- The paper demonstrates that LLMs learn through optimal lossy compression aligned with Information Bottleneck theory.
- It introduces a scalable entropy estimator using randomized soft quantization to effectively measure high-dimensional representations.
- Compression optimality, quantified by the ratio I(Y;Z)/I(X;Z), is shown to robustly predict downstream performance across models.
Learning is Forgetting: LLM Training as Optimal Lossy Compression
Introduction
This work presents a comprehensive information-theoretic analysis of LLM training, framing representation learning as an instance of lossy compression. By introducing scalable, tractable mutual information estimation for LLMs, the authors demonstrate that pre-training systematically aligns with Information Bottleneck (IB) theory. The optimality and structure of a model's internal representations robustly predict downstream task performance across a spectrum of benchmarks and model sizes. Its central thesis is that LLMs learn by compressing their training data and retaining only the information most relevant to their prediction objective, thus approaching optimality predicted by rate-distortion theory.
Framing LLM Training as Lossy Compression
LLMs are trained on trillions of tokens, resulting in high-dimensional internal representations. Drawing from information theory, the authors highlight an analogy to lossy data compression: just as mp3 or jpeg formats discard perceptually irrelevant information, LLMs discard input information that does not contribute to improved predictive performance. The mathematical framework operative here is the Information Bottleneck (IB), where the model seeks to retain as much mutual information with the target (I(Y;Z), "expressivity") as possible for a given amount of information about the input (I(X;Z), "complexity"), compressing away details not needed for prediction.
The "information plane"—plotting I(X;Z) versus I(Y;Z)—provides a geometric and conceptual tool for interpreting learning dynamics. The IB bound specifies the limiting frontier for optimal lossy compression; models lying close to or on this boundary are maximally efficient given their inductive and training biases.
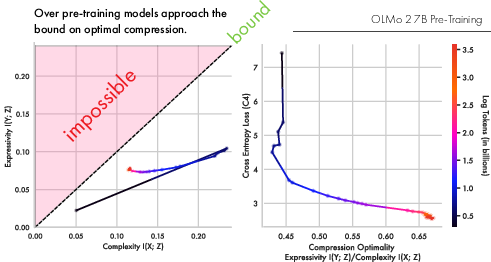
Figure 1: The OLMo2-7B LLM’s pre-training trajectory in the information plane, first expanding expressivity then compressing complexity until representations approach the optimal IB bound as loss saturates.
Computing mutual information with high-dimensional, continuous representations is challenging. The authors present and deploy a scalable entropy estimator based on randomized soft quantization over the unit hypersphere. For each layer's representations, they perform a soft assignment to random reference vectors and aggregate these assignments to approximate Shannon entropy. This process allows conditional and unconditional entropy estimates at scale and is robust to the curse of dimensionality—critical for practical application in large LLMs.
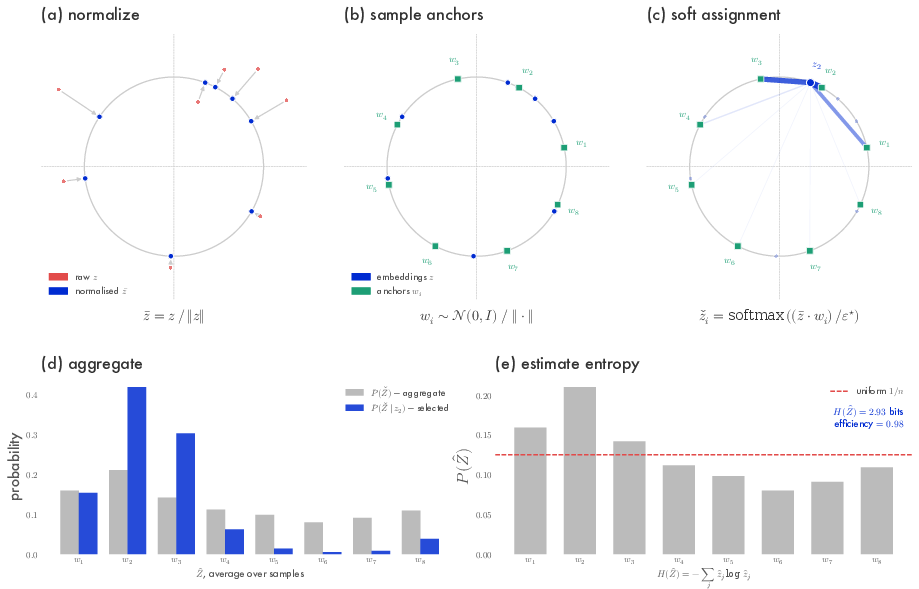
Figure 2: The estimation pipeline for soft entropy, comprising normalization, random projection, soft assignments, and aggregation for efficient mutual information estimation.
Contextual mutual information is estimated by conditioning on n-gram windows of various lengths using back-off strategies, providing fine control over granularity. Expressivity and complexity for tokens, bigrams, trigrams, and higher n-grams are efficiently computed for all layers and across checkpoints, enabling model-scale analysis.
