- The paper introduces an LLM-augmented, human-validated framework that constructs high-quality loneliness datasets from Reddit posts, achieving 76–80% accuracy in distinguishing caregiver from non-caregiver expressions.
- The methodology integrates advanced filtering, a modified UCLA Loneliness Scale, and expert-guided categorization to attribute loneliness to seven distinct causes.
- The results reveal that caregiver loneliness is primarily linked to network and relational deficits, contrasting with the social and emotional focus observed in non-caregivers.
Leveraging LLMs for Large-Scale Measurement and Analysis of Loneliness in Caregivers and Non-caregivers
Introduction
The paper "Why Are We Lonely? Leveraging LLMs to Measure and Understand Loneliness in Caregivers and Non-caregivers" (2604.07834) presents an LLM-augmented, human-validated methodology for constructing high-quality datasets from Reddit posts to systematically evaluate loneliness and its causes, contrasting the caregiving and non-caregiving populations. The study creates evaluation and categorization frameworks tailored to psychological theory and the unique context of caregiving, employs multiple state-of-the-art LLMs, and collects detailed demographic data to dissect population-level differences in the manifestation and etiology of loneliness.
Methodological Innovations
The authors design an end-to-end pipeline that integrates large-scale Reddit scraping, rigorous filtering (token thresholds, regular expressions, relevance labeling), and expert-grounded scales. Relevant posts are delineated by subreddit targeting and LLM annotation, with further human validation to minimize cross-contamination between caregiver and non-caregiver data. For measurement, the paper introduces a modified UCLA Loneliness Scale, adapting first-person items for third-person judgment and enforcing explicit textual evidence as annotation criteria. This schema outperforms vanilla approaches to social media loneliness annotation, especially in its attention to ambiguous or implicit expressions (see Figure 1 and Figure 2 for confusion matrices, shown below).
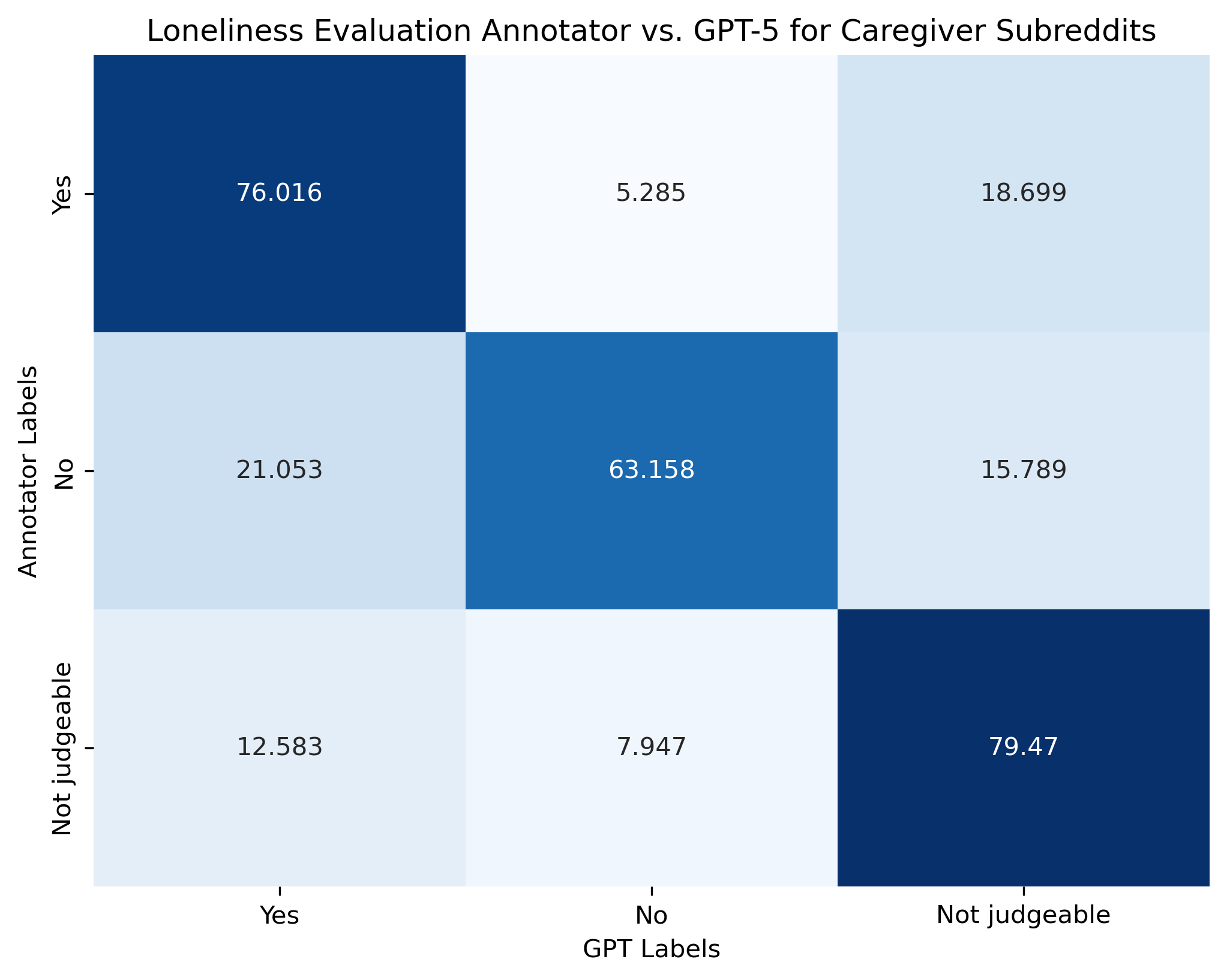
Figure 1: Confusion matrix for the loneliness annotation framework in caregiver subreddits; “no” labels suffer reduced agreement.
