- The paper introduces semi-online reinforcement learning that simulates online dynamics on static data to optimize GUI automation tasks.
- It employs a Patch Module with multiple strategies and a dual-level reward structure to balance local action accuracy and global task performance.
- Empirical results show state-of-the-art performance on multi-turn benchmarks, with strong SOP metrics and notable gains over baseline models.
Semi-online Reinforcement Learning for GUI Automation: The UI-S1-7B Approach
Motivation and Problem Setting
Graphical User Interface (GUI) automation agents have advanced rapidly with the integration of multimodal LLMs and reinforcement learning (RL). However, a fundamental dichotomy persists: offline RL offers stable, efficient training on static datasets but fails to generalize to multi-turn, long-horizon tasks due to lack of trajectory-level reward signals and exposure bias; online RL enables agents to learn from their own outputs and recover from errors, but is hampered by sparse rewards, high deployment costs, and limited data diversity. The UI-S1 paper introduces Semi-online RL, a paradigm that simulates online RL dynamics using only offline trajectories, aiming to combine the stability and efficiency of offline RL with the robustness and long-horizon optimization of online RL.
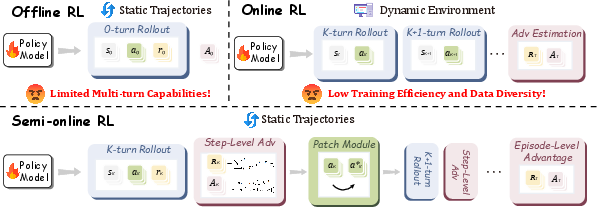
Figure 1: Semi-online RL simulates online RL on static trajectories, efficiently enhancing multi-turn agent capabilities.
Semi-online RL: Methodology
Semi-online Rollout
The core of Semi-online RL is the semi-online rollout: during training, the agent generates actions conditioned on its own historical outputs, not just expert demonstrations. When the agent's action matches the expert, the next state is taken from the expert trajectory. If a mismatch occurs, a Patch Module is invoked to recover the trajectory and continue training, rather than terminating the rollout.
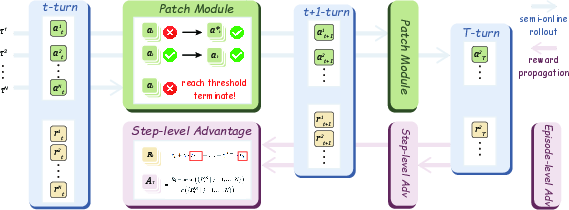
Figure 2: Semi-online RL with Patch Module for adaptive recovery from action mismatches and dual-level advantage computation.
Patch Module
The Patch Module enables continued learning after action mismatches by injecting expert actions and, optionally, synthetic reasoning. Three patching strategies are evaluated:
- Thought-Free Patch: Only the expert action is injected, with no reasoning.
- Off-Policy Thought Patch: Reasoning is generated by an auxiliary model.
- On-Policy Thought Patch: Reasoning is generated by the current policy model, maintaining style consistency.
Empirically, Thought-Free Patch with a patch threshold ϵ=1 achieves the best trade-off between performance and computational efficiency.
Policy Optimization
Semi-online RL introduces a hierarchical reward structure and dual-level advantages:
- Step-level advantage: Measures the relative return of an action at a specific step across sampled rollouts.
- Episode-level advantage: Measures the total return of a trajectory relative to other trajectories in the batch.
The final advantage is a weighted sum of both, enabling the policy to optimize for both local accuracy and global task completion. Discounted future returns (γ=0.5) are used to propagate long-horizon rewards, which is critical for multi-turn reasoning.
Evaluation: Metrics and Benchmarks
The paper introduces SOP, a semi-online evaluation metric that maintains model-generated history during evaluation, closely mirroring real-world deployment. SOP demonstrates a much stronger correlation with true online performance (AndroidWorld, R2=0.934) than traditional offline metrics (e.g., AndroidControl-High, R2=0.470).
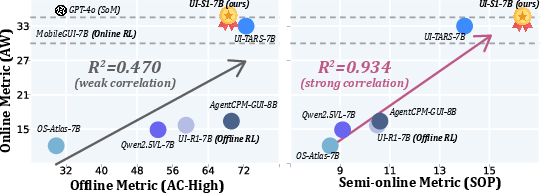
Figure 3: SOP shows strong correlation with online metrics, while traditional offline metrics are weak proxies.

