Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution
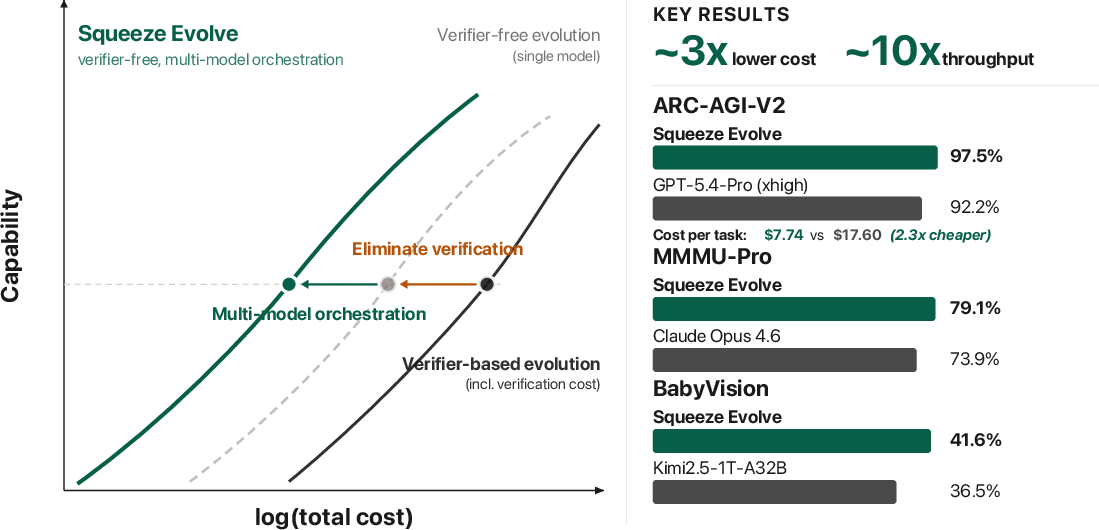
Abstract: We show that verifier-free evolution is bottlenecked by both diversity and efficiency: without external correction, repeated evolution accelerates collapse toward narrow modes, while the uniform use of a high-cost model wastes compute and quickly becomes economically impractical. We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference. Our approach is guided by a simple principle: allocate model capability where it has the highest marginal utility. Stronger models are reserved for high-impact stages, while cheaper models handle the other stages at much lower costs. This principle addresses diversity and cost-efficiency jointly while remaining lightweight. Squeeze Evolve naturally supports open-source, closed-source, and mixed-model deployments. Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision, Squeeze Evolve consistently improves the cost-capability frontier over single-model evolution and achieves new state-of-the-art results on several tasks. Empirically, Squeeze Evolve reduces API cost by up to $\sim$3$\times$ and increases fixed-budget serving throughput by up to $\sim$10$\times$. Moreover, on discovery tasks, Squeeze Evolve is the first verifier-free evolutionary method to match, and in some cases exceed, the performance of verifier-based evolutionary methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a smarter way to use AI models when you want them to “think harder” at test time without relying on an outside checker to tell them what’s right. The authors call their approach Squeeze Evolve. It mixes several AI models of different strengths and prices, and assigns each model to the part of the problem where it helps the most. The goal is simple: get better answers for less money and time.
What questions did the researchers ask?
They focused on two big questions:
- If we have models that vary in cost and skill, which model should do which job during the “evolution” of answers (like generating ideas, choosing the best ones, and combining them)?
- How can we coordinate these models so we keep answer quality high, keep ideas diverse, and still spend as little as possible?
They also looked at a key challenge: without an outside judge (a “verifier”), repeated self-improvement often collapses into the same kind of answer again and again, which hurts the chances of discovering the right solution.
How did they do it?
One simple idea: treat test-time methods as “evolution”
Many test-time tricks people use today can be seen as a kind of evolution:
- Start with a bunch of candidate answers.
- Score or select some of them.
- Combine or improve them to make new answers.
- Repeat for a few rounds.
This is like a classroom where students draft answers, the best ideas are selected, and then the class merges them into stronger solutions.
The Squeeze Evolve approach
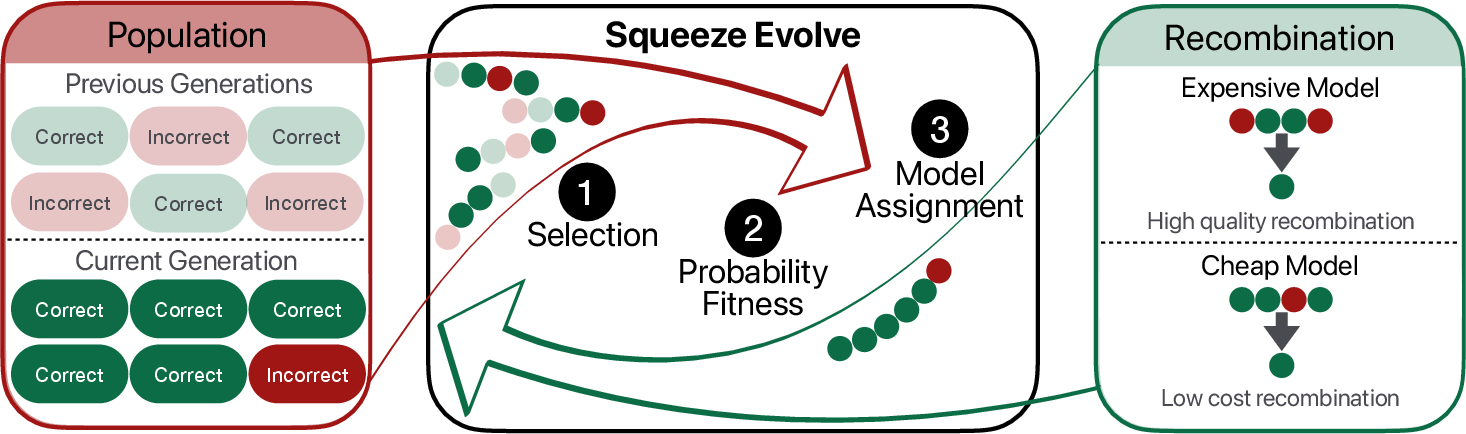
The authors keep this evolution setup but “orchestrate” multiple models:
- Use a stronger, more expensive model only where it matters most.
