- The paper's main contribution is its agentic architecture that enables precise, inference-time consent management in generative AI.
- It demonstrates how granular, context-dependent opt-in mechanisms overcome the limitations of training-time opt-out protocols while addressing multi-party ownership and copyright challenges.
- The study outlines practical implementations in music and other domains, offering a roadmap for dynamic rights control and equitable creator compensation.
Nuanced Consent Mechanisms in Generative AI: A Critical Appraisal of Inference-Time Opt-in
Background: Structural Deficiencies of Training-Time Opt-Out
Prevailing generative AI development is characterized by large-scale, indiscriminate data scraping, with AI developers often assuming default opt-in for any publicly accessible digital content. The binary "opt-out" regime, enforced primarily through protocols like robots.txt and nascent standards such as TDMRep, ai.txt, and ODRL, has proven functionally inadequate. Empirical studies reveal that bot adherence to these directives is inconsistent, especially as directives become more restrictive and as scrapers (including AI model pretraining crawlers) either actively avoid or circumvent them. Consequently, rights holders face an unmanageable compliance burden, compounded by poor data provenance tooling, lack of dataset transparency, and the infeasibility of training data removal post-ingestion. This makes the default paradigm de facto "opt-in," particularly as high-profile data sets contain extensive copyrighted material irrespective of restriction signals ([longpre_consent_2024]; [kim_scrapers_2025]; [cui_odyssey_2025]).
The practical and conceptual failures of this model are amplified by the viral use of generative AI for stylistic imitation (as seen in the “Ghiblification” trend), and by the inability of copyright alone to protect intangible aspects of works such as signature style or likeness, which frequently lie outside statutory IP frameworks ([jon_ghiblification_2025]; [sobel_elements_2024]). Notably, copyright exceptions—like the EU TDM exception—further complicate rights holders’ control, as legal ambiguity persists regarding “lawful access” and the scope of permissible use for AI training ([lucchi_generative_2025]).
Argument for Nuanced, Contextual Consent
The paper advances an agentic and workflow-aware theory of consent, positing that “opt-in” must be highly granular, context-dependent, and verified not only at the point of data acquisition (training) but also at inference and dissemination stages of generative AI. This expanded approach recognizes:
- Complex Multi-Party Ownership: Creative works often involve multiple, dynamically changing rights holders (individuals, institutions, estates, or communities), whose interests may be divergent or based on non-commercial incentives (e.g., cultural custodianship) ([kostova_creators_2017]; [bachner_facing_2005]; [kirui_epistemics_2025]).
- Datafication of Style and Likeness: Generative AI is uniquely able to learn and reproduce high-dimensional stylistic attributes and likenesses, which copyright frameworks inadequately address. This exposes creators—especially those with recognizable personal brands or cultural identifiers—to non-consensual use and even economic harm ([bukingolts_mimetic_2025]; [benton_artists_2025]).
- Irreducible Diversity of Contexts of Use: The potential downstream uses of generative outputs are effectively limitless, including by platforms and in modalities that may run counter to rights holders’ personal, reputational, or cultural priorities ([deladurantaye_control_2025]; [lee_rethinking_2022]).
Alternative Levers of Control Across the Generative AI Pipeline
By mapping stakeholder influence across the generative AI lifecycle, the paper identifies that locus of control can—and should—extend to multiple stages:
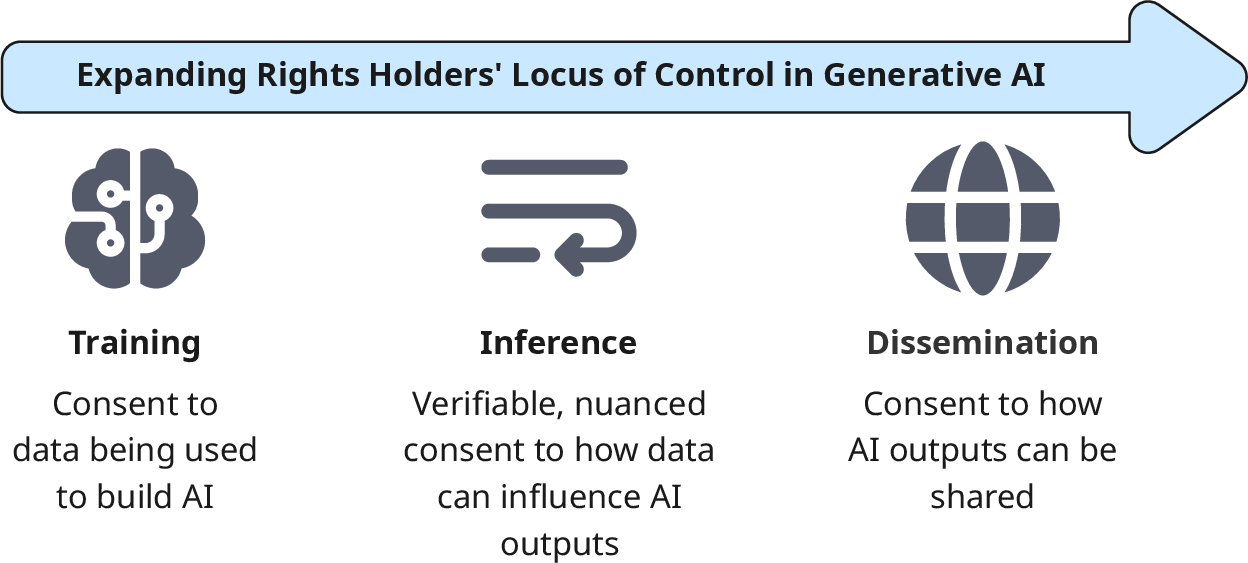
Figure 1: Expanding rights holders' locus of control from training data to inference and dissemination.