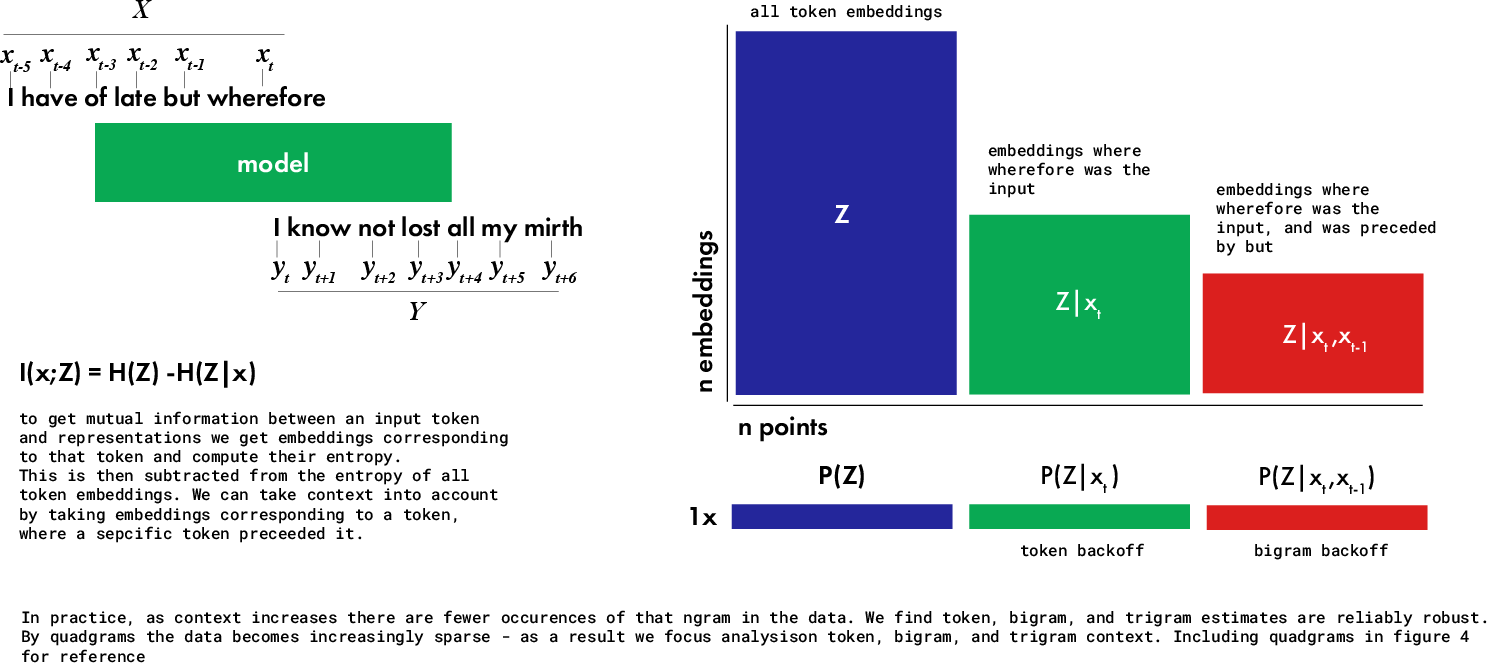
Figure 3: The conditional probability estimation protocol, demonstrating how context windows are sub-selected for precise, scalable conditional mutual information estimation.
Two-Phase Learning Dynamics: Empirical Confirmation of IB Theory
Tracking OLMo2 family models across pre-training, the authors observe a two-phase IB learning dynamic: initial expansion (growing I(Y;Z) as representations become increasingly predictive), followed by a compression phase (reducing I(X;Z) by pruning task-irrelevant complexity) until the IB bound is approached and loss saturates.
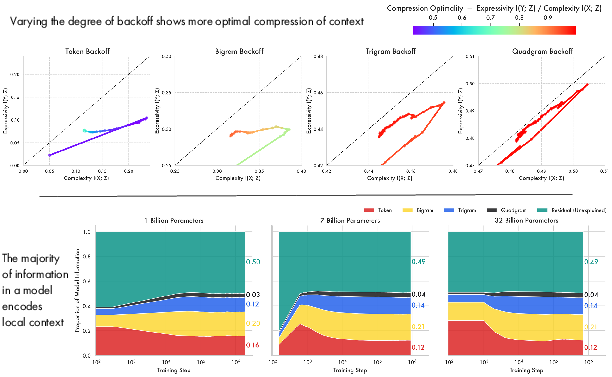
Figure 4: Evolution of information plane coordinates when varying the context window, demonstrating that LLMs compress both token and contextual information over training via information bottleneck dynamics.
Intriguingly, how much context a model encodes—moving from token to quadgram—shapes the approach to the optimal bound. Larger context representations (e.g., trigrams, quadgrams) compress both source and target distributions, reflecting the local contextual nature of natural language.