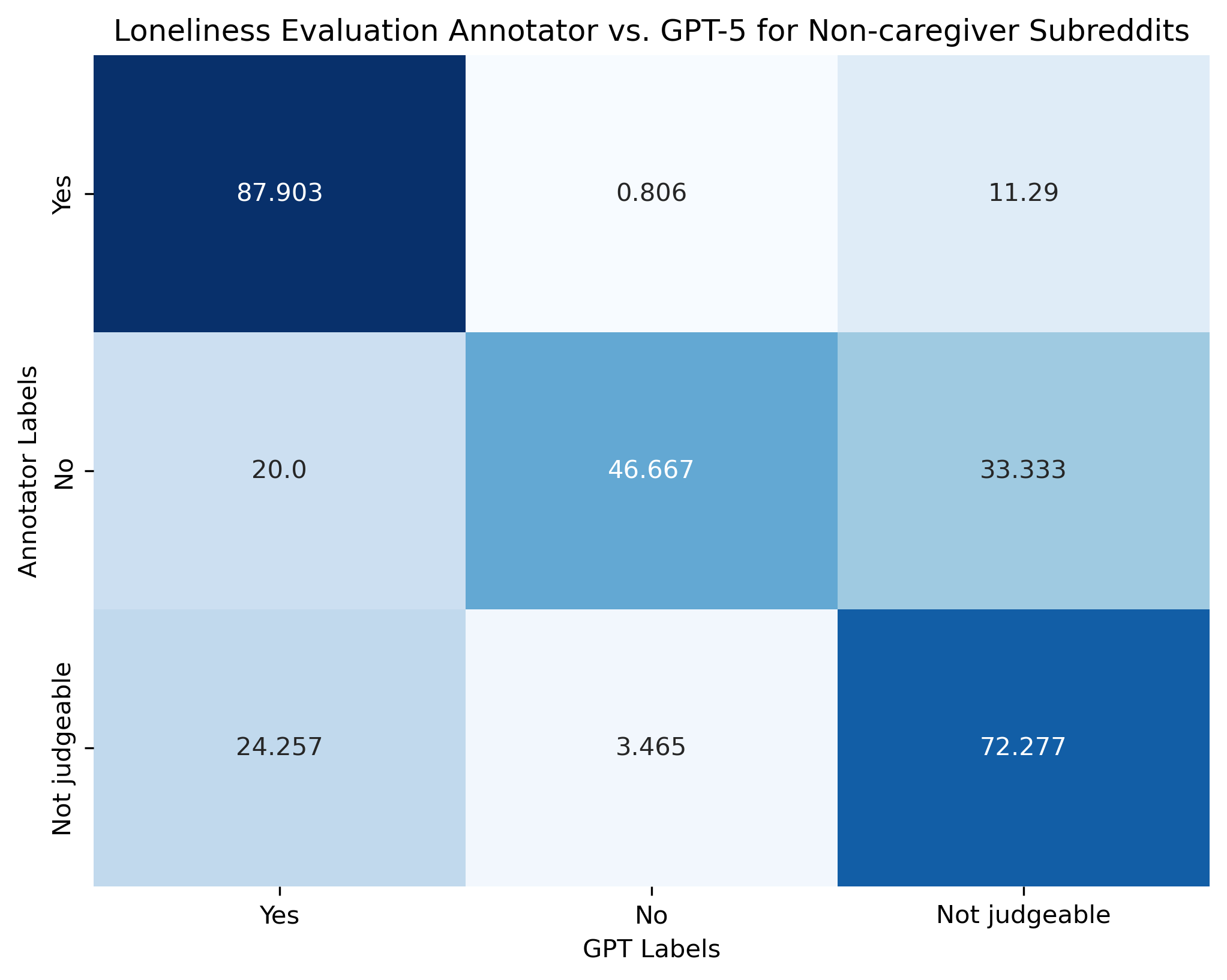
Figure 2: Confusion matrix for non-caregiver subreddits, likewise illustrating confusion around the “no” label.
