- The paper introduces GeoMMBench and GeoMMAgent to rigorously benchmark and advance expert-level multimodal intelligence in geoscience and remote sensing.
- It evaluates 36 MLLMs against expert-level tasks, revealing significant performance gaps with human experts and demonstrating GeoMMAgent’s superior 88.4% test accuracy.
- The proposed multi-agent framework decomposes complex geospatial tasks into retrieval, perception, and reasoning stages, underscoring the importance of modularity for advanced AI.
GeoMMBench and GeoMMAgent: Advancing Expert-Level Multimodal Intelligence in Geoscience and Remote Sensing
Motivation and Benchmark Design
The increasing sophistication of multimodal LLMs (MLLMs) has catalyzed interest in domain-specific artificial general intelligence (AGI), particularly for highly specialized fields such as geoscience and remote sensing (RS). However, the evaluation of these capabilities lags behind other domains, primarily due to a lack of comprehensive, multidisciplinary benchmarks that encompass the broad spectrum of knowledge, sensing modalities, and reasoning required for expert-level interpretation in Earth observation contexts.
GeoMMBench addresses this gap by presenting a rigorously curated, expert-authored benchmark that comprehensively assesses MLLMs across four primary disciplines (RS, photogrammetry, GIS, GNSS) and a heterogeneous set of sensor modalities, including optical, hyperspectral, SAR, LiDAR, DEM, and thermal imagery. The benchmark comprises 1,053 image-based multiple-choice questions designed to require not only perceptual and low-level visual understanding but advanced domain-specific reasoning, spatial analysis, and application of theoretical knowledge.
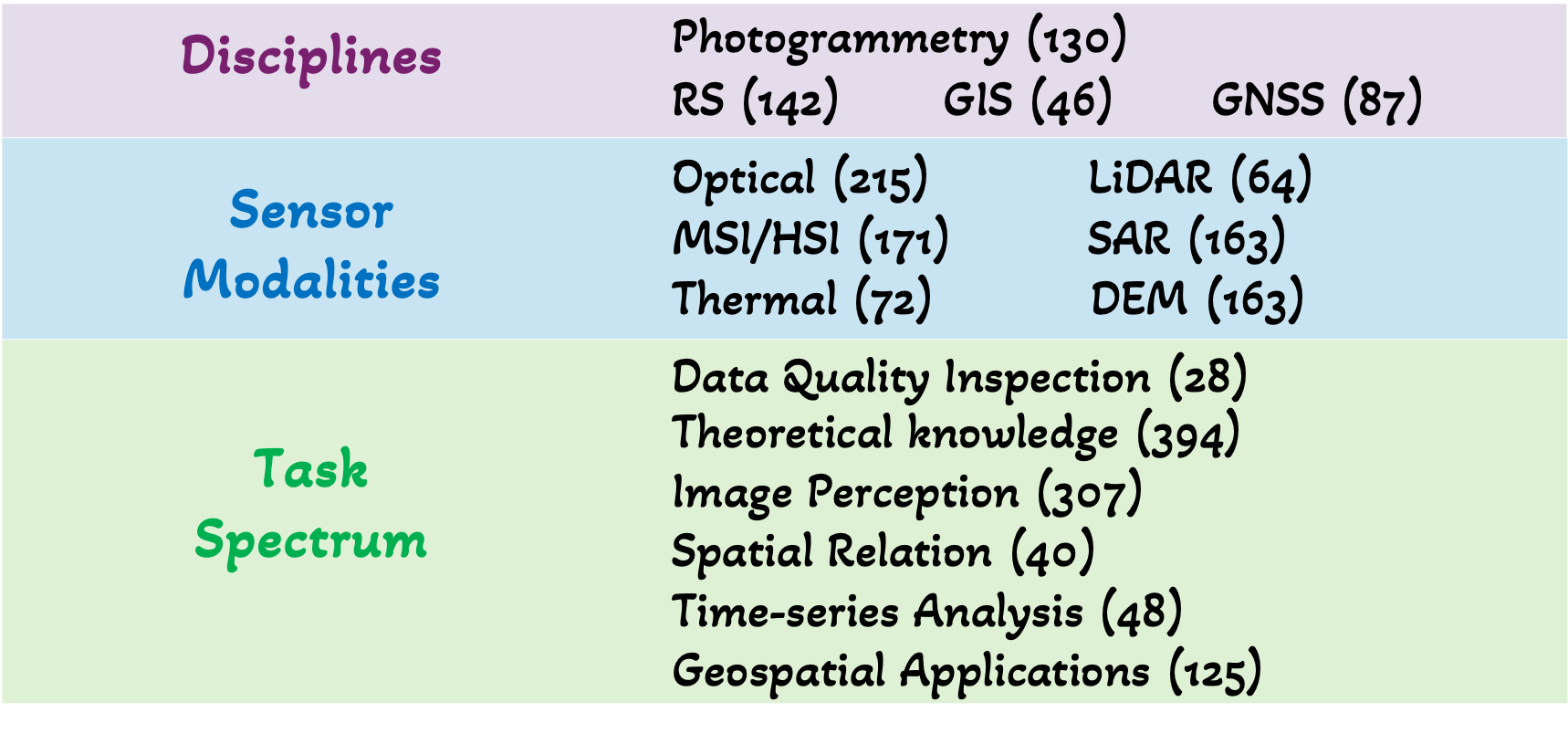
Figure 1: Expert-level knowledge dimensions in geoscience and RS covered in GeoMMBench.
