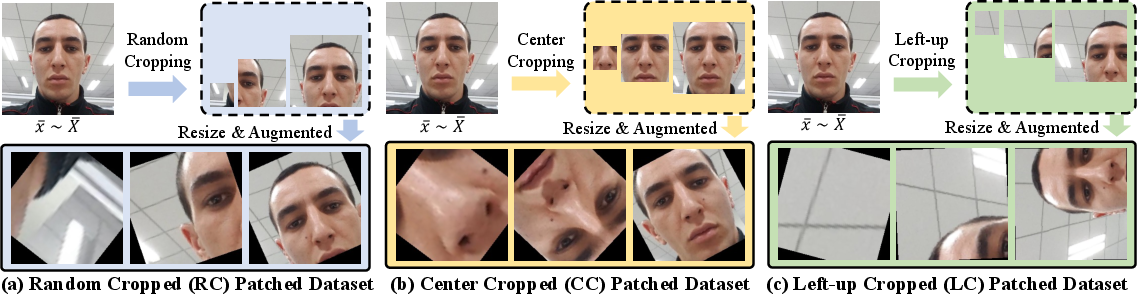
- The paper introduces a novel framework leveraging a PCGAN for artifact pattern augmentation and a patch-based multi-tasking network to boost generalization.
- Methodologically, it disentangles facial content from spoof artifacts using spatial skip connections and patch-wise adversarial losses.
- Experimental results show a significant reduction in ACER and improved AUC, demonstrating robust performance under cross-domain and partial attack scenarios.
Domain-Generalizable Face Anti-Spoofing with Patch-Based Multi-Tasking and Artifact Pattern Conversion
Introduction and Problem Context
Face recognition (FR) systems have become ubiquitous in security-critical applications, prompting the persistent challenge of presentation attacks (PAs) and digital manipulation (e.g., deepfakes). The reliability of face anti-spoofing (FAS) algorithms is severely constrained by the domain diversity and scale of available datasets. Conventional models exhibit pronounced performance degradation under cross-domain and unseen attack conditions, primarily due to overfitting to specific devices, environments, and artifact distributions. This work addresses these critical limitations through two core innovations: a Pattern Conversion GAN (PCGAN) for artifact-level augmentation and a Patch-based Multi-tasking Network (PMN) for fine-grained detection robustness.
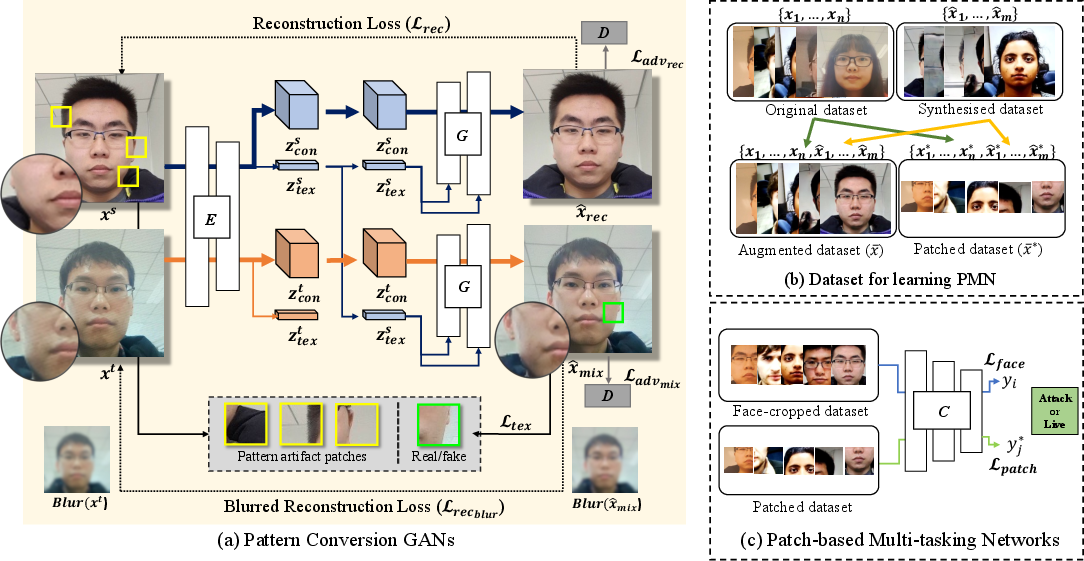
Figure 1: Overall framework illustrating (a) disentanglement and conversion of spoof artifact patterns by combining spatial facial content features and artifact representations from different images, (b) PCGAN-based data augmentation and patch dataset generation, (c) Patch-based Multi-tasking Network for joint learning from patched and full face images.