A parallel, expert-validated typology attributes loneliness to seven distinct categories (social, emotional, physical, mental health, relational, network, and other), distinguishing causes related and unrelated to caregiving.
Model performance is benchmarked against human annotation for both frameworks. The loneliness evaluation task achieves 76.09%–79.78% accuracy, while the cause categorization framework yields micro-F1 scores of 0.825 (caregivers) and 0.80 (non-caregivers). These scores indicate that contemporary LLMs (specifically GPT-5 and its variants) can operationalize complex, multi-label annotation schemes at scale, though “no” judgments and rare cause classes remain challenging.
Dataset Construction and Demographic Profiling
From approximately 70,000 raw Reddit posts, the pipeline surfaces 387 posts from lonely caregivers and 908 from lonely non-caregivers that satisfy strict annotation thresholds. Demographic information is extracted using GPT-4o, which demonstrates 88.31% accuracy across nine caregiver- and patient-related fields after human validation. The resulting caregiver dataset, while modest in size, manifests demographic breadth, encompassing a range of ages, caregiving durations, relationships (see Figure 3–9 for detailed distributions and category breakdowns).
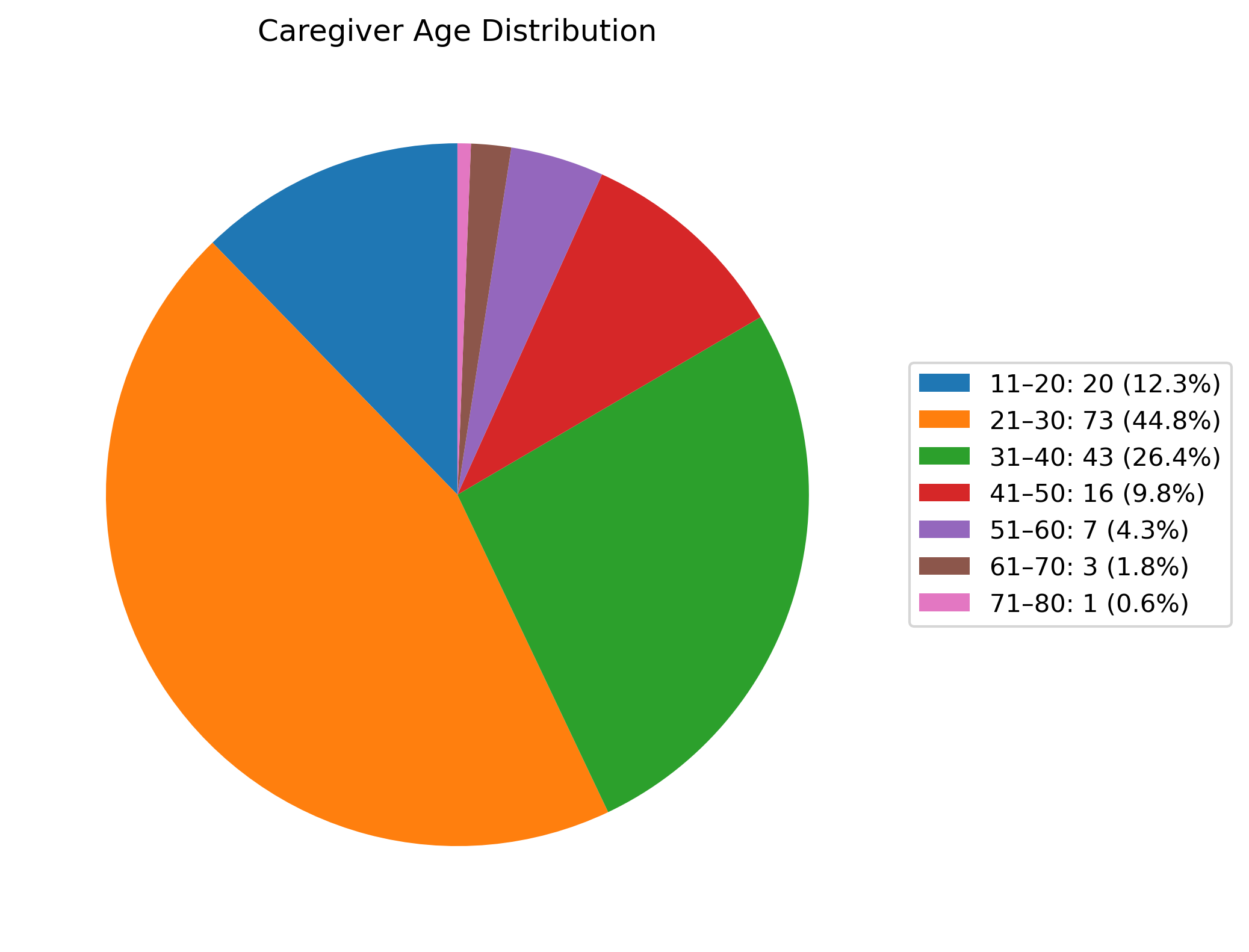
Figure 3: Distribution of caregiver ages among labeled posts, exhibiting a youth skew typical for online platforms.
