- The paper introduces ASTRA, an adaptive semantic tree reasoning architecture that significantly enhances complex table QA through hierarchical and symbolic-textual methods.
- It combines three adaptive strategies—Direct Semantic Parsing, Symbolic Reference Encoding, and Programmatic Structure Synthesis—augmented by an evaluator-guided refinement loop to ensure high structural integrity and information coverage.
- Empirical evaluations show that ASTRA outperforms existing models on benchmarks like AIT-QA, HiTab, and SSTQA, achieving higher accuracy and reducing representation gaps.
Adaptive Semantic Tree Reasoning for Complex Table QA: An Expert Synthesis of the ASTRA Architecture
Motivation and Problem Setting
Table QA in the context of LLMs presents significant challenges when confronting complex tables characterized by hierarchical headers, irregular layouts, and semantic dependencies. Linear serialization methods (e.g., Markdown/HTML) and physical tree approaches fail to capture hierarchical and semantic nuance, induce representation gaps, and lack symbolic reasoning transparency. Rule-based tree parsers are brittle, while relational and triple-based decompositions introduce data sparsity or redundancy and obscure logical structure. ASTRA (Adaptive Semantic Tree Reasoning Architecture) directly targets these limitations by proposing an LLM-centric, adaptive semantic tree pipeline integrated with hybrid reasoning.
Design Criteria for Robust Table Serialization
ASTRA formulates four rigorous desiderata for serialization. Explicit Hierarchy and Semantic Context address the loss of multi-level dependencies and latent entity-attribute associations. Representation Alignment bridges the modality gap innate to LLMs by constructing sequentialized, natural language-aligned structures. Symbolic Compatibility ensures every serialization is directly amenable to code-based reasoning, guaranteeing verifiable, traceable numerical results and supporting provenance audits. Schema Flexibility is preserved with adaptive strategies that generalize beyond canonical forms, eschewing redundancy and maintaining compactness across arbitrary layouts.
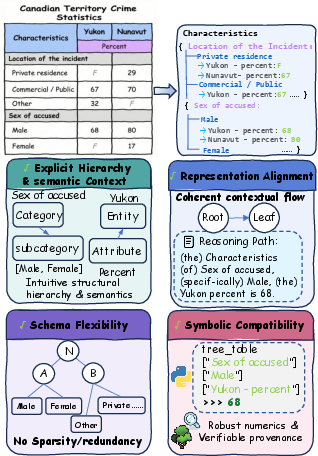
Figure 1: Key desiderata for robust table serialization and their instantiation in AdaSTR.
ASTRA Overview: AdaSTR and DuTR
Adaptive Semantic Tree Reconstruction (AdaSTR)
AdaSTR performs hierarchical semantic parsing, schema detection, and context-sensitive tree synthesis. Its adaptive mechanism dynamically chooses among three tree construction strategies:
- Direct Semantic Parsing (DSP): End-to-end LLM-based synthesis for moderately sized, structured tables.
- Symbolic Reference Encoding (SRE): Coordinate-based symbolic scaffolds for content-dense tables, optimizing token and structural efficiency.
- Programmatic Structure Synthesis (PSS): Loop-driven script generation for hyperscale tables with repeated patterns, optimizing instance expansion.
Each strategy is augmented by an Evaluator-Guided Refinement Loop measuring Information Coverage and Structural Integrity, iteratively correcting hallucinations and omissions until prescribed thresholds are satisfied. This modularity ensures both scalability and representational fidelity.
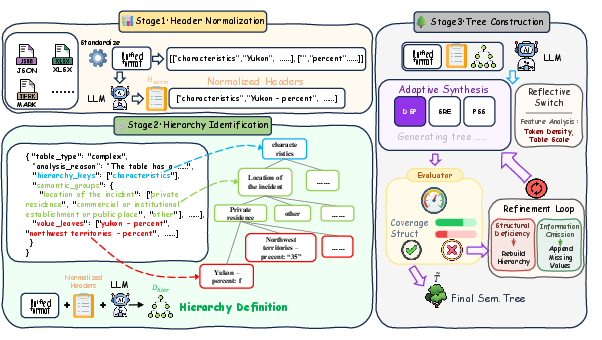
Figure 2: Overview of the Adaptive Semantic Tree Reconstruction process.