Figure 4: SOP achieves high efficiency, diversity, and correlation with online performance compared to other evaluation methods.
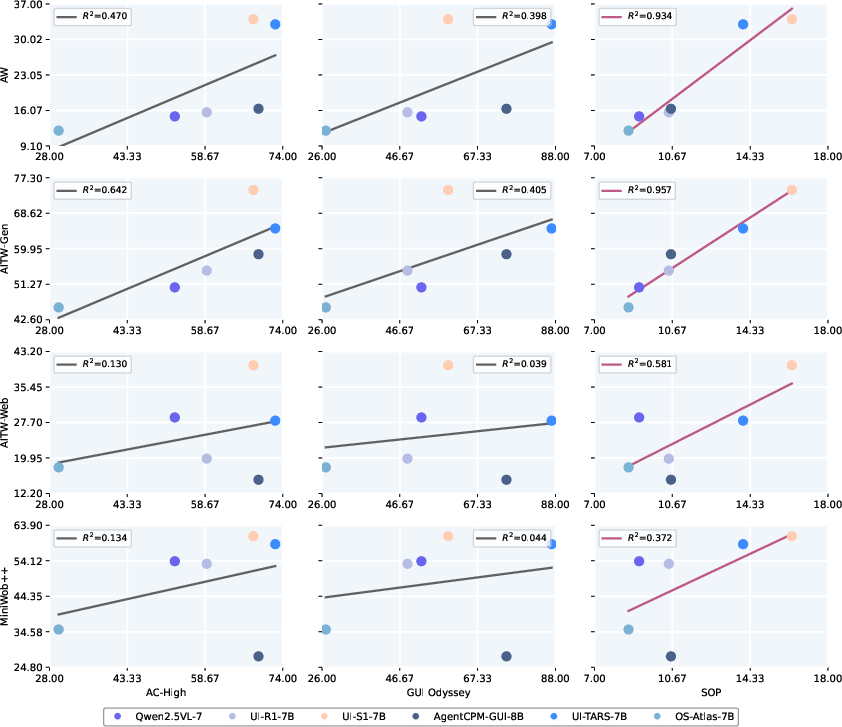
Figure 5: SOP outperforms AC-High and GUI Odyssey in correlation with online metrics across multiple benchmarks.
Benchmarks
UI-S1-7B is evaluated on both multi-turn (AndroidWorld, AITW-Gen, AITW-Web, MiniWob++) and single-turn (ScreenSpot-V2, AndroidControl-High, GUI Odyssey) benchmarks. The model achieves state-of-the-art results among all open-source 7B models on multi-turn tasks, with substantial improvements over the base model (Qwen2.5VL-7B): +12.0% on AndroidWorld, +23.8% on AITW-Gen, and competitive results on single-turn tasks.
Empirical Analysis
Patch Module Ablation
Increasing the patch threshold ϵ (number of mismatches allowed before termination) consistently improves SOP and AndroidWorld scores, with diminishing returns and increased computational cost for large ϵ. Thought-Free Patch is preferred for its efficiency and competitive performance.
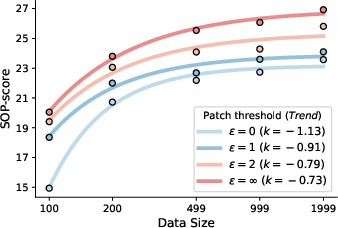
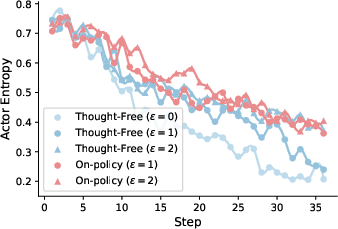
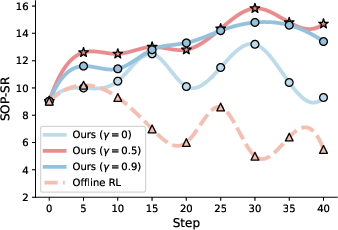
Figure 6: Data scaling for different ϵ values in Thought-Free Patch, showing SOP-score improvements.