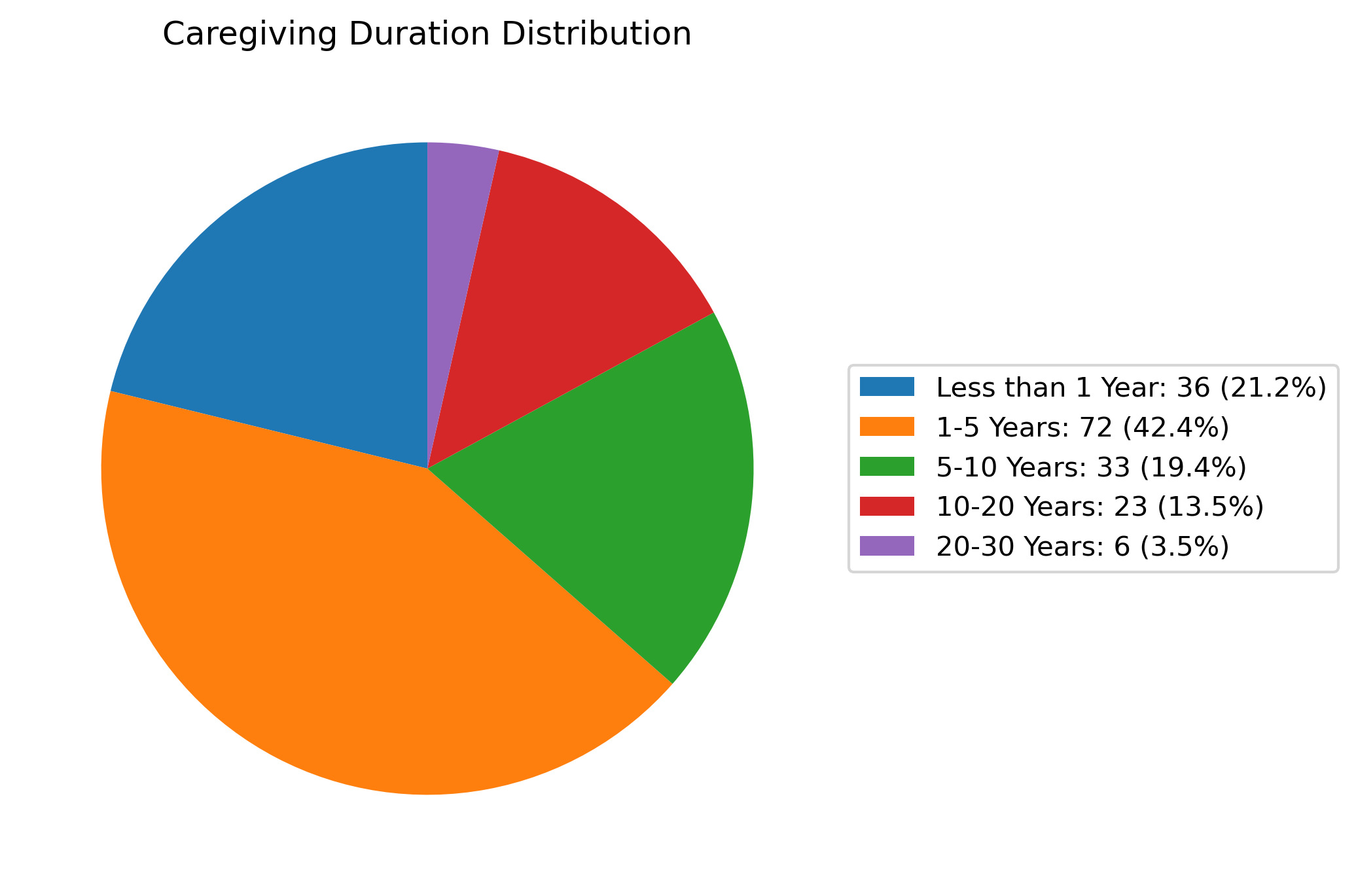
Figure 4: Duration of caregiving responsibilities, indicating diverse experience lengths.
