Scalable Neural Decoders for Practical Fault-Tolerant Quantum Computation
Abstract: Quantum error correction (QEC) is essential for scalable quantum computing. However, it requires classical decoders that are fast and accurate enough to keep pace with quantum hardware. While quantum low-density parity-check codes have recently emerged as a promising route to efficient fault tolerance, current decoding algorithms do not allow one to realize the full potential of these codes in practical settings. Here, we introduce a convolutional neural network decoder that exploits the geometric structure of QEC codes, and use it to probe a novel "waterfall" regime of error suppression, demonstrating that the logical error rates required for large-scale fault-tolerant algorithms are attainable with modest code sizes at current physical error rates, and with latencies within the real-time budgets of several leading hardware platforms. For example, for the $[144, 12, 12]$ Gross code, the decoder achieves logical error rates up to $\sim 17$x below existing decoders - reaching logical error rates $\sim 10{-10}$ at physical error $p=0.1\%$ - with 3-5 orders of magnitude higher throughput. This decoder also produces well-calibrated confidence estimates that can significantly reduce the time overhead of repeat-until-success protocols. Taken together, these results suggest that the space-time costs associated with fault-tolerant quantum computation may be significantly lower than previously anticipated.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making quantum computers more reliable by catching and fixing their tiny mistakes fast enough to keep up. The authors build a new kind of “decoder” (a smart program) called Cascade that uses neural networks to spot when errors in a quantum computer have combined to flip the meaning of stored information—and to do it quickly enough for real-time use.
What questions were the authors trying to answer?
In simple terms, they asked:
- Can we build a decoder that is both very accurate and very fast for modern quantum error-correcting codes?
- Do today’s codes perform better in practice than older “worst-case” rules of thumb suggest?
- Can a learned decoder give trustworthy “confidence scores” that help reduce the total time needed for big quantum tasks?
How did they approach the problem?
A quick primer: what needs decoding?
Quantum bits (qubits) are fragile. To protect data, quantum computers use quantum error correction (QEC), which spreads information across many qubits. The machine repeatedly measures “checks” (called stabilizers) that don’t reveal the data but do reveal where something “looks off.” The pattern of these “detection events” over space and time is called the syndrome. A decoder’s job is to read this syndrome and say whether the data was flipped in a way that matters (a “logical error”)—and if so, how to fix it.
Think of it like a spellchecker for a long text that only sees hints about where letters might be wrong. The decoder must quickly decide: did the overall meaning change?
The new idea: a structure-aware neural decoder
The authors build a convolutional neural network called Cascade that takes advantage of how many popular QEC codes are laid out like repeating grids. It learns to pass information locally across this grid in a smart way.
They focus on two code families:
- Surface codes (a 2D grid measured repeatedly over time)
- Bivariate bicycle (BB) codes (arranged on a repeating donut-like shape called a torus)
Three design principles make their decoder effective:
- Locality: Errors leave local “footprints,” so the network first fixes nearby patterns, then gradually handles larger ones—like zooming out layer by layer.
- Translation equivariance: The code looks the same in many places, so the same rules can work everywhere on the grid.
- Anisotropy: Different directions mean different things (e.g., time vs. space, or different types of checks), so the network treats directions differently instead of symmetrically.
In practice: the network turns detection events into vectors, passes messages between neighbors using learned “convolutions” that respect the code’s geometry, and finally predicts the chance that each logical bit flipped. It’s trained at one noise level but generalizes across many.
What did they find, and why is it important?
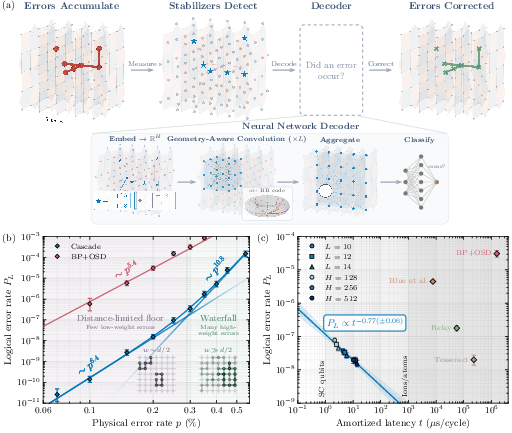
- Much lower logical error rates with modest code sizes
- On a well-known BB code (often called the Gross code), Cascade reaches logical error rates around at a physical error rate of .