- Use a cheaper model for easier or lower-impact steps.
- Sometimes don’t use a model at all, and just apply a lightweight rule like majority vote when the group already agrees.
Think of it like a team project: you call in the expert only for the toughest parts, while juniors handle routine tasks, and the team uses quick votes when everyone already sees the same answer.
How do they decide which model to use?
They use simple signals that the models already produce:
- Confidence: how sure the model seems about what it wrote (you can think of this as how “peaky” its word probabilities are).
- Diversity: how much the group’s answers disagree.
If a group of answers is uncertain or very mixed, that’s a good time to bring in the stronger model. If the group is confident or already agrees, a cheaper model or a quick rule often works fine.
Importantly, these signals are almost free to compute. The models already generate what’s needed while they write their answers.
Key design choices they discovered
- Strong starts matter: using the stronger model to create the very first batch of answers sets the evolution up for success.
- Cheap models can still be great “aggregators”: if the input candidates are already good, combining them doesn’t require a top model.
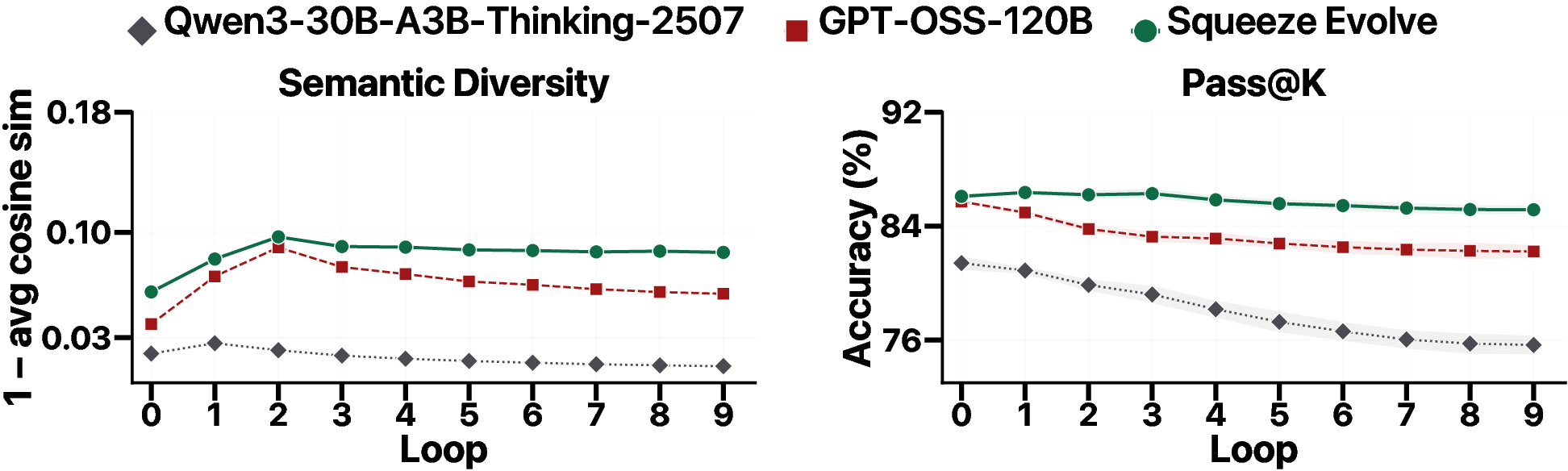
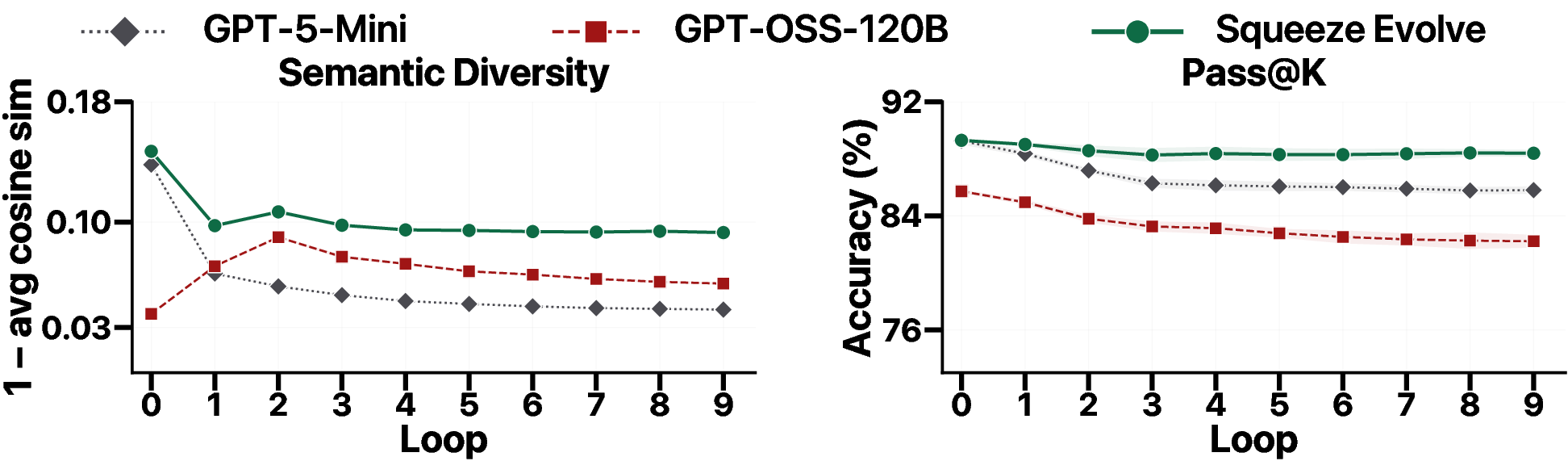
- Keep diversity alive: mixing models prevents the group from converging too early to the same style of answer, improving the odds that one path finds the correct solution.
