Extract-0: A Specialized Language Model for Document Information Extraction
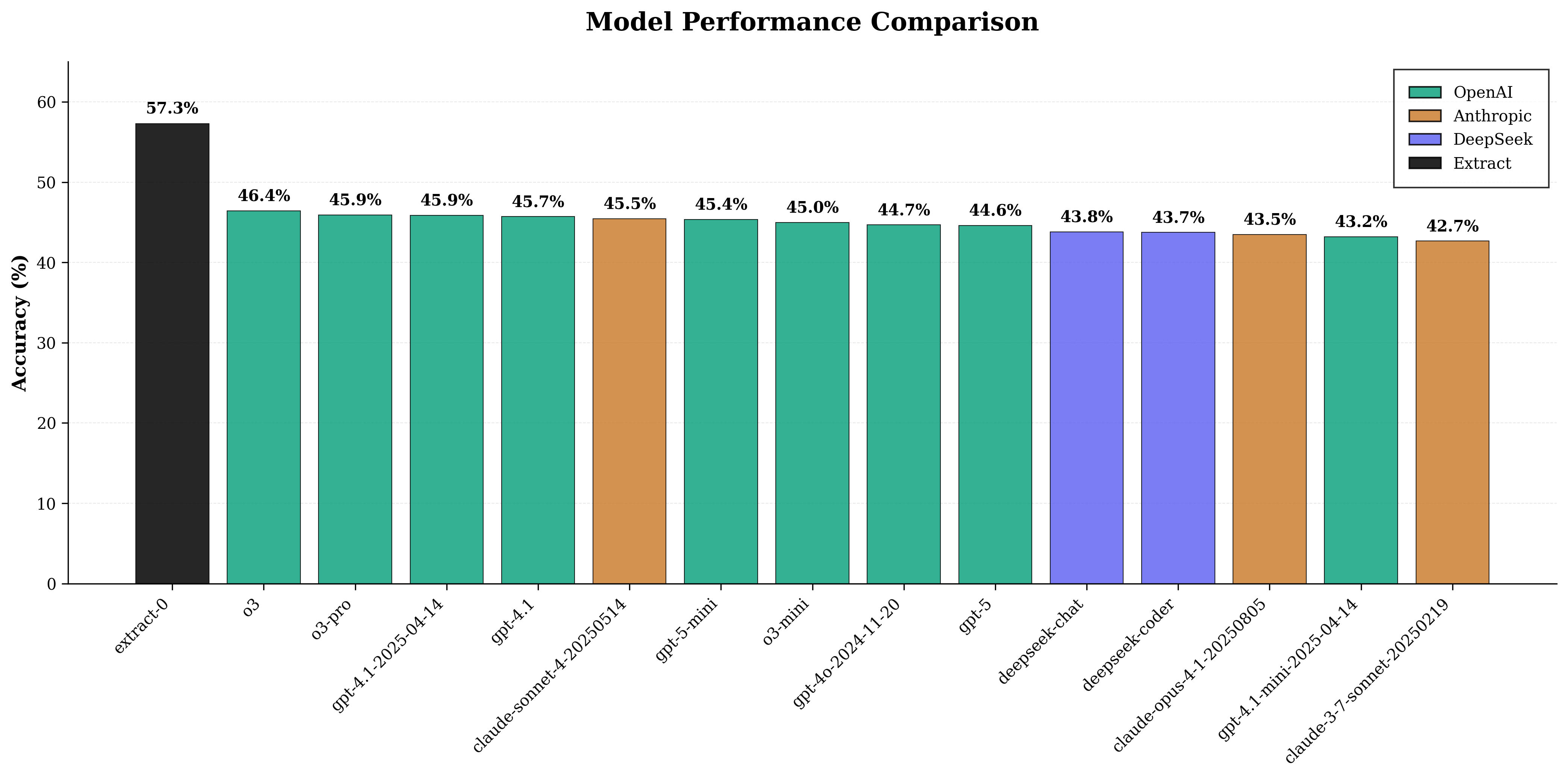
Abstract: This paper presents Extract-0, a 7-billion parameter LLM specifically optimized for document information extraction that achieves performance exceeding models with parameter counts several orders of magnitude larger. Through a novel combination of synthetic data generation, supervised fine-tuning with Low-Rank Adaptation (LoRA), and reinforcement learning via Group Relative Policy Optimization (GRPO), Extract-0 achieves a mean reward of 0.573 on a benchmark of 1,000 diverse document extraction tasks, outperforming GPT-4.1 (0.457), o3 (0.464), and GPT-4.1-2025 (0.459). The training methodology employs a memory-preserving synthetic data generation pipeline that produces 280,128 training examples from diverse document sources, followed by parameterefficient fine-tuning that modifies only 0.53% of model weights (40.4M out of 7.66B parameters). The reinforcement learning phase introduces a novel semantic similarity-based reward function that handles the inherent ambiguity in information extraction tasks. This research demonstrates that task-specific optimization can yield models that surpass general-purpose systems while requiring substantially fewer computational resource.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “Extract‑0: A Specialized LLM for Document Information Extraction”