- It is up to about 17× more accurate than the best practical alternatives they tested and can beat some by about 4000× in certain settings.
- It reveals a “waterfall” effect that helps in practice
- Textbook rules say that the chance of failure mainly depends on the shortest “bad” patterns (minimum distance). In reality, the authors show there are two regimes:
- A steep “waterfall” where many slightly larger error patterns dominate, causing the logical error rate to drop much faster than expected as gets smaller.
- A “floor” at very low noise where only the absolute smallest bad patterns matter.
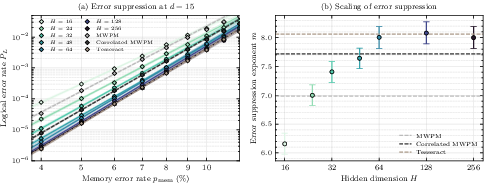
- For the Gross code, they measure a steep part scaling like before it eventually approaches a distance-limited part around .
- This means that, in the noise range relevant to real machines, you can get better protection than simple distance-based estimates predict.
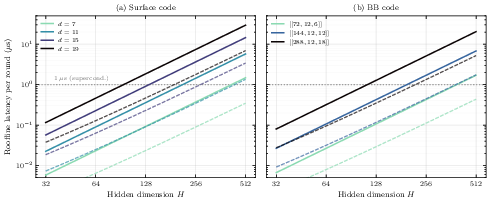
- Speed that fits real hardware timelines
- With a modern GPU (NVIDIA H200), single-shot latency is about 40 microseconds per cycle. With batching, the average time per cycle is much lower.
- That fits comfortably within the real-time budgets for trapped-ion and neutral-atom systems (around 1 millisecond), and the design should map well to specialized hardware for even faster decoding.
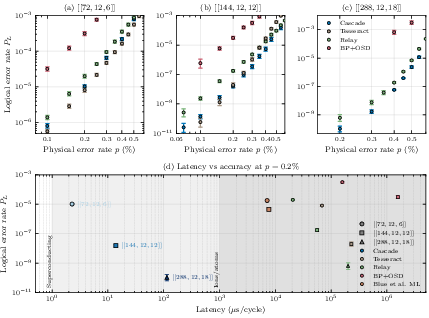
- Strong performance on surface codes, too
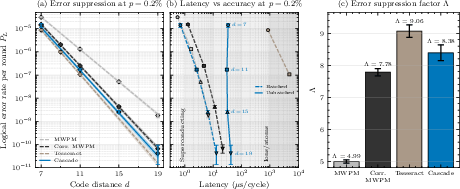
- At a typical noise level (), Cascade’s “error suppression per unit distance” is better than standard matching decoders and close to a strong but slow baseline (“Tesseract”).
- In practical terms, to hit a target logical error rate around , Cascade can use a smaller code (distance ) than standard decoders (often ), saving roughly 40% of physical qubits.
- Trustworthy confidence estimates that cut time overhead
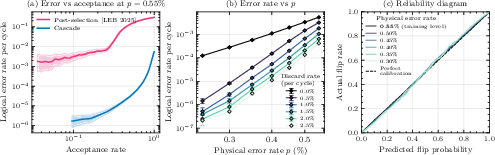
- The decoder not only predicts “error or not,” it also predicts how confident it is. Those confidence scores stay well-calibrated even far from the training noise level.
- If you only accept results when the decoder is confident (and redo the others), you can dramatically lower the effective error rate with only a small fraction of discards.
- Example: on a small BB code at high noise, they achieve about logical error with ~95% acceptance—far better than existing post-selection methods that might accept only ~5% at similar error rates. That can reduce the number of retries for “repeat-until-success” steps (like magic state distillation) by about 20×.