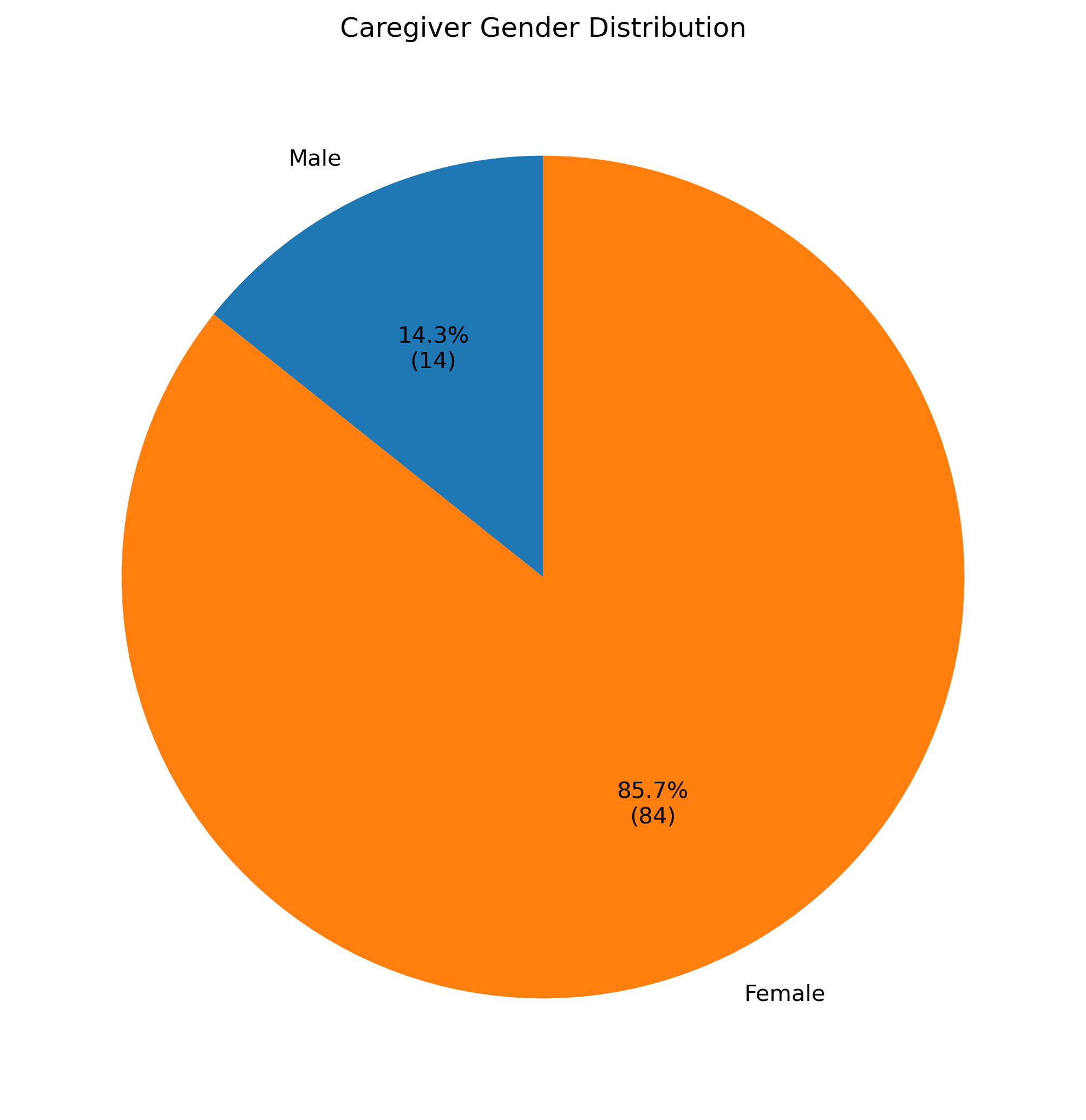
Figure 5: Gender distribution of self-identified caregivers, with overrepresentation of females.