1. What is this paper about?
This paper introduces Extract‑0, a smaller, specialized AI model that’s really good at one job: pulling specific facts from long, messy documents and putting them into a neat, structured format (like filling out a form). Even though it’s much smaller than famous general models, it beats them on this task, and it was trained cheaply.
2. What questions did the researchers ask?
They wanted to know:
- Can a focused, smaller model do document information extraction better than big, general‑purpose models?
- Can we train it with limited money and hardware?
- How can we teach the model to accept different “right” answers that mean the same thing (like “Jan 1, 2020” vs. “2020‑01‑01”)?
3. How did they do it? (Methods explained simply)
The team built and trained Extract‑0 in three main steps.
Step A: Making lots of training examples (synthetic data)
- They collected real documents from places like arXiv (science papers), PubMed (medical papers), Wikipedia, and FDA sites (regulatory documents).
- They split each document into smaller pieces (“chunks”) so the model could read long documents in parts.
- As the system moved from one chunk to the next, it kept a “memory” of what it already found. Think of it like a careful reader keeping notes while moving through a book, so later parts don’t contradict earlier ones.
- They created many practice tasks where the goal was: given a “schema” (a template that says what fields to extract) and a document, produce a clean JSON output. JSON is a computer‑friendly format that’s like a digital form with labels and values.
- They controlled the length of each training example (by counting “tokens,” which are pieces of words) so everything fit into the model’s reading window.
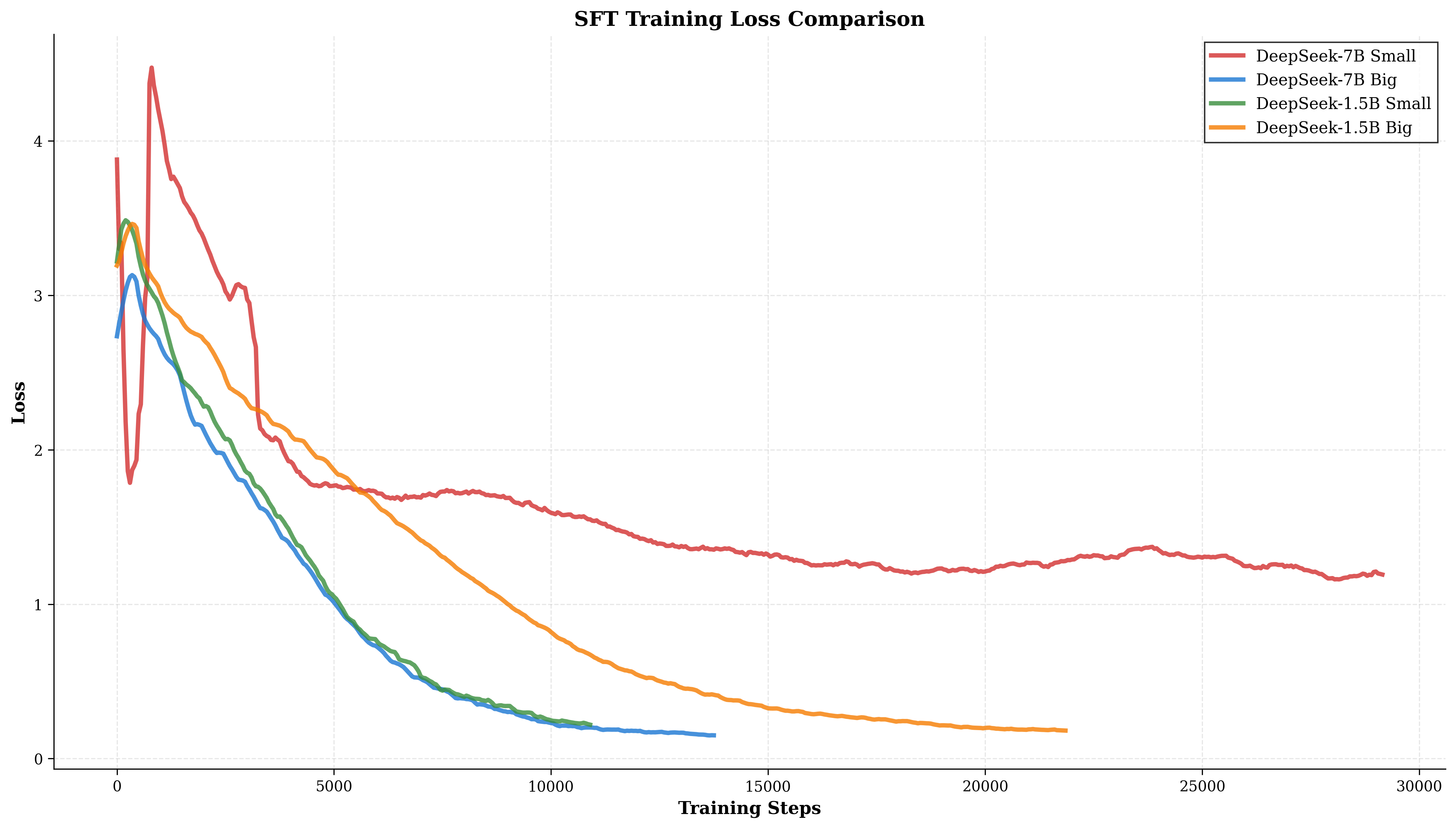
Step B: Fine‑tuning the model efficiently (LoRA)
- They started with a 7‑billion‑parameter base model and adapted it using a technique called LoRA.