- Generalization and robustness
- Models trained at a single noise level worked well across seven orders of magnitude in logical error rate, without showing a stubborn “error floor.”
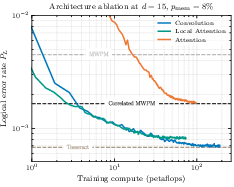
- As the model’s capacity (size) increases, it learns to handle the complex, higher-weight error patterns that simpler decoders miss—unlocking the steep waterfall benefits.
What could this mean for the future?
- Fewer qubits and less time for big jobs: Because the “waterfall” makes error rates drop faster than expected, you may need smaller codes to reach the same target reliability. Combined with fast, confidence-aware post-selection, this can shrink both the space (qubits) and time (retries) costs of fault-tolerant quantum computing.
- Better planning: Resource estimates should consider more than just code distance. The shape of likely error patterns and how well the decoder handles them can change real-world performance a lot.
- Decoder–hardware co-design: Decoding power isn’t a side detail—it directly affects how many qubits and how much time you need. The Cascade approach is local and regular, making it well-suited for acceleration on GPUs, FPGAs, or ASICs.
- Broad applicability: The same ideas work for different code families (surface codes and quantum LDPC codes like BB codes), and should extend to many others that have repeating local structure.
In short, this work shows that smart, geometry-aware neural decoders can make quantum error correction both more accurate and fast enough for real devices. That brings practical, large-scale quantum computing a meaningful step closer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open problems that the paper leaves unresolved and that future work could address:
- Lack of rigorous decoding guarantees: The neural decoder has no formal correctness guarantees (e.g., provable correction up to weight or thresholds), and the absence of observed error floors down to is empirical; develop analytical bounds or adversarial tests to certify worst-case behavior.
- Incomplete characterization of the “waterfall”: The paper infers two power-law regimes but does not quantify or enumerate the minimal failure mode spectrum ; devise methods to compute/estimate for quantum LDPC codes, relate it to code structure, and tie decoder design to maximizing the steep-waterfall exponent.
- Limited noise models: Results are reported for circuit-level and data-level depolarizing noise; evaluate robustness under realistic hardware noise (biased dephasing, amplitude damping, leakage, measurement bias, erasures/flags, coherent/non-Markovian and spatiotemporal correlations, cross-talk, qubit-heterogeneous error rates).
- Domain shift robustness: Although trained at a single noise level, generalization is demonstrated only across depolarizing rates; test performance and calibration under distribution shifts common in hardware (drifts, calibration changes, different gate schedules, changing measurement fidelities).
- Boundary and defect effects: The approach assumes bulk translation symmetry; quantify performance impacts near boundaries, defects, and dislocations, and extend to irregular layouts (patch codes, rotated patches, missing qubits).
- Operations beyond memory: The study targets memory experiments with static checks; extend to dynamic fault-tolerant operations (lattice surgery, braiding, gauge fixing), time-varying Tanner graphs, and measurement schedules with hook-error structure.
- Scalability to larger distances and code sizes: Results are shown up to (surface) and (BB); characterize latency, memory, and accuracy scaling for and for high-rate qLDPC codes with larger and , including multi-logical-qubit interactions.
- Latency for superconducting platforms: Single-shot latency (s/cycle on an H200) exceeds the s budget for superconducting qubits; validate and quantify speed-ups from FPGA/ASIC implementations (beyond roofline estimates), including end-to-end I/O and memory-movement costs.
- Hardware implementation details: No prototype on dedicated hardware is presented; investigate fixed-point/quantized inference, memory footprint, throughput under on-chip bandwidth limits, and robustness to hardware-induced numerical errors.
- Fairness of speed comparisons: Baselines are single-threaded CPU; compare against optimized, parallelized, and GPU/FPGA implementations of competing decoders to isolate algorithmic from hardware advantages.
- Training cost and data requirements: The paper does not detail training compute, dataset sizes, or wall-clock costs; quantify training budgets, sample efficiency, and the feasibility of retraining across codes/distances/noise settings.
- Cross-distance and cross-code transfer: It is not shown whether one trained model generalizes across distances or codes without retraining; test zero-shot and few-shot transfer across , boundary conditions, and different qLDPC families.
