- The paper introduces Masked Dual Path Distillation (MDPD), combining dual-path feature and logits distillation for efficient transfer learning.
- It employs a lightweight, trainable side network that is discarded after training, reducing inference latency by at least 25.2% while maintaining accuracy.
- Empirical results on visual, language, and multimodal tasks demonstrate state-of-the-art performance and superior memory efficiency compared to PETL and traditional METL approaches.
Memory-Efficient Transfer Learning via Masked Dual Path Distillation
Motivation and Background
Transfer learning with large pre-trained models underpins state-of-the-art results across vision, language, and multimodal tasks. Fully fine-tuning these large backbones, however, is computationally prohibitive, incurring excessive memory cost and substantial risk of overfitting in data-scarce regimes. Parameter-efficient transfer learning (PETL) schemes, such as Adapter tuning, LoRA, or prompt-based approaches, offer trainable parameter reduction by updating only subsets or injecting small modules, but still incur significant memory overhead because their gradients traverse the entire backbone during backpropagation.
Memory-efficient transfer learning (METL) addresses these shortcomings by introducing lightweight side networks parallel to the backbone. During adaptation, only the side network is updated while the backbone is kept frozen, dramatically reducing the memory required for gradient storage. However, the critical limitation of existing METL approaches is their reliance on the side network during inference, introducing additional latency and memory cost, thus undermining the primary goal of total efficiency.
Masked Dual Path Distillation: Methodology
"Memory-Efficient Transfer Learning with Fading Side Networks via Masked Dual Path Distillation" (2604.09088) introduces Masked Dual Path Distillation (MDPD), an approach that combines efficient fine-tuning with zero-inference overhead from the side network. The approach leverages a dual-path knowledge distillation framework and a hierarchical feature-based distillation strategy to maximize transfer efficiency and optimize backbone adaptation.
The MDPD training pipeline comprises two intertwined networks: the frozen backbone and a lightweight, trainable side network. Both networks, initialized from the pre-trained model, interact through two main distillation mechanisms:
- Feature-Based Distillation (Backbone→Side Network): Intermediate features from the backbone are used as targets for corresponding layers in the side network. Dimensionality mismatches between the backbone and side network outputs are reconciled via low-rank bottleneck modules to maintain parameter efficiency.
- Logits-Based Distillation (Side Network→Backbone): The side network, optimized for the downstream task, produces logits that supervise the backbone's task-specific output layer. The backbone in this phase is partially unfrozen at normalization layers and the output head, allowing for minimal but sufficient adaptation.
A unique attribute of MDPD is the mutual, alternating teacher-student dynamic between backbone and side network, which enhances both generalization and downstream performance. Most importantly, after training, the side network is discarded; only the backbone, now independently capable of downstream inference, is deployed. This ensures that inference-time memory and computational cost are equivalent to that of PETL approaches, without their respective training memory bottlenecks.
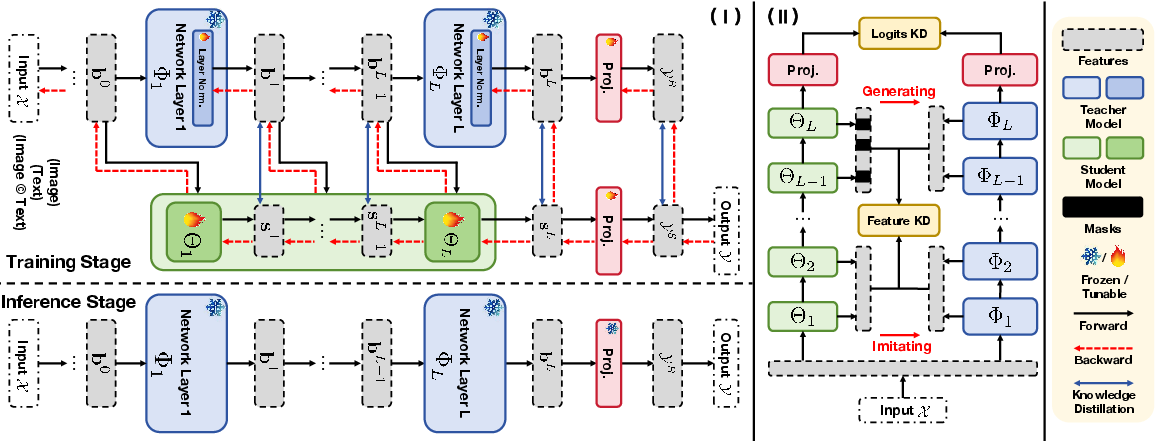
Figure 1: Overview of MDPD. During training, backbone and side network mutually distill features and logits; inference uses the backbone only, maximizing efficiency.