- LoRA is like adding small “clip‑on adapters” to the model instead of rewriting the whole model. Only about 0.53% of the model’s weights were changed. This makes training faster, cheaper, and less risky.
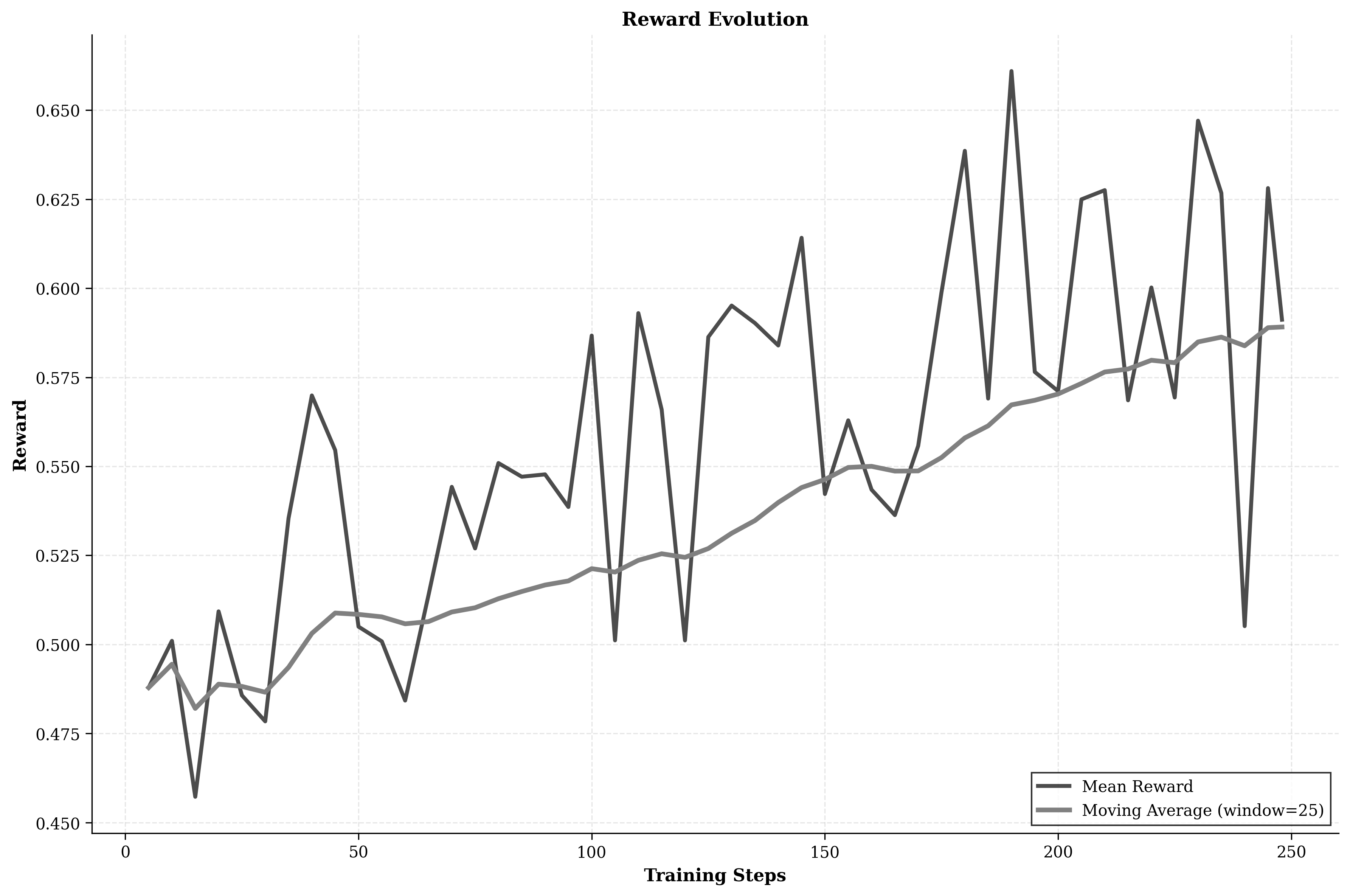
Step C: Teaching with feedback (Reinforcement Learning + a smarter score)
- After basic training, they improved the model with reinforcement learning: the model tries to extract information, gets a score, and learns to do better.