- Online/continual learning on hardware: Strategies to adapt to drift during operation (online updates, meta-learning) are not explored; design safe adaptation schemes that maintain fault-tolerance guarantees.
- Batch normalization at inference: The architecture uses batch normalization; assess sensitivity of BN running statistics to distribution shift and real-time streaming (small batches), and evaluate alternatives (layer/group norm) for deployment.
- Handling missing/delayed data: Real systems may drop or delay syndrome rounds; develop robust streaming decoders that handle missing data, variable , and backpressure with bounded performance loss.
- Exploiting soft information: The decoder consumes binary detection events; investigate incorporating analog/log-likelihood or confidence-weighted measurements from hardware to improve decoding.
- Integration with flagged/erasure information: Modern circuits provide flag qubits and erasure markers; extend the model to ingest flags/erasures and quantify gains over binary-only inputs.
- Confidence calibration theory and limits: Calibration is demonstrated empirically; analyze why calibration persists under noise variation, develop formal guarantees, and evaluate robustness to mismatch or temporal drift.
- Post-selection in full FT pipelines: While acceptance-rate vs. tradeoffs are shown, the impact on end-to-end factory throughput, scheduling, and space–time tradeoffs in magic/entanglement distillation remains unquantified; perform pipeline-level simulations.
- Multi-logical-qubit scaling: For high-rate codes () with many logical operators, the pooling and head-per-observable strategy may scale poorly; study computational scaling and interference between logical observables.
- Waterfall-aware resource estimation: The paper argues for revised estimates but provides no general methodology; build predictive models that include waterfall behavior, decoder capacity, and to guide code/architecture co-design.
- Decoder capacity threshold: The observed capacity “threshold” (e.g., ) is empirical; characterize capacity–accuracy curves across architectures, derive scaling laws, and identify minimal models that preserve near-optimal performance.
- Universality across code families: Claims of broad applicability are not empirically validated beyond surface and BB codes; test on other qLDPC families (lifted-product, hyperbolic, Kasai, etc.) and on subsystem/gauge codes.
- Streaming/rolling-window inference: The study evaluates fixed ; design and benchmark causal, rolling-window decoders that minimize latency while approaching full-volume accuracy.
- Interpretability and failure analysis: The learned message-passing rules are opaque; develop tools to extract failure modes, detect “neural trapping sets,” and provide actionable diagnostics for decoder design.
- Reliability engineering of the classical stack: Faults in classical decoding (e.g., bit flips in memory, transient computation errors) are not considered; assess their impact on logical error rates and required classical fault-tolerance.
- Open-source reproducibility: Detailed circuit schedules, code, and datasets are not described as released; provide artifacts to reproduce figures (especially low- regimes) and enable community benchmarking.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be realized with current hardware and software capabilities, drawing directly from the paper’s findings on the Cascade neural decoder, its latency/throughput, and calibrated confidence outputs.
Industry
- Real-time decoding for trapped-ion and neutral-atom QEC experiments
- Sectors: quantum hardware, control systems, cloud quantum services
- What: Integrate GPU-based Cascade inference in the control stack to decode surface and qLDPC (e.g., BB) codes within per-cycle budgets (~40 μs single-shot on H200; far lower amortized). Use batched decoding for buffered rounds in memory experiments or deep Clifford circuits.
- Tools/products/workflows: CUDA/Triton kernels; decoder daemon connected to the control plane; syndrome-buffering pipelines; per-shot “confidence tags” returned with corrections.
- Assumptions/dependencies: Physical error rates ≲0.1–0.2%; mid-circuit measurement/control latencies ≥O(100 μs) (e.g., ions, atoms); streaming syndrome interfaces; close match between training and hardware noise.
- Confidence-aware post-selection in repeat-until-success protocols
- Sectors: quantum software, compilers, workflow orchestration
- What: Use calibrated confidence estimates to discard low-confidence cycles, reducing retries in magic-state and entanglement distillation (demonstrated up to ~20× fewer retries at high p on small BB codes).