System engineering to make it fast
They also built practical serving tricks:
- Separate GPU pools for the cheap and expensive models so neither one sits idle.
- A custom “confidence engine” that calculates confidence quickly without wasting memory or time.
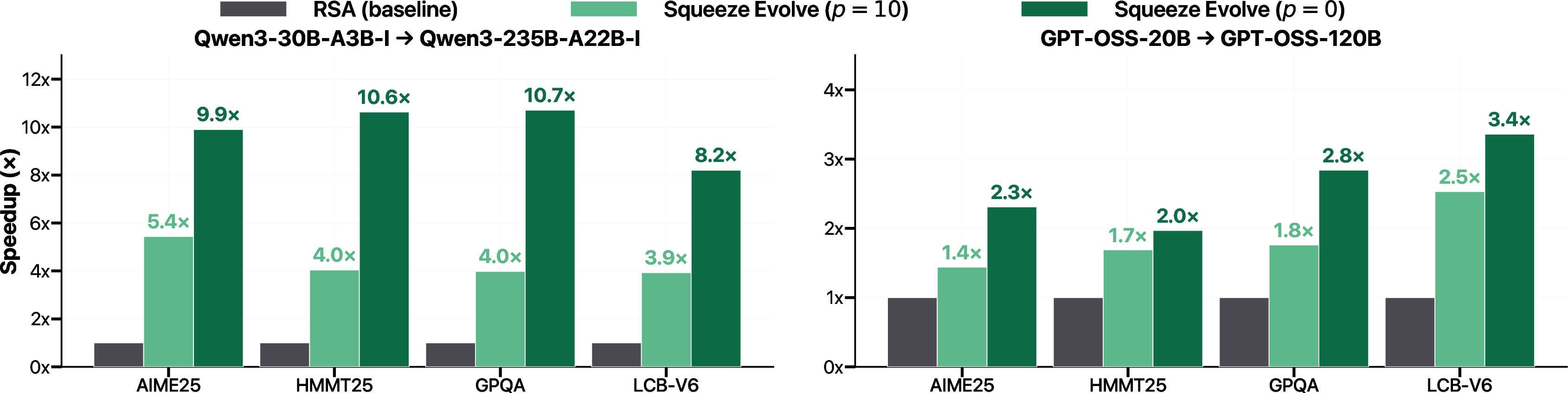
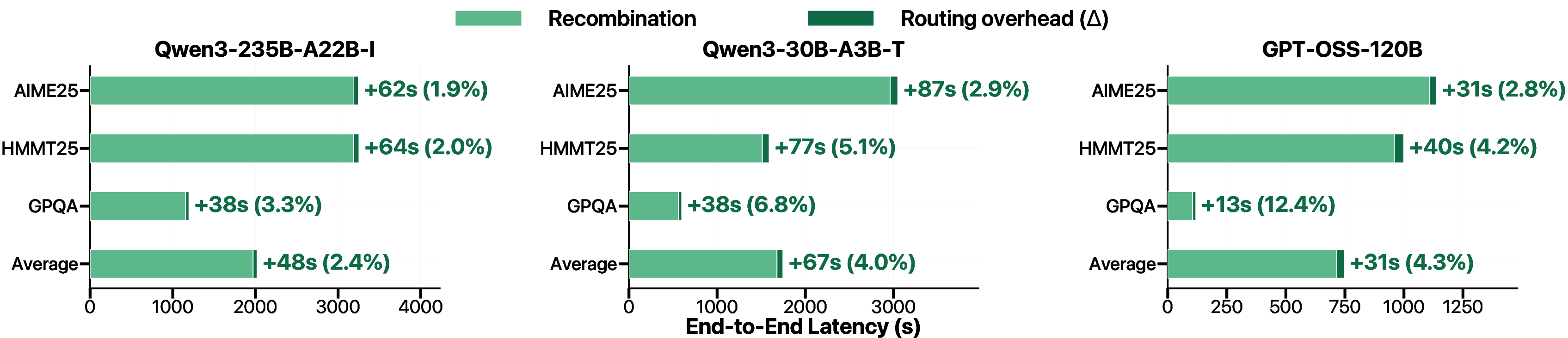
- Very low routing overhead (just a few percent of total time), with up to about 10× higher throughput at a fixed budget.
What did they find?
Across many tasks—math contests (AIME 2025, HMMT 2025), hard science questions (GPQA-Diamond), coding (LiveCodeBench V6), visual reasoning (ARC-AGI-V2), and multimodal vision (MMMU-Pro, BabyVision)—Squeeze Evolve delivered strong results.
Highlights:
- Lower cost for similar or better accuracy: often 1.3× to 3.3× cheaper than using a single strong model alone, while matching or beating its accuracy.
- Faster service at the same budget: up to about 10× more problems solved in the same time and cost.
- Fights “diversity collapse”: multi-model evolution kept a wider set of ideas alive longer, raising the chance at least one is correct.
- Strong starts win: using the best model to create the initial answers had a bigger impact on final quality than using it later to combine answers.