Methodology
Pattern Conversion GAN (PCGAN)
PCGAN facilitates explicit disentanglement between facial content and spoof artifact patterns—mathematically, mapping input images x∈R3×1024×1024 into content (zcon) and artifact (zpat) latent codes. Unlike prior generative approaches (e.g., StyleGAN-based domain adaptation [styleassemble], cycle-consistent transfer [yadav2021cit]), PCGAN (based on modified swapping auto-encoders [SAE]) employs minimal downsampling in the encoder to preserve high-frequency artifact details (e.g., moiré, dot matrix, screen glare):
- Generator: Integrates zcon via spatially-aware skip connections and injects zpat through AdaIN at each CNN block.
- Discriminator/Patch Discriminator: Patch-wise adversarial losses enforce artifact-specific fidelity.
PCGAN is trained with joint reconstruction, blurred reconstruction, adversarial, and patch-disentanglement losses. The blurred loss enforces content consistency under artifact translation by downsampling, thus suppressing high-frequency artifact variance while retaining semantic identity.

Figure 2: PCGAN can remove (c) or inject (d) artifact patterns, as visualized by Canny and Hough transforms, demonstrating effective artifact-level manipulations across facial samples.
Patch-Based Multi-Tasking Network (PMN)
PMN incorporates CLIP-based multimodal encoders, MLPs, and multi-task heads. This network jointly supervises both global-face and randomly-cropped patch images to enhance robustness against partial or local attacks (e.g., paper edges, display corners):
Synthesized Data Augmentation and Patch Training
PMN is trained using both original images and PCGAN-augmented images, including live-to-spoof and spoof-to-live conversions. This augmentation bridges both label and domain spaces, ensuring the detector is robust not only to seen artifact variations but also to synthetic, unseen artifacts.
Experimental Results
Benchmark Evaluation and Analysis
The proposed method is evaluated on several established FAS datasets under domain generalization protocols, including OULU-NPU, CASIA-FASD, MSU-MFSD, Replay-Attack, CASIA-SURF, CASIA-SURF CeFA, and WMCA. Key metrics are ACER (Average Classification Error Rate) and AUC.
Strong Numerical Claims:
- On cross-domain FAS (e.g., OCM→I), PCGAN+PMN achieves an ACER of 3.33%, outperforming leading CLIP-based methods without relying on extra external datasets (e.g., CelebA-Spoof).
- In large-scale cross-ethnicity benchmarks (e.g., CSW), the approach yields the best average ACER (10.78%) and AUC (95.58%) among strong baselines (Table: tab:csw).
- Even when trained without real live images but only PCGAN-synthesized artifact-free “live” samples, performance remains competitive (average ACER: 5.70%), emphasizing effective semantic preservation in artifact removal.

Figure 4: Grad-CAM visualizations show that the proposed method with both PMN and PCGAN (d) focuses activation on spoof-affected regions, outperforming ResNet50 baselines and PMN-only variants, especially for partial attacks.
Ablation and Component Analysis
Computational Cost
The training addition of GAN-based sample generation (109M params, 95G FLOPs) is negligible during inference, as only the CLIP-based detector (86M params, 17.6G FLOPs) is used. This renders the approach computationally efficient relative to diffusion-based augmentation approaches (e.g., AG-FAS).
Implications and Future Directions
The artifact-centric approach of PCGAN, coupled with patch-level multi-task supervision, advances the state of domain-generalizable FAS through:
- Explicit artifact disentanglement: Facilitates more realistic and controllable augmentation of artifact patterns, crucial for robustness in the open world where new spoofing mediums and techniques are regularly encountered.
- Patch-level reasoning: Enables local supervisor signals for detection of partial, mixed, or subtle spoofs, outperforming global-only or domain-adaptive baselines.
- Synergistic augmentation: Combination of real and synthetic data is essential; synthetic-only models do not match the fidelity and diversity required for full generalization.
Potential future directions include: expanding the diversity and sophistication of synthetic artifact patterns (possibly through larger generative models or diffusion frameworks), developing temporal or video-based FAS leveraging artifact-level augmentation, extending patch-based multi-tasking to non-facial biometrics, and investigating cross-modal feature disentanglement.
Conclusion
This work introduces a domain-generalizable face anti-spoofing solution, leveraging artifact-focused data augmentation through PCGAN and patch-based multi-task learning by PMN. The methodology demonstrates compelling improvements in cross-domain generalization, partial attack robustness, and computational efficiency. The explicit focus on artifact pattern manipulation and patch-level supervision addresses both theoretical and practical constraints in FAS. Extending this paradigm to richer generative schemes and broader biometric modalities represents a logical and promising trajectory for future investigation.