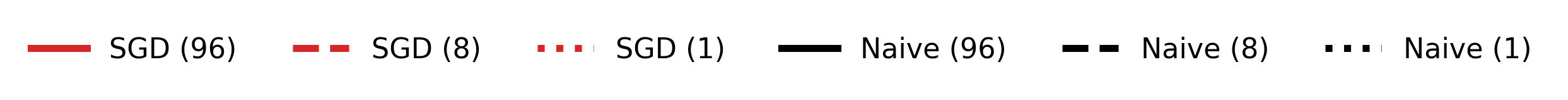Published 9 Apr 2026 in cs.CL, cs.AI, cs.LG, and stat.ML | (2604.08423v1)
Abstract: What are the limits of controlling LLMs via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
The paper introduces Dataset Policy Gradient, demonstrating how RL and metagradients can optimize synthetic data generation for arbitrary differentiable objectives.
It leverages higher-order gradients and advanced optimizers like Adam to approximate true dataset-level gradients under controlled error bounds.
Empirical results show effective manipulation of model behaviors such as watermarking, norm control, and emergent multilingual data generation.
Synthetic Data for Arbitrary Differentiable Objectives: A Technical Analysis
Introduction
The paper "Synthetic Data for any Differentiable Target" (2604.08423) develops and analyzes Dataset Policy Gradient (DPG), a novel RL-based meta-optimization framework for training synthetic data generators to target arbitrary differentiable downstream metrics through model supervision. The key innovation is moving from heuristics or human-specified goals for synthetic data to direct, fine-grained optimization of the generator, with theoretical and empirical analysis demonstrating precise control over downstream model behavior via synthetic data alone.
Methodology: Dataset Policy Gradient
DPG incorporates metagradient-based data valuation into an RL loop to assign individual synthetic examples a reward proportional to their global downstream influence, rather than assigning a single scalar reward to an entire synthetic dataset. This is enabled by efficiently computing higher-order gradients, as in [(Engstrom et al., 17 Mar 2025), raghu2021metalearning]. The core optimization objective is:
πθmaxED∼πθ[Φ(A(D))]
where πθ is the parameterized synthetic data generator, D is a dataset sampled from the generator, A is the (possibly multi-step) training procedure for the target model, and Φ is any differentiable metric evaluating the model post-training. The generator is updated via policy gradients, with rewards per datum computed via metagradients from Φ back to example weights, tracked over several training steps:
r(x)=∂wx∂Φ(A(w,D))w=1
A formal analysis (see Section \emph{Theory}) justifies that this closely approximates the true "dataset-level" RL gradient, under the usual smoothness and SGD regime assumptions.
Figure 1: DPG enables generator optimization for downstream targets by propagating rewards based on metagradient data importance.
Theoretical Guarantee
The main theorem establishes that under mild regularity assumptions and multi-step SGD in A, the per-example DPG policy gradient approximates the intractable true dataset-level gradient, with an error bound that shrinks as SGD step size η→0 and batch size B→∞. The bound reflects the difference between the SGD (discrete) parameter trajectory and a continuous SDE, building on recent theory [pmlr-v134-fontaine21a]. This result extends influence function theory (cf. [koh2017influence, bae2022influence]) to the high-dimensional, non-convex, multi-step setting with arbitrary metrics, provided full metagradients (not approximations) are used.
