- The paper introduces a reinforcement fine-tuning framework that augments LLMs with dual-graph reward shaping, segmented reasoning supervision, and an online curriculum scheduler.
- The model achieves up to 13.2% absolute gains and preserves 90% core accuracy, demonstrating robust performance on misinformed and complex queries.
- Ablation studies highlight the critical role of reasoning-aware advantage estimation, with optimal penalty tuning ensuring stable learning.
ReRec: Reinforcement Fine-Tuning for Reasoning-Augmented Recommendation Assistants
Motivation and Problem Setting
ReRec addresses challenges in leveraging LLMs for recommendation assistants facing complex, multi-constraint user queries expressed in natural language. Unlike conventional RecSys based on MF/GNNs, LLMs have the potential to utilize nuanced language and context, but often suffer from limitations in multi-step reasoning and reward sparsity when trained via standard supervised fine-tuning or RL with coarse metrics such as NDCG. Complex queries require decompositional reasoning, query constraint alignment, and personalization, which are difficult to supervise when naive reward models yield undifferentiated signals.

Figure 1: Example of Reasoning-Augmented LLM-based Recommendation Assistant requiring multi-step inference and constraint tracking.
Methodological Framework
ReRec introduces an RFT framework tailored for recommendation reasoning, composed of three core mechanisms:
- Dual-Graph Enhanced Reward Shaping: Integrates classical recommendation metrics (NDCG@K) with Query Alignment Score (QAS) from item-attribute graphs and Preference Alignment Score (PAS) based on user-item interaction embeddings (e.g., LightGCN-derived). This hybrid reward enables fine-grained assessment of outputs, differentiating between partially aligned recommendations and truly irrelevant responses, thus facilitating exploration and stable RL optimization.
- Reasoning-aware Advantage Estimation (RAAE): Segments generated outputs into reasoning steps, aligning token-level rewards for correct or penalizing incorrect reasoning trajectories. Incorrect segments, especially those leading to erroneous recommendations, receive reduced rewards, guided via a wpenalty hyperparameter. This stratified supervision provides a mechanism for the model to identify and eliminate intermediate mistakes, improving global reasoning capacity.
- Online Curriculum Scheduler: Implements dynamic curriculum learning based on ongoing model performance, adaptively prioritizing easier queries and filtering out mastered samples, determined via epoch-wise reward inverses. This ensures smooth convergence and mitigates the tendency for RL-trained LLMs to stagnate on hard instances early in training.
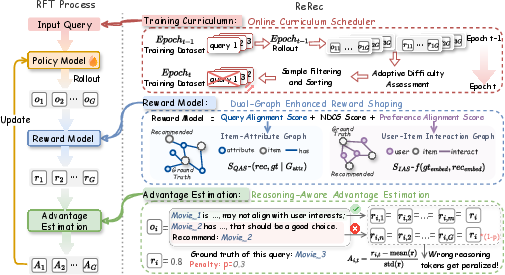
Figure 2: The overall model architecture of the proposed ReRec, highlighting reward shaping, reasoning supervision, and curriculum scheduling.
Empirical Evaluation
Experiments are conducted on RecBench+, a benchmark for reasoning-intensive, query-based recommendation spanning movie/book domains with explicit, implicit, misinformed, interest-based, and demographic queries. All evaluations are based on accuracy over candidate sets including hard negatives designed to test personalized reasoning.
ReRec achieves superior performance over baseline LLMs (Qwen-2.5-3B-Instruct, Llama-3.2-3B-Instruct), closed-source baselines (GPT-4o, DeepSeek-R1), conventional CRS models (TallRec, InteRecAgent, CRAG), and RL-trained models (GRPO, REINFORCE++, RLOO). Gains are most pronounced for misinformed/hard queries, indicating enhanced resilience to misleading information and context-sensitive reasoning. On challenging tasks with Llama backbone, ReRec yields 3.76%–13.2% absolute improvements over second-best RL baselines, and demonstrates over 440% improvement relative to an untrained LLM.
