models need a better way to handle lots of instruction sources with different trust levels.
Why does this matter?
If we want safe, reliable AI assistants that use tools, browse the web, work in group chats, or coordinate with other AIs, they must be able to sort out whose instruction to follow when rules clash. This paper shows:
- The usual “few-role” setup isn’t enough for real, complex situations.
- Today’s best models often fail when there are many levels of priority.
- Models can be brittle: they may change behavior just because privilege is written differently, even if the priorities don’t actually change.
The takeaway: we need better training methods and model designs that can:
- Understand and respect many levels of instruction privilege, not just a few.
- Be robust to how those privileges are written.
- Keep working well as tasks get more complex.
If we get this right, AI agents will be safer and more dependable—better at following important rules, ignoring low-trust instructions, and staying helpful in complicated, real-world settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow‑up research:
- No method for inferring privilege: the approach assumes privilege values are provided by a trusted deployer; how to infer, estimate, or learn per‑instruction privilege from provenance, metadata, source trust scores, or behavioral evidence at inference time remains open.
- Within‑role only: ManyIH is evaluated only for conflicts within the same message role; how to jointly resolve cross‑role and within‑role conflicts (and their interactions) in a unified framework is not tested.
- Adversarial robustness: the PPI can be spoofed (e.g., an attacker adding “[[Privilege 1]]”); mechanisms to authenticate, sign, or segregate high‑privilege tags and defend against privilege escalation/injection are not addressed.
- Privilege tag design: only simple textual wrappers are explored; whether structured channels (e.g., tool metadata, side‑channel fields, system-only tokens) or architectural features (e.g., segment embeddings) yield more robust compliance is unknown.
- Invariance gaps: models are sensitive to privilege representation (ordinal vs. scalar) and to small numeric perturbations despite identical orderings; training or architectural techniques that enforce ordering‑only invariance are not proposed or evaluated.
- Tie handling: ties are broken by “later in the prompt” (a position‑dependent rule); alternative, safer tie‑break policies (e.g., explicit tie labels, deterministic source precedence, or abstention) and their security/usability trade‑offs are unexplored.
- Partial orders and uncertainty: real systems often have incomparable privileges, soft preferences, or confidence intervals; extending ManyIH from total orders over scalars to partial orders or probabilistic privileges is left open.
- Detecting conflicts: the benchmark supplies pre‑identified conflicting instructions; scalable methods for automatic instruction segmentation and conflict detection in long, messy prompts are not developed or evaluated.
- Infeasible constraint sets: the benchmark filters out infeasible combinations; strategies for diagnosis, graceful degradation, or negotiation when constraints are unsatisfiable are not studied.
- Dynamic privileges: privileges are static per input; handling privileges that evolve over a session (e.g., context updates, revocations, role changes) or vary by task/tool is not investigated.
- Position effects: ManyIH aspires to position‑invariant privilege resolution, yet LLMs are known to exhibit recency biases; systematic study and mitigation of position effects beyond the tie rule is missing.
- Generality of domains: evaluation is limited to Python coding styles and instruction‑following augmentations of 46 agents; coverage of other languages, modalities (vision, speech), tools, or decision‑making tasks is untested.
- Realistic end‑to‑end agents: ManyIH is not validated in full agent loops (retrieval, tool calls, multi‑agent collaboration) where privileges may attach to tools, memory, or retrieved content and can conflict across steps.
- Multilingual settings: prompts and constraints appear English‑only; robustness of privilege interpretation and conflict resolution across languages and mixed‑language contexts remains open.
- Long‑context scaling: while 40k tokens are allowed, the benchmark does not systematically vary context length; how tiered IH scales with extreme context sizes and context fragmentation is not measured.
- Training methods: the paper proposes a paradigm and benchmark but no training/fine‑tuning recipes; data construction, losses, and curricula that teach many‑tier privilege reasoning are not provided.
- Architectural supports: beyond prompt design, no exploration of architectures that encode privilege separately (e.g., learned privilege embeddings, control channels, or verifier‑integrated planners) is provided.
- Reasoning–efficiency trade‑offs: longer CoT does not reliably help; principled methods to achieve efficient yet reliable privilege resolution (e.g., symbolic solvers, planning+checking) are not explored.
- Error taxonomy: failures are reported as accuracy drops, but a detailed diagnosis (misreading tags, mis‑segmenting instructions, failing to compare privileges, overfitting to position, etc.) is not provided.
- Metric design: an all‑or‑nothing pass metric is used; graded metrics that separately quantify conflict resolution accuracy, non‑conflicting adherence, and safety‑critical wins are not evaluated.