The inclusion of complex, integrative questions targeting geospatial relationships, sensor properties, theoretical principles, and high-level applications ensures a more rigorous and holistic evaluation of Expert AGI capabilities compared to prior RS benchmarks, which have generally been limited to classification or object detection over RGB imagery.

Figure 2: Example GeoMMBench questions spanning multiple RS disciplines, sensor modalities, and reasoning task types.
Benchmark Construction and Methodology
GeoMMBench's construction leveraged domain expertise from geoscience professionals (including PhDs and graduate researchers) who systematically defined and reviewed the scope, content, and evaluative axes. Each item in the benchmark demands image-dependent reasoning, with a rigorous review process ensuring the exclusion of samples solvable by text-only inference and those with ambiguous phrasing or inaccurate solutions.
Benchmarked models are evaluated under standardized, zero-shot settings, and human experts provide a reference baseline. The task spectrum spans foundational concepts, image quality and preprocessing, mid-level perception (including sensor modality discrimination), spatial and temporal reasoning, and domain-specific application analytics.
Empirical Evaluation of Multimodal Models
Thirty-six MLLMs—including both open-source and proprietary systems—were assessed on GeoMMBench. The evaluation reveals persistent deficiencies in current models:
- Current MLLMs remain far from expert-level performance: Human experts achieve a validation accuracy of 86.5%, while the best closed-source models (e.g., Gemini-1.5 Pro) attain 70.7%. The strongest open-source model (Qwen3-VL-30B) reaches 66.7%, demonstrating measurable progress but underscoring the challenging nature of the tasks.
- GeoMMAgent substantially outperforms all baselines: The proposed GeoMMAgent system achieves 88.4% test accuracy, exceeding human experts on validation and outperforming all evaluated models by considerable margins.
- Domain-specialized models (GeoChat, TeoChat, LHRS-Bot, VHM) underperform relative to generalist advanced MLLMs, revealing that current approaches to instruction tuning and dataset curation in domain-specific contexts remain inadequate for enabling expert-level reasoning across the diversity of relevant tasks.
GeoMMAgent: Multi-Agent Architecture for Expert Geospatial Intelligence
Recognizing the inherent limitations of single-model architectures for complex geospatial reasoning and perception, the authors introduce GeoMMAgent, a modular, extensible multi-agent framework that orchestrates domain-specific tools and MLLMs across three core stages: retrieval, perception, and reasoning.
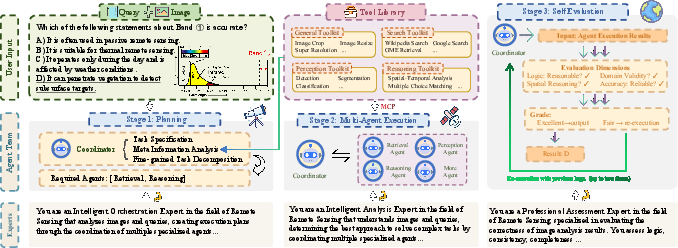
Figure 3: Overview of GeoMMAgent’s multi-agent planning, execution, and self-evaluation loop for expert-level geospatial task solving.