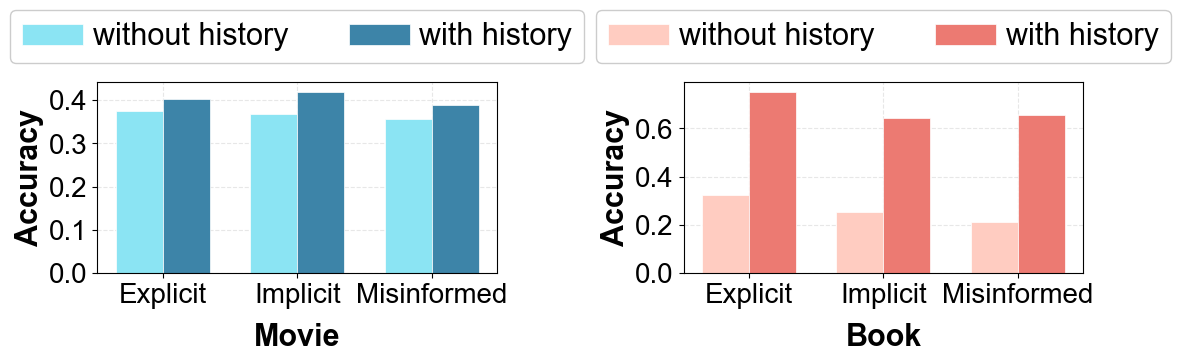
Figure 3: Performance on personalized recommendation, showing ReRec’s ability to utilize historical preferences for distinguishing between hard negatives.
Generalization, Capability Retention, and Ablations
ReRec is evaluated for cross-domain (train on movie, test on book, and vice versa) and cross-task transfer (sequential recommendation). The model exhibits strong generalization, outperforming base LLMs and approaching the performance of specialized sequential RecSys. When trained for query-based recommendation, ReRec retains up to 90% accuracy compared to domain-specific SASRec, and achieves up to 396% relative improvement over the Llama base model.
Capability retention is tested across reasoning, instruction-following, MCQ answering, and world knowledge. ReRec preserves the base LLM’s attributes with minimal decline, and even yields a 21.6% improvement in reasoning benchmarks, unlike SFT which induces catastrophic forgetting (reasoning drops by 15.7%, knowledge by 80%).
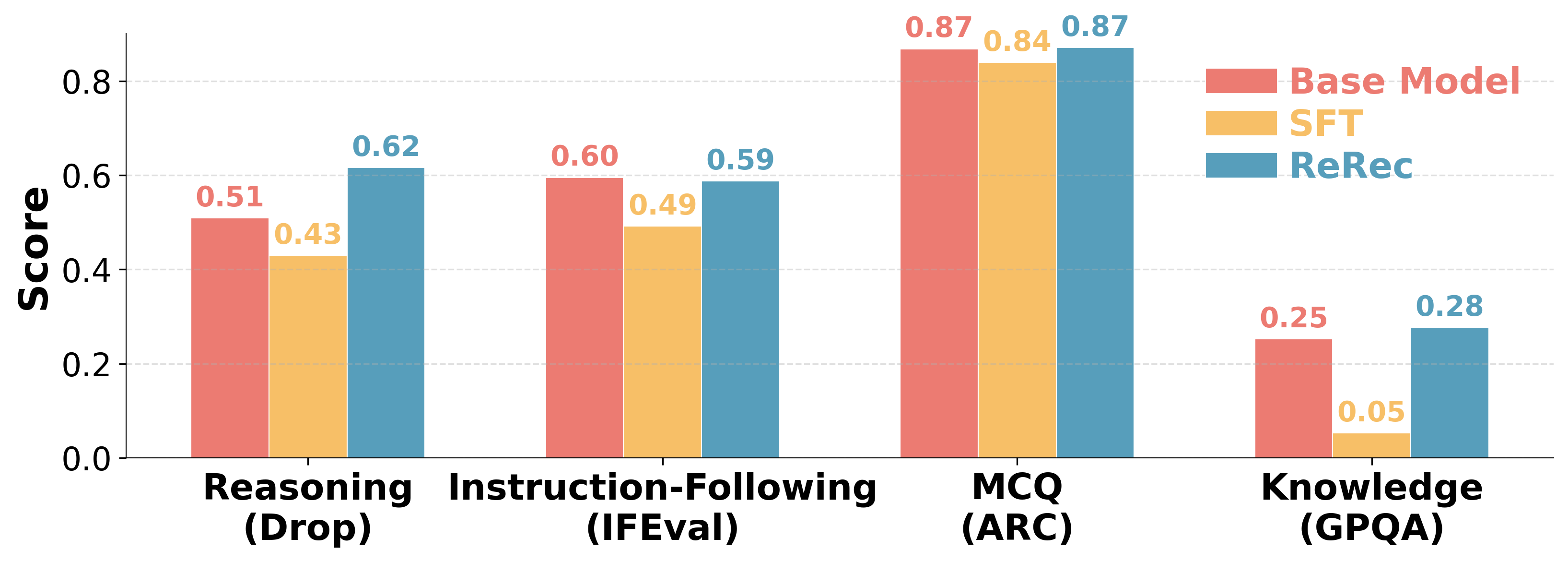
Figure 4: Knowledge and Capability Retention, validating the preservation and enhancement of critical skills post-RFT.