- Benchmark construction biases: IF subset instructions are LLM‑generated and LLM‑verified with ~80% human‑validated faithfulness; residual bias, leakage, and judge brittleness are not fully quantified or mitigated.
- Constraint diversity in coding: conflicts are limited to stylistic constraints; whether results transfer to semantic trade‑offs (e.g., performance vs. privacy) is unknown.
- Privilege–position correlation: privileges are randomized and decoupled from position; how models behave when real‑world privileges correlate with position, source, or formatting is not studied.
- Robustness to tag variants: only two PPI formats and one meta‑instruction are tried; the sensitivity to different delimiters, wording, casing, spacing, or embedding in JSON/Markdown is not systematically mapped.
- Handling nested/overlapping instructions: the PPI tags contiguous instruction spans; overlapping or nested privileges (e.g., a global high‑privilege rule with local exceptions) are not supported or tested.
- Provenance integration: the framework does not integrate cryptographic provenance (e.g., signed tool outputs) or trust pipelines that could programmatically assign privileges.
- Human factors and governance: how deployers author, audit, and manage many‑tier privilege policies at scale (usability, errors, versioning, transparency) is not addressed.
- Safety interactions: how ManyIH interacts with constitutional/safety policies (e.g., when a lower‑privilege instruction contradicts a high‑privilege safety rule) and how to formalize non‑overridable constraints is unclear.
- Multi‑agent settings: while motivated by multi‑agent systems, no explicit evaluation of conflicts among agents with different privileges, or of arbitration/consensus mechanisms, is provided.
- Robustness to stochasticity: experiments use temperature 0; variance under sampling, different seeds, or decoding strategies is not reported.
- Theoretical guarantees: there is no formal semantics or guarantees (e.g., soundness/completeness under certain assumptions) for privilege‑based conflict resolution in LLMs.
Practical Applications
Overview
The paper proposes Many-Tier Instruction Hierarchy (ManyIH)—a paradigm and Privilege Prompt Interface (PPI) that let LLM agents resolve conflicts among arbitrarily many instructions with explicit, dynamic privilege values at inference time—and ManyIH-Bench, a benchmark to evaluate this capability at scale. Below are practical applications that leverage these findings and methods across sectors, grouped by deployment horizon.
Immediate Applications
The following applications can be prototyped or deployed now by updating prompts, orchestration middleware, or evaluation pipelines, while observing the paper’s caveats (e.g., models’ brittleness to privilege formats and current performance below 50% on ManyIH-Bench).
- Privilege-aware agent orchestration in enterprise software
- Sectors: software, IT, enterprise productivity
- What to do: Implement the PPI (ordinal or scalar) in your agent framework (e.g., LangChain, LangGraph, LlamaIndex, OpenAI Assistants, AutoGen) so every instruction from system messages, users, tools, memory, RAG results, and other agents is tagged with a privilege value. Resolve conflicts strictly by privilege, not by message role or position.
- Workflows/tools:
- A “policy-as-code” layer that maps instruction sources to privileges (e.g., system=1, developer config=5, first-party tools=20, third-party plugins=50, unverified web=80 in an ordinal scheme).
- Middleware that wraps all incoming content with PPI tags before passing to the model; privilege metadata attached to tool schemas and vector-store documents.
- Assumptions/dependencies: Privilege assignment must be controlled by a trusted orchestrator; PPI tags must be protected from user or tool tampering (e.g., sanitize tool outputs to strip tags, or confine tags to a system-only channel). Expect model sensitivity to tag formats and numeric values; choose a single interface and stay consistent.
- Safer tool use and browsing/RAG with trust-weighted conflict resolution
- Sectors: cybersecurity, search, knowledge management
- What to do: Tag retrieved documents, web pages, and plugins with privilege values based on provenance (e.g., signed corporate docs > vetted databases > arbitrary web). In the prompt, instruct the model to prefer higher-privilege evidence when content conflicts.
- Workflows/tools: Integrate source trust scores into PPI tags for each retrieved chunk; add rules that prevent low-trust content from overriding safety or compliance instructions.
- Assumptions/dependencies: Requires reliable provenance metadata; existing models remain vulnerable if attackers can inject pseudo-privileged tags—harden the ingestion pipeline.
- Role-sensitive multi-user group chat agents
- Sectors: collaboration tools, customer support, community management
- What to do: In group chats with admins/moderators/members, assign per-user privilege levels at inference (not just “user” role). The agent obeys higher-privilege participants on conflicts (e.g., moderator safety policy vs. member request).