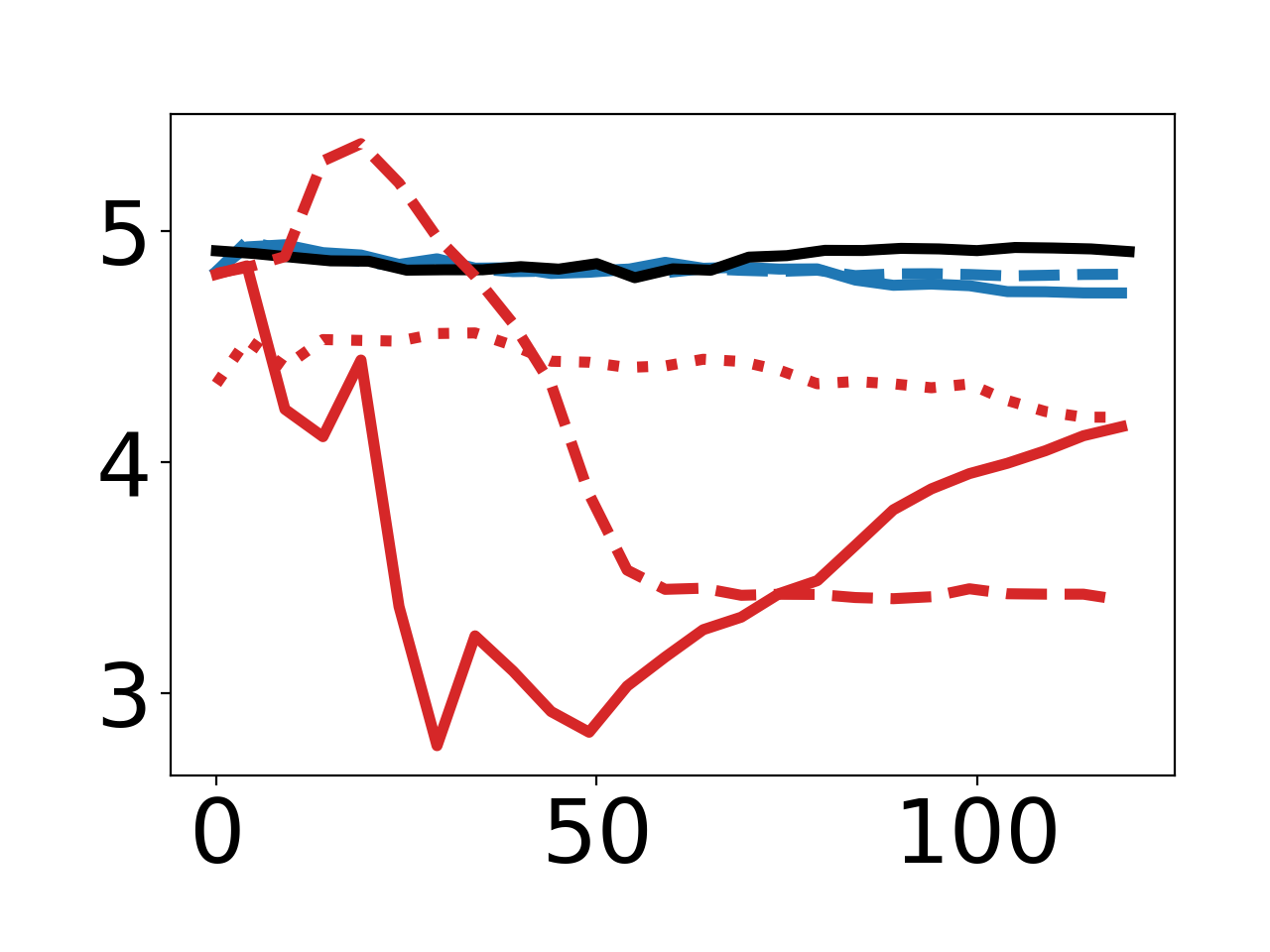
A crucial empirical finding is that Adam in πθ0 is required for effective generator training—SGD-based baselines and single-step approximations degrade performance, indicating optimizer dynamics are essential for accurate meta-optimization, a point differing from canonical influence function approaches.
Empirical Results
The DPG framework is validated over increasingly complex and adversarial targets, yielding several notable results:
Imprinting Structured Patterns in Model Weights
By targeting metrics that penalize the πθ1 distance between LM head weights and a "watermark" pattern (e.g., a QR code or the image "67"), DPG-trained generators are able to produce seemingly benign synthetic text paraphrases such that, after fine-tuning the target model on them, its LM head contains the encoded pattern.
Figure 1: Paraphrased Wikipedia samples can produce a QR code in the LM head after model training on synthetic data.
