- The paper introduces OmniBehavior, a benchmark constructed from real-world Kuaishou logs to capture long-horizon, multi-scenario user behavior with high fidelity.
- It details a rigorous pipeline including data cleaning, multi-modal fusion, and anonymization, ensuring robust simulation across five diverse scenarios.
- Evaluation reveals that even state-of-the-art LLMs struggle with long-context reasoning and bias, highlighting the need for advanced memory architectures.
Real-world Human Behavior Simulation: OmniBehavior Benchmark for LLM-based User Simulators
Benchmark Motivation and Construction
LLMs have shown potential for user simulation in interactive systems, but prior benchmarks are confined to narrow, single-scenario datasets or synthetic data, failing to reflect authentic human behavior's complexity. "Towards Real-world Human Behavior Simulation: Benchmarking LLMs on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces" (2604.08362) introduces OmniBehavior, a benchmark built entirely from real-world Kuaishou industrial logs, capturing multi-scenario, long-horizon, and heterogeneous traces. The construction pipeline aggregates data from five major scenarios, applies two-layer data cleaning, multi-modal fusion, and strict anonymization, resulting in a high-fidelity dataset that spans diverse user actions, demographic profiles, and sequence lengths up to 100k steps. This comprehensive benchmark addresses fragmented evaluation settings and sets a rigorous standard for LLM-based user simulation.
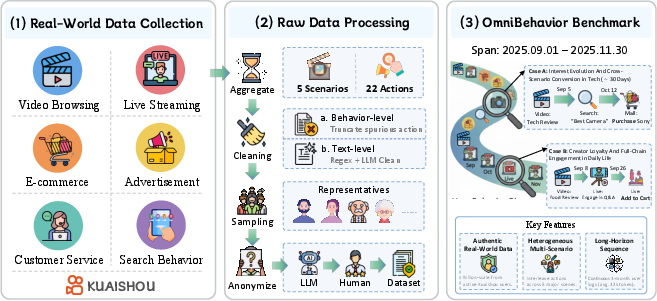
Figure 1: Overview of OmniBehavior, detailing real-world log collection, cleaning, sampling, and anonymization across scenario domains.
Empirical Analysis of Real User Behavior
The paper presents extensive analyses verifying that authentic human behavior modeling requires multi-scenario and long-horizon data. Profile reconstruction illustrates that single-scenario logs yield fragmented and biased user representations, while multi-scenario aggregation increases information coverage by 20–30%, eliminating tunnel vision. Quantitative tracing of 180 conversion events reveals that 81.8% of causal chains span multiple scenarios and persist over days, substantially exceeding traditional short-session windows. A case study demonstrates that a purchase decision accumulates over a 12-day sequence involving heterogeneous actions, confirming the necessity of benchmarks preserving causal integrity and cross-domain dependencies.
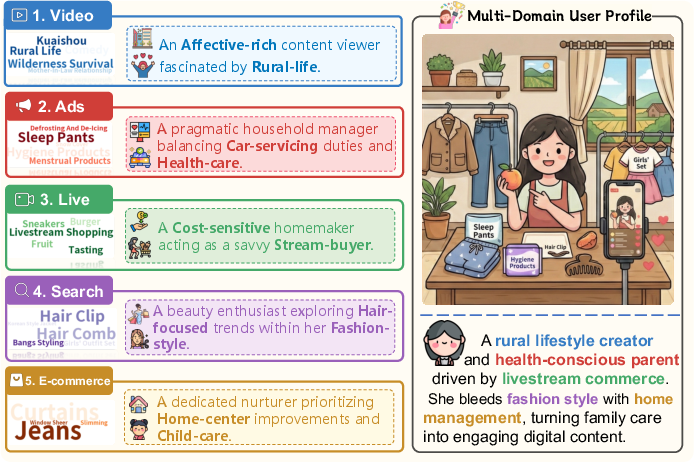
Figure 2: User profile reconstruction shows richer, less biased modeling with multi-scenario data.

Figure 3: Cross-scenario causal chain leading to purchase, evidencing long-term dependencies in user decision-making.
Distributional analysis further finds that synthetic data lacks the stochastic, intertwined interest evolution observed in real trajectories, exhibiting mechanical and abrupt shifts instead. This underscores the irreplaceable value of benchmarks grounded in authentic logs.
Benchmark Scope and Diversity
OmniBehavior encompasses five principal scenarios: video browsing, live streaming, advertisement, e-commerce (including customer service dialogue), and search behavior, covering 22 distinct actions. Sequence lengths exhibit high variance, challenging models to reason over short-term and ultra-long interactions. The sampled user population spans diverse genders, age groups, and interests, capturing heterogeneous preferences and backgrounds essential for robust simulation.
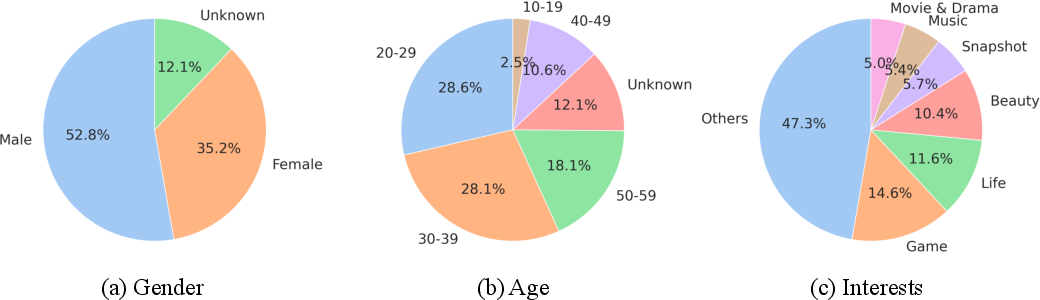
Figure 4: Demographic and behavioral distributions evidence diversity across user population and interests.