GeoMMAgent is realized via:
- Planning: A coordinator agent decomposes complex tasks based on the input query and image, generating structured plans for downstream execution.
- Execution: Subtasks are delegated to specialized agents (retrieval, perception, reasoning), leveraging a plug-and-play toolkit library encompassing model-based detectors/classifiers, semantic retrieval engines, and reasoning-oriented LLMs.
- Self-Evaluation: The reasoning trace and outputs are reviewed, validated, and iteratively refined to ensure logical consistency and correctness.
Ablation studies in the supplementary material indicate that removing perception, reasoning, or knowledge modules significantly degrades performance, confirming the necessity of agent modularity and functional specialization in achieving near-expert accuracy.
Diagnostic Error Analysis and Identified Failure Modes
Despite progress, detailed error analysis indicates several persisting challenges for SOTA models, many of which are systematically revealed via GeoMMBench tasks:

Figure 4: Representative failure cases for advanced MLLMs, highlighting systematic errors in domain alignment, geospatial relationship reasoning, sensor modality interpretation, and perception robustness.
- Visual-linguistic misalignment: Models possess textual knowledge but fail to visually identify spectral bands, sensor types, or spatial relationships in diagrams.
- Sensor modality confusion: Failure to generalize beyond RGB imagery results in poor performance on SAR, HSI, and other sensor types.
- Inadequate spatial reasoning: Predictors struggle with interpreting maps, distance estimation, orientation, and geospatial cues.
- Domain-specific knowledge gaps: Even advanced models fail fundamental GIS, photogrammetry, or remote sensing process items due to insufficient data representation and weak transfer.
Multiple additional figures in the supplementary illustrate these error patterns across specialized subfields including spectral interpretation, platform recognition, LiDAR analysis, environmental monitoring, and hypothesis-driven RS applications (Figures 6-20).
Practical and Theoretical Implications
The introduction of GeoMMBench and GeoMMAgent has significant implications for both practical AI deployment and future research:
- Benchmarks designed by domain experts, with curated multidimensional task spectra, are essential for credible claims of domain AGI competence. Evaluation on superficial or annotation-driven datasets does not capture the demands of real-world expert interpretation in Earth observation.
- Agent-based model orchestration, with explicit modular decomposition and tool integration, is a promising paradigm for pushing model performance toward expert-level AGI, particularly for tasks requiring tightly coupled multidisciplinary reasoning and diverse data modalities.
- Current open-source models show promising acceleration but remain reliant on expanded, field-specific datasets, improved instruction-tuning mechanisms, and enhancements in modality-agnostic visual encoders to match or exceed proprietary systems.
Future Directions
There is a clear trajectory toward integrating even broader toolkits, extending task diversity, and enhancing the self-improvement and memory capabilities of agent-based orchestrators. Future research should target:
- Rich, real-time knowledge integration via external knowledge sources and retrieval systems for dynamic geospatial phenomena;
- Enhanced multimodal fusion for RS-specific data types through hybrid architectural innovations and multi-task pretraining strategies;
- Expanded coverage of spatial, temporal, and application-specific scenarios reflective of high-stakes analytical workflows encountered in scientific and industrial settings;
- Transparent, interpretable reasoning traces to support trustworthy integration of AI into expert-driven scientific pipelines.
Conclusion
GeoMMBench represents a significant advancement in the rigorous evaluation of MLLMs for geoscience and RS, setting an authoritative new standard for expert-level assessment. The GeoMMAgent multi-agent framework, by harmonizing retrieval, perception, and reasoning in a modular architecture, establishes a demonstrably effective path toward domain-specialized AGI in complex, high-dimensional Earth observation settings. This work provides both a practical toolkit and a methodological foundation for future efforts in developing, evaluating, and deploying expert multimodal AI systems across geospatial disciplines.