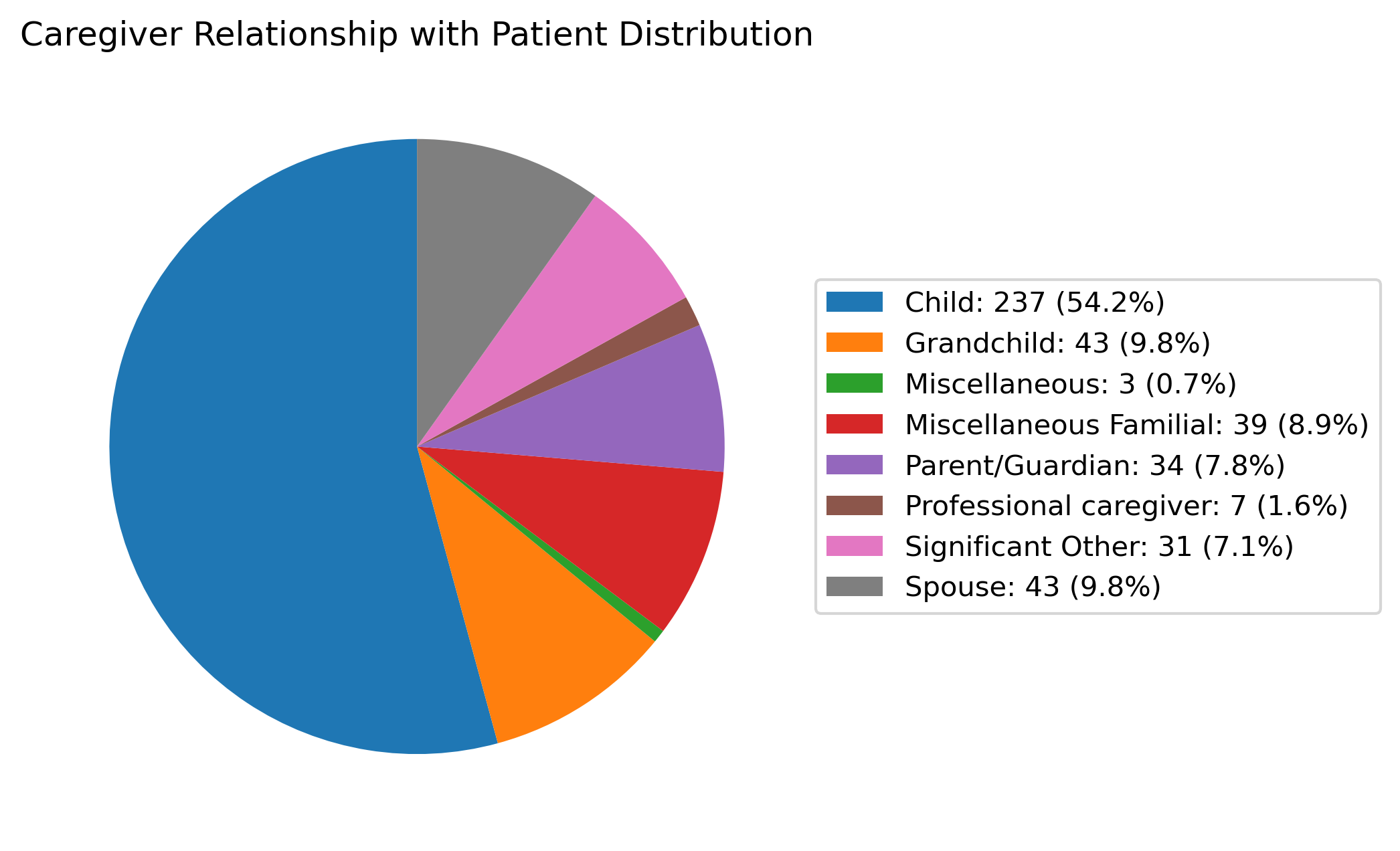
Figure 6: Distribution of the relationship between caregiver and patient (e.g., child, spouse, other family), with most caregivers supporting parent or grandparent.