- Tools/products/workflows: Acceptance-threshold tuning in schedulers; confidence-aware factory controllers; logs for acceptance vs. yield analysis.
- Assumptions/dependencies: Probability calibration persists under real noise; additional buffering allowed; small discard rates acceptable for throughput targets.
- Waterfall-aware resource estimation and device design
- Sectors: hardware architecture, consulting, developer tooling
- What: Update logical-error models to include the waterfall regime; reduce required code distance for target logical error (e.g., surface code d=15 vs. d=19), lowering qubit counts by ~30–40% at p≈0.1–0.2%.
- Tools/products/workflows: Enhanced resource-estimation calculators; code-distance planners; meta-schedulers that trade code distance vs. acceptance thresholds.
- Assumptions/dependencies: Observed exponents generalize to deployed devices; consistent performance across code families and layouts; verification against hardware data.
- Decoder-as-a-Service (DaaS) for quantum cloud platforms
- Sectors: cloud, software, managed services
- What: Host trained decoders to ingest syndrome streams and return corrections + confidences; batch to maximize throughput for offline post-processing (memory experiments, benchmarking).
- Tools/products/workflows: REST/gRPC APIs; GPU-backed microservices; customer-specific model fine-tuning; SLAs for throughput and accuracy.
- Assumptions/dependencies: Network latency excludes tight in-loop feedback; data privacy/tenancy policies; cost-effective GPU time.
- Benchmarking and acceptance testing for qLDPC deployments
- Sectors: hardware QA, code vendors, integrators
- What: Use Cascade as a high-accuracy, high-throughput baseline to evaluate new code constructions and hardware stacks; map waterfall onset and slopes across devices.
- Tools/products/workflows: Standardized syndrome datasets; continuous benchmarking pipelines; regression dashboards.
- Assumptions/dependencies: Access to representative noise/interleavings; compute budget for model evaluation; reproducible training seeds and datasets.
Academia
- Probing waterfall regimes and failure-mode spectroscopy
- Sectors: quantum information, error-correction theory
- What: Use Cascade to expose high-weight minimal failure modes and measure the two-regime (waterfall/floor) behavior that typical decoders miss.
- Tools/products/workflows: Syndrome simulation suites; failure-mode counting and clustering; comparisons across code families.
- Assumptions/dependencies: Sufficient model capacity (H≥64 in paper) and training compute; careful separation of data-level vs. circuit-level noise analyses.
- Curriculum and training modules on ML-based decoding
- Sectors: education
- What: Course labs demonstrating translation-equivariant, anisotropic convolutional decoders; hands-on calibration and post-selection exercises.
- Tools/products/workflows: Teaching notebooks; open-source toy implementations; datasets of synthetic and hardware-derived syndromes.
- Assumptions/dependencies: Moderate GPU availability; simplified codes for classroom scale.
Policy
- Updated benchmarks and procurement guidelines for FTQC
- Sectors: standards bodies, government programs, industry consortia
- What: Add decoder throughput/latency and confidence calibration metrics to RFPs and benchmarks; recognize decoder co-design as first-class in FTQC roadmaps.
- Tools/products/workflows: Benchmark suites specifying code families, noise models, latency budgets; conformance tests for calibration.
- Assumptions/dependencies: Community agreement on metrics; availability of open benchmarks; vendor-neutral testing.
Daily Life
- Outreach and literacy tools
- Sectors: education/outreach
- What: Interactive demos illustrating waterfall scaling and confidence-aware post-selection to explain how ML accelerates reliable quantum computing.
- Tools/products/workflows: Web-based visualizations; small simulators with tunable “acceptance” sliders.
- Assumptions/dependencies: Simplified models; non-expert-friendly UIs.
Long-Term Applications
These applications require further research, scaling, or co-design (hardware/algorithm integration), but are strongly suggested by the paper’s methods and results.
Industry
- Sub-μs, in-loop decoders for superconducting platforms
- Sectors: semiconductors, quantum control electronics
- What: FPGA/ASIC implementations of the local, feed-forward convolutional decoder with quantized weights and deterministic pipelines to meet ~1 μs budgets.
