- The paper introduces IRRL, combining incremental learning and residual RL to continuously adapt social navigation policies in resource-constrained settings.
- It leverages a fixed social force model alongside a GNN-based residual actor-critic policy, achieving near state-of-art success rates with sample efficiency.
- Real-world trials demonstrate enhanced collision avoidance and stable adaptation on mobile robots, validating IRRL's practical deployment benefits.
Incremental Residual Reinforcement Learning: A Framework for Real-World Social Navigation
Introduction and Motivation
The increasing operational deployment of mobile robots within environments populated by humans necessitates robust social navigation capabilities. As human navigation conventions and crowd dynamics are region- and context-dependent, policies tuned in simulation frequently demonstrate limited sim-to-real transfer for real-world operation. Real-world RL—enabling robots to learn adaptively from actual interactions—can address generalizability, but the practical limitations of edge-compute capabilities and stringent sample-efficiency requirements present substantial barriers. Most existing DRL for navigation is not designed for continual adaptation on resource-constrained platforms, heavily depending on components such as replay buffers and batch updates that are ill-suited to real-world robotic scenarios. This paper introduces Incremental Residual Reinforcement Learning (IRRL), a framework that synthesizes incremental learning and residual RL to deliver efficient, stable online policy refinement under realistic constraints (2604.07945).
Social navigation RL has evolved from simple collision-avoidance to interaction-aware, representation-rich paradigms, e.g., those leveraging GNNs with attention, yet these routinely rely on simulated crowd scenarios. Recent works exploring real-world RL often distribute compute to external infrastructure or necessitate persistent connectivity, which is incompatible with most autonomy requirements. Incremental learning circumvents this by eschewing buffers and batch updates, enabling data-efficient, computation-light online adjustment. Additionally, residual RL frameworks facilitate rapid and safe learning by refining an existing robust (often classical) policy, focusing data efficiency on compensating for the base policy’s deficiencies rather than global behavior learning from scratch.
IRRL Framework
IRRL unifies the strengths of streamlined incremental optimization and residual RL. The design leverages a fixed Social Force Model (SFM) as the base policy, which provides baseline crowd-avoidance and social compliance. A residual RL policy is trained to refine base actions, yielding an aggregate behavior that both respects social forces and adapts to context-specific empirical nuances.
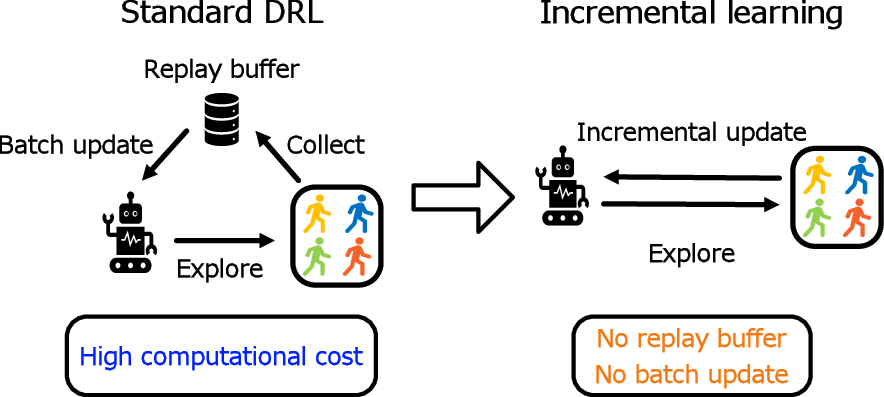
Figure 1: The schematic situates incremental RL as a superior fit for resource-constrained devices compared to standard deep RL approaches reliant on extensive replay buffers.
The residual policy is modeled within an actor-critic framework. Both the actor and critic accept aggregated crowd state embeddings (integrated via GATv2-based GNNs), which naturally accommodates environments with varying numbers of dynamic pedestrians.