Ablation studies indicate that removing any of the three components (reward shaping, RAEE, curriculum scheduler) reduces accuracy, with RAEE being most critical.
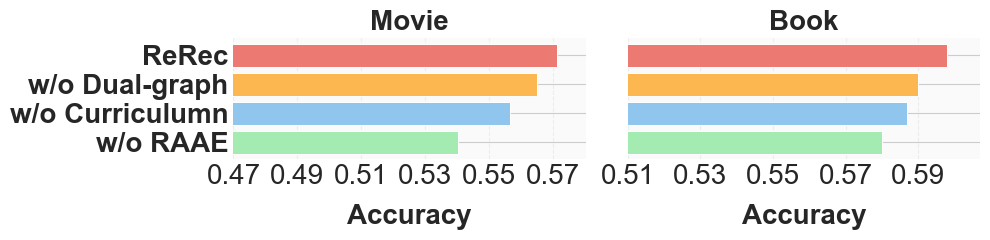
Figure 5: Ablation of ReRec demonstrating the importance of reasoning-aware advantage estimation.
Parameter Analysis
Penalty parameter wpenalty in RAEE is scrutinized. An optimal value (e.g., 0.30) is found to maximize accuracy, confirming the need for moderate penalization for incorrect reasoning, while excessive penalization impairs learning stability.
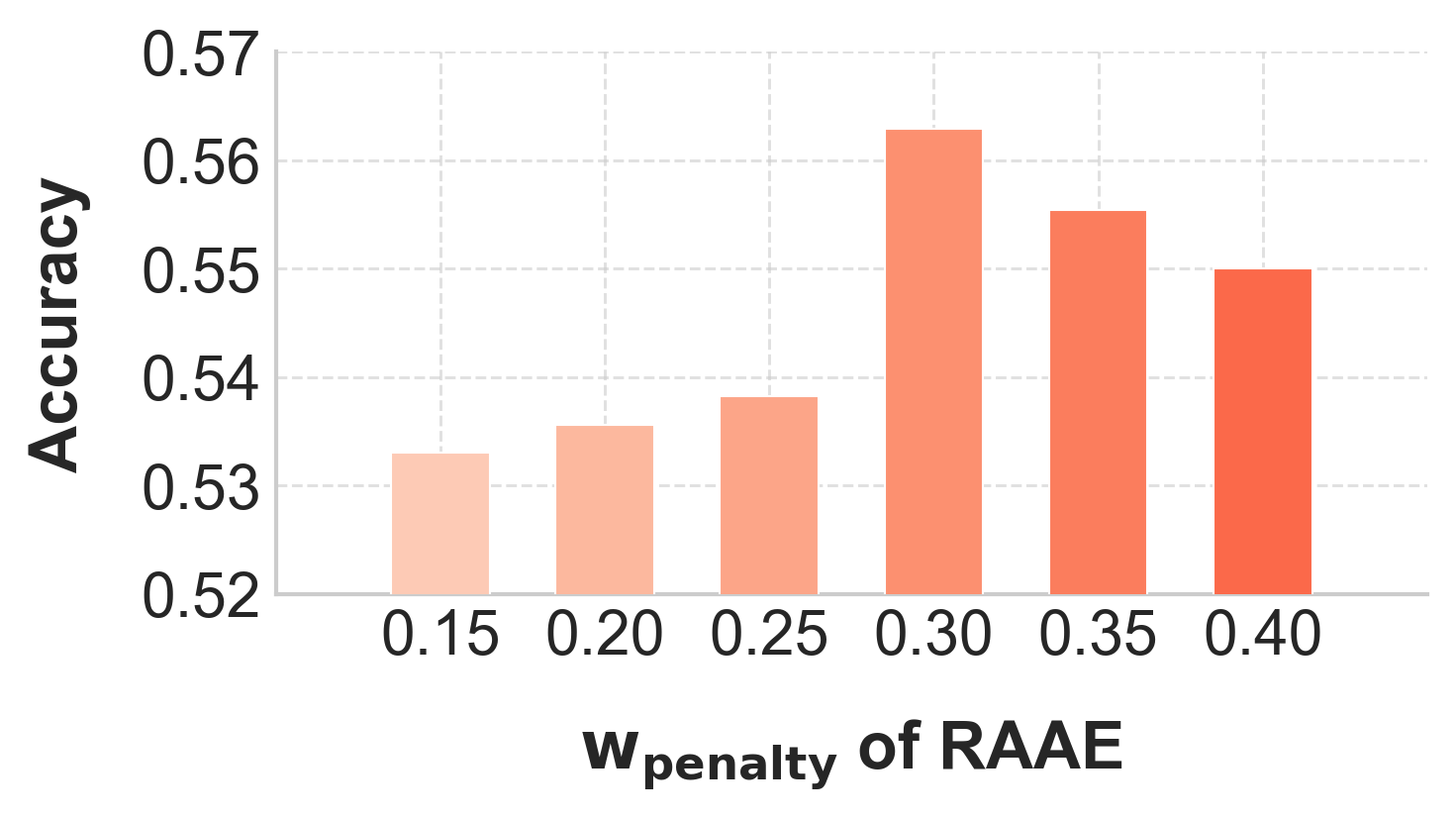
Figure 6: Effect of wpenalty showing accuracy peaks when penalty is neither too weak nor too strong.
Practical and Theoretical Implications
By explicitly aligning reward signals with query constraints and user preferences through dual-graph modeling and by decomposing reasoning processes with fine-grained supervision, ReRec steers LLMs to achieve greater interpretability, reliability, and personalization in recommendation tasks. This approach bridges the gap between general LLM skill sets and domain-specific recommendation needs, mitigating forgetting of core linguistic and reasoning abilities. The reinforcement-based regimen naturally extends to recommendation scenarios involving sequential reasoning, tool-augmented inference, and cross-domain adaptation without manual annotation scaling.
Theoretically, ReRec demonstrates the efficacy of integrating token-level RL feedback, dynamic curricula, and composite reward structures in guiding LLMs beyond simple output alignment to internal process optimization. The findings underscore the necessity of intermediate reasoning supervision in RL for complex multi-step dialogic tasks.
Prospects for Future Research
Advancing ReRec towards multi-turn conversational settings involves hierarchical and accumulative reward structures, necessitating persistent memory, cross-utterance constraint tracking, and adaptation to evolving user intents. Integration with external tools—retrieval engines, collaborative filtering, explicit KG layers—could further empower the model to execute context-augmented reasoning steps flexibly within RL training loops. These directions will require innovative reward engineering, model architectures, and scalable curriculum policies suitable for open-ended dialogic recommendation.
Conclusion
ReRec establishes a principled and empirically validated framework for reasoning-augmented LLM-based recommendation through reinforcement fine-tuning. It demonstrates substantial gains in recommendation accuracy, personalization, and reasoning skill preservation, surpassing existing baselines in challenging query settings. The modular design, comprising reward shaping, reasoning-aware advantage, and adaptive curriculum, offers a blueprint for future domain-specific RL-based LLM agents in recommendation and more broadly in complex interactive AI tasks.