- Tools/products/workflows: RTL IP blocks; high-throughput on-chip interconnects to readout electronics; cryo-compatible variants.
- Assumptions/dependencies: Hardware design cycles; aggressive quantization without accuracy loss; tight memory footprints; reliable low-latency I/O.
- Unified decoders for large, high-rate qLDPC families
- Sectors: hardware, software
- What: Extend Cascade to lifted-product, Kasai, and emerging qLDPC codes at larger distances; exploit stronger waterfalls to reduce overheads.
- Tools/products/workflows: Generalized toroidal/Cayley-graph convolutions; scalable training across devices; code-aware hyperparameter auto-tuning.
- Assumptions/dependencies: Adequate training data; architectural adaptations to stabilizer degrees/connectivity; stability at very large d.
- Runtime-adaptive QEC and scheduling driven by confidence
- Sectors: quantum orchestration, compilers
- What: Use per-shot confidence to vary syndrome rounds (early-stop), route outputs to different distillation stacks, or trigger dynamic retries—all in real time.
- Tools/products/workflows: Policy engines for acceptance gates; runtime monitors; feedback to analog control.
- Assumptions/dependencies: Closed-loop schedulers; robust calibration under drift; safeguards against rare miscalibration.
- Continuous-learning decoders (online fine-tuning on hardware logs)
- Sectors: MLOps for QEC
- What: Pipelines to ingest syndromes, detect distribution shifts, and fine-tune decoders to device-specific noise (domain adaptation).
- Tools/products/workflows: Drift detectors; federated learning across fleets; A/B deployments with rollback.
- Assumptions/dependencies: Data governance; avoiding overfitting; safe update policies for in-loop ML.
- Cross-pollination to classical LDPC in communications/storage
- Sectors: telecom (5G/6G), data storage, networking
- What: Apply structure-aware, anisotropic, translation-equivariant neural message passing to LDPC decoding where regular geometries exist, improving waterfall-region performance with hardware-friendly kernels.
- Tools/products/workflows: Local, deterministic CNN blocks for baseband/FEC ASICs; training at high SNR with cross-generalization.
- Assumptions/dependencies: Mapping to code structures used in practice; strict power/latency envelopes; certification in standards.
Academia
- Code–decoder co-design to shape failure-mode spectra
- Sectors: quantum coding theory
- What: Design codes that both raise minimum distance and sculpt the multiplicity distribution N(w) to maximize waterfall steepness under learned decoders.
- Tools/products/workflows: Differentiable code construction; search guided by learned decoders; new metrics beyond distance.
- Assumptions/dependencies: Efficient surrogates for logical error vs. structure; compute resources for joint optimization.
- Foundational studies of calibration and uncertainty in QEC
- Sectors: statistics for physical systems
- What: Theoretical and empirical frameworks for calibrated probabilities under nonstationary or correlated noise; safety bounds for post-selection.
- Tools/products/workflows: Reliability diagrams at scale; conformal prediction for syndromes; robust training objectives.
- Assumptions/dependencies: Access to long-horizon hardware logs; standardized datasets.
Policy
- Roadmap adjustments for FTQC timelines and PQC migration
- Sectors: cybersecurity policy, national roadmaps
- What: Revise qubit-count/timeline estimates for large-scale algorithms given lower space–time overheads; re-evaluate post-quantum cryptography urgency.
- Tools/products/workflows: Scenario analyses incorporating decoder-enabled reductions; sensitivity studies by hardware modality.
- Assumptions/dependencies: Hardware progress to ≤0.1% gate errors; reproducible decoder performance in the field.
- Standards for QEC telemetry and ML-in-the-loop safety
- Sectors: standards bodies, regulators
- What: Define reporting for decoder latency, error suppression factor, calibration curves; guidelines for fail-safe behavior of ML decoders in control loops.
- Tools/products/workflows: Compliance test suites; incident reporting; red-team evaluations of miscalibration risks.
- Assumptions/dependencies: Community buy-in; vendor cooperation; interoperability targets.