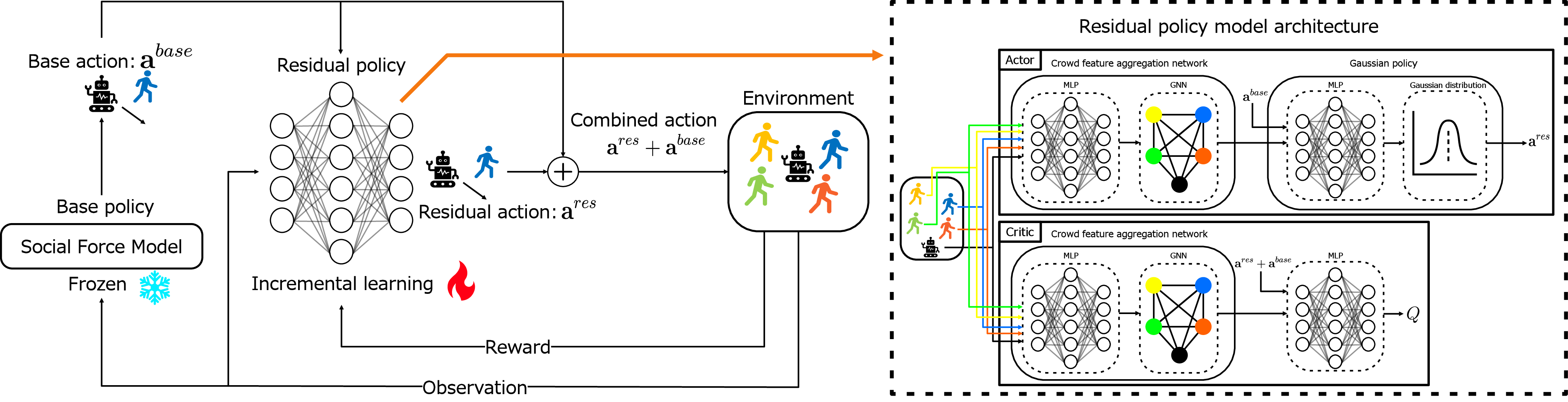
Figure 2: The IRRL architecture incrementally updates a GNN-based residual actor-critic policy over a frozen SFM base; only most-recent observations are used for updates.
IRRL incorporates several stabilizing mechanisms drawn from contemporary RL literature:
- Penultimate normalization is utilized for both actor and critic feature representations to reduce variance.
- TD error scaling is employed for robust gradient propagation by normalizing errors relative to a running estimate of their magnitude.
- Automatic entropy tuning is included to maintain optimal exploration–exploitation balance.
Critically, IRRL omits target networks and double-Q methods to minimize computational and memory overhead for embedded/edge platforms.
Simulation Results
Experiments in CrowdNav’s circle-crossing environments with five pedestrians controlled by either SFM or ORCA underscore IRRL’s efficacy. The method is compared against: (i) SFM base policy; (ii) replay buffer based RL methods (SAC, TD3, PPO, each as a residual policy); and (iii) various incremental RL baselines (Stream AC(λ), SAC-1, TD3-1). Over 100,000 training episodes and 500 evaluation trials, IRRL reliably approaches the performance of the off-policy batch-updating methods while maintaining vastly superior stability and sample-efficiency compared to incremental baselines.
In SFM pedestrian settings, IRRL attains a success rate of 98.8% (collision rate 1.2%, average return 0.666), and in the more challenging ORCA case, 98.4% success (1.5% collision, 0.635 return). This is within statistical proximity to the best replay-buffered methods, a substantial advance given IRRL’s minimal computational and storage cost.
Learning curves demonstrate not only rapid convergence but also variance reduction and elimination of catastrophic failure cases that occur in other incremental methods.
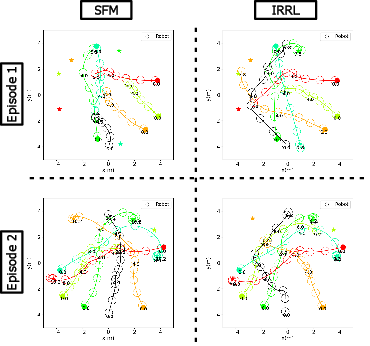
Figure 4: Trajectories produced by IRRL consistently bypass the inefficiencies and failures present in the base SFM strategy.
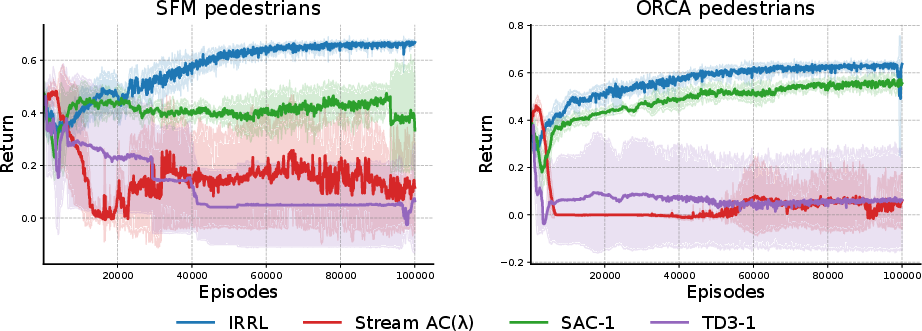
Figure 3: IRRL exhibits the fastest and most stable learning among incremental RL baselines across both SFM and ORCA pedestrian environments.