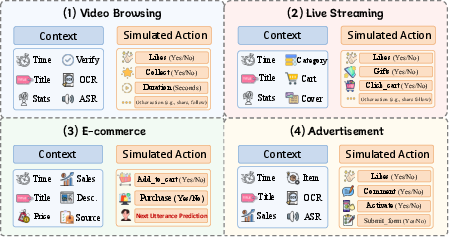
Figure 5: OmniBehavior benchmark schema requires agents to predict heterogeneous behaviors across scenario-specific contexts.
Evaluation of SOTA LLMs
A comprehensive evaluation of both closed-source (Claude-4.5-Opus, Gemini-3-Flash, GPT-5.2, etc.) and open-source (GLM-4.7, DeepSeek-V3, Qwen3-235B, etc.) LLMs on OmniBehavior reveals significant limitations in high-fidelity simulation. Even the best model, Claude-4.5-Opus, achieves an overall score of 44.55, with F1 scores not exceeding 40% for binary actions, indicating that instruction-tuned LLMs are insufficient for capturing long-tail, stochastic, and cross-scenario dependencies. Notably, larger context windows (up to 128K tokens) do not yield consistent improvement; current architectures struggle in long-context reasoning and require advanced memory management.
Structural Bias in LLM Simulation
A systematic comparison reveals a fundamental structural bias termed positivity-and-average bias. LLM-based simulators systematically overestimate action probabilities (hyper-activity bias), erasing negative feedback signals critical for applications like churn prediction. Utterance and sentiment analysis demonstrate a pronounced "Utopian Tendency": LLMs generate highly polite, positive, and conflict-avoiding language, suppressing adversarial and dissatisfied interactions prevalent in real-world logs.

Figure 6: Real user vocabulary reveals friction; LLM simulators default to polite, sanitized language.
Quantitative behavioral analysis shows severe persona homogenization: distributions of intra- and inter-user behavioral distances substantially overlap in simulated populations, unlike the distinct separation found in real users. This convergence toward a generic "average person" undermines the modeling of individual differences and long-tail behaviors, limiting ecological validity.
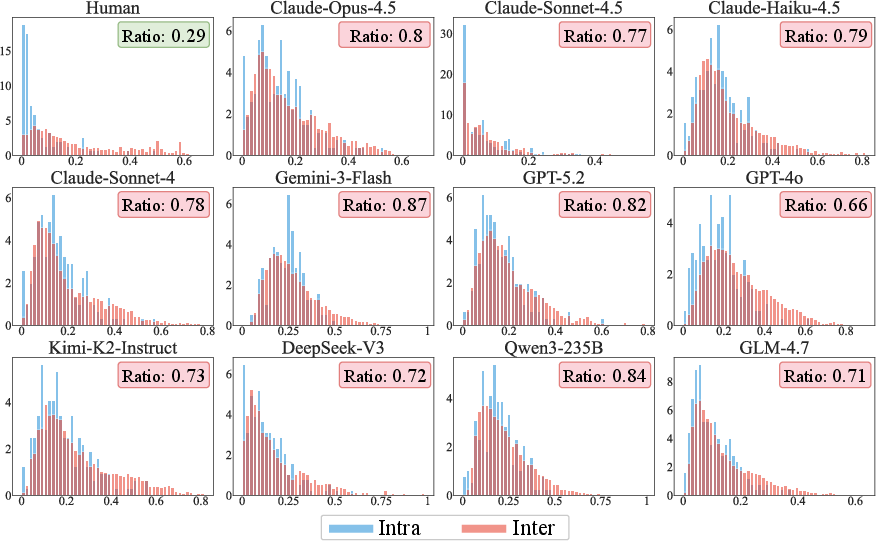
Figure 7: Comparison of behavioral distance distributions; LLM simulators homogenize user personas compared to authentic populations.
Implications and Future Directions
OmniBehavior exposes structural limitations of current LLMs for user simulation at scale. Practically, these findings undermine the reliability of LLM simulators for realistic interactive system evaluation, recommender testing, and behavioral modeling in social sciences. Theoretically, the results highlight deficiencies in long-context reasoning, causal modeling, and representation of behavioral heterogeneity. Addressing these gaps requires advances in memory architectures, structure-aware context integration, calibration for negative and long-tail signals, and techniques to counter alignment-induced persona homogenization. Future developments will likely focus on integrating real-world feedback, causal chain preservation, and explicit modeling of temporal dynamics and adversarial user patterns.
Conclusion
OmniBehavior delivers a new standard for high-fidelity, cross-scenario, long-horizon user simulation benchmarking, revealing substantial capability gaps and structural biases in contemporary LLMs. The benchmark enables rigorous evaluation and will guide future research in modeling authentic, heterogeneous, and causally rich human behaviors. The findings stress the importance of grounding LLM-based simulators in real-world data, with attention to preserving behavioral diversity and causal structure for robust deployment in AI-driven interactive systems.