- The score wasn’t strict “exact match” (because there are many correct ways to write the same thing). Instead, they used a “semantic similarity” score, which checks whether the meaning is the same even if the wording is different. For example, “IBM” and “International Business Machines” can be matched if they mean the same company.
- They used a method called GRPO (a variant of PPO), which is a safe way to update the model so it improves steadily without going off track.
4. What did they find, and why does it matter?
Here are the key results:
- Higher task score than much larger models: Extract‑0 achieved a mean reward (average score between 0 and 1) of 0.573 on 1,000 test extraction tasks. This beat GPT‑4.1 (0.457), o3 (0.464), and GPT‑4.1‑2025 (0.459). In simple terms: the smaller, specialized model did better at this specific job.
- More reliable structured outputs: Valid JSON outputs rose from 42.7% (before training) to 79.9% after fine‑tuning, and 89.0% after reinforcement learning. That means fewer broken or incomplete answers.
- Big gains from each training step: The base model scored 0.232; with supervised fine‑tuning it rose to 0.507; with reinforcement learning it reached 0.573.
- Low cost: Total training cost was about $196 on a single high‑end GPU. That’s very affordable compared to typical big‑model training.
Why this matters: Many businesses need to turn emails, PDFs, contracts, or reports into clean data fields. A smaller, cheaper model that’s very good at this one job can save money and be easier to run than giant models.
5. What could this change in the real world?
- Practical automation: Companies in healthcare, finance, and law could automate data entry more reliably and cheaply.
- Specialized over general: This work shows that a model focused on a single task can outperform larger general models for that task. That could encourage more “specialist” AIs for different jobs.
- Easier to audit and maintain: Specialized components make it clearer where errors come from, which helps with fixing problems and meeting regulations.
The authors also note some limits and future steps:
- Mostly English: The model was trained on English documents; new languages would need extra work.
- Very niche documents may need extra tuning: For highly specialized formats (like certain legal contracts), more training examples would help.
- The “meaning‑based” scoring is smart but not perfect: It might miss small but important details (like a missing middle initial in a name).
- Cross‑document consistency: The model reads one document at a time; future versions could link information across multiple documents.
Bottom line: With clever data generation, efficient fine‑tuning, and a fair scoring system that understands meaning, a smaller, specialized AI can beat bigger models at extracting information from documents—while being far cheaper to train and run.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and uncertainties that future researchers could address:
- Real-world validation: No evaluation on real, production documents (e.g., scanned PDFs, contracts, invoices, clinical notes), only synthetic tasks derived from arXiv/PubMed/Wikipedia/FDA; external benchmarks (e.g., FUNSD, DocVQA, SROIE, Kleister, VRDU) are not reported.
- Layout/vision modality: The pipeline assumes plain text; it does not handle document layout, tables, forms, figures, or OCR noise typical of PDFs and scans, nor does it leverage layout-aware models or vision-language approaches.
- Long-context handling: Inference behavior for documents exceeding the 2048-token window is unclear; there is no explicit mechanism for chunked inference with memory/state carryover comparable to the synthetic “memory-preserving” generator.
- Memory at inference: The “memory-preserving” architecture is a data-generation method, not an inference-time algorithm; it remains unknown whether a similar memory mechanism during inference would improve consistency on long or multi-section documents.
- Cross-document tasks: No support for entity resolution or consistency across multiple related documents (e.g., dossiers, filings, patient records); how to maintain cross-document memory remains open.
- Schema generalization: Generalization to unseen schemas, novel field types, deeper nesting, and very large schemas is not evaluated (zero-shot or few-shot schema induction remains open).
- Output length constraints: The 532 max new tokens may be insufficient for large schemas or high-recall extractions; capacity limits and truncation failure modes are not studied.