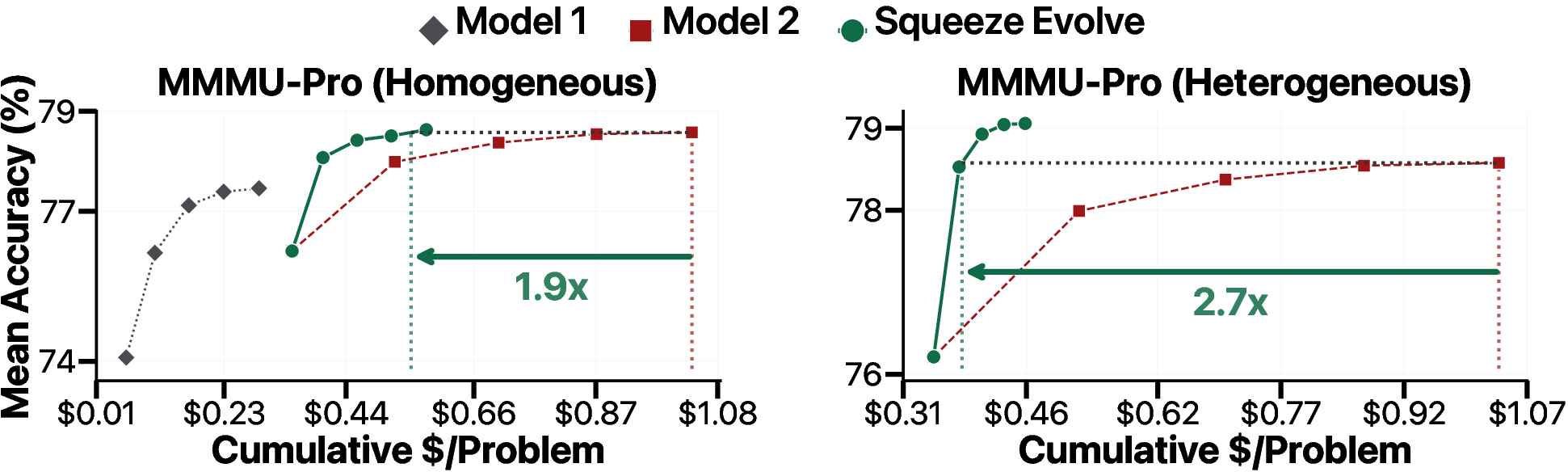
- Vision surprise: on image tasks, once the first round used a vision-capable model, later rounds could be handled by a cheaper text-only model without losing accuracy—saving 2.3× to 2.5× cost.
- New cost–quality frontier on ARC-AGI-V2: 97.5% accuracy at about $5.93–$7.74 per task without running code—competitive with, or cheaper than, approaches that do execute code.
- Discovery tasks: on open-ended problems like circle packing, this verifier-free method matched or beat approaches that rely on external verifiers.
Why does this matter?
As AI gets used in more areas, we can’t always afford an external checker, and sometimes no good checker exists. This paper shows a practical way to get strong results anyway by:
- Spending expensive model time only where it helps most.
- Preserving diversity to avoid “everyone making the same mistake.”
- Using the models’ own signals to guide decisions cheaply.
- Working across open-source, closed-source, and mixed setups.
In short, Squeeze Evolve turns “just throw more compute at it” into “use the right compute at the right time.” That makes advanced AI more affordable and more effective, which can help in classrooms, coding assistants, scientific search, and any place we need reliable answers on a budget.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased so future researchers can act on it:
- Theoretical guarantees and analysis
- Absent formal analysis of convergence, stability, or sample efficiency for verifier-free evolution with routing; no bounds on error amplification or diversity collapse across loops.
- No optimality analysis of the routing policy (percentile-based threshold) under marginal-utility assumptions; lack of theory on when multi-model orchestration outperforms single-model evolution.
- Confidence signal definition, calibration, and robustness
- The “group confidence” formula appears inconsistent with its verbal interpretation (Eq. (1) suggests higher values when distributions are flatter/less certain, whereas the text treats larger values as higher confidence); requires clarification, calibration, or a corrected monotonic mapping.
- No systematic calibration study for self- and cross-model confidence across domains/models; open question: how to normalize confidence across tokenizers, chat templates, or model families so thresholds are comparable and stable.
- Vulnerability to overconfident wrong answers and distribution shift is untested; need stress tests (adversarial prompts, out-of-distribution tasks) and robust alternatives (e.g., temperature scaling, conformal risk control, ensemble-based uncertainty).
- Fitness proxies beyond logprobs/diversity
- Limited to token-logprob-based “confidence” or final-answer diversity; unexplored: trajectory-level features (e.g., entropy over steps), critique consistency, self-uncertainty elicitation, embedding dispersion, or learned low-cost scorers.
- No exploration of hybrid or multi-signal fitness (e.g., combining confidence, diversity, and structural features) or of learning a router from data with generalization guarantees.
- Routing policy design and adaptivity
- Only a single percentile threshold p is tuned; no method to auto-tune p online, adapt across tasks, or budget-constrain routing under latency or dollar caps.
- No ablations of sensitivity to p across datasets and seeds, or to other unreported hyperparameters (N, K, T, temperature, top-k, sampling strategies).
- Lack of exploration of more than two LLM tiers (L > 2), hierarchical or multi-stage routing, or conditional re-escalation when low-tier aggregation fails.
- Diversity preservation strategies
- While multi-model routing mitigates diversity collapse, explicit diversity-preserving operators (e.g., controlled mutations, de-duplication, novelty search, lineage re-seeding) are not explored.
- No principled diversity metrics beyond answer-count; open question: how to maintain semantic/process diversity (e.g., CoT diversity, tree coverage) without increasing cost significantly.
- Initialization dependence and alternatives
- Strong performance hinges on expensive strong-model initialization; unexplored: partial strong initialization (e.g., only some seeds), staged warm-starts, or curriculum-based initialization to reduce cost.
- No study of multi-ancestor strategies (mixing models at loop 0) or of learned policies to choose initialization depth given budget and task difficulty.
- Generality across task types
- Benchmarks are mainly math/coding/vision QA; unexplored: long-form generation, multi-turn agentic tasks, tool-use with external APIs, program synthesis with execution, and safety-critical or high-stakes decision-making.
- Applicability to tasks with non-canonical outputs (e.g., creative writing, ambiguous labels) where answer extraction or majority voting is ill-defined remains unknown.
- Multimodal orchestration boundaries
- Vision experiments suggest later loops can be text-only, but no criteria to detect tasks that require re-grounding in images/video or to re-introduce visual input adaptively.