Dual-Mode Tree Reasoning (DuTR)
Upon semantic tree construction, DuTR enables hybrid reasoning via:
- Tree-based Textual Navigation: Dynamic path traversal, query-adaptive directionality (leaf-to-root or root-to-leaf), embedding-guided retrieval, and LLM semantic validation. This ensures high recall on evidence localization.
- Symbolic Tree Manipulation: Abstraction of the semantic tree to a minimal, value-stripped skeleton prior to code generation. The system supports few-shot program induction, handles a spectrum of logical and aggregation queries, and incorporates a Self-Correction execution loop to autonomously repair code against execution failures.
A lightweight LLM-based answer selector resolves discrepancies between the two paradigms, optimizing for factual consistency with input evidence.
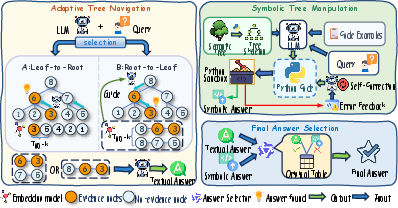
Figure 3: Overview of the Dual-Mode Tree Reasoning process.
Empirical Evaluation
ASTRA is thoroughly benchmarked on AIT-QA, HiTab, and SSTQA, covering high-complexity hierarchical, semi-structured, and domain-specialized table settings. Backbone LLM is consistently controlled (DeepSeek-V3-250324), and robust QA accuracy is measured using consensus-validated LLM-as-a-judge protocols.
Strong Numerical Results and Mode Complementarity
- AIT-QA: 91.6% (ASTRA, adaptive selection) versus 89.1% (OpenAI o3) and 90.4% (GraphOTTER).
- HiTab: 90.1% (ASTRA, adaptive selection) versus 85.3% (OpenAI o3), 88.8% (GraphOTTER), and 49.0% (ST-Raptor).
- SSTQA: 81.9% (ASTRA, adaptive selection) versus 78.2% (OpenAI o3), 71.5% (GraphOTTER).
Oracle (ideal per-query selection) upper-bounds are 93.5% (AIT-QA), 94.1% (HiTab), 86.1% (SSTQA). Notably, there is significant complementarity between textual and symbolic modes: textual excels in semantic-nuance queries, symbolic dominates arithmetic and logical aggregation tasks.
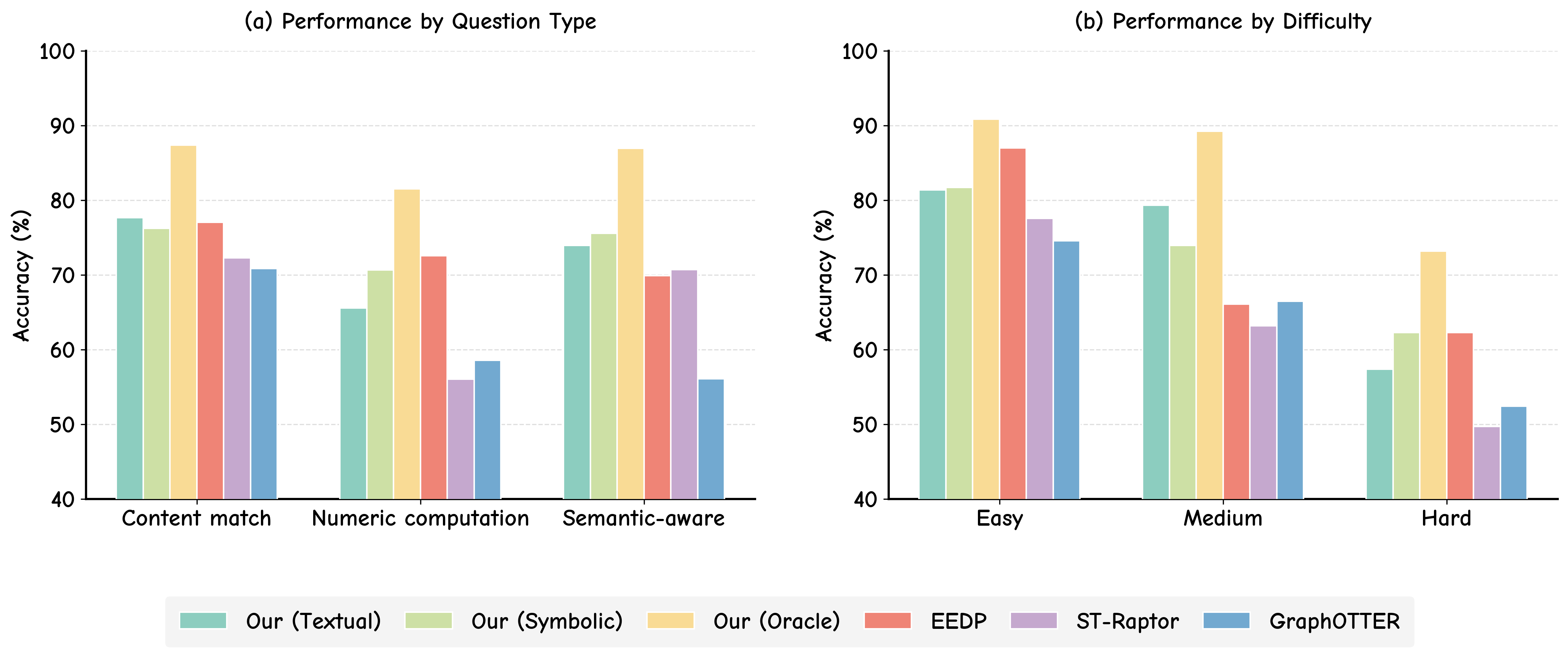
Figure 4: Performance breakdown by question type and difficulty for DuTR and baselines.
Comparative Analysis and Ablation