- Workflows/tools: Group-chat middleware that maps user IDs to privileges; add audit logs showing which instruction won and why.
- Assumptions/dependencies: Requires identity/auth integration and reliable role mapping; guard against privilege escalation if user-supplied content can embed tags.
- Coding assistants that enforce multi-source style and policy constraints
- Sectors: software engineering, DevOps
- What to do: For code-generation, tag style rules from PEP8/company policies, repository linters, and project-specific guidelines with privileges. The assistant must satisfy the highest-privilege style in each conflict group while still passing tests.
- Workflows/tools:
- IDE extensions or CI bots that wrap tasks and constraints in PPI.
- Combine with linters/formatters (e.g., Black, ESLint) as post-checks; fail builds if the assistant violates higher-privilege rules.
- Assumptions/dependencies: Model performance shows ManyIH compliance is the bottleneck (style adherence), while functional correctness can remain high—use post-generation checkers to mitigate errors.
- Compliance-first enterprise chatbots
- Sectors: finance, healthcare, legal/compliance-heavy industries
- What to do: Elevate regulatory and safety rules above user requests and tool outputs via PPI; ensure conflicts resolve in favor of compliance instructions.
- Workflows/tools: A central policy registry; privilege-tagged snippet injection into prompts; compliance dashboards to review adherence.
- Assumptions/dependencies: Must continuously update policy rules; defend against adversarial content attempting to masquerade as high privilege.
- Privilege-aware multi-agent systems
- Sectors: autonomous operations, research agents, decision support
- What to do: In agent swarms, assign privileges to sub-agents (e.g., planner > critics > skill executors) and to tool outputs; conflicts defer to the highest-privilege agent.
- Workflows/tools: Router that tags inter-agent messages; adjudication step that prunes lower-privilege instructions before final actuation.
- Assumptions/dependencies: Requires explicit agent roles and a stable communication protocol; monitor overhead from larger prompts.
- Operational evaluation using ManyIH-Bench for release gating
- Sectors: MLOps, QA
- What to do: Integrate ManyIH-Bench (or a customized variant) into CI/CD to measure adherence to multi-tier conflicts whenever you change models, prompts, or tools.
- Workflows/tools: GitHub Actions or similar pipeline; per-model dashboards reporting overall vs. subset accuracy and sensitivity to privilege formats.
- Assumptions/dependencies: Benchmark is non-adversarial; results may not capture worst-case security exposures—pair with adversarial testing.
- Education: Teacher-over-student instruction resolution in tutors
- Sectors: education technology
- What to do: Privilege teacher-set curricula, safety policies, and accommodation rules over student ad hoc requests or third-party content in tutoring agents.
- Workflows/tools: LMS integration mapping course policies to privilege tags; per-lesson constraints encoded via PPI.
- Assumptions/dependencies: Identity and role integration; ensure students cannot inject privileged tags.
- Healthcare assistant with privilege-aligned instruction following
- Sectors: healthcare
- What to do: Rank instruction sources (licensed clinician orders > institutional guidelines > patient preferences > generic web info). The assistant resolves conflicts accordingly.
- Workflows/tools: EHR-integrated orchestrator assigning privileges by data provenance and clinician identity; logging for clinical audit.
- Assumptions/dependencies: Strict governance; human oversight for safety; prevent privilege spoofing; ensure PHI is handled securely.
- Finance/trading copilots with risk-control precedence
- Sectors: finance
- What to do: Enforce that risk limits, compliance and conduct policies override trader prompts or market commentary when generating plans or summaries.
- Workflows/tools: Policy engine to compute privileges; post-hoc validators (e.g., rule checks) before order staging.
- Assumptions/dependencies: Regulatory constraints; audit trails; careful defense against adversarial inputs posing as privileged content.
- Robotics and autonomy: instruction arbitration for mission safety
- Sectors: robotics, manufacturing, logistics
- What to do: Tag mission plans, safety constraints, and operator overrides with top privilege; ensure lower-privilege subsystem suggestions cannot override safety.
- Workflows/tools: Mission controller that injects PPI into language-mediated planning modules; safety monitors enforcing privileged constraints before execution.
- Assumptions/dependencies: Real-time constraints; integration with non-LLM safety controllers; ensure the LLM’s privilege logic does not become the single point of failure.
- Daily life: smart-home assistants with household role hierarchies
- Sectors: consumer tech
- What to do: Parents/primary owners > teen/guest instructions > IoT notifications; prioritize device safety and parental controls via explicit privileges.