Hierarchical Feature Distillation
A critical observation is that feature distributions between backbone and side network diverge substantially in deep layers, especially regarding attention distributions. For shallow layers—where attention patterns are well-aligned—direct feature imitation is effective. In contrast, for deep layers, the authors employ masked feature generation: selected tokens of side network features are replaced by learned mask tokens, and a simple convolutional generator attempts to reconstruct the backbone's deep features based on these masked representations.
This strategy balances the conflicting demands of semantic alignment and information diversity, ensuring stability in shallower layers while maximizing adaptation flexibility and representational richness in deeper layers.
Empirical Results
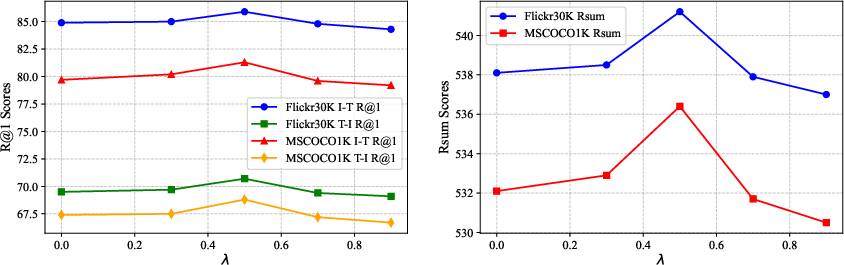
MDPD is extensively validated on visual, language, and multimodal tasks, including ITR (Flickr30K, MSCOCO), VTR (MSR-VTT, MSVD), VQA (VQAv2, GQA), visual grounding (RefCOCO, RefCOCO+, RefCOCOg), as well as the GLUE and VTAB-1K benchmarks for language-only and vision-only evaluation.
Key strong claims substantiated by empirical results include:
Theoretical and Practical Implications
MDPD establishes that side network architectures for METL can be relegated entirely to the training stage, negating their inference burden. This property brings METL paradigms in line with parameter-efficient approaches for real-world, resource-constrained deployment. The paper provides detailed analysis of memory usage during backpropagation, formalizing why prior PETL methods cannot surpass certain theoretical memory bounds, while side-network based METL approaches do, and how MDPD maximizes these gains.
The dual-path, hierarchical distillation concept provides a general template for future transfer learning research, with implications beyond memory efficiency: More fine-grained teacher-student strategies may improve knowledge transfer in self-supervised representation or continual learning contexts.
Practically, MDPD's architecture-agnostic design and validated performance on both unimodal and multimodal settings signal robust applicability to large-scale, real-world AI systems that must balance adaptation capacity against stringent memory and time constraints.
Conclusion
Masked Dual Path Distillation provides a rigorously substantiated approach to memory-efficient transfer learning, resolving the inferential inefficiency inherent in prior METL architectures. The combination of mutual distillation, feature masking, and side network fading enables fast, accurate, and resource-transparent deployment of adapted models. This framework points toward increasingly efficient fine-tuning paradigms and suggests further research directions in distillation topology, masking policies, and teacher-student dynamics for both unimodal and multimodal foundation model adaptation.