- No evaluation on audio/video, temporal reasoning, or tasks requiring continuous visual grounding across loops.
- Interaction with lightweight verifiers
- The paper focuses on verifier-free settings; unexplored middle ground: occasional cheap/verifier hints, partial program checks, static analyzers for code, or weak oracle signals to curb error propagation.
- Aggregation strategies and “lite” tier
- “Lite” aggregation is minimally explored (majority vote/random); potential improvements (e.g., small specialized aggregators, rule-based heuristics, symbolic solvers) are not evaluated for cost–accuracy trade-offs.
- No analysis of failure modes where aggregation reinforces common but wrong lineages; techniques for de-biasing aggregation are absent.
- Selection mechanisms and population management
- Selection is mostly uniform or simple fitness-weighted; untested alternatives: tournament selection, novelty-weighted sampling, or adaptive K and M per loop.
- The “replace” vs “accumulate” update rule is only briefly used (accumulate for circle packing) without systematic comparison across tasks; open question: when does accumulation prevent regressions vs entrench errors.
- System and deployment constraints
- Latency-matched GPU pools and the custom confidence engine improve throughput, but generalization to multi-tenant, heterogeneous clusters (with dynamic workloads, preemption, or failure) is unexamined.
- No adaptive autoscaling strategy when routing fractions shift over time; lack of robustness benchmarks for service-level objectives (SLOs) under load spikes.
- Portability and reproducibility
- Gains rely on a custom vLLM “confidence engine”; portability to other serving stacks or closed APIs is unclear, especially where logprobs are not exposed.
- Reported API prices are time-sensitive; replicability with fluctuating costs or self-hosted deployments needs guidance and standardized cost accounting (including energy).
- Security, privacy, and safety
- Cross-model scoring and aggregation may transmit user content across providers; privacy and compliance implications are unaddressed.
- No adversarial robustness analysis (prompt attacks targeting routing/aggregation), nor safety mechanisms to prevent confident, harmful outputs in a verifier-free loop.
- Comparative baselines and ablations
- Limited comparisons to other routing or multi-model methods (e.g., RouteLLM, mixture-of-agents with adaptive assignment), test-time training, or verifier-light strategies.
- Missing ablations isolating contributions from strong initialization vs routing vs confidence scoring vs lite aggregation to quantify each component’s marginal utility.
- Tokenization and prompt-template mismatches
- Cross-model scoring and aggregation can suffer from tokenizer/template differences; no systematic study of how these affect confidence estimates, routing decisions, or aggregation quality.
- Scaling laws and cost–capability modeling
- Empirical curves are provided, but no generalized scaling law or predictive model to choose N, K, T, and p given a fixed budget and target accuracy across tasks.
- Open question: can we learn task-specific policies predicting marginal utility of escalating to a stronger model for each group.
- Edge cases and failure analysis
- Sparse analysis of where routing misfires (e.g., cheap model aggregates confidently wrong groups), or of tasks where Squeeze Evolve underperforms single-model evolution.
- Lack of diagnostics/telemetry for operators to detect diversity collapse, overconfidence, or routing drift in production.
- ARC-AGI-V2 and circle-packing specifics
- ARC routing relies on answer diversity due to missing logprobs; sensitivity to answer parsing and to tasks with high surface-form variability is unquantified.
- Circle-packing setup and results are truncated; reproducibility details (objective curves, best-found solutions, comparison to verifier-based baselines) are incomplete.
- Ethical and licensing considerations
- Mixing open- and closed-source models raises licensing, attribution, and data-sharing questions; no discussion of policies for enterprise or regulated settings.
These gaps suggest concrete directions: develop calibrated, multi-signal fitness estimators; design adaptive, multi-tier routing with online tuning; add explicit diversity maintenance; explore partial/learned initialization; extend to long-horizon, multimodal, and safety-critical tasks; integrate lightweight verifiers; systematize scaling laws and production-grade deployment practices; and provide clearer theoretical and empirical foundations for when and why routing yields the best cost–capability trade-offs.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling and model APIs, leveraging the paper’s confidence-based routing, multi-model orchestration, and serving-system co-design to improve the cost–capability frontier.
- Cost-optimized LLM serving via multi-model orchestration (Software, Cloud/ML Ops)
- What it enables: Reduce reasoning costs by 1.3–3.3× and boost fixed-budget throughput up to ~10× by routing “easy” recombination groups to cheaper models and reserving expensive models for high-utility steps.
- Potential tools/workflows: Confidence-based router; three-tier recombination (Model 2, Model 1, lite); percentile-based routing knob p; latency-matched GPU pools; vLLM prefill-only confidence engine.
- Assumptions/dependencies: Access to multiple models; API access to token logprobs or ability to do prefill-only cross-model scoring; serving stack that supports batching and routing; compliance with model licenses and data governance.
- Coding assistants with cheaper-but-accurate refinement (Software Engineering)
- What it enables: Use a strong “think” model to initialize candidate code, then recombine/aggregate with a smaller model; retain or beat single-model accuracy on LiveCodeBench V6 at ~2× lower cost.
- Potential tools/workflows: RSA-style generation at loop 0 with a high-capability model; confidence- or diversity-driven grouping; cheaper model (or lite aggregator) for consolidation and final draft.
- Assumptions/dependencies: Proper prompt templates for each model; sandboxed code execution optional; human-in-the-loop recommended for production code.
- Math and technical problem-solving at lower cost (Education, R&D, Enterprise Analytics)
- What it enables: AIME/HMMT/GPQA-style reasoning with 1.4–2.1× savings using open-weight pairs; accuracy can exceed the expensive model alone when initialization uses a stronger model and recombination is routed.
- Potential tools/workflows: Strong initializer + cheap aggregator; confidence percentile routing; replace update rule for short runs, accumulate for longer discovery tasks.
