- The paper decomposes preference pairs into generator-level and sample-level deltas to clarify how reasoning models learn.
- The paper demonstrates via ablation experiments that intrinsic reasoning quality, not outcome correctness, drives performance gains.
- The paper reveals that curating high-delta examples, particularly those with strong step coherence, significantly improves data efficiency.
Decomposing Preference Delta: Mechanistic Insights into Reasoning Model Optimization
Introduction
The paper "Decomposing the Delta: What Do Models Actually Learn from Preference Pairs?" (2604.08723) provides a comprehensive examination of preference-based optimization in LLMs for reasoning tasks, challenging assumptions underpinning widely-adopted methods such as Direct Preference Optimization (DPO) and related approaches. The analysis is centered on dissecting the underlying signals within preference pairs, advancing a dual-framework: generator-level delta (the capability gap between model pairs generating chosen and rejected responses), and sample-level delta (the quality gap within individual paired reasoning traces). The work systematically investigates how these factors impact both in-domain (mathematical reasoning) and out-of-domain (STEM, code) performance, offering new perspectives for data selection, scaling, and alignment strategies.
Dual Notion of Delta in Preference Data
A crucial conceptual contribution is the distinction and operationalization of generator-level and sample-level deltas. Generator-level delta is defined as the capability disparity between the models generating the chosen and rejected responses, effectively serving as a global prior for data informativeness. Sample-level delta quantifies the quality difference within a given preference pair over axes such as factuality, (strategy/step) coherence, computational precision, and signal-to-noise, as measured by LLM-as-a-judge rating schemes. The experimental setup exploits an extensive set of OpenR1-Math-220k preference pairs synthesized by diverse LLMs (Nemotron, S1 families) allowing precise manipulation and measurement of both delta types.
Scaling Laws and Out-of-domain Generalization
Extending the delta learning hypothesis to verifiable reasoning, the authors validate that DPO can yield strong downstream gains from preference pairs even when both responses are produced by relatively weak models and neither is outcome-verified. On in-domain mathematical benchmarks, scaling the chosen model’s capability produces, at most, modest benefits once the base LLM is sufficiently competent. However, out-of-domain generalization in STEM and code tasks improves monotonically as generator-level delta increases, with the largest performance increments corresponding to the widest capability gap between paired models. This result is visualized in the scaling law plot, with accuracy trends shown per model size.
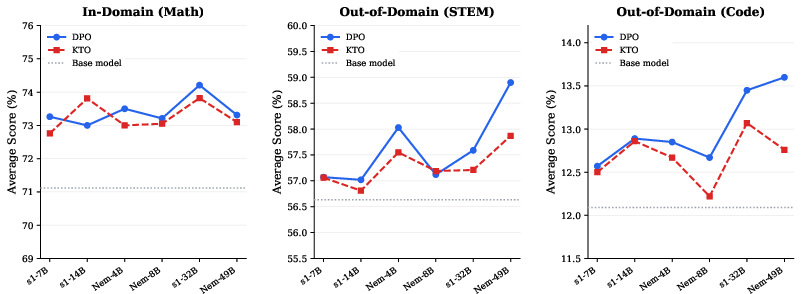
Figure 1: Scaling law of delta learning for reasoning tasks. Increasing generator-level delta notably widens out-of-domain generalization, with all models using s1-3B for rejection.
Sample-level delta analyses reveal that as the chosen model's strength increases, not only do average quality differences in all dimensions grow, but so does the informativeness of individual preference pairs. This substantiates that generator-level scaling indirectly amplifies sample-level signal strength, especially critical for domains with domain shift.
Decomposing Sample-level Delta: Correctness versus Reasoning Quality
Challenging the prevailing assumption that preference pairs’ efficacy stems chiefly from final-answer correctness, the paper provides ablation experiments on all four correctness configurations (correct → incorrect, correct → correct, incorrect → incorrect, incorrect → correct). The findings are unambiguous: all combinations, including those where both responses are incorrect, produce measurable improvements over baseline models, both in-domain and out-of-domain. The performance differentials across configurations are minimal and not dominant—correctness does not explain the majority of the learning signal. For example, DPO on incorrect-vs-correct pairs and correct-vs-correct pairs both yield non-trivial gains.
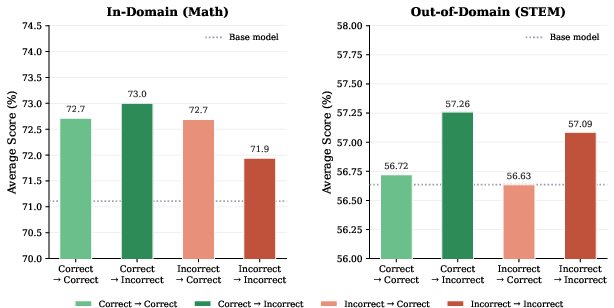
Figure 2: DPO performance for Nemotron-8B across correctness pairings. All configurations improve over baseline, highlighting the limited explanatory power of outcome correctness.
Notably, configurations where the rejected response is incorrect perform marginally better, which supports recent analyses of DPO’s gradient dynamics that emphasize "pushing away" from negative examples over "pulling toward" positives.
Fine-grained Quality Decomposition and Efficient Data Selection
A salient result emerges by directly selecting top-k preference pairs exhibiting the greatest sample-level deltas along individual dimensions. By training on only the top 1k, 2.5k, or 5k such pairs, the authors demonstrate that a small subset of curated, high-delta data can recover nearly all DPO gains produced by the full (16.5k) dataset. Marginal benefit saturates rapidly with subset size, implying significant sample efficiency. Among all reasoning quality metrics, step coherence is most predictive of downstream performance in both in-domain and out-of-domain tasks, suggesting its extraction is particularly aligned with what preference-optimized models actually learn.