Daily Life
- Earlier availability of practical quantum applications
- Sectors: healthcare (drug discovery), materials, logistics, finance
- What: As space–time overheads drop, fault-tolerant workloads (quantum chemistry, optimization, simulation) arrive sooner, improving R&D cycles and downstream services.
- Tools/products/workflows: FTQC workflows scaled to “utility-grade” logical error rates (10⁻¹⁰–10⁻¹²); hybrid cloud integrations.
- Assumptions/dependencies: End-to-end system readiness (algorithms, compilers, control); sustained hardware advances; economic viability.
Notes on feasibility across applications
- The demonstrated gains rely on code families with regular, translation-like structure and current physical error rates near 0.1–0.2%. Performance may degrade for irregular codes unless the convolution is adapted (or replaced by a GNN).
- Single-shot latency targets differ by modality: ions/atoms permit O(1 ms), while superconducting demands ~1 μs, likely requiring dedicated hardware.
- Training at a single high-noise level generalized well in simulations; real devices may need fine-tuning for non-ideal, time-varying noise.
- Quantization and compression will be essential for hardware deployment; maintaining calibration and accuracy after compression is a key dependency.
Glossary
- Anisotropy: Direction-dependent behavior where information from different directions has distinct meaning for decoding. "Third, anisotropy: information arriving from different directions carries distinct meaning---for instance, a surface code stabilizer's horizontal and diagonal neighbors are of different type (X versus Z), and the temporal direction encodes measurement errors rather than data qubit errors."
- Bivariate bicycle (BB) codes: A family of quantum LDPC codes defined on a torus with regular, translation-symmetric stabilizer structure. "3D convolutions for surface codes, generalized convolutions on the torus for bivariate bicycle (BB) codes"
- Circuit-level depolarizing noise: A realistic noise model where depolarizing errors can occur on gates, measurements, and idle qubits throughout the circuit. "Distance scaling of BB code decoders under circuit-level depolarizing noise."
- Clifford circuits: Quantum circuits composed of Clifford gates (e.g., H, S, CNOT), often used in error-correction and stabilizer operations. "as in memory experiments or deep Clifford circuits."
- Correlated MWPM: A variant of minimum-weight perfect matching that incorporates correlations between X and Z error types to improve accuracy. "Logical error rate per round versus code distance for MWPM, correlated MWPM, Tesseract, and Cascade."
- Data-level depolarizing noise: A simplified noise model where depolarizing errors act only on data qubits (used here for training efficiency). "Logical error rate versus memory error rate at distance for surface code models with varying hidden dimension (data-level depolarizing noise, used here for training efficiency)."
- Degeneracy: The phenomenon where many different physical error patterns yield the same syndrome, so only the error’s equivalence class matters. "Because many different physical error patterns can produce the same syndrome (degeneracy), the decoder need only identify the equivalence class of the error, not the exact error."
- Detection events: Changes in stabilizer measurement outcomes between rounds that signal the presence of errors. "errors accumulate on data qubits; stabilizer measurements produce a spacetime syndrome (pattern of detection events); a decoder determines whether a logical error occurred"
- Distance-limited floor: The regime where logical error scaling is ultimately limited by the code distance, dominating at very low physical error rates. "transitioning to a distance-limited floor () at very low noise."
- Error floor: A non-vanishing logical error rate plateau that can occur if systematic decoding failures persist; absence indicates continued exponential suppression. "We observe no error floor: exponential error suppression persists to the lowest physical error rates tested"
- Error suppression factor Λ: A multiplicative factor characterizing exponential decrease of logical error with code distance below threshold. "Below the code's threshold error rate, decreases exponentially with code distance, characterized by the error suppression factor such that ."
- Gross code: A specific high-rate bivariate bicycle code instance used as a benchmark (e.g., ⟦144,12,12⟧). "For example, for the Gross code~\cite{bravyi2024high}, the decoder achieves logical error rates up to below existing decoders"
- Hyperbolic surface codes: Topological quantum codes defined on hyperbolic lattices, offering alternative trade-offs of distance and rate. "hyperbolic surface codes~\cite{breuckmann2021quantum}, and other quantum LDPC codes defined on periodic lattices or Cayley graphs."