- Structural guarantees: 11% invalid JSON after RL is still material; constrained decoding, formal schema-constrained generation, or programmatic decoders are not explored for stronger structural guarantees.
- Reward function bias: The custom reward (MiniLM-based semantic similarity with τ=0.35) is also used for evaluation, risking alignment to the metric rather than true extraction quality; metric robustness, calibration, and potential reward hacking are not analyzed.
- Field criticality: The reward treats fields uniformly; there is no weighting for high-impact fields (e.g., IDs, amounts, legal names) where small errors matter disproportionately.
- Mathematical and symbolic fidelity: The reward’s embedding-based similarity may poorly capture correctness of equations, symbols, LaTeX, and units; no specialized evaluation for math fidelity is reported.
- Units and normalization: There is no unit normalization or consistency checking; the reward may score semantically mismatched units as similar.
- Dates and numerics: Date parsing and numerical relative error are used, but corner cases (time zones, formats, rounding, scientific notation, ranges, uncertainties) and tolerance setting are not validated.
- List matching threshold: The choice of τ=0.35 for list bipartite matching is not justified or ablated; sensitivity to τ and false-positive matching risk is unknown.
- Comparative evaluation fairness: Details on prompting, decoding limits, context provisioning, and token budgets for GPT-4.1, o3, and GPT-4.1-2025 are missing, so fairness and reproducibility of cross-model comparisons are unclear.
- Statistical robustness: No confidence intervals, statistical significance tests, or variance across multiple runs/seeds are provided for reported gains.
- Distribution shift: The 1,000-task test set is drawn from the same synthetic pipeline; performance under domain shift (e.g., different industries, writing styles, noisy OCR) is untested.
- Human-validated ground truth: Synthetic labels are not human-audited; label noise, artifacts, and their downstream impact are not characterized.
- Component ablations: No ablations for key design choices (memory-preserving generation vs. naive generation, LoRA rank/targets, RL reward variants, τ threshold, embedding model choice, token budgets, augmentation probabilities).
- RL stability and sample efficiency: GRPO training lasts 248 steps with dynamic KL control; sensitivity to hyperparameters, convergence reliability, and generalization after RL are not explored.
- Catastrophic forgetting: Claims of avoiding forgetting are not substantiated with evaluations on non-extraction tasks or general capabilities of the base model post-fine-tuning.
- Multilinguality: Training is English-only; zero-shot transfer and multilingual fine-tuning strategies (script differences, locale formats) are not studied.
- Error analysis: No qualitative or category-level error breakdown (by field type, domain, document length, schema complexity) to guide targeted improvements.
- Robustness to adversarial inputs: No assessment of prompt injection, schema poisoning, malformed JSON prompts, or adversarial document content.
- Inference efficiency and cost: Latency, throughput, and per-document inference cost vs. large APIs are not measured; deployment constraints (CPU-only, edge devices) are not addressed.
- Continual learning and drift: No strategy for updating the model to handle regulatory changes, new formats, or concept drift without catastrophic forgetting.
- Privacy and compliance: Handling of PII/PHI, on-prem deployment, and safeguards for sensitive documents are not discussed.
- Model release: It is unclear whether fine-tuned weights are released; replicability of results with the provided code/data is not demonstrated end-to-end.
- Composability with tools: Integration with retrieval, validators, schema compilers, or symbolic post-processors to boost reliability is not investigated.
- Benchmark breadth: Only mean reward and JSON validity are reported; per-field F1, exact-match, precision/recall, and task-type breakdowns are missing.
- Failure recovery: There is no strategy for partial extractions, fallback prompts, self-correction loops, or uncertainty estimates to guide human-in-the-loop workflows.
- Ethical and domain risks: Potential harms from mis-extraction in high-stakes settings (healthcare, finance, legal) and mitigation strategies are not analyzed.
Practical Applications
Immediate Applications
The following applications can be deployed with existing methods, tooling, and reported performance characteristics of Extract-0 and its training pipeline.
- Schema-guided document extraction API/microservice
- Sectors: cross-industry (finance, healthcare, legal, insurance, supply chain, government).
- Tools/products/workflows: containerized 7B extractor with JSON-schema prompts; LoRA adapters per document type; validation layer that enforces JSON validity; REST/SDK for ingestion; monitoring using JSON-validity and reward metrics.
- Assumptions/dependencies: high-quality text or OCR output; well-defined extraction schema; acceptable latency on available hardware; security controls for PII/PHI.
- AP/AR automation (invoices, receipts, purchase orders)
- Sectors: finance, SMB accounting, retail, logistics.