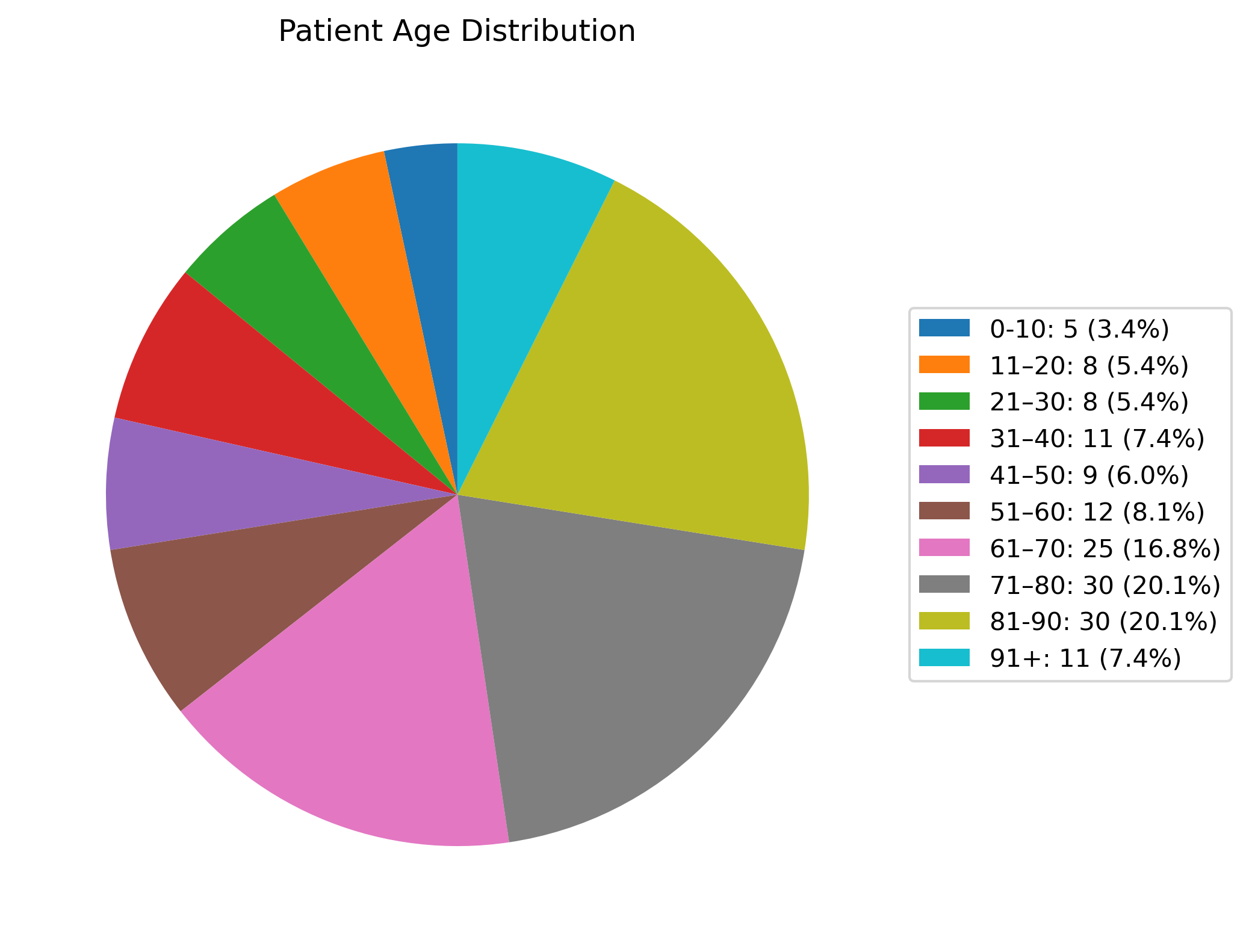
Figure 7: Patient age distribution, confirming predominance of elderly care recipients.
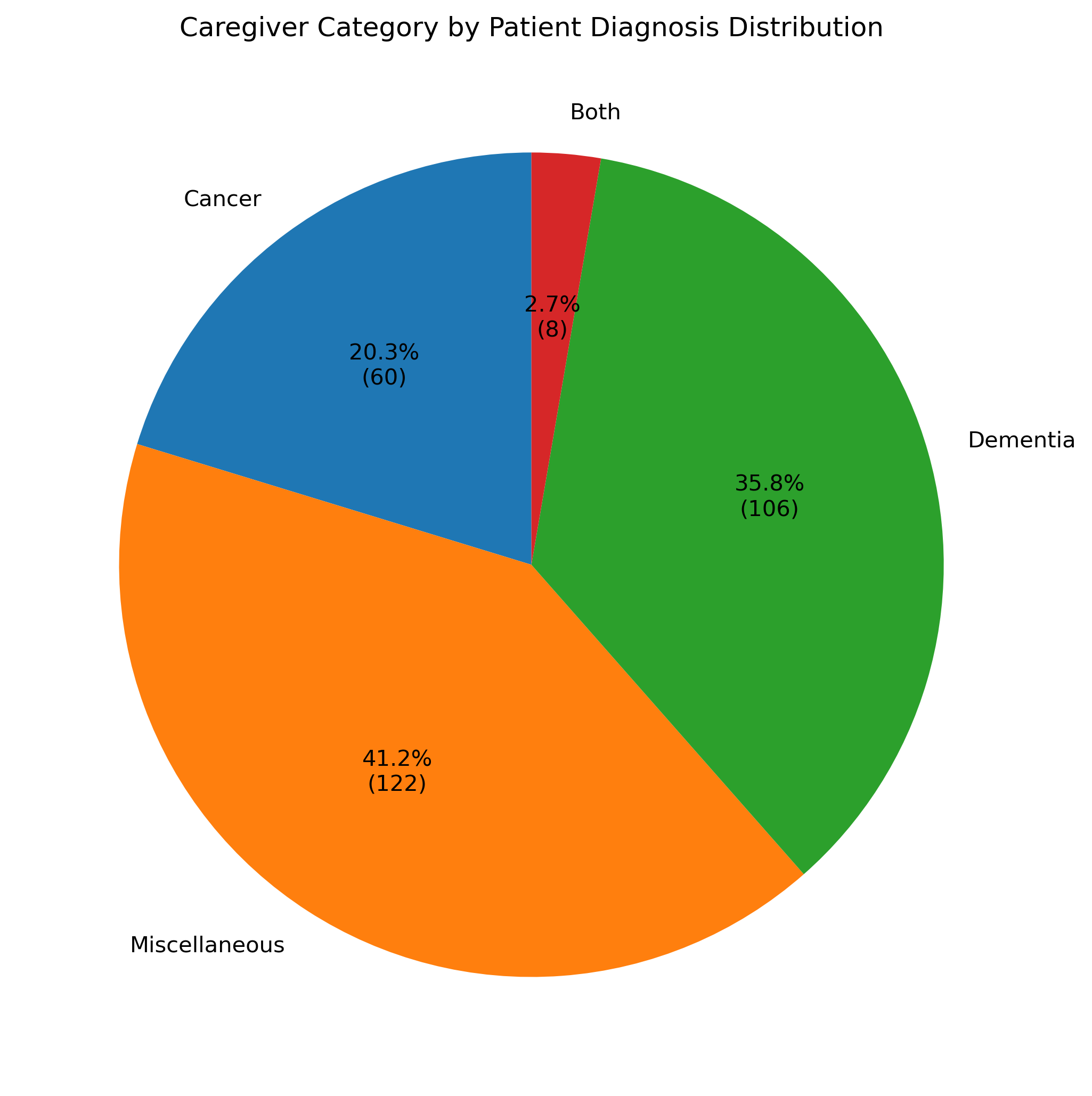
Figure 8: Distribution of patient diagnoses; cancer and dementia are prevalent, but other diagnoses are well represented.
Approximately half of posts allow demographic extraction for any given attribute, supporting the claim that Reddit data, despite its anonymity, can yield robust population statistics when annotated at scale.
Analytical Findings
A key empirical contribution is the clear differentiation in loneliness typologies between caregivers and non-caregivers, visualized in the cause-of-loneliness distribution (see Figure 9 in the original manuscript; not available here). For caregivers, the dominant categories are network- (56.1%) and relational-related (37.1%) causes of loneliness centered on caregiving, while non-caregivers are characterized by classic social (74.2%) and emotional (47.8%) loneliness. Notably, only 16.5% of caregiver posts report social causes unrelated to caregiving. This contrasts sharply with the non-caregiver cohort, suggesting that caregiving fundamentally restructures the antecedents of loneliness, deprioritizing mere lack of relationships in favor of support, recognition, and role-based validation. Additionally, the “other” category is rarely invoked, indicating that the cause typology comprehensively captures the observed phenomena.
LLM accuracy is higher for detection of present evidence (“yes”) and explicit lack of evidence (“not judgeable”), but falters on explicit negation (“no”). In cause categorization, frequent classes (network, social, relational) are easier for LLMs, with infrequent types suffering from annotation imbalance and prompting ambiguity.