- Lifted-product codes: A family of quantum LDPC codes built via lifted product constructions that can yield good distances and rates. "including lifted-product codes~\cite{xu2024constant}"
- Logical observable: A measurement corresponding to a logical Pauli operator on the encoded qubits. "and a prediction head applied independently to each logical observable."
- Low-density parity-check (LDPC) codes: Codes defined by sparse parity-check matrices that enable efficient error correction; in quantum form, they support scalable fault tolerance. "quantum low-density parity-check codes have recently emerged as a promising route to efficient fault tolerance"
- Magic state distillation: A protocol that purifies noisy non-Clifford states to enable universal fault-tolerant computation. "such as magic state distillation~\cite{campbell2017roads}."
- Minimum-weight perfect matching (MWPM): A standard decoder for topological codes that pairs syndrome defects along least-weight paths. "For surface codes, minimum-weight perfect matching (MWPM) is the dominant decoding approach~\cite{dennis2002topological,higgott2022pymatching,higgott2025sparse}."
- Ordered statistics decoding (OSD): A post-processing method that improves BP decoding by solving a reduced linear system, often at higher computational cost. "Our largest model (, ) achieves logical error rates orders of magnitude below belief propagation with ordered statistics decoding (BP+OSD)~\cite{roffe2020decoding}"
- Post-selection: Discarding outcomes judged unreliable to reduce logical errors at the cost of acceptance rate. "Calibration enables post-selection: by discarding low-confidence predictions (measured by the output confidence), we achieve lower logical error rates at the cost of reduced acceptance rate"
- Receptive field: The region of the input (syndrome) that influences a unit’s output; grows with convolutional layers to capture larger-scale correlations. "Successive layers expand the receptive field, so that after layers the network integrates information across the full code distance"
- Repeat-until-success protocols: Procedures that retry probabilistic operations until a desired outcome occurs, impacting time overhead. "repeat-until-success protocols~\cite{smith2024mitigating,zhou2025error,menon2025magic}"
- Stabilizer code: A quantum code defined by commuting Pauli operators (stabilizers) whose measurement detects errors on encoded qubits. "A stabilizer code encodes logical qubits into physical qubits, protecting against errors up to weight "
- Syndrome: The spacetime pattern of detection events obtained from stabilizer measurements that the decoder uses to infer errors. "The decoding problem is to infer, from this syndrome, the equivalence class of the error"
- Tanner graph: A bipartite graph representing variable (data qubit) nodes and check (stabilizer) nodes used for message passing in decoding. "belief propagation performs local message passing on the bipartite Tanner graph"
- Toric codes: Topological quantum codes defined on a torus, closely related to surface codes but with periodic boundaries. "toric codes, hyperbolic surface codes~\cite{breuckmann2021quantum}, and other quantum LDPC codes"
- Torus : The periodic lattice on which BB codes are defined, enabling translation symmetry. "a torus for BB codes"
- Translation equivariance: The property that shifting the input leads to a corresponding shift in the output, matching the code’s spatial regularity. "Second, translation equivariance: the identical local structure at every site means the same decoding rules should apply everywhere."
- Trapping sets: Problematic substructures that cause iterative decoders like BP to stall or converge to wrong solutions. "trapping sets~\cite{poulin2008iterative,raveendran2023trapping} (patterns that cause it to converge to incorrect solutions)"
- Union-find decoders: Fast, structure-exploiting decoders for surface codes that trade some accuracy for speed. "Union-find decoders offer a faster alternative with simpler operations, though with somewhat lower accuracy~\cite{delfosse2021almost}."
- Waterfall: The steep regime of rapidly decreasing logical error below threshold, driven by many higher-weight failure modes rather than minimum-weight ones. "a steep waterfall () where the numerous high-weight failure modes dominate at moderate physical error rates "
- Weight-sharing: Using the same learned parameters across spatial positions to exploit translation symmetry in convolutional decoders. "This regularity enables weight-sharing across the code, just as for surface codes."
Collections
Sign up for free to add this paper to one or more collections.