- Tools/products/workflows: prebuilt schemas (vendor, line-items, taxes); integrations with ERP/accounting (NetSuite, SAP, QuickBooks/Xero); human-in-the-loop exceptions; LoRA adapters per vendor formats.
- Assumptions/dependencies: reliable OCR for scanned documents; vendor layout variability; max context length requires chunking for long statements.
- KYC/AML onboarding and verification (ID docs, proof of address, bank statements)
- Sectors: fintech, banking, crypto exchanges.
- Tools/products/workflows: schema for identity fields, dates, addresses, risk indicators; cross-field consistency checks; compliance audit logs; automated routing for manual review when similarity scores are borderline.
- Assumptions/dependencies: high precision on names/dates (reward may over-tolerate “John Smith” vs “John P. Smith”); document tamper-detection handled by separate system; multilingual support may be needed in production.
- Healthcare claims, prior authorizations, and clinical attachments parsing
- Sectors: payers, providers, healthtech.
- Tools/products/workflows: mapping extracted fields to FHIR resources or EDI (CPT/ICD, provider info, dates); LoRA adapters for payer-specific forms; quality gates (JSON validity, required fields).
- Assumptions/dependencies: HIPAA-compliant deployment; medical domain adaptation for specialized forms; OCR quality on faxed/scanned attachments.
- Legal contract analytics and obligation tracking
- Sectors: legal, procurement, real estate, HR.
- Tools/products/workflows: clause/obligation/exceptions schemas; CLM integration to generate review tasks from JSON; model ensemble with rule-based validators; LoRA per contract family (MSAs, NDAs, leases).
- Assumptions/dependencies: subtle wording differences can be material; semantic reward may mask small but critical deviations—human review recommended for high-risk clauses.
- Regulatory and compliance extraction (SEC, FDA, EU directives)
- Sectors: finance, life sciences, energy, telco.
- Tools/products/workflows: requirement mapping schemas; compliance matrix builders; change monitoring from new filings; lineage/audit trails with structured outputs.
- Assumptions/dependencies: diverse, specialized document types may require further fine-tuning; cross-document linking not yet supported.
- Scientific literature and patent mining (entities, equations, methods)
- Sectors: R&D, pharma, academic publishing, IP.
- Tools/products/workflows: extraction of equations, materials, datasets, experimental conditions into knowledge graphs; ingestion pipelines from arXiv/PubMed; deduplication via list-similarity matching.
- Assumptions/dependencies: technical domain adaptation improves precision; handling of LaTeX/math fidelity vs ASCII constraints; patents and highly specialized formats may need extra training.
- Customer support triage and case structuring (emails, tickets, logs)
- Sectors: SaaS, ITSM, telecom.
- Tools/products/workflows: schemas for issue type, severity, product area, steps-to-repro; RPA trigger integration; analyst dashboards using JSON validity/field coverage.
- Assumptions/dependencies: long threads require chunked memory-preserving processing; noisy inputs; need for domain lexicons.
- Records digitization and open data (FOIA responses, public records)
- Sectors: government, policy, NGOs.
- Tools/products/workflows: bulk pipeline to convert PDFs to structured open data; schema versioning; public auditability via deterministic schema validation.
- Assumptions/dependencies: OCR/legal redaction pipeline; quality variance across historical scans; governance for personally identifiable information.
- HR and recruiting (resume/CV and job spec parsing)
- Sectors: HR tech, staffing.
- Tools/products/workflows: skills/experience/education schemas; ATS integration; candidate-job matching features using list similarity.
- Assumptions/dependencies: fairness/bias monitoring; multilingual resumes; template variability.
- Education operations (syllabi, rubrics, assignments metadata)
- Sectors: education, edtech.
- Tools/products/workflows: LMS connectors; schema for outcomes, grading policies, deadlines; auto-population of course catalogs.
- Assumptions/dependencies: FERPA-compliant deployment; diverse institutional formats.
- MLOps and data-centric AI: synthetic data generation for extractor training
- Sectors: ML platform teams, annotation providers.
- Tools/products/workflows: reuse of memory-preserving augmentation to bootstrap domain-specific datasets; semantic-similarity reward for automatic quality scoring; rapid LoRA adaptation for new schemas.
- Assumptions/dependencies: synthetic-to-real gap; careful benchmark design to avoid leakage; base-model licensing compliance.
- RPA plug-in for document-heavy workflows
- Sectors: cross-industry.
- Tools/products/workflows: UiPath/Automation Anywhere activities that call the extractor; schema version control; exception handling using JSON validity plus confidence thresholds.
- Assumptions/dependencies: latency/SLA constraints and on-prem options; connector maintenance; secure credential handling.
Long-Term Applications
These applications likely require additional research, scaling, or system development beyond what is reported.