An explicit ablation shows AdaSTR's Evaluator-Guided Loop is critical (coverage drops from 0.929 to 0.745 without it), and adaptive construction strategies are essential for robustness (min coverage rate drops to 0.153 when disabled). DuTR's semantic path navigation—embedding-based retrieval and dynamic traversal—yields gains up to +8.5% over static traversal. Removal of symbolic code examples or skeleton abstraction results in substantial drops, especially for sub-10B scale models.
Intrinsic analysis revealed that mere tree-based serialization—without advanced reasoning—already surpasses raw table prompting by 7–8%, underscoring the fundamental representational advantage and the validity of hierarchy-centric serialization.
Efficiency and Scalability
ASTRA shows lower online latency and faster construction (e.g., 43s construction/6s QA on HiTab) compared to ST-Raptor (139s/26s). While GraphOTTER's decoding is fast, its inference is unscalable for session settings. Amortized, ASTRA is preferable for multiturn analysis as soon as N≥3 queries per table.
Case Studies and Diagnostics
Visual case studies reveal AdaSTR’s explicit parent-child linkage counteracts enumeration errors, representation gaps, and hallucinations exhibited by triple-based (GraphOTTER), rule-based tree (ST-Raptor), and purely textual prompting (EEDP) methods. ASTRA’s symbolic reasoning enforces dictionary-structure fidelity, yielding exact answers under complex schema conditions.
ASTRA further outperforms relational transformation baselines (RelationalCoder, TabFormer, Chain-of-Table) on EM in complex settings, with superior structure-logic isomorphism. Its representation methods systematically outperform uniform relational flattening, particularly as the complexity of header hierarchies and block structures increases.
Figure 5: Visualization of the Operating Expenses Analysis table.
Evaluation Metrics and Quality Correlates
Empirical evidence demonstrates a high correlation between ASTRA’s Information Coverage/Structural Integrity metrics and downstream QA accuracy, justifying their use in metric-guided refinement and adaptive cutoffs for self-correction.