- Assumptions/dependencies: Benchmark-like problems with textual final answers; no external verifier needed, but optional human review in high-stakes settings.
- Multimodal Q&A with vision-light pipelines (Vision, Document AI, Robotics)
- What it enables: Use a vision-capable model only at initialization to “ground” the image content; perform subsequent recombination with a cheaper text-only model, achieving 2.3–2.7× savings with matched or improved accuracy on MMMU-Pro/BabyVision.
- Potential tools/workflows: Vision model for loop 0; text-only routing for later loops; lite aggregation for consensus groups.
- Assumptions/dependencies: Tasks where initial visual grounding suffices and later reasoning is textual; careful prompt design to preserve visual context across loops.
- Public-sector and enterprise chatbots with budget-aware escalation (Public Services, Customer Support)
- What it enables: triage-based escalation—use cheap models for consensus cases, escalate uncertain groups to a frontier model; reduce costs while maintaining answer quality.
- Potential tools/workflows: Group confidence from token logprobs or answer diversity; dynamic routing thresholds; logging for auditability.
- Assumptions/dependencies: Well-defined acceptability criteria; privacy and compliance for cross-model data sharing; human fallback for low-confidence results.
- Procurement and deployment strategy for mixed open/closed models (Policy, IT Strategy)
- What it enables: Combine open-weight (self-hosted) and proprietary APIs to reach capability targets under cost constraints; shift spending to high-marginal-utility steps.
- Potential tools/workflows: Budget planning around routing percentile p; capacity planning for latency-matched GPU pools; benchmarking against internal targets.
- Assumptions/dependencies: Stable API pricing; internal ability to self-host open-weight models; vendor policies around logprob access.
- Inference infrastructure upgrades for confidence scoring (Cloud/ML Systems)
- What it enables: Deploy prefill-only confidence computation to accelerate cross-model scoring by 4–10× and reduce memory/transfer overhead (e.g., vLLM prefill path returning a scalar).
- Potential tools/workflows: vLLM plugin or patch for on-GPU accumulation of confidence; batched prefill scoring; per-problem adaptive thresholds.
- Assumptions/dependencies: Access/modification rights to serving stack; GPU memory sizing for resident models; minimal overhead target (2.4–4.3% observed).
- Safety-aware routing with calibrated confidence (Risk, Compliance)
- What it enables: Use group confidence and answer diversity to detect uncertain or conflicting candidates; automatically escalate to stronger models or human review.
- Potential tools/workflows: Confidence dashboards; risk-based routing rules; logs for incident analysis.
- Assumptions/dependencies: Confidence calibration per domain; oversight protocols for escalations; careful monitoring to avoid silent failure on adversarial inputs.
- Data labeling and QA with verifier-free aggregation (Data Ops)
- What it enables: Aggregate multiple noisy annotations (e.g., extraction, classification) without expensive external verifiers; reduce cost via lite aggregation where consensus exists.
- Potential tools/workflows: K-subset grouping from candidate labelers; majority vote for consensus; confidence-triggered escalations.
- Assumptions/dependencies: Clear answer extraction; ground-truth audits for a subset; privacy when mixing vendors.
- On-device + cloud hybrid apps (Edge AI)
- What it enables: Perform the expensive initialization in the cloud (frontier/vision model) and delegate subsequent recombination loops to on-device cheaper models to reduce latency/bandwidth.
- Potential tools/workflows: Split pipelines across edge and cloud; caching of loop-0 outputs; lightweight aggregators on-device.
- Assumptions/dependencies: Device capable of running a small model; secure data transfer; acceptable end-to-end latency.
Long-Term Applications
These applications require further research, scaling, or integration with domain-specific systems or verifiers.
- Verifier-efficient scientific discovery pipelines (R&D, Materials, Energy, Pharma)
- Potential: Use verifier-free evolution to pre-screen candidate hypotheses/designs (e.g., structures, parameters) and reserve expensive simulations/experiments as sparse verifiers, reducing compute-lab costs and queue times.
- Tools/workflows: Hybrid loops—cheap evolution with periodic high-fidelity verification; accumulate update rule to preserve promising lineages; confidence-guided selection to maintain diversity.
- Assumptions/dependencies: Domain-appropriate priors/prompts; reliable surrogate fitness signals before verification; careful risk management for false positives.
- Autonomous design and program synthesis with marginal-cost control (Software, EDA, AutoML)
- Potential: Synthesize code, circuits, or configs by routing recombination to appropriate models as search progresses; maintain solution diversity to avoid mode collapse.
- Tools/workflows: Evolutionary operators as modular services; integration with build/test pipelines; dynamic routing tuned to budget and deadlines.
- Assumptions/dependencies: Verifier integration for final acceptance; guardrails against reward hacking; incremental training may further improve.
- Agentic systems with hierarchical routing (General AI, Enterprise Automation)
- Potential: Extend routing from recombination groups to full subtask graphs—on-device small models for routine steps, cloud frontier models for critical decisions; tighter SLA control.
- Tools/workflows: Task-graph schedulers aware of confidence; multi-modal tier routing; cost–risk policy engines.
- Assumptions/dependencies: Robust task decomposition; consistent confidence calibration across tasks and modalities; orchestration complexity.
- Robust multimodal reasoning for robotics and embodied AI (Robotics)
- Potential: Initial perception with a vision model, then offline, cheaper textual reasoning for planning; reduce compute on resource-constrained robots.
- Tools/workflows: Perception-to-text grounding; staged planning loops with cheap models; fallback to full-stack vision when confidence drops.
- Assumptions/dependencies: Tasks where visual grounding persists across planning; tight real-time constraints; safety validation.
- Calibrated confidence APIs and standards (Ecosystem/Policy)
- Potential: Standardize token-level/top-K confidence exposure across providers to enable interoperable routing and safety policies.
- Tools/workflows: Provider-neutral confidence schema; evaluation suites for confidence fidelity; governance guidelines for escalation policies.
- Assumptions/dependencies: Provider cooperation; privacy/PII-safe logging; consensus on calibration metrics.