- Workflows/tools: Home app UI where admins set privilege levels; device policies injected via PPI.
- Assumptions/dependencies: Shared accounts and identity are reliable; prevent child devices from producing privileged tags.
Long-Term Applications
These opportunities require further research, model training, ecosystem agreement, or product maturation—motivated by the paper’s findings that current models degrade with more tiers and are sensitive to representation.
- Model training and architectures explicitly aligned to ManyIH
- Sectors: AI model providers, academia
- What to build: Fine-tune or architect models (e.g., with Instructional Segment Embeddings or dedicated heads) to reason over arbitrary privilege tiers, invariant to numeric scaling and tag formats; train on ManyIH-like data.
- Dependencies: High-quality, diverse many-tier datasets; evaluation beyond non-adversarial cases; inference costs of more complex reasoning.
- Standardization of instruction privilege markup
- Sectors: standards bodies, platforms, policy
- What to build: An open “Instruction Privilege Markup” spec (akin to content-security policies) that all agent frameworks and plugins implement; per-source privilege contracts.
- Dependencies: Cross-vendor agreement; backward compatibility; mechanisms to prevent tag injection by untrusted parties.
- Cryptographically assured privilege and provenance
- Sectors: security, enterprise IT, government
- What to build: Cryptographic signing of instructions/tools/data with verifiable source identity, tied to privilege levels; the agent honors privilege only if signatures validate.
- Dependencies: PKI adoption; secure key management; tool/plugin ecosystems supporting attestation.
- Adaptive, evidence-based trust calibration
- Sectors: search, RAG, research assistants
- What to build: Dynamic privilege assignment based on source reliability scores (e.g., citations, past accuracy, human feedback), updated over time; automatic down-weighting of unreliable sources.
- Dependencies: Reliability metrics, feedback loops, and data pipelines; interpretability about why privileges changed.
- Formal verification and auditing of privilege resolution
- Sectors: safety-critical industries, regulators
- What to build: Tooling that statically or probabilistically verifies that an agent’s outputs satisfy all active (winning) instructions given the privilege order; produce explainable traces for compliance audits.
- Dependencies: Specification languages for constraints; integration with legal/compliance review; performance overhead.
- Government and industry procurement benchmarks
- Sectors: public sector, regulated industries
- What to build: Policies that require ManyIH-style tests in vendor evaluations (e.g., NIST-style benchmarks); minimum bars for multi-tier conflict resolution and robustness to representation changes.
- Dependencies: Benchmark expansion to adversarial settings; consensus on pass criteria; cost-effective testing procedures.
- Privilege-aware skill/plugin marketplaces
- Sectors: software platforms, app ecosystems
- What to build: Marketplaces where plugins declare privilege requirements and undergo certification; orchestrators enforce caps (e.g., third-party plugins cannot exceed a set privilege).
- Dependencies: Certification programs; runtime sandboxes; revenue models aligned with safety.
- Safety-critical deployments (healthcare, aviation, energy)
- Sectors: healthcare, aviation, energy/utilities, automotive
- What to build: Agents that can rigorously prioritize safety and regulatory instructions across many data/control sources (human supervisors, sensors, logs, external advisories), with verified adherence.
- Dependencies: Co-designed HCI for overrides, redundant safeguards, and fail-safes; regulatory approvals; assurance cases.
- Education-scale orchestration across curricula and stakeholders
- Sectors: education
- What to build: Privilege-managed tutoring across curricula, district policies, IEP/504 accommodations, and parental preferences; consistent conflict resolution across courses and grades.
- Dependencies: Data interoperability across LMS/SIS; role identity management; consent and privacy protections.
- Research assistants that prioritize high-trust literature
- Sectors: academia, pharma, R&D
- What to build: ManyIH-driven RAG that elevates meta-analyses and consensus guidelines over preprints or blogs when synthesizing or recommending actions.
- Dependencies: Rich metadata on evidence quality; domain ontologies; careful UX to expose privilege decisions.
- Consumer email and productivity assistants with policy-override
- Sectors: consumer productivity
- What to build: Assistants that respect user rules but cannot violate security settings or organizational policies (e.g., data leakage prevention rules), even when tool outputs conflict.
- Dependencies: OS/app-level policy integration; robust privilege enforcement inside apps and cloud services.
Key Assumptions and Dependencies (Cross-cutting)
- Trusted privilege assignment is a prerequisite: An administrator or orchestration layer—not users or untrusted tools—must set privilege values.