Residual RL Contribution
Ablation experiments isolating the effect of the residual RL paradigm show that removing the SFM base (i.e., learning from scratch) dramatically increases performance variance and introduces risk of policy collapse. The residual structure not only fast-tracks convergence but also provides a robust anchor for continuous online learning.
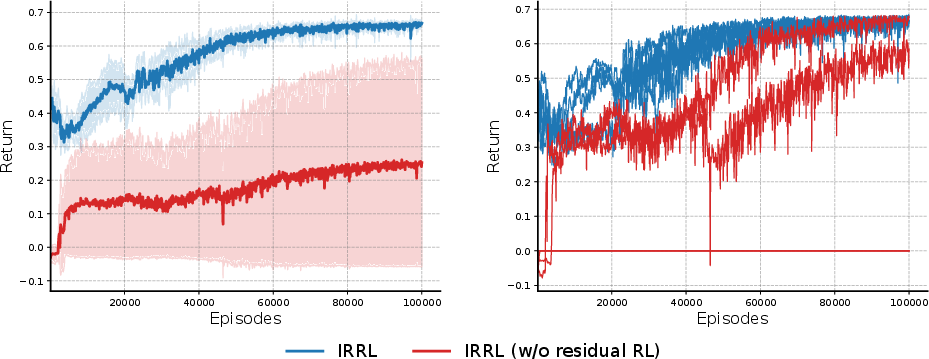
Figure 7: Incorporation of the residual RL component yields accelerated average return improvement and reduces variance across random seeds.
Real-World Experiments
Evaluation proceeds to a hybrid real-physical setup using a Mecanum-wheeled robot with 3D-LiDAR and onboard inference (Jetson AGX Orin). Pre-trained in simulation, the robot adapts over 100 online episodes in environments with physical and mixed (virtual/physical) pedestrians. Perceptual stack includes DR-SPAAM-based detection and EMCL for self-localization, deployed entirely onboard.

Figure 5: Hybrid real-world environment visualization highlighting the integration of virtual pedestrians within the robot’s perception.
Over 100 re-learning episodes, the robot achieves measurable gains in navigation metrics in both physical and hybrid pedestrian setups:
- Success rates in physical pedestrian settings increase from 40% to 60%, with collision rate dropping accordingly.
- In virtual/physical hybrids, success rises from 52% to 82%.
The increased execution time post-adaptation is ascribed to the behavioral divergence between cooperative (simulation) and uncooperative (real) pedestrian actors—deliberate stalling emerges as the optimal collision-avoidance action under novel real-world dynamics.
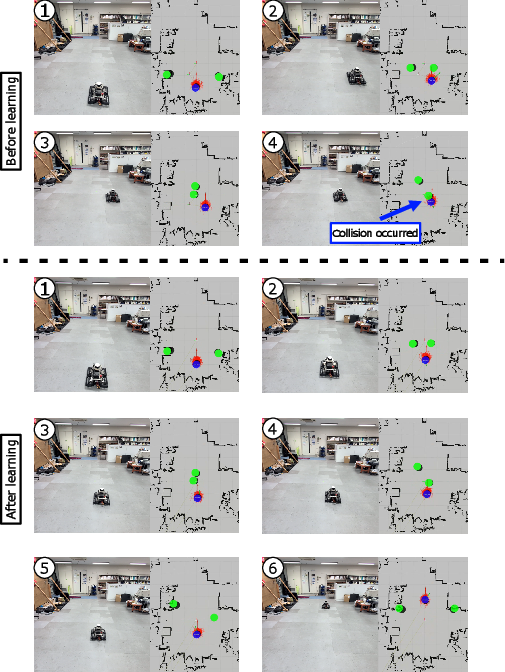
Figure 6: Pre- and post-adaptation robot navigation in the hybrid environment; after learning, the agent exhibits effective collision avoidance.

Figure 8: Real-environment adaptation enables the robot to shift from unsafe aggressive crossing to safe, socially compliant waiting strategies.
Implications and Future Directions
IRRL makes formally significant advances toward scalable, stable, and sample-efficient online policy refinement for real-world robot social navigation. By structurally eliminating buffer/batch dependencies while leveraging robust base policies, IRRL renders continual RL feasible even for systems with modest hardware resources. This opens avenues for on-the-fly adaptation in heterogeneous, evolving environments—critical for widespread, long-term real-world deployment. Future directions include continuous, lifelong learning, co-evolution with time-varying pedestrian norms, and larger-scale deployment in urban and social settings.
Conclusion
IRRL effectively merges incremental learning and residual RL to enable real-world online adaptation for social navigation within severe compute and sample-efficiency constraints. Both simulation and physical experiments confirm strong performance, robust stability, and successful domain transfer, establishing IRRL as an authoritative baseline for further research in on-device, continual robot social policy learning (2604.07945).