- Hardware and kernel support for prefill-only scoring (Systems/Hardware)
- Potential: NIC/GPU kernels specialized for sequence prefill and scalar confidence accumulation to further reduce latency and energy for routing at scale.
- Tools/workflows: Runtime paths for prefill-only batches; memory-optimized token-prob pipelines; hardware–software co-design.
- Assumptions/dependencies: Vendor support; sufficient demand for dedicated primitives; interoperability with serving frameworks.
- Curriculum-based evolution for education and training (Education)
- Potential: Adaptive problem solving where harder items are escalated to stronger models while easier items are consolidated cheaply; personalized curricula at lower cost.
- Tools/workflows: Difficulty-aware routers tied to learner models; multi-turn tutoring with cost caps; teacher dashboards showing confidence profiles.
- Assumptions/dependencies: Pedagogical validation; bias and fairness checks; parental/educator oversight.
- Risk-managed decision support in regulated domains (Healthcare, Finance, Legal; with human oversight)
- Potential: Apply verifier-free evolution for drafting and exploration, escalate to expert review or higher-tier models for low-confidence cases, reducing routine costs while preserving safety.
- Tools/workflows: Confidence-triggered escalation trees; traceable aggregation logs; auditable reason chains.
- Assumptions/dependencies: Strict human-in-the-loop; domain approvals; explicit non-diagnostic disclaimers in healthcare; compliance-grade logging and privacy.
- Benchmarking and research methodology for test-time scaling (Academia/Industrial Research)
- Potential: Use the unified evolutionary formulation to compare methods, study diversity collapse, and develop new fitness signals and operators.
- Tools/workflows: Open-source Squeeze Evolve SDK; replayable pipelines; ablation harness for routing thresholds and grouping strategies.
- Assumptions/dependencies: Community adoption; standardized datasets; reproducible serving environments.
- Marketplaces for modular evolutionary operators (AI Platforms)
- Potential: Pluggable “initialize,” “select,” “recombine,” and “score” operators from different vendors; cost-aware auctions for operator slots at inference time.
- Tools/workflows: Operator APIs with capability/cost metadata; real-time bidding based on confidence and budget; compliance gates.
- Assumptions/dependencies: Interop standards; incentives for vendors; robust metering and privacy controls.
Notes on Feasibility and Dependencies
- Confidence signal availability: Best performance relies on token logprobs or top-K probabilities; where APIs lack this (e.g., some vision models), answer diversity is a fallback but may be coarser.
- Initialization dominance: Strong initial populations materially impact final accuracy; budget the strongest model at loop 0 when possible.
- Routing hyperparameter p: A single percentile controls the accuracy–cost trade-off; requires light tuning by domain.
- Diversity preservation: Multi-model orchestration mitigates diversity collapse; group formation and sampling temperature influence outcomes.
- Governance and safety: In high-stakes domains, maintain human oversight and/or external verifiers; log decisions for auditability.
- Infrastructure: Benefits compound with latency-matched pools, batched prefill scoring, and minimal orchestration overhead; self-hosting open weights can unlock larger savings.
Glossary
- AIME 2025: A benchmark of math problems (American Invitational Mathematics Examination) used to evaluate mathematical reasoning of LLMs. "We evaluate Squeeze Evolve across AIME~2025, HMMT~2025, GPQA-Diamond, LiveCodeBench~V6, MMMU-Pro, BabyVision, ARC-AGI-V2, and circle packing"
- AlphaEvolve: An LLM-driven evolutionary pipeline that uses an external verifier to evaluate candidate programs. "AlphaEvolve uses explicit external verifier, where candidate programs are evaluated and the resulting scalar rewards guide future search."
- Ancestor function: The initialization function that generates the initial population of candidate trajectories. "For a query , we initialize a population using an ancestor function "
- ARC-AGI-V2: A challenging visual reasoning benchmark (Abstraction and Reasoning Corpus) for general intelligence. "On ARC-AGI-V2, Squeeze Evolve achieves 97.5\% accuracy at \$7.74/task without code execution, setting a new state-of-the-art cost-capability frontier"
- BabyVision: A multimodal vision benchmark focusing on visual reasoning. "Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision, Squeeze Evolve consistently improves the costâcapability frontier"
- Circle packing: An optimization problem of packing circles to maximize the sum of radii; used as a scientific discovery task. "On circle packing, it is the first verifier-free evolutionary method to match, and in some cases exceed, the performance of verifier-based evolutionary methods."
- Confidence engine: A custom GPU-side implementation to compute confidence statistics efficiently during prefill. "a custom confidence engine reduces scoring latency by 4--10, latency-matched GPU pools prevent bottlenecks, and the end-to-end routing overhead is only 2.4--4.3\%"
- Confidence-based routing: Assigning groups to models based on confidence signals to optimize cost and accuracy. "We introduce confidence-based routing, a lightweight mechanism that assigns each recombination group to the most cost-effective model using only signals already produced during inference"
- Cost–capability frontier: The trade-off curve between model performance and cost. "Squeeze Evolve shifts the cost--capability frontier left by combining verifier-free evolution with multi-model orchestration."
- Cross-model confidence: Confidence computed by scoring a trajectory under a different model than the one that generated it. "Cross-model confidence scores a trajectory under a different model from the one that generated it."
- DeepConf: A method that uses token-level confidence estimates to filter reasoning traces. "DeepConf~\citep{fu2025deepthinkconfidence} uses token-level confidence to filter traces."
- Diversity collapse: The degeneration of population diversity during iterative generation, reducing search capacity. "Self-aggregation methods such as RSA~\citep{venkatraman2026recursiveselfaggregationunlocksdeep} and Mixture-of-Agents~\citep{wang2024mixtureofagentsenhanceslargelanguage} combine multiple LLM outputs into refined answers, but use a single model or fixed assignment, leading to diversity collapse~\citep{singh2026v1unifyinggenerationselfverification}."