- Training: Current opt-in approaches (e.g., data licensing, collective rights management) are necessary but insufficient, as the binary decision either enables all downstream uses in perpetuity or forecloses them entirely.
- Inference: At the point of content generation, user prompts and system outputs are concretely tied to specific entities or styles. This enables fine-grained, prompt-conditional consent checks and supports dynamic negotiation of permissible uses.
- Dissemination: Rights holders may specify platform-, region-, or audience-specific constraints on generated outputs, influencing how, where, and by whom AI content may be distributed or monetized.
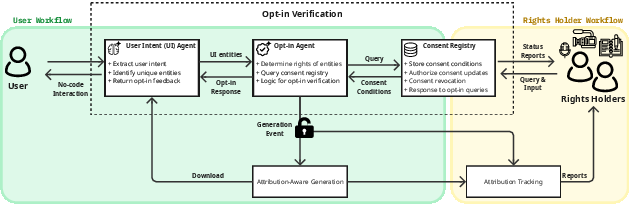
Agentic Architecture for Inference-Time Opt-in
Operating at the inference stage, the proposed architecture introduces discrete agents—User Intent Agent, Opt-in Agent, and Consent Registry—to enable systematic, entity-aware, and feedback-centric consent checking. This design supports:
Application: Case Study in Music
The music domain, characterized by multi-layered rights (composition, recording, performance) and co-authorship, is used to illustrate the complexity and the case for inference-stage control. For example, a prompt such as “Create a song from ‘Rolling in the Deep’ with Grimes’s Voice” is decomposed into referential entities (song, artist), and the system checks, via the Consent Registry, whether each element is independently and combinatorially permitted. In this scenario, Grimes's consent may permit style or voice use only in combination with original user content, not with third-party copyrighted works, and the absence of registry presence for "Rolling in the Deep" defaults to denial ([morreale_attributionbydesign_2025]; [deng_computational_2024a]).
Implications for Generative AI Governance and Future Developments
Adopting inference-time, opt-in centric frameworks would realign power dynamics between rights holders and model developers, supporting compensation models (upfront, recurring, platform-based) tied to actual economic value in production and dissemination. This architecture aligns with emerging regulatory directions seeking dataset transparency (EU AI Act), machine-readable rights management, and verifiable content provenance ([lucchi_generative_2025]; [longpre_data_2024]; [morreale_attributionbydesign_2025]).
The approach also suggests a pathway for finer-grained collective licensing, as explored in the music industry (GEMA, AI-royalty fund proposals), and aligns with technical advances in attribution, watermarking, and provenance tracking that can bridge legal-technical gaps for compliance and equitable remuneration ([jacques_protecting_2024]; [fan_can_2025]; [xu_copyright_2025]). If widely implemented, this paradigm would enable more robust, dynamic, and audit-friendly governance—potentially extending across modalities (visual, text, audio), geographies, platforms, and cultural domains.
However, several challenges remain: conflict resolution in collective consent scenarios, bias toward prominent or readily indexable entities, governance of opt-in databases across jurisdictions, resistance from creators who object to AI use categorically, adversarial attacks on opt-in infrastructure, and the limitations of current technical enforcement. Furthermore, systemic inequalities (regional, demographic, genre-based) risk being exacerbated if attribution, compensation, or recommendation systems reinforce the established status quo in cultural economies ([kelly_pressure_2024]; [lumeau_geographical_2024]).
Conclusion
The paper systematically exposes the limitations of binary, training-time opt-out mechanisms and articulates a rigorous, agentic solution for inference-time, nuanced opt-in in generative AI. By enabling explicit, context-conditional, and time-bounded consent, the proposed architecture restores rights holders’ agency, supports granular control over styles, likeness, and downstream use, and offers a viable framework for balancing innovation, creator autonomy, and equitable compensation. Adoption of such layered governance is critical both for the ethical deployment of generative AI and for sustaining a dynamic, pluralistic creative ecosystem.