This work validates the feasibility of deploying LLMs to apply rigorously defined, psychological evaluation frameworks to noisy, large-scale social media corpora. Practically, it demonstrates that Reddit is a viable data source for nuanced, population-specific mental health analysis, albeit with data sparsity constraints (only 1.36% of caregiver posts pass the high loneliness threshold). The pipeline allows scalable, reproducible harvesting of mental health signals, contrasting with scarce, labor-intensive survey- or interview-based research.
Theoretically, LLM performance under annotation constraints (demanding explicit textual evidence, not inference) exposes both the power and limitations of current models in differentiating subtleties of loneliness manifestation. The strong separation of causes between populations—especially the primacy of role-specific support and validation in caregiver loneliness—calls for targeted design of mental health interventions, suggesting that generic outreach efforts are unlikely to be effective for caregivers.
Technically, this work encourages expansion to multi-LLM ensembles, broader social media landscapes, and further refinement of annotation schemes, including richer gold standards with multiple expert annotators and enhanced adversarial label balance. The pipeline could serve as a foundation for future studies on symptomatology, treatment-seeking behavior, and population health surveillance.
Conclusion
The paper establishes a scalable, LLM-driven architecture for measuring and explaining loneliness in large online populations, validating both psychological measurement and population-specific cause attribution at scale. It reveals pronounced, qualitative differences in the etiology of loneliness between caregivers and non-caregivers, with practical implications for intervention and theoretical consequences for models of social isolation. The approach exemplifies rigorous, model-guided computational social science with immediate extensibility to other mental health domains and digital phenotyping challenges.