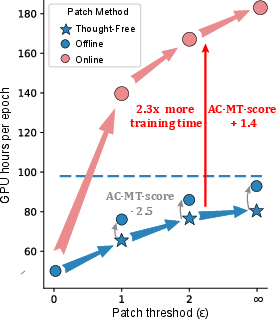
Figure 7: Training GPU hours for different patch methods and thresholds, highlighting the efficiency of Thought-Free Patch.
Training Dynamics and Scaling
Semi-online RL exhibits favorable scaling laws: larger ϵ values not only improve absolute performance but also enhance data efficiency. The method maintains higher policy entropy during training, supporting more robust exploration and preventing premature convergence.
Discount Factor and Training Paradigm Ablation
Discounting future rewards (γ=0.5) is essential for multi-turn performance; setting γ=0 (no future rewards) leads to significant degradation. Combining SFT with Semi-online RL yields the best results, outperforming either method alone and reducing redundant actions.

Figure 8: Left: Training paradigm combinations; Middle: Average steps to complete AndroidWorld tasks; Right: Ablations on episode advantages and historical images.
Case Studies
Qualitative analysis demonstrates that UI-S1-7B can handle complex, cross-application, multi-step tasks requiring information retention and consistent reasoning-action alignment. In contrast, offline RL and SFT-only models exhibit premature termination, information loss, or redundant actions.
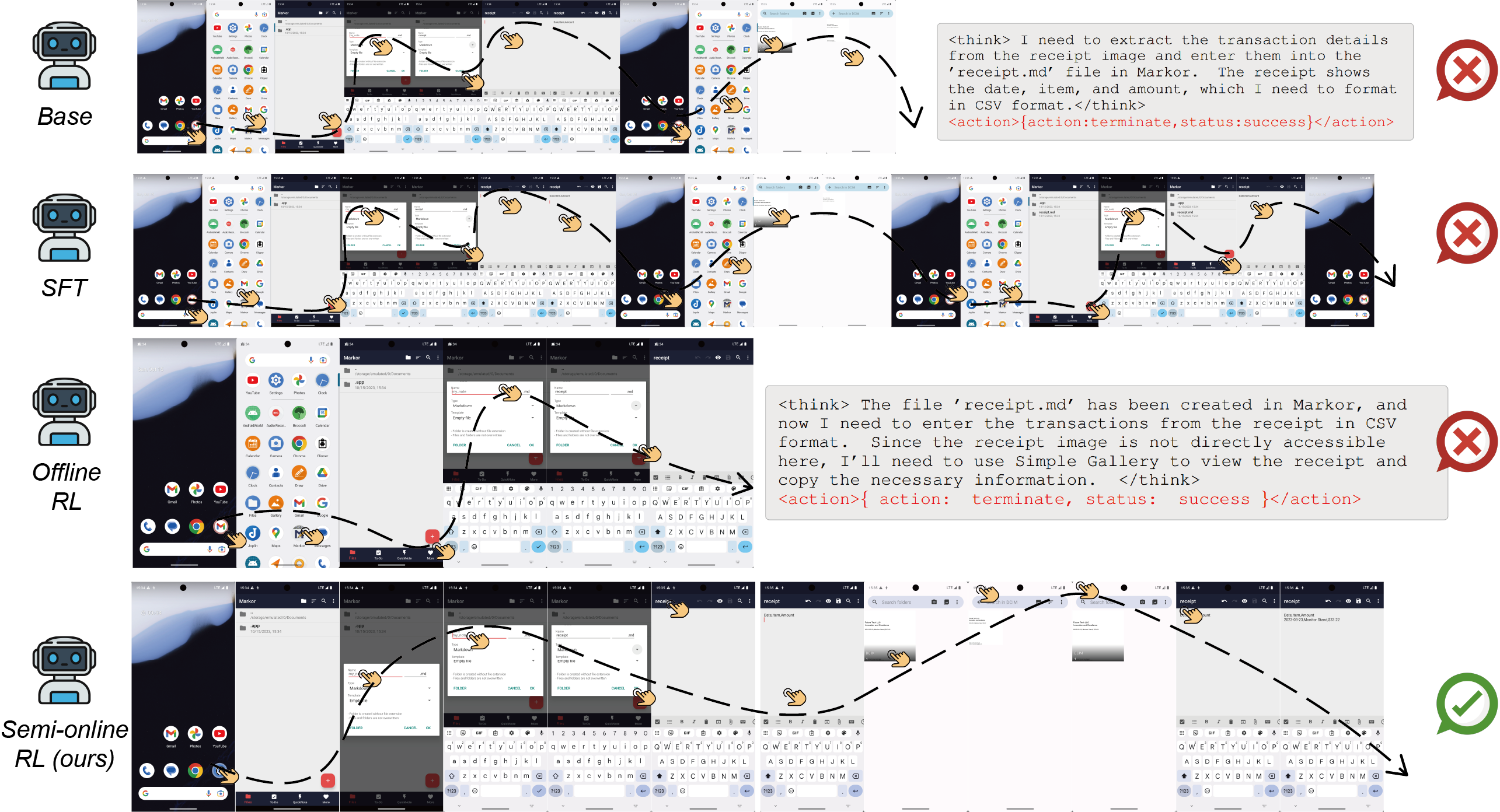
Figure 9: Successful cross-app, multi-step task in AndroidWorld, requiring information transfer and memory.