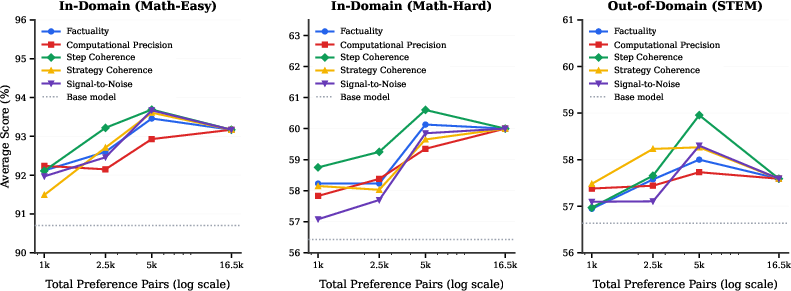
Figure 3: Accuracy as a function of number of high-delta training pairs by quality dimension; step coherence consistently maximizes gains with minimal data.
Overlap analyses further indicate interdependence among dimensions—e.g., strategy and step coherence selections overlap significantly—reflecting shared underlying structure in reasoning quality.
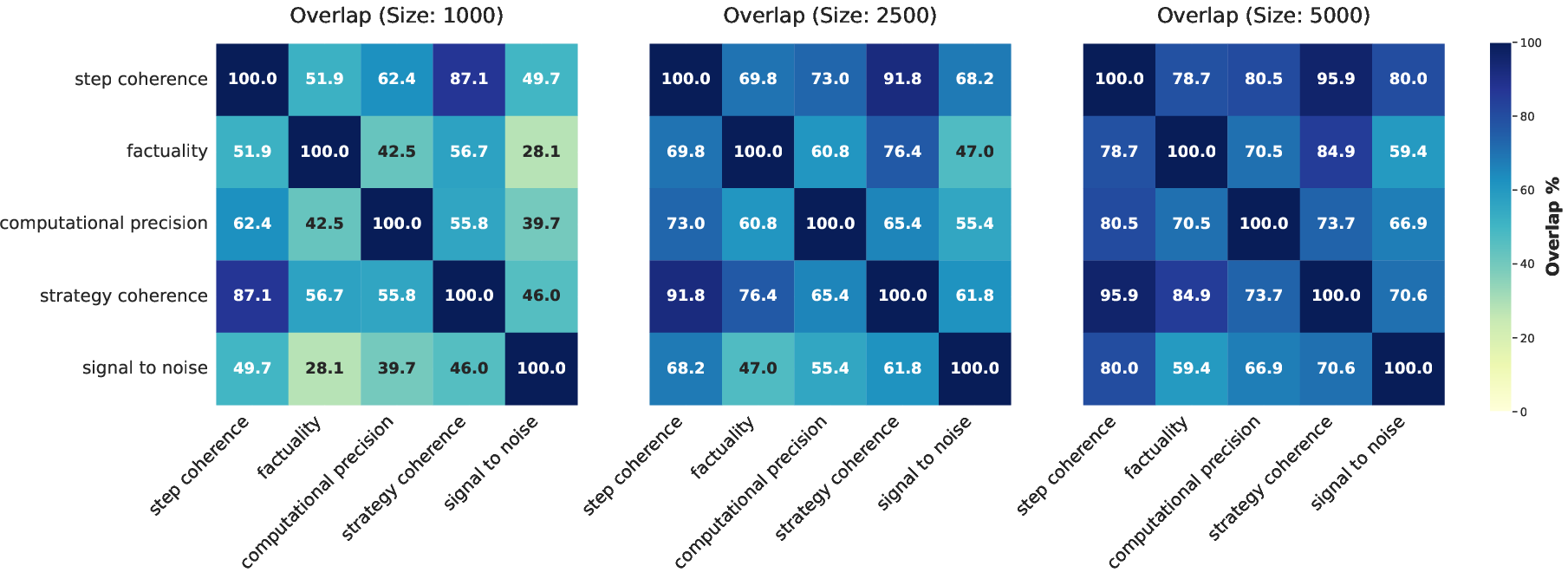
Figure 4: Overlap between sample selections formed by top deltas across different quality dimensions and set sizes.
Implications and Future Directions
These empirical and analytic results yield several impactful takeaways:
- Generator-level delta maximization serves as a principled method for constructing highly informative preference datasets, invaluable for tasks necessitating generalization beyond the training domain.
- Systematic sample-level delta measurement, especially via reasoning process-specific metrics such as step coherence, facilitates aggressive data reduction without performance loss, dramatically improving the data-efficiency and cost-effectiveness of preference-based alignment pipelines.
- The dominant learning signal in preference-based reasoning optimization is localized within the structure and logical flow of reasoning traces, and not in outcome correctness—a finding at odds with long-held assumptions and of consequence for interpretability, reward modeling, and evaluation.
- Recent advances in multi-aspect chain-of-thought evaluation and automated critics can further refine high-signal data curation, promoting scalable and more robust alignment as models are deployed in ever more specialized settings.
Conclusion
"Decomposing the Delta: What Do Models Actually Learn from Preference Pairs?" (2604.08723) establishes an authoritative framework for understanding what constitutes an effective supervisory signal in preference optimization for reasoning models. The work identifies generator-level delta and sample-level delta as decoupled, complementary levers that can be harnessed to boost out-of-domain generalization and dramatically increase training sample efficiency. The empirical finding that reasoning quality—particularly step coherence—rather than outcome correctness underpins model improvement has implications for future research in preference data generation, LLM post-training, and diagnostic interpretability. This paradigm is poised to inform better practical alignment strategies and inspire investigations into even more fine-grained, process-centric preference optimization methodologies.