- The paper establishes a statistical and empirical framework for scaling laws in Mixture-of-Experts Transformers by decomposing active capacity from routing complexity.
- It proves uniform generalization bounds via covering-number arguments that link routing combinatorics to distinct approximation and estimation errors.
- Empirical validations show that while routing overhead can limit gains, high expert specialization (large M/k ratios) significantly improves performance.
This essay provides a technical synthesis of "Generalization and Scaling Laws for Mixture-of-Experts Transformers" (2604.09175), which establishes a statistical and empirical framework for analyzing scaling behavior, generalization, and the routing-combinatorics tradeoffs in Mixture-of-Experts (MoE) Transformer architectures. The work delivers rigorous covering-number bounds, approximation theory, and scaling laws that clarify how active per-example parameter capacity and routing complexity interact, and systematically aligns theoretical predictions with empirical LLM performance and contemporary MoE scaling results.
The MoE Transformer architecture leverages conditional computation by activating only a small subset (k) of M experts per input (token), thus decoupling per-example compute from total parameter count. The statistical complexity of such models, however, fundamentally differs from dense networks, because:
- Approximation power is dictated by the active parameter budget (Nact), not the total count.
- Generalization error depends on the combinatorial space of possible routing patterns (essentially, how many ways k active experts can be chosen out of M at each position/layer).
- Compute-optimal training depends on the allocation tradeoff between data size and active capacity.
Through a sup-norm covering-number argument, the paper proves that the metric entropy decomposes additively: one term scales with the effective active parameter count, while a MoE-specific routing overhead term (proportional to klog(eM/k)) accounts for routing pattern multiplicity. This decomposition is critical, as it isolates the statistical regularization from the combinatorics induced by conditional computation.
Assuming input data concentrate on a d-dimensional C1 manifold in RD and Cβ target functions, the paper demonstrates that MoE Transformers achieve minimax-optimal approximation rates on M0-dimensional domains, with the dominant exponent governed by the intrinsic rather than ambient dimension (recovering the M1 scaling). The generalization bound in L2-risk for empirical risk minimization under squared loss is:
M2
This result clarifies three principal sources of error:
- Approximation error: controlled by the active parameter budget, scaling as M3.
- Estimation error: proportional to M4 (favorable in overparameterized, data-limited regimes).
- Routing complexity: additive, scaling as M5, conservative due to the union-bound over possible routing patterns.
This bound grounds statistical reasoning for architecture design: growth of the expert pool (M6) at fixed M7 yields only a logarithmic improvement, unless specialization enables effective reduction in function class complexity beyond worst-case.
Scaling Laws: Data, Model, and Compute
The derived scaling laws connect the theory directly with regimes of practical training:
- Data scaling (fixed model): error declines as M8, M9. MoEs match dense transformer scaling in exponents but measure the axis against Nact0.
- Model scaling (fixed data): in the approximation-dominated regime, risk scales as Nact1, Nact2.
- Compute-optimal frontier: at fixed total compute Nact3, optimal active parameter and data allocation (with Nact4) yields loss decay as Nact5.
A major insight is the existence of two scaling regimes depending on the relative weight of the routing term:
- For small Nact6, or Nact7, the routing overhead is negligible, and power-law scaling dominates.
- For large Nact8, the routing term can dominate, creating a data inefficiency floor.
Routing Complexity and Expert Specialization
Critically, the analysis exposes the routing complexity threshold:
However, expanded routing ablation uncovers an empirical reversal: for sufficiently large k4, performance improves as k5 increases, indicating gains from expert specialization which are not predicted by the conservative, uniform analysis. Thus, while the theoretical bounds certify only logarithmic improvements, actual gains can be substantial and are data-dependent, motivating further research on data-dependent, specialization-aware generalization bounds for MoEs.
Empirical Validation and Alignment with Prior MoE Scaling Work
The statistical theory is benchmarked against systematic scaling experiments across TinyStories, WikiText-103, and OpenWebText, with empirical exponents extracted from both model and data scaling. The observed exponents largely match theoretical predictions using estimated intrinsic dimensions, confirming that active capacity—not total parameter count—controls practical scaling dynamics, especially in regimes where the routing term is subdominant.
Comparison to recent empirical MoE scaling laws such as those from “Joint MoE Scaling Laws” [ludziejewski2025joint] and “Scaling Laws for Fine-Grained MoE” [Krajewski2024FineGrainedMoE], reveals close structural alignment: the theoretical exponents satisfy the same power law relationships, and deviations in empirical exponents (e.g., amplified data efficiency at large expert counts) are consistently explained either by non-worst-case specialization or by practical training heuristics beyond the pessimistic union-bound theory.
Implications and Forward Directions
The paper contributes a rigorous reference point for statistical reasoning about MoE Transformers, with implications for both theory and practice:
- For rigorous design: architectural choices affecting k6, k7, k8, and k9 can now be justified or critiqued via their explicit effects on the error decomposition and routing term.
- For practical deployment: the results demarcate settings where MoEs offer dense-model scaling benefits at lower per-example compute, and clarify when such benefits saturate unless specialization emerges.