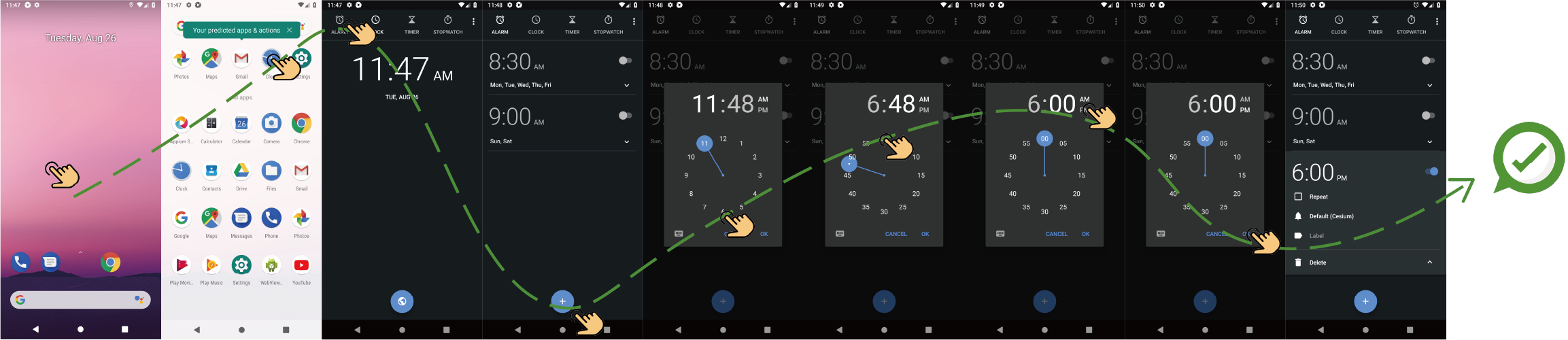
Figure 10: Successful task in AITW-Gen: "Set an alarm for 6pm".
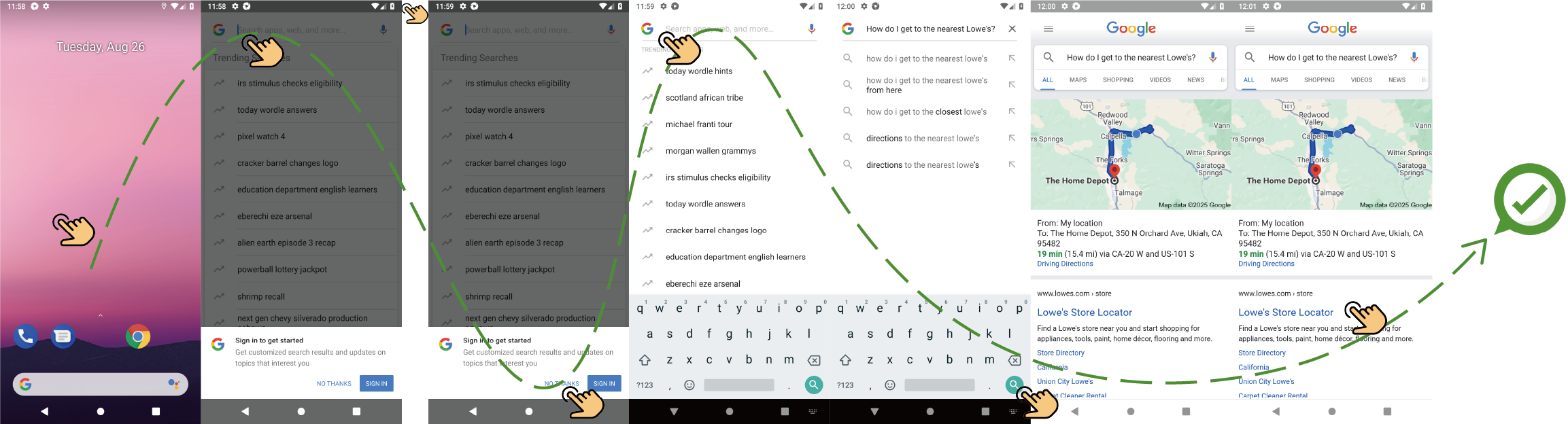
Figure 11: Successful task in AITW-Gen: "How do I get to the nearest Lowe's?".