- Robustness remains a challenge today: The paper shows model performance degrades as the number of tiers grows and is sensitive to privilege formats and even small numeric perturbations; mitigate with consistent interfaces, post-checkers, and human oversight.
- Security hardening is essential: Prevent untrusted inputs from introducing or altering PPI tags; consider content sanitization, channel separation for tags, or cryptographic validation.
- Context and cost trade-offs: Adding PPI and richer constraints increases prompt length and latency; measure performance and cost impacts.
- Evaluation must be continuous: Integrate ManyIH-Bench (and domain-specific variants) and adversarial tests into QA to detect regressions when updating models or orchestration logic.
These applications turn ManyIH’s core idea—explicit, fine-grained, and dynamic privilege resolution at inference—into concrete products and workflows that can improve reliability, safety, and governance of LLM agents across real-world settings.
Glossary
- agentic: Pertaining to autonomous agents or systems that act, plan, and make decisions. Example: "agentic systems"
- Agent Swarm: A specific multi-agent system used as an example of interacting agents. Example: "Agent Swarm"
- all-or-nothing metrics: Evaluation criterion where a sample counts as correct only if all required conditions are satisfied. Example: "all-or-nothing metrics"
- AST (Abstract Syntax Tree): A tree-structured representation of source code used for static analysis and transformation. Example: "AST analysis"
- bootstrap 95% CIs: Confidence intervals estimated via bootstrap resampling methods at the 95% level. Example: "bootstrap 95% CIs"
- chain-of-thought (CoT): The intermediate reasoning tokens or explanations a model produces when solving a problem. Example: "chain-of-thought length"
- chat templates: Prescribed conversational formats (with roles/tokens) used to train and run chat models. Example: "chat templates"
- conflict groups: Sets of mutually exclusive instructions that compete under a privilege ordering. Example: "conflict groups"
- indirect prompt injection attacks: Attacks that embed adversarial instructions in external content so they enter the model’s context indirectly. Example: "indirect prompt injection attacks"
- Instruction Hierarchy (IH): A principle that higher-privilege instructions override lower-privilege ones when conflicts arise. Example: "The Instruction Hierarchy"
- Instruction privilege: The authority level of an instruction based on the trust assigned to its source. Example: "Instruction privilege is a property of an instruction"
- Instructional Segment Embedding (ISE): An architectural method assigning learned segment embeddings to differentiate instruction roles. Example: "Instructional Segment Embedding"
- jailbreak attacks: Attempts to bypass safety rules by prompting models to ignore higher-level safety instructions. Example: "jailbreak attacks"
- LLM judges: LLMs used as automated evaluators to assess constraint adherence or correctness. Example: "LLM judges"
- Many-Tier Instruction Hierarchy (ManyIH): An extension of IH that supports arbitrarily many privilege levels defined at inference time. Example: "Many-Tier Instruction Hierarchy (ManyIH)"
- ManyIH-Bench: A benchmark designed to evaluate models’ ability to resolve multi-tier instruction conflicts. Example: "ManyIH-Bench"
- MBPP: A dataset of Python programming problems with unit tests (Mostly Basic Python Problems). Example: "MBPP coding problems"
- meta-instruction: A high-level directive inserted into the prompt that specifies rules for resolving instruction conflicts. Example: "meta-instruction"
- oracle-free alignment: Alignment techniques that do not rely on ground-truth oracle labels during training or evaluation. Example: "oracle-free alignment"
- ordinal interface: A privilege-tagging scheme where lower ordinal numbers indicate higher authority. Example: "The ordinal interface uses ordinal values 1,2,3,..."
- PEP 8: The official Python style guide dictating code formatting conventions. Example: "PEP~8"
- Privilege Prompt Interface (PPI): A prompt annotation mechanism that tags instructions with explicit privilege values. Example: "privilege prompt interface (PPI)"
- reasoning effort: A test-time control that adjusts the amount of deliberate reasoning a model performs. Example: "reasoning effort to high"
- role labels: Categorical tags (e.g., system, user, tool) assigned to messages that imply default privilege. Example: "role labels"
- role tokens: Special tokens marking conversational roles that models are trained to interpret. Example: "role tokens"
- scalar interface: A privilege-tagging scheme where larger numeric values indicate higher authority. Example: "a scalar interface which uses any scalar values"
- system prompt extraction: The act (or attack) of eliciting hidden system instructions from a model. Example: "system prompt extraction"
- tool schemas: Structured specifications of tools (APIs/functions) that describe parameters, behaviors, and constraints. Example: "tool schemas"
Collections
Sign up for free to add this paper to one or more collections.