- For theory advancement: the strong empirical evidence of gains from specialization at high M0 advocates for data-dependent generalization theory or optimization-dependent analyses, beyond uniform convergence.
Potential theoretical extensions include developing lower bounds for MoE architectures under adaptive or data-dependent routing, or characterizing scaling in the presence of routing regularization, load balancing, or online expert pruning.
A representative figure demonstrates how validation loss behaves with varying routing complexity and expert pool sizes, supporting the two-phase regime predicted:
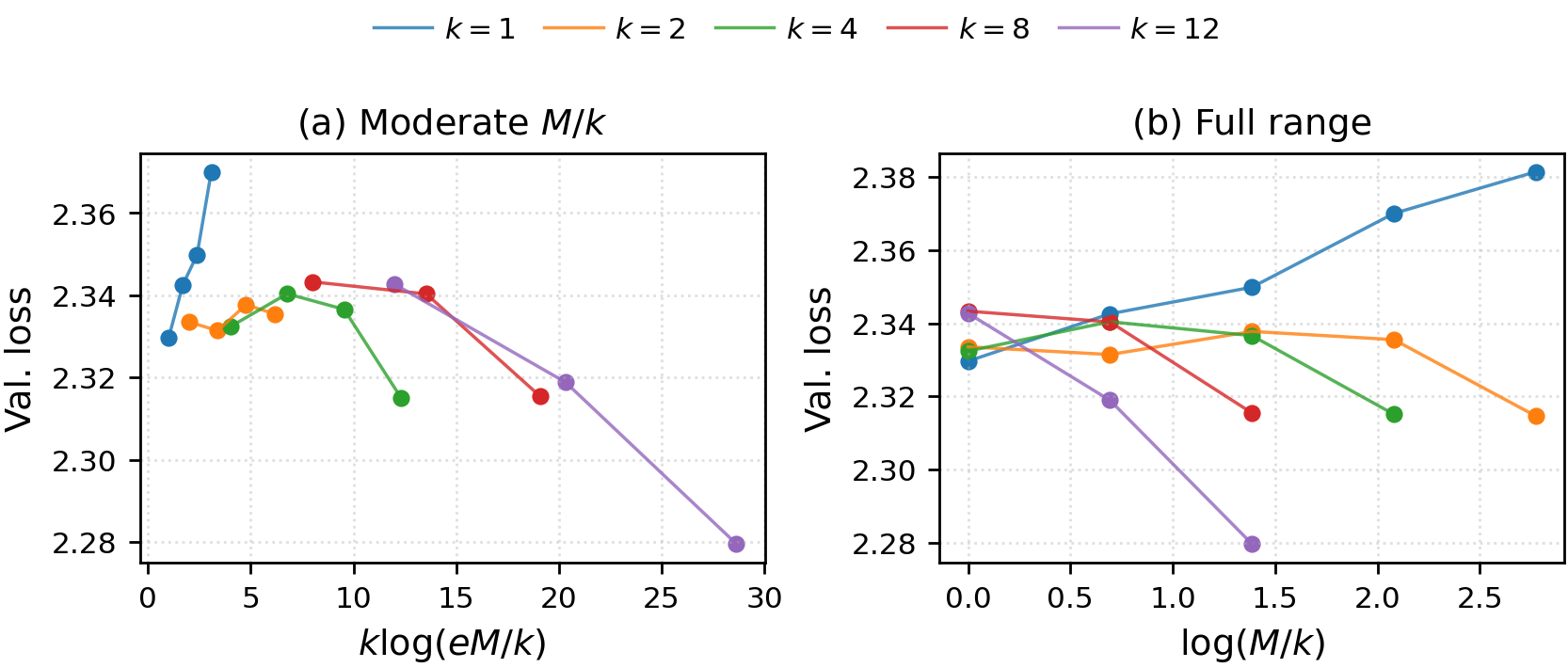
Figure 1: Routing ablation across M1: In the moderate regime, loss aligns with routing complexity M2; for larger M3, empirical loss improves, evidencing specialization-driven performance increases not captured by worst-case theory.
Conclusion
This work delivers a mathematically robust and empirically validated framework explicating the tradeoffs between active capacity and routing complexity in Mixture-of-Experts Transformers. By precisely separating parameter-driven generalization from routing-induced combinatorics, it provides practitioners and theorists with a comprehensive toolkit to understand, benchmark, and improve MoE architectures under scaling. While worst-case theory certifies only modest improvements from expert pool growth beyond active parameter scaling, the empirical regime evidences the impact of specialization and structured routing—pointing to fertile ground for future advances in sparse model generalization theory and systems design.
References
- "Generalization and Scaling Laws for Mixture-of-Experts Transformers" (2604.09175)
- "Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient" [ludziejewski2025joint]
- "Scaling Laws for Fine-Grained Mixture of Experts" [Krajewski2024FineGrainedMoE]
- "Scaling Laws for Neural LLMs" (Kaplan et al., 2020)
- "Training compute-optimal LLMs" [Hoffmann2022]
- "Efficient Scaling of LLMs with Mixture-of-Experts" [du2022glam]
(Additional references and empirical protocols are provided in the original paper.)