Figure 12: Successful task in AndroidWorld: "Delete the following recipes from Broccoli app...".
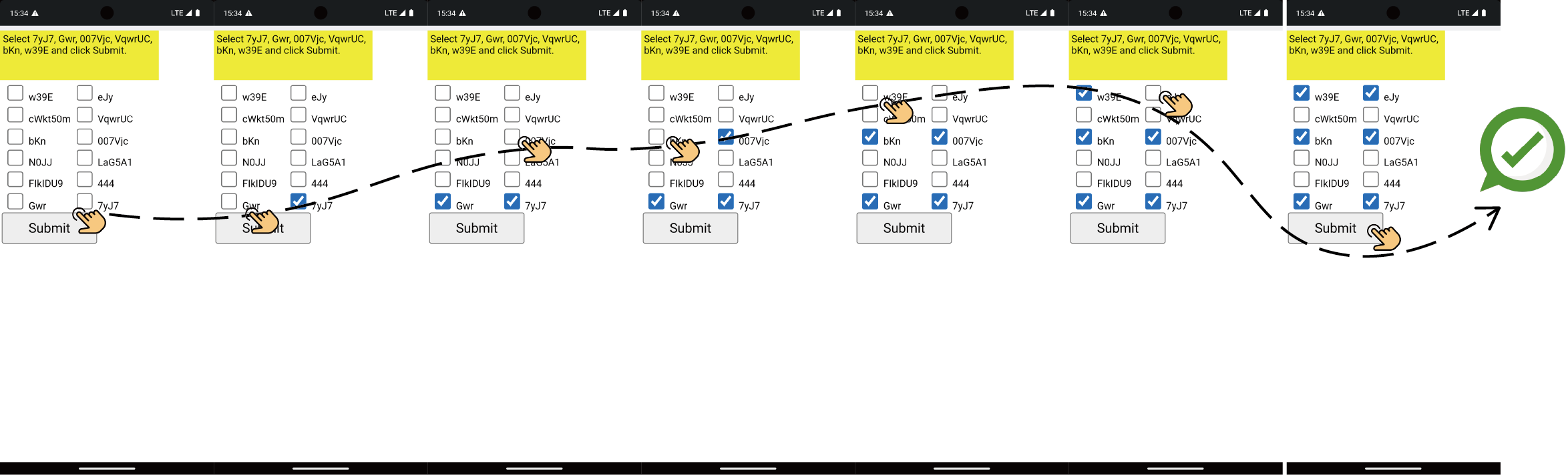
Figure 13: Successful task in MiniWob++: multi-selection and submission.