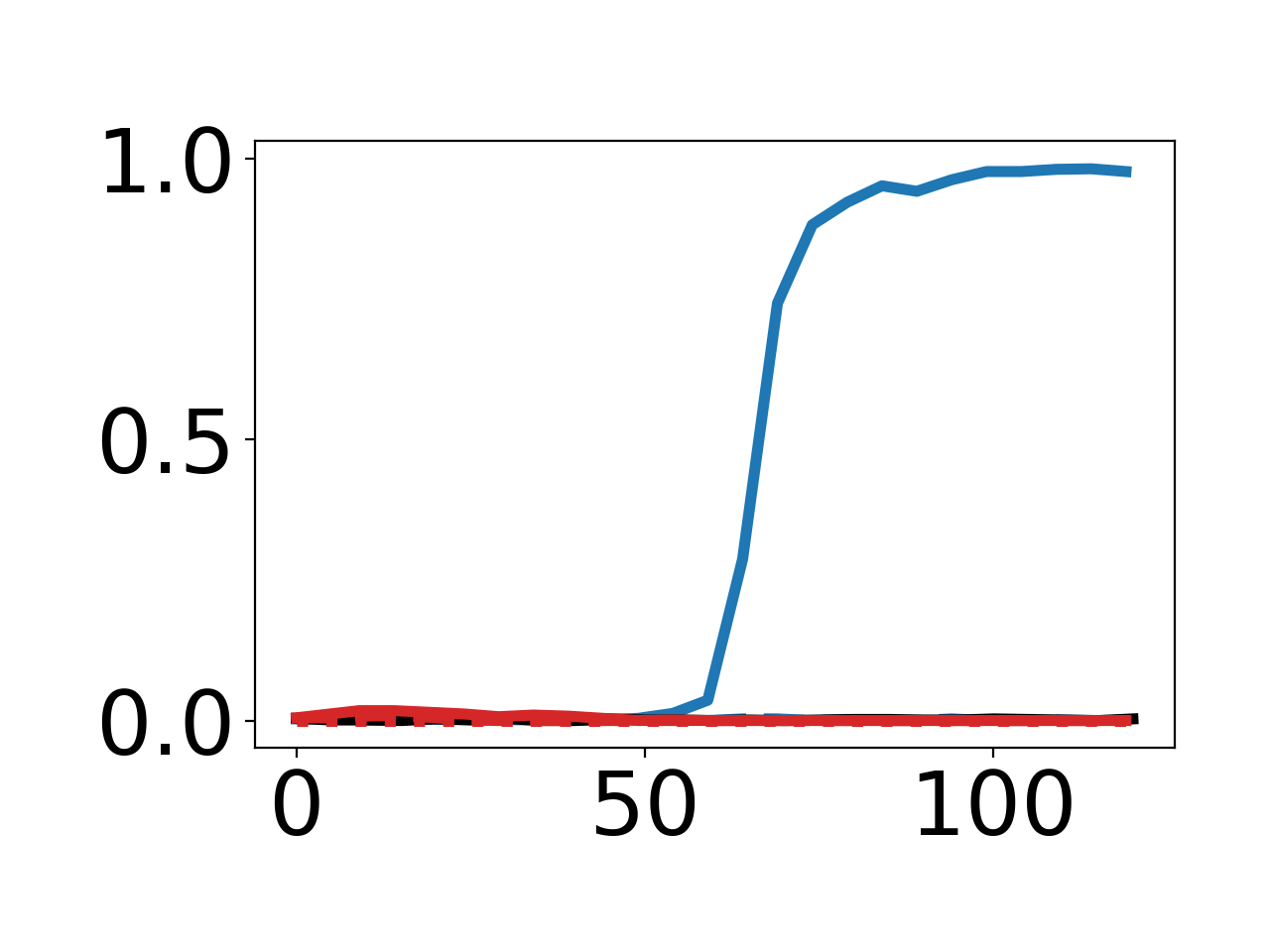
This result holds even for large and arbitrary targets, including a 21x21 QR code and a 6x7 patch shaped as "67". Only DPG with Adam and sufficient (96) inner-loop steps can fully achieve the intended encoding, as seen in the final weight visualizations.