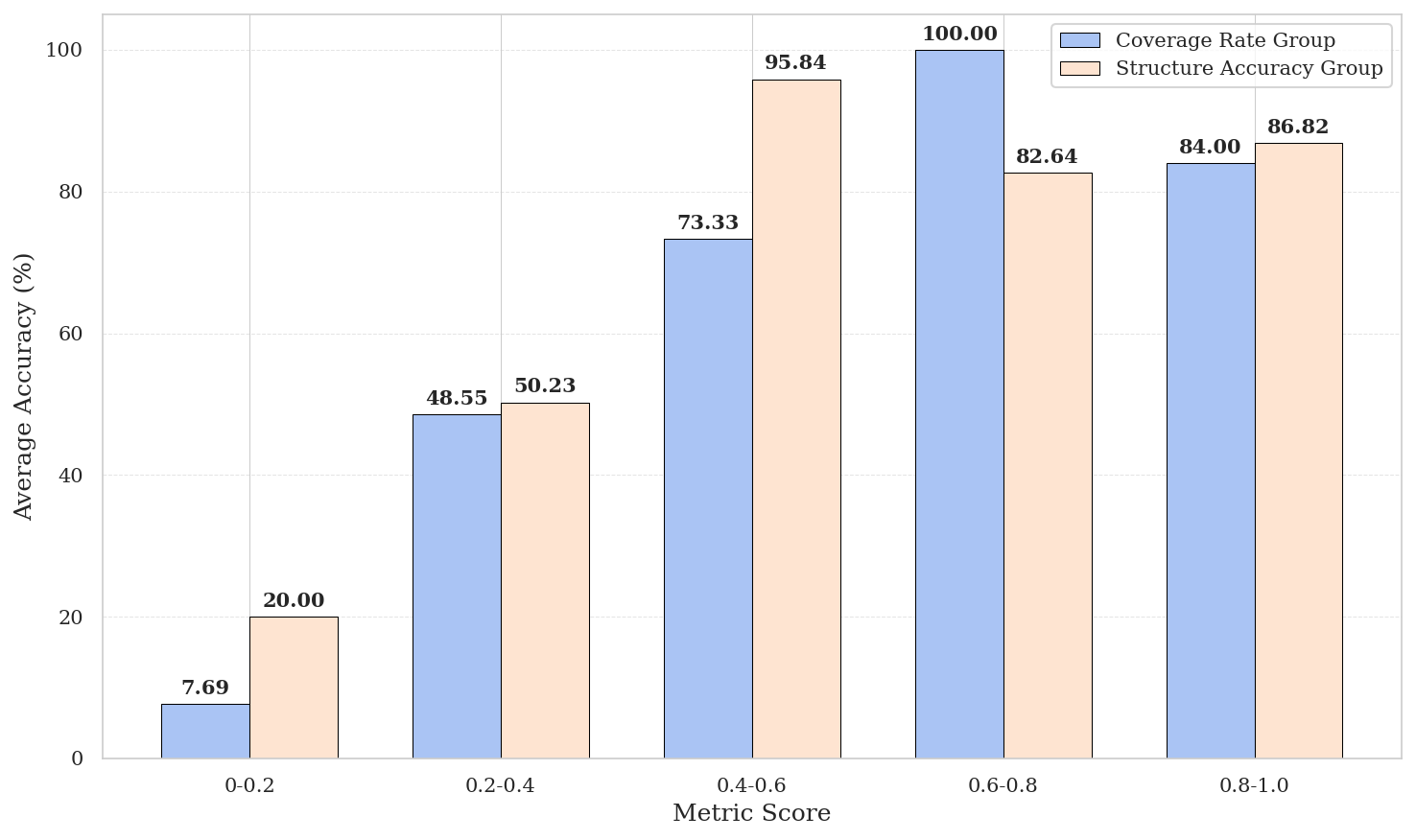
Figure 6: Relationship between evaluation metric scores (information coverage and structure integrity) and downstream QA accuracy across score bins.
Comprehensive failure analysis indicates symbolic mode is primarily affected by structure misalignment (36.7%), while textual suffers from arithmetic hallucination (20%) and retrieval bias, but ASTRA's adaptive selection substantially ameliorates these error regimes. Consensus error is in many cases attributable to dataset annotation errors, not true model failure.