- Cross-document entity resolution and corpus-level consistency
- Sectors: finance (KYC/CDD), healthcare (longitudinal records), legal (case bundles).
- Tools/products/workflows: persistent entity memory, canonicalization, and co-reference across documents; knowledge graph builders that reconcile entities over time.
- Assumptions/dependencies: architectural changes to maintain cross-document memory; new training signals and evaluation protocols.
- Multilingual and cross-script extraction
- Sectors: global finance, government, multinational enterprises.
- Tools/products/workflows: multilingual LoRA adapters; multilingual semantic similarity reward; locale-aware date/number parsing.
- Assumptions/dependencies: multilingual training data and evaluation; tokenization and embedding coverage; locale-specific compliance requirements.
- Layout-aware multimodal extraction (forms, tables, scanned images)
- Sectors: insurance, logistics, manufacturing, public sector archives.
- Tools/products/workflows: integration with OCR and layout models (e.g., LayoutLMv3, Donut); table/geometric cues; image+text fusion.
- Assumptions/dependencies: additional compute and training; robust OCR; rights to train on images.
- Learned reward models for extraction quality
- Sectors: all regulated/high-stakes domains.
- Tools/products/workflows: train a reward model from human judgments to catch subtle errors (e.g., middle initials, units, negations); hierarchical error weighting by downstream impact.
- Assumptions/dependencies: labeled assessment datasets; continuous calibration; preventing reward hacking.
- Compliance-grade, auditable extractors with formal guarantees
- Sectors: banking, pharma, defense, utilities.
- Tools/products/workflows: strict schema validators, deterministic decoding, provenance logging, policy checks; certification packages (SOC 2, ISO 27001, GxP).
- Assumptions/dependencies: standardization of test suites; third-party audits; regulatory acceptance.
- Auto-schema induction and standards mapping
- Sectors: healthcare (FHIR), finance (XBRL, ISO 20022), logistics (UBL).
- Tools/products/workflows: propose schemas from sample docs; align extracted fields to domain standards; mapping wizards.
- Assumptions/dependencies: reliability thresholds before autoproduction; human review loop; evolving standards.
- Continual learning with adapter orchestration
- Sectors: BPOs, shared services, SaaS platforms.
- Tools/products/workflows: per-client/per-document-type LoRA adapter zoo; router that selects adapters by document fingerprint; drift detection and retraining pipeline.
- Assumptions/dependencies: MLOps for versioning and rollback; avoiding catastrophic forgetting; governance for model sprawl.
- Privacy-preserving training and deployment (federated/fine-tuning on-prem)
- Sectors: healthcare, government, defense, finance.
- Tools/products/workflows: federated LoRA; differential privacy for updates; encrypted inference.
- Assumptions/dependencies: performance/utility tradeoffs; secure aggregation infrastructure.
- Edge and constrained-environment deployment
- Sectors: field operations, retail, mobile scanning apps.
- Tools/products/workflows: quantization (INT4/INT8), CPU inference pipelines, hardware accelerators; offline extraction on devices.
- Assumptions/dependencies: accuracy under quantization; memory footprint; battery/thermal constraints.
- End-to-end automation with agentic validation
- Sectors: operations, finance close, supply chain reconciliation.
- Tools/products/workflows: agent that validates extracted fields against internal systems (ERP/CRM), requests clarifications, and resolves conflicts; escalation rules.
- Assumptions/dependencies: robust tool-use and planning; reliable external connectors; safeguards against cascading errors.
- Public-sector transparency and open-data standardization at scale
- Sectors: policy, civic tech.
- Tools/products/workflows: mass processing of legacy PDFs to publish structured datasets; change-detection across regulatory updates; public audit dashboards.
- Assumptions/dependencies: funding and governance; records retention and redaction; legal frameworks for data release.
- Cost-optimized large-scale pipelines
- Sectors: enterprises processing millions of documents.
- Tools/products/workflows: distributed hybrid sequential-parallel processing (as proposed) with autoscaling; cost-aware routing (cheap vs. high-accuracy adapters); telemetry-driven optimization.
- Assumptions/dependencies: workload characterization; robust observability; queue backpressure controls.
Cross-cutting Assumptions and Dependencies
- Data quality: Extract-0 assumes text availability; OCR accuracy and layout fidelity heavily influence outcomes.
- Schema quality: Clear, stable schemas are pivotal; auto-schema induction is future work.
- Domain coverage: Out-of-domain formats (patents, niche reports) may require additional LoRA fine-tuning.
- Language scope: Current training is English-only; multilingual production use requires new data and evaluation.
- Context limits: Long documents need chunking with memory-preserving processing; extremely long or interleaved contexts may degrade performance.