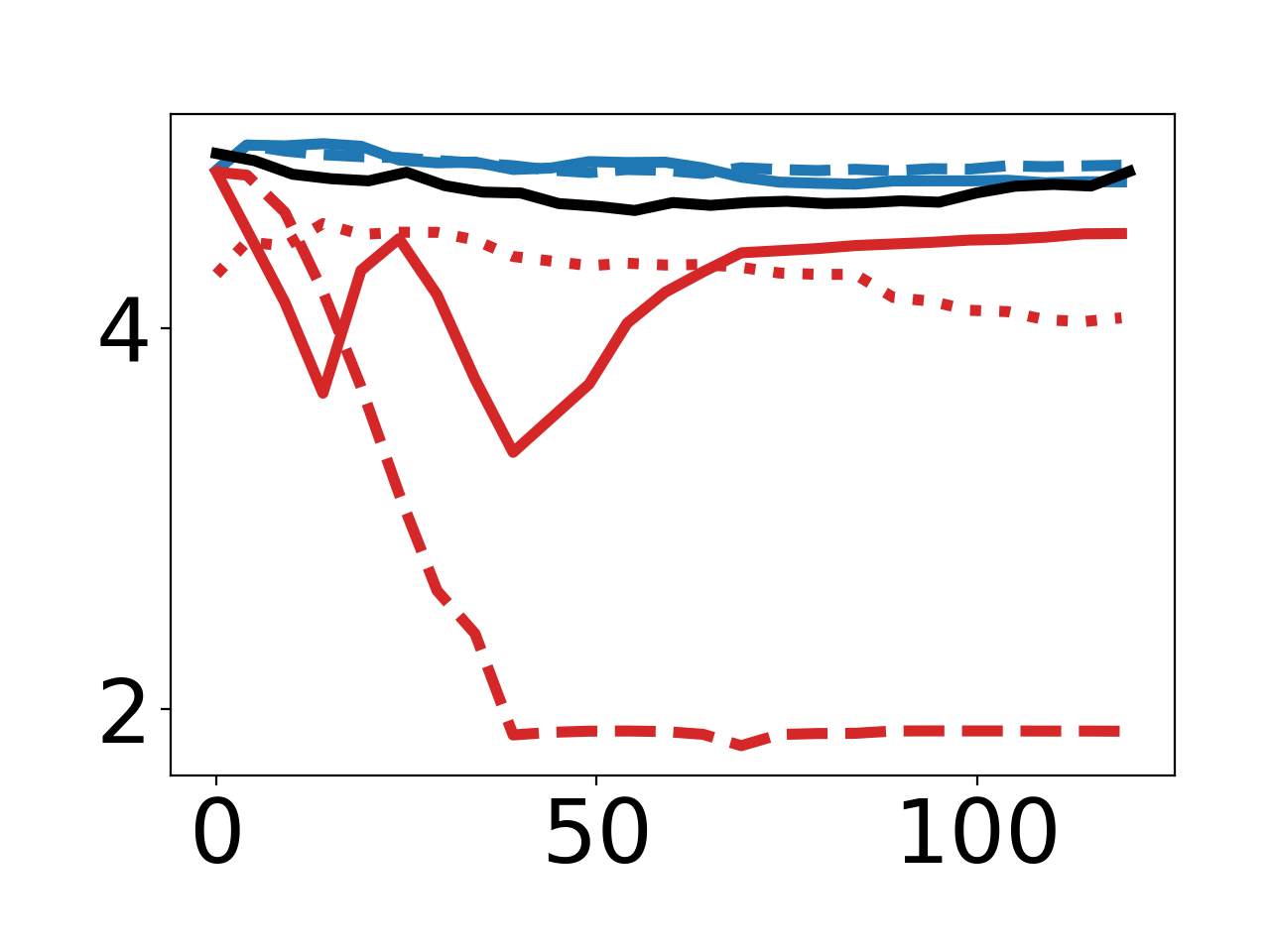
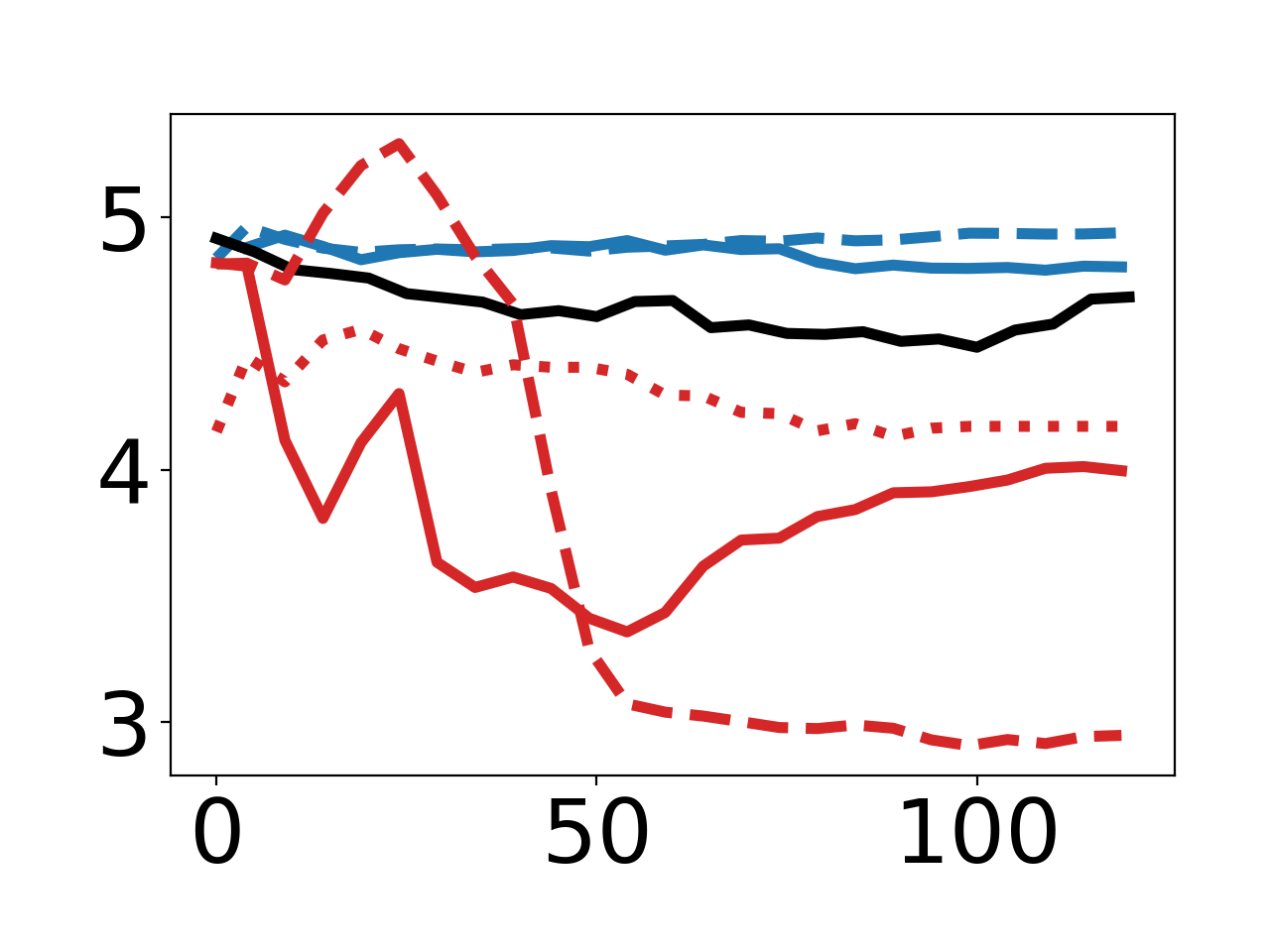
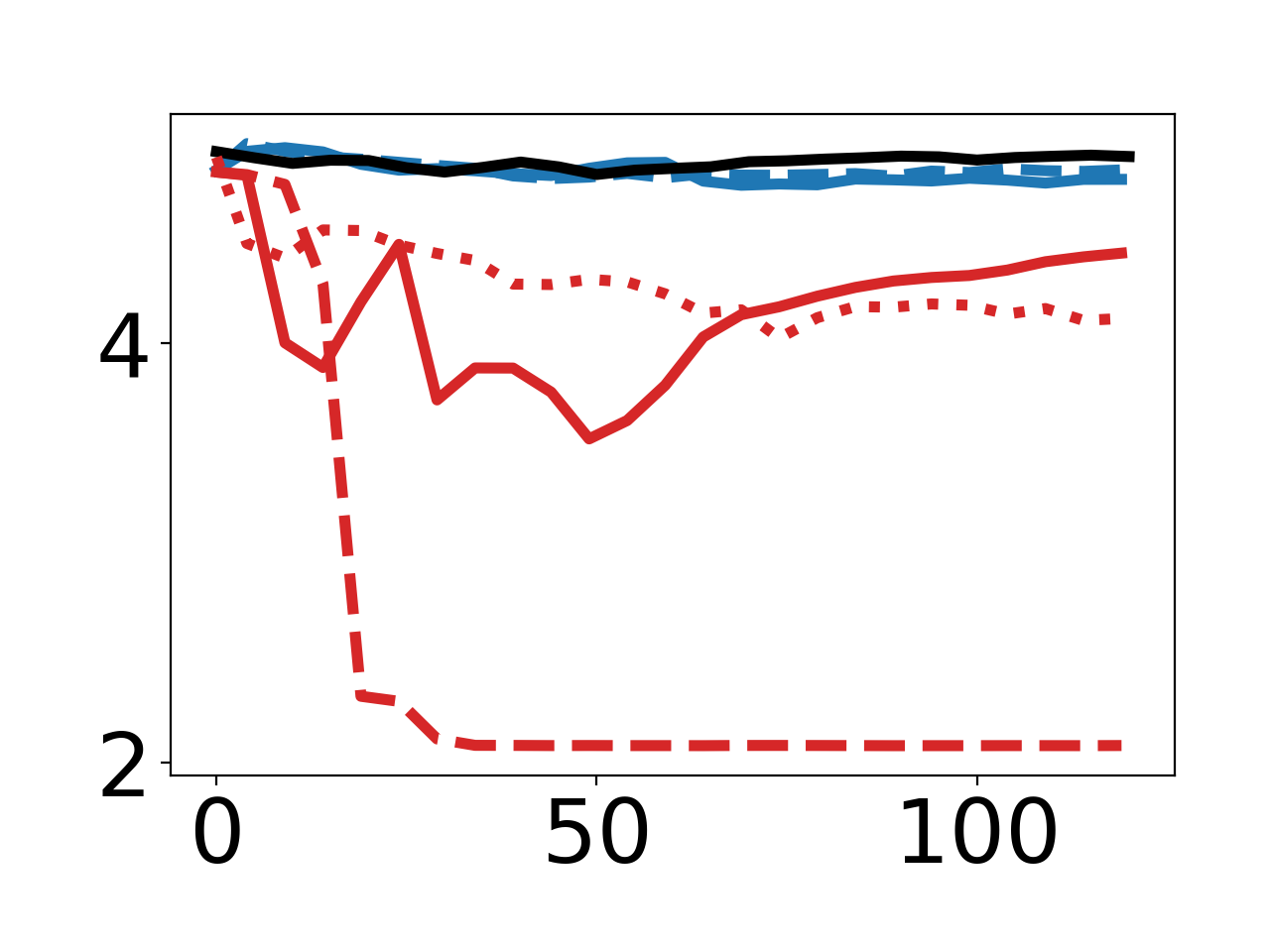
Directly Controlling Model Norms
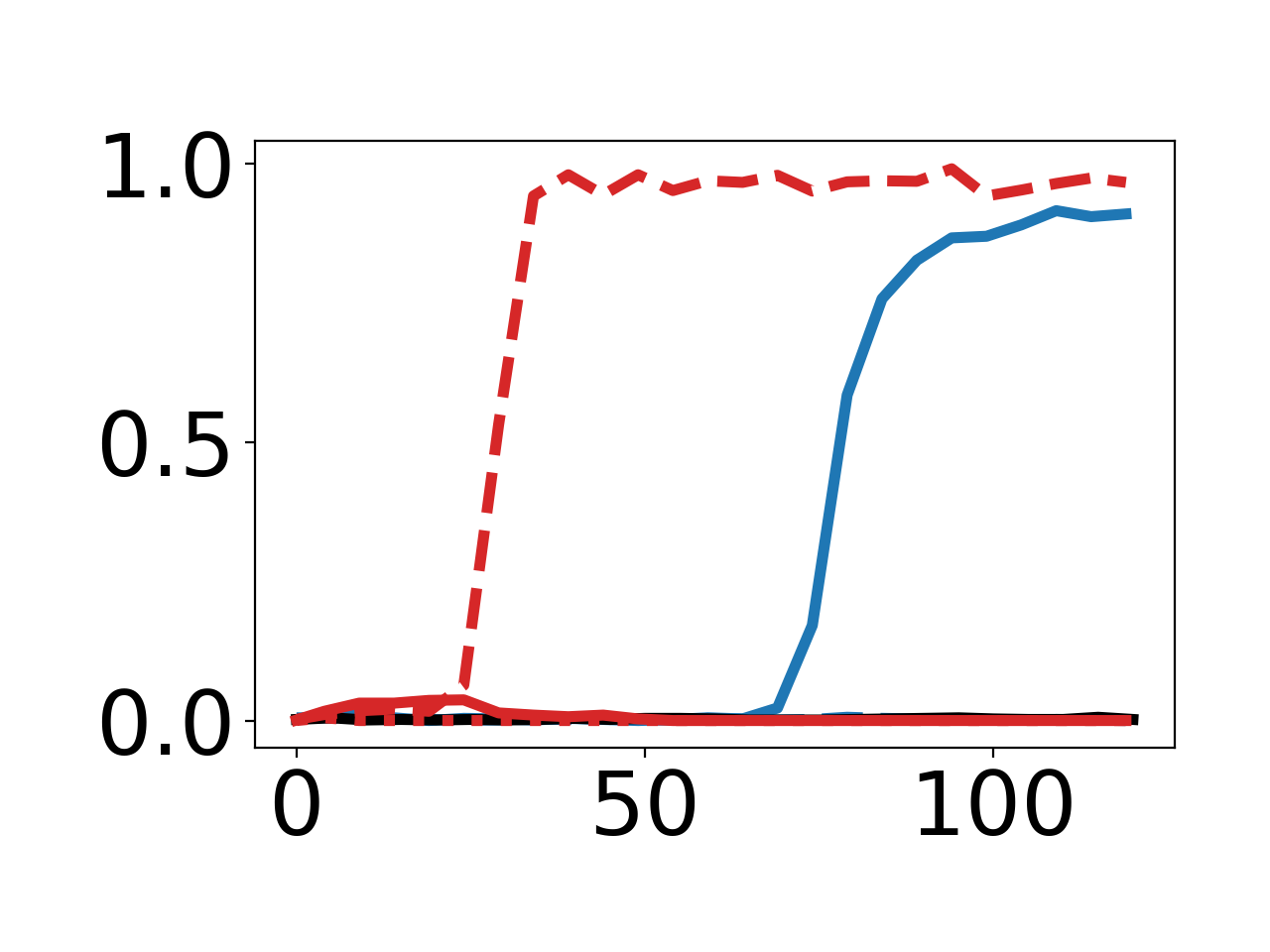
By optimizing for reduced πθ2 norm of model parameters, DPG produces synthetic data that consistently ablates norm, again relying on multi-step Adam-based meta-optimization for maximal effect.
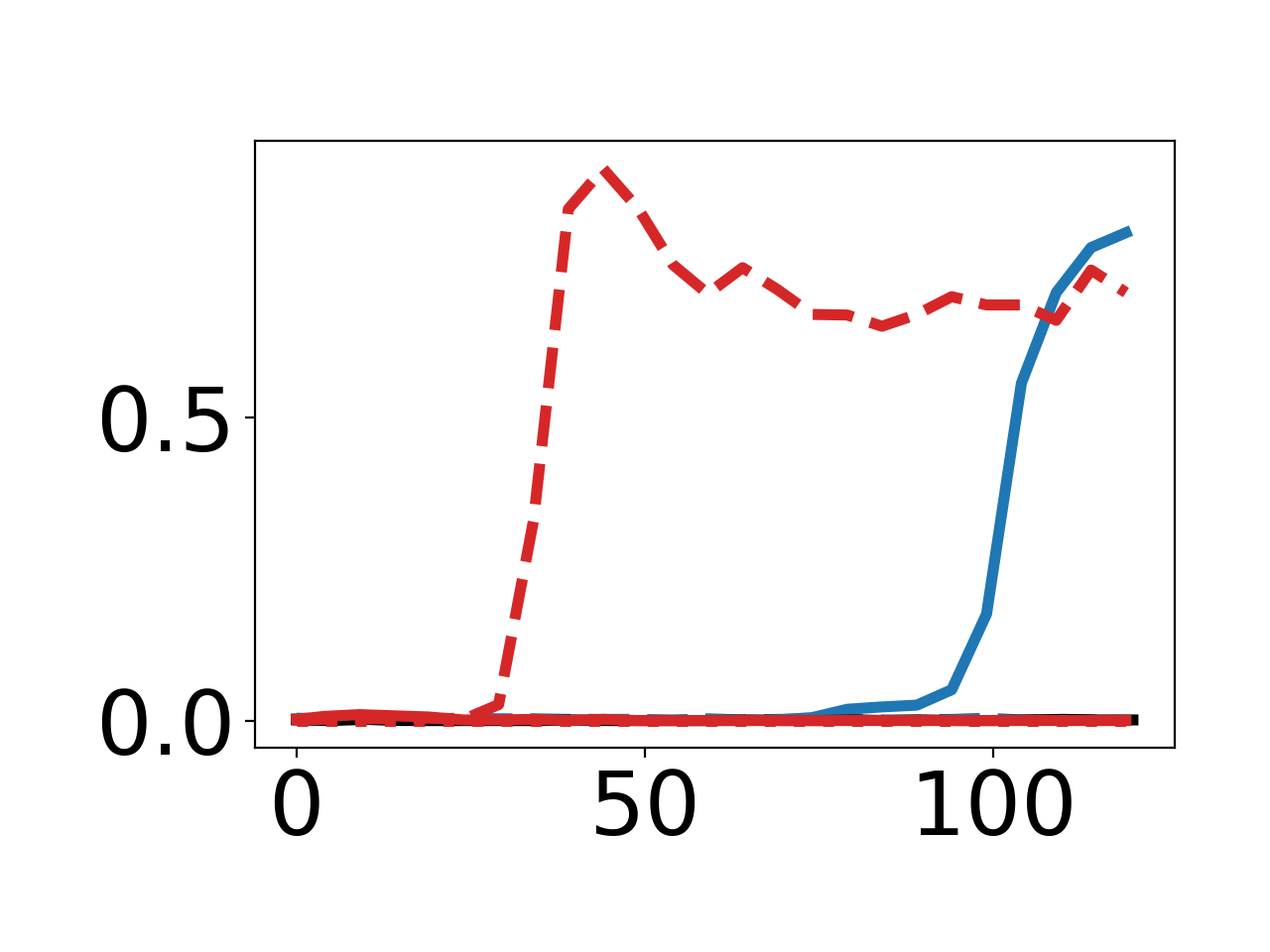
Figure 2: Empirical curves demonstrating effects of different inner-loop step counts and optimizers for norm and "67" targets.
Semantic Control: Multilingual and Non-Natural Targets
When the downstream metric is LM loss on a held-out LAMBADA benchmark in a new language (DE, ES, FR, IT), the DPG generator, initialized on English Wikipedia, learns to output high-entropy paraphrases in the target language. Notably, the prompt never specifies translation; the reward induces translation emergently.