Scale, Training Data, and the Limits of Compression
Model and dataset scale critically influence these learning dynamics. Large models (e.g., OLMo2 7B, 32B) closely approach the optimal IB bound, traversing the full expansion-compression learning trajectory. Smaller models (e.g., 1B) can perform the initial expansion but oscillate and fail to achieve meaningful compression in later training, consistently lagging behind larger counterparts. This suggests a threshold for representational capacity is required to achieve optimal lossy compression for complex data distributions.
When extending these analyses across 47 open-weight models spanning diverse architectures and training regimens, the convergence to the IB bound is a robust, family-agnostic phenomenon; all models cluster tightly near the theoretical optimum, regardless of architecture or hyperparameter selection.
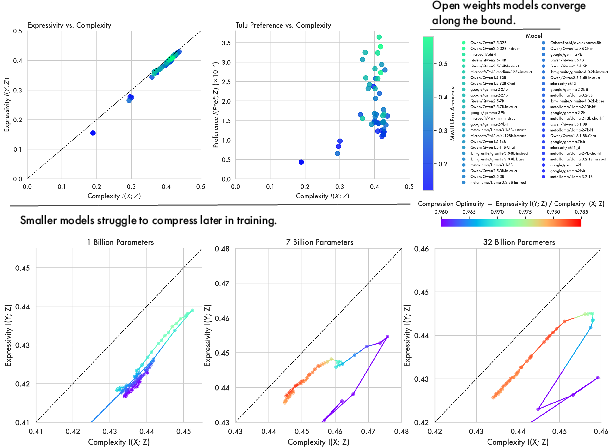
Figure 5: Trigram-level information planes for 75 open-weights models, demonstrating near-universal convergence towards the IB bound and highlighting the scale-dependent quality of compression.
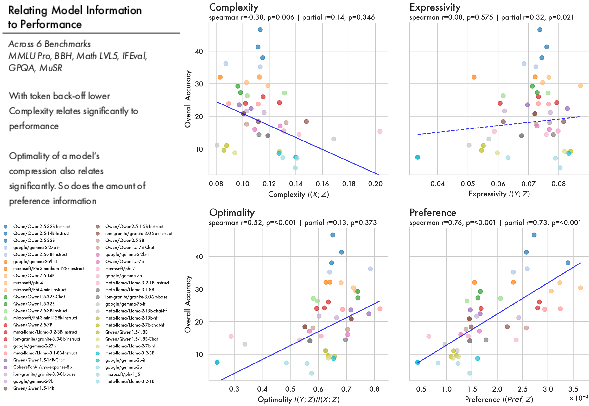
A key contribution is the empirical linkage between representational structure—as quantified by information-theoretic statistics—and downstream performance. Across six competitive benchmarks (MMLU Pro, BBH, Math LVL5, IFEval, GPQA, MuSR):
Those models that more optimally compress context, rather than tokens, outperform others. Similarly, models with greater preserved information about human preferences (computed using preference-labeled datasets) robustly outperform less preference-sensitive models on instruction-following and alignment tasks.
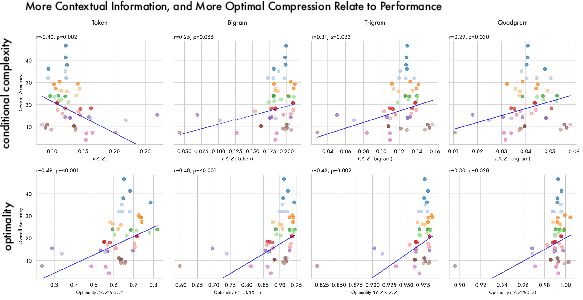
Figure 7: Proportions of token- versus context-level information correlated with downstream performance: as models allocate more bits to contextual distinctions, benchmark performance rises.
Theoretical and Practical Implications
This work advances a rigorous, unifying theory that subsumes classical learning-theoretic intuitions (e.g., Occam’s Razor, bias-variance, rate-distortion tradeoffs) and mechanistic interpretability perspectives. It empirically links optimal compression—quantified in the information plane—to both generalization and alignment, assigning causal status to lossy compression as the driver of model capabilities and limitations. The strong correlation of compression optimality with downstream performance provides actionable criteria for model selection (e.g., checkpoint picking, early stopping). Moreover, the tractable estimation procedure described is applicable to any LLM, independent of scale or architecture; it can be operationalized using only a single forward pass with teacher forcing on a representative data slice.
For future research, several directions are promising:
- Extending to fine-tuning and preference alignment: Quantifying information transitions across instruction- and preference-focused post-training.
- Entropy-driven early stopping and model selection: Leveraging proximity to the IB bound as a computationally efficient selection metric.
- Generalization to non-language domains: Testing whether architectures for other modalities (e.g., vision transformers) also exhibit bound-approaching compression behaviors.
Conclusion
LLM pre-training is fundamentally a process of optimal lossy compression: representations evolve to preserve the minimal sufficient statistics of their input for prediction under the constraints of model capacity and task relevance. This compressive process is observable, quantifiable, and predictive of practical performance. The information-theoretic methodology introduced here provides a model- and scale-agnostic lens for analyzing, understanding, and predicting LLM behavior—laying foundations for principled interpretability and improved training procedure design anchored in global representational statistics rather than solely local, circuit-based explanations.