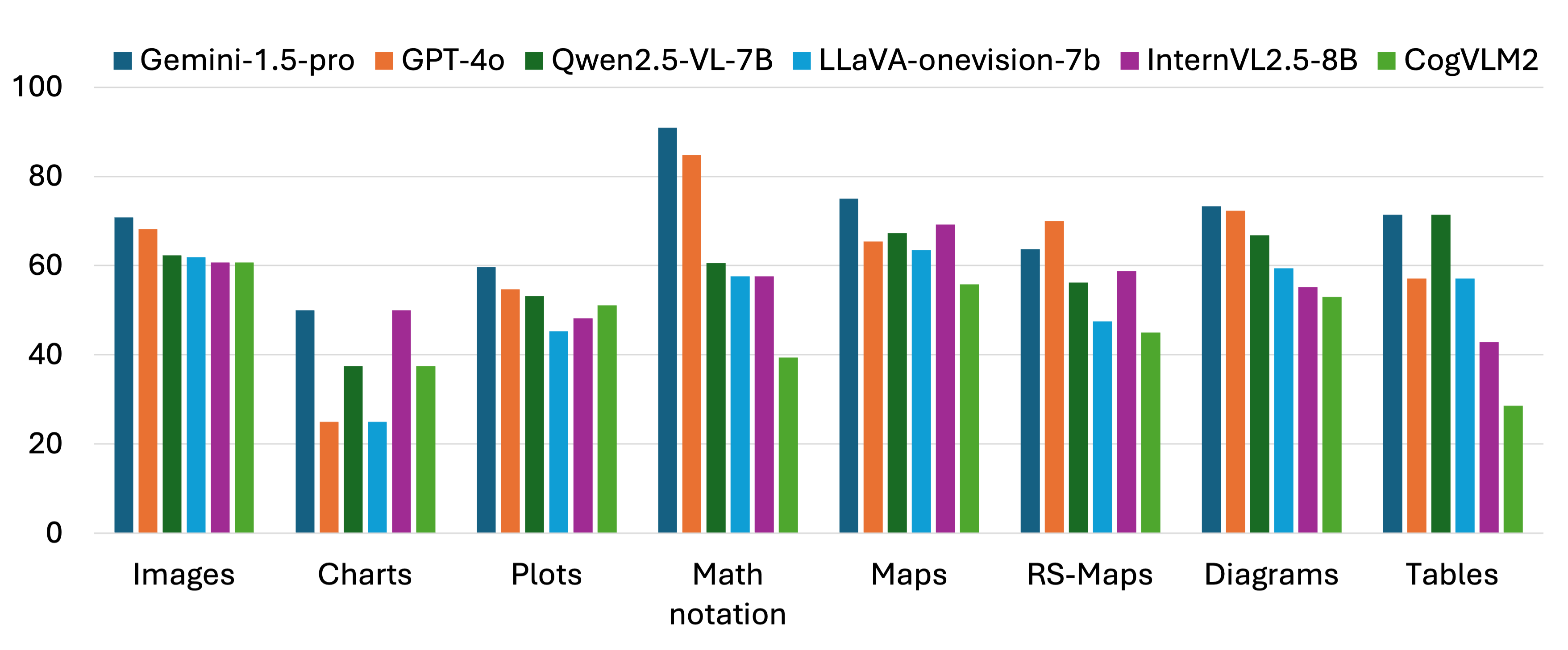
Figure 5: Performance of MLLMs on different types of images in GeoMMExpert, highlighting modality-specific weaknesses and the gap to human-level performance.
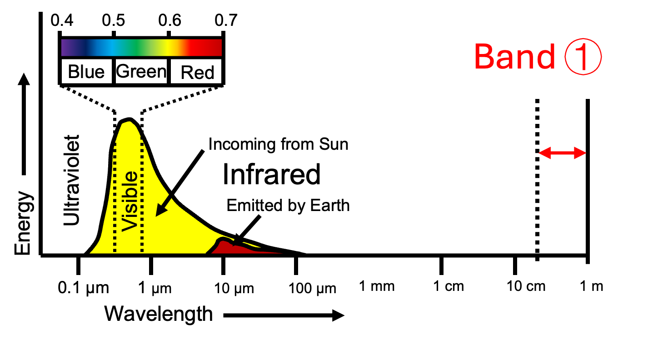
Figure 6: GeoMMAgent case study — band identification via multimodal fusion, task decomposition, and iterative self-evaluation.

Figure 7: GeoMMAgent in object counting for RS imagery, illustrating model-agent cooperation for accurate, explainable interpretation.