Figure 3: For four languages, the DPG generator learns to rephrase in the target language, measured by language classifier outputs and n-gram entropy.
For extreme targets, such as LM loss on a random 32-character UUID, DPG is able to induce the generator to emit the UUID verbatim, despite starting from English Wikipedia paraphrasing (Figure 4).
Figure 4: DPG generator's outputs increasingly match a target UUID as RL proceeds, measured by exact and partial string match.
Baseline approaches, including naive RL on final LM loss (i.e., without metagradients), embedding-based rewards, fasttext-based language classification, and Levenshtein similarity, do not yield meaningful control—only proper metagradient-based per-example rewards drive generator learning for these challenging targets.
Generalization and Transfer
Synthetic data produced by DPG generators trained on a specific target model (e.g., Llama 3.2 Instruct in JAX) generalize to distinct model implementations and frameworks; applying the generated data in bulk (10M tokens) improves perplexity on unseen multilingual tasks more than competitive baselines, and the gain transfers across instruct/base variants and frameworks (cf. Table A11).
Implications and Discussion
The DPG procedure substantially expands the capability of direct data-driven model editing via synthetic supervision. Notably, it demonstrates that one can induce arbitrary, even semantically orthogonal, properties into a model solely through synthetic data continued pre-training (CPT).
These findings are significant both practically and theoretically:
Fine-grained model control: Arbitrary differentiable model properties, even at a sub-parameter or behavioral level, can be steerable through DPG-optimized synthetic data.
Synthetic data curation: This approach unifies data attribution, meta-learning, and RL methods, leading to automated, highly targeted data curation pipelines not limited by heuristic templates.
Security implications: The same techniques enable sophisticated model watermarking, provenance tracing, or even subtle targeted data poisoning, as DPG can induce hidden or malicious behaviors undetectably within normal-looking training data.
Future research: Extensions to scaling DPG for large-scale foundation model pretraining ("pretraining data as a RL policy"), automated safeguard design, and the integration of optimizer-dependent influence functions for broader model editing are likely directions. Additionally, understanding which class of model properties are robustly amenable to this approach, limitations under multi-task settings, and the role of metagradient fidelity are open research questions.
Conclusion
The Dataset Policy Gradient framework provides a foundation for end-to-end differentiable, RL-based synthetic data generation capable of precisely targeting downstream model characteristics. Both its theoretical analysis and experimental achievements indicate that, with proper metagradient computation and optimizer configuration, practitioners can induce highly structured, arbitrary, and non-trivial transformations in trained LMs with purely synthetic and ostensibly naturalistic supervision. This raises both opportunities for robust and compliant model editing as well as imperatives for the monitoring and governance of synthetic data pipelines.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.