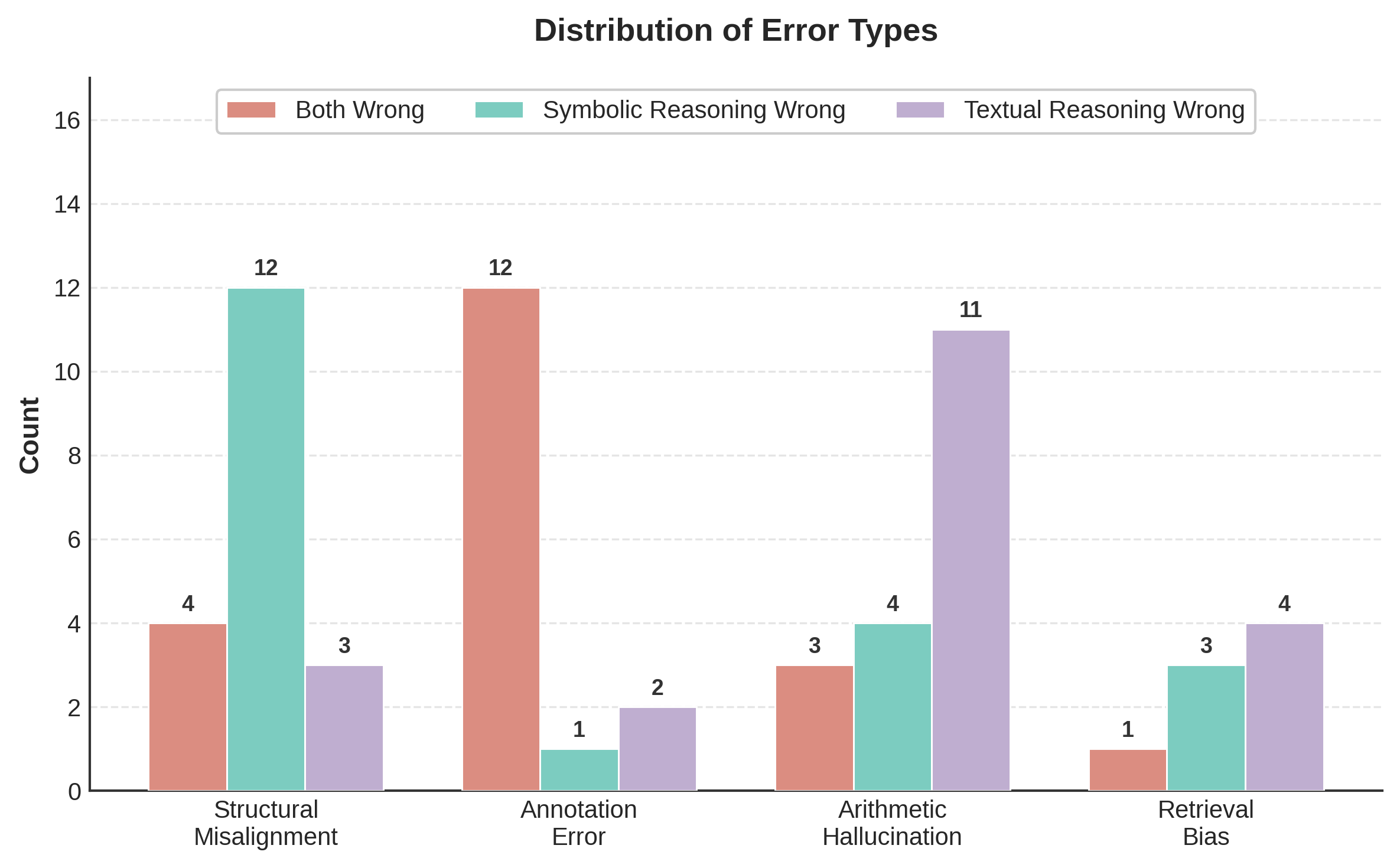
Figure 7: Statistics of error categories by reasoning failure mode.
Theoretical and Practical Implications
ASTRA's architecture highlights the necessity of aligning data representation with LLM reasoning priors, ensuring executions are both semantically faithful and computationally verifiable. By coupling explicit logical serialization with dual-mode reasoning, ASTRA bridges natural language understanding and symbolic computation. This design enables robust generalization across both proprietary and open-source models, reduces cognitive load by restoring local context, and substantially lowers hallucination rates compared with textual-only and symbolic-only approaches.
The directionality of the research paves the way for several future developments, such as multimodal fusion to capture visual attribute cues, generalization to ultra-complex multi-table scenarios (beyond intra-table logic), and dynamic agentic routines for active inspection and code repair in limited-resource settings.
Conclusion
ASTRA advances the state of the art in complex Table QA, establishing that adaptive, hierarchy-aware semantic tree serialization is central to maximizing reasoning accuracy for LLMs. Dual-mode symbolic-textual reasoning unlocks performance unattainable by prior graph, linear, or rule-based approaches. The introduction of tree centricity as the unifying interface for both natural language evidence retrieval and program synthesis sets a new benchmark in aligning LLM architectures with the semantic and operational requirements of heterogeneous tabular data.
Reference: "ASTRA: Adaptive Semantic Tree Reasoning Architecture for Complex Table Question Answering" (2604.08999)