- Evaluation-transfer gap: Reported gains come from held-out synthetic tasks; real-world validation and calibration are necessary.
- Governance: PII/PHI handling, auditability, and regulatory compliance must be designed into deployments.
- Licensing/IP: Ensure base model and dataset licenses permit intended commercial use.
Glossary
- bfloat16: A 16-bit floating-point format that balances range and precision, commonly used for efficient mixed-precision training. "The training utilized mixed precision with bfloat16"
- Bipartite matching: An algorithmic technique for optimally pairing elements from two disjoint sets, used here to match predicted and gold list items. "uses a bipartite matching approach"
- Catastrophic forgetting: When a model loses previously learned information during fine-tuning; mitigation techniques aim to preserve prior knowledge. "enabling efficient adaptation without catastrophic forgetting."
- Clipped surrogate objective: A stabilization technique in policy optimization that limits changes to the policy update ratio to prevent destructive updates. "The policy update follows the clipped surrogate objective"
- Context window: The maximum number of tokens a model can consider at once during processing or generation. "ensures that each training example fits within the model's context window."
- Cosine similarity: A metric that measures the cosine of the angle between two vectors, used to assess semantic similarity between text embeddings. "computed using cosine similarity of sentence embeddings"
- FieldSim: A type-aware similarity function that computes field-level semantic similarity for structured outputs. "and \text{FieldSim} is a type-aware similarity function that handles different data types appropriately."
- Generalized Advantage Estimation (GAE): A method to compute low-variance, bias-controlled advantage signals for reinforcement learning. "The advantage estimation employs Generalized Advantage Estimation (GAE)"
- Gradient checkpointing: A memory optimization technique that recomputes intermediate activations during backpropagation to reduce GPU memory usage. "The training infrastructure employed gradient checkpointing to reduce memory consumption"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm variant that updates policies using clipped objectives and advantage estimates. "The reinforcement learning training employed a Group Relative Policy Optimization (GRPO) algorithm"
- Hybrid parallel-sequential architecture: A processing design that runs documents in parallel while treating chunks within each document sequentially to preserve context. "The system processes documents using a hybrid parallel-sequential architecture."
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another; used to regularize policy updates. "maintain the KL divergence within the range [1.5, 3.5]"
- KL penalty coefficient: A scaling factor applied to the KL divergence term to control the strength of regularization during training. "The KL penalty coefficient was dynamically adjusted to maintain the KL divergence within the range [1.5, 3.5]"
- Label masking: A training strategy where only target tokens (e.g., assistant outputs) contribute to the loss, preventing the model from learning to reproduce inputs. "The label masking strategy ensures that the model only receives gradient signals from the assistant's responses"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that injects low-rank trainable matrices into frozen weights to adapt large models. "The supervised fine-tuning phase employed Low-Rank Adaptation (LoRA)"
- Memory-preserving architecture: A design that accumulates extracted information across chunks to ensure consistency and context retention in long documents. "employs a sequential memory-preserving architecture"
- MiniLM: A compact transformer model used to produce sentence embeddings for similarity computation. "from a pre-trained MiniLM model"
- Mixed precision: Training using multiple numeric precisions (e.g., float32 and bfloat16) to improve speed and reduce memory while maintaining stability. "The training utilized mixed precision with bfloat16"
- Parameter-efficient fine-tuning: Techniques that adapt a small subset of parameters to reduce computational cost while achieving strong task performance. "parameter-efficient fine-tuning that adapts only 0.53\% of model weights"
- Policy ratio: The ratio of new to old policy probabilities for an action, used in policy optimization objectives. "where $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}(a_t|s_t)}$ is the probability ratio"
- Schema-guided transformation: Converting unstructured text into structured outputs based on a predefined schema specifying required fields and formats. "schema-guided transformation of unstructured text to structured JSON output"
- Sentence embeddings: Vector representations capturing the semantics of sentences, enabling similarity-based comparisons beyond exact string matches. "computed using cosine similarity of sentence embeddings"
- Sentence transformer model: A transformer variant specialized for producing sentence-level embeddings suitable for semantic similarity tasks. "String fields that cannot be interpreted as dates utilize embedding-based semantic similarity through the sentence transformer model."
- Temporal difference error: The difference between predicted and observed returns used to update value estimates in reinforcement learning. "represents the temporal difference error"
- Tokenizer: The component that converts text into tokens for model input and counts tokens to enforce context limits. "where Tokenizer represents the tokenization function that converts text into tokens."
- Warmup: A learning rate schedule phase that gradually increases the rate at the start of training to improve stability. "The training employed a constant learning rate schedule with warmup"
Collections
Sign up for free to add this paper to one or more collections.