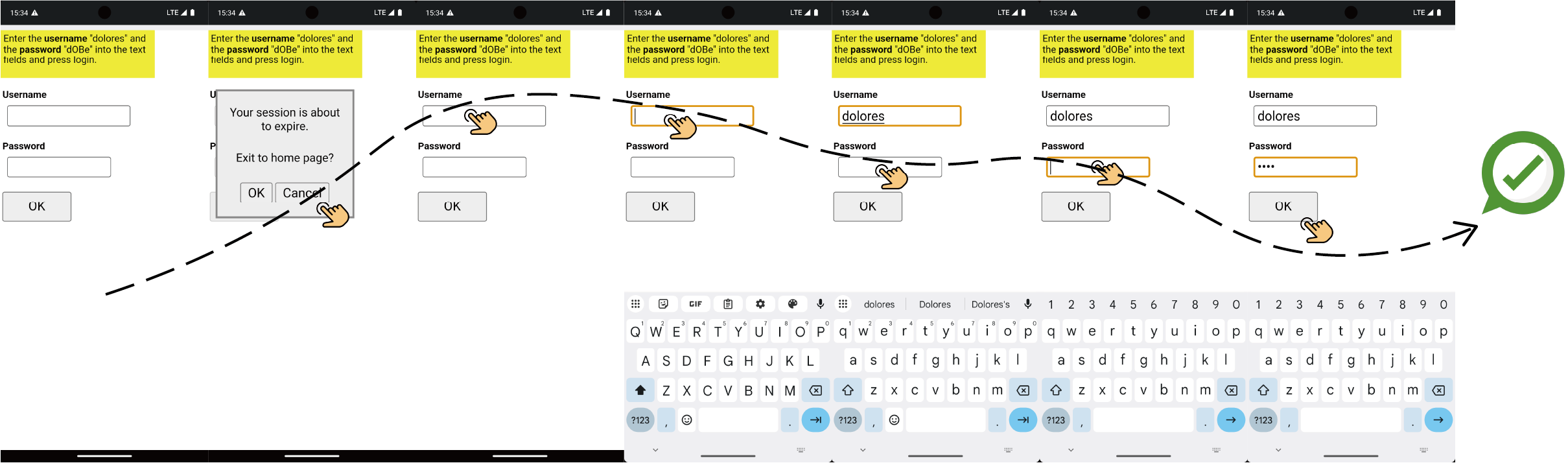
Figure 14: Successful task in MiniWob++: login with username and password.
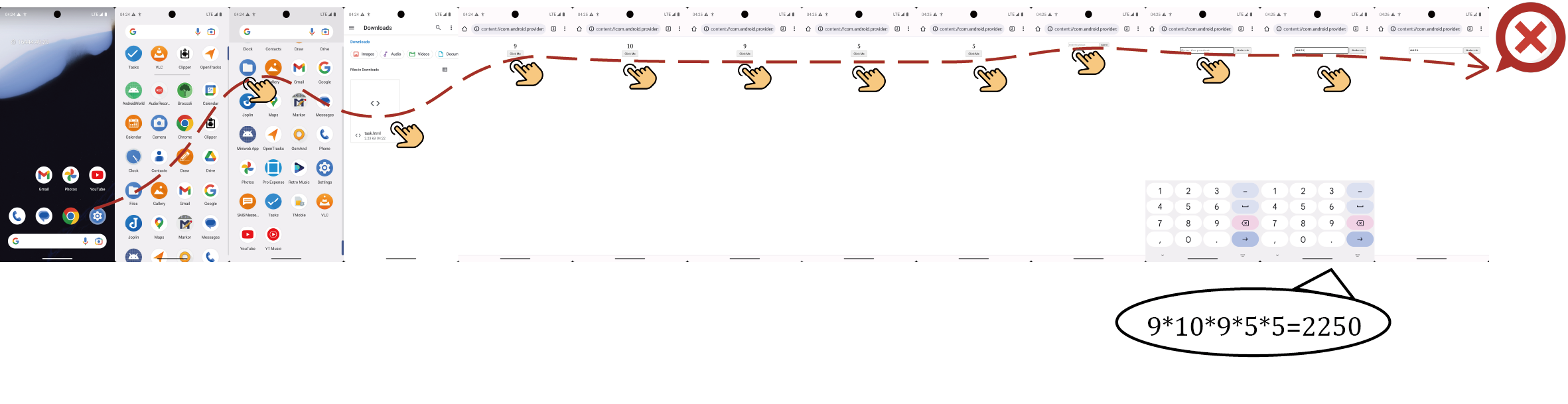
Figure 15: Failure case in AndroidWorld: correct memory but arithmetic error in multi-step reasoning.
Implications and Future Directions
The Semi-online RL paradigm addresses a critical bottleneck in GUI agent training: the inability of offline RL to generalize to multi-turn, long-horizon tasks, and the impracticality of large-scale online RL. By simulating online dynamics on static data and introducing robust patching and hierarchical credit assignment, UI-S1-7B achieves strong generalization and efficiency. The SOP metric provides a practical, reliable proxy for real-world evaluation, facilitating rapid development cycles.
Implications:