- Evolutionary operator: An operator that encapsulates selection and recombination steps in the evolution process. "We unify these steps into a single evolutionary operator , which encapsulates selection followed by recombination:"
- External verifier: An outside mechanism (e.g., tests or reward models) that checks candidate solutions. "When coupled with an external verifier, this paradigm can unlock powerful discovery capabilities."
- Fitness signal: A scalar proxy for trajectory quality used to guide selection and routing. "Let denote a fitness signal: a function that maps a set of candidate trajectories to quality estimates."
- Fitness-weighted selection: Sampling candidates with probabilities proportional to their fitness scores. "or by fitness-weighted sampling, where candidates are drawn with probability "
- GPQA-Diamond: A high-difficulty graduate-level QA benchmark. "We evaluate Squeeze Evolve across AIME~2025, HMMT~2025, GPQA-Diamond, LiveCodeBench~V6, MMMU-Pro, BabyVision, ARC-AGI-V2, and circle packing"
- Group confidence (GC): An aggregate confidence score over tokens and candidates within a group. "Group confidence (GC) derives from the top- token log-probabilities already produced during inference."
- Group diversity: A measure of distinct final answers within a group to gauge disagreement. "Group diversity provides an equivalent signal when token log-probabilities are unavailable (e.g., APIs that do not expose prefill-only scoring):"
- HMMT 2025: A math competition benchmark (Harvard–MIT Mathematics Tournament) for assessing reasoning. "We evaluate Squeeze Evolve across AIME~2025, HMMT~2025, GPQA-Diamond, LiveCodeBench~V6, MMMU-Pro, BabyVision, ARC-AGI-V2, and circle packing"
- Latency-matched GPU pools: A serving strategy that sizes model pools so their per-loop runtimes align, preventing idle time. "latency-matched GPU pools prevent bottlenecks, and the end-to-end routing overhead is only 2.4--4.3\%"
- LiveCodeBench V6: A contamination-free code generation benchmark. "We evaluate Squeeze Evolve across AIME~2025, HMMT~2025, GPQA-Diamond, LiveCodeBench~V6, MMMU-Pro, BabyVision, ARC-AGI-V2, and circle packing"
- Majority voting (self-consistency): Selecting the most frequent answer among multiple samples; a test-time scaling method. "majority voting (self-consistency) is a degenerate single-step process that generates a population once and selects the largest answer cluster using consensus frequency as an implicit fitness signal."
- Marginal utility: The additional benefit of using a stronger model at a particular step. "allocate model capability where it has the highest marginal utility."
- Mixture-of-Agents: A framework that combines outputs of multiple LLM agents via aggregation. "Mixture-of-Agents~\citep{wang2024mixtureofagentsenhanceslargelanguage} combine multiple LLM outputs into refined answers"
- MMMU-Pro: A multidiscipline multimodal benchmark for visual understanding. "Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision"
- Multi-model orchestration: Coordinating multiple models with different costs and capabilities across pipeline stages. "We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference."
- Non-LLM aggregation: Lightweight, non-generative methods (e.g., voting) to combine candidates. "based on the fitness signal: models ordered by increasing cost, plus a lightweight non-LLM aggregation tier."
- Pass@K: The probability of solving a task with up to K independent attempts. "This drives the population toward an increasingly narrow solution mode, causing pass@ to fall along with semantic diversity"
- Prefill-only: An inference mode that only performs a forward pass without autoregressive decoding. "As a result, cross-model scoring is a prefill-only operation whose cost scales linearly with sequence length."
- Program synthesis: Automatically generating programs to solve tasks. "Uses code execution and program synthesis."
- Recursive self-aggregation (RSA): An iterative method that repeatedly aggregates subsets of candidates to refine answers. "recursive self-aggregation (RSA) corresponds to a verifier-free multi-step evolutionary process"
- Recombination: Synthesizing a new candidate from a group of existing trajectories. "We unify these steps into a single evolutionary operator , which encapsulates selection followed by recombination:"
- Routing percentile: The per-problem threshold (percentile p) used to decide which groups go to which model. "The routing percentile~ is the single hyperparameter practitioners tune at deployment time."
- Self-aggregation: Letting the model combine its own outputs into refined candidates. "Self-aggregation methods such as RSA~\citep{venkatraman2026recursiveselfaggregationunlocksdeep} and Mixture-of-Agents~\citep{wang2024mixtureofagentsenhanceslargelanguage} combine multiple LLM outputs into refined answers"
- Self-evolution: Iteratively improving candidates via selection, mutation, and recombination without external verification. "A particularly promising direction is self-evolution, where models iteratively improve candidates through selection, mutation, and recombination"
- Self-model confidence: Confidence computed from the same model that generated the trajectory. "Self- and cross-model confidence serve as effective proxies for fitness estimation."
- Serving throughput: The number of tasks completed per unit time under a fixed budget. "increases fixed-budget serving throughput by up to %%%%1415%%%%."
- State-of-the-art: The best known performance at a point in time. "setting a new state-of-the-art cost-capability frontier"
- Test-time scaling: Improving output quality by spending extra compute at inference time (e.g., search or refinement). "Test-time scaling has emerged as a practical way to push LLMs beyond one-shot inference"
- Token log-probabilities: Per-token log probabilities output by the model used for confidence estimation. "token log-probabilities already produced during inference"
- Trajectory: A sequence of generated tokens (reasoning trace and answer) for a single attempt. "Let denote a fitness signal: a function that maps a set of candidate trajectories to quality estimates."
- vLLM: A high-throughput LLM serving system used to implement the custom prefill path. "we implement a custom prefill path in vLLM that accumulates the confidence statistic directly on GPU"
- Verifier-based: Methods that rely on external verification signals to guide evolution. "the performance of verifier-based evolutionary methods."
- Verifier-free evolution: Evolutionary inference without access to external verification, relying on intrinsic signals. "We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference."
Collections
Sign up for free to add this paper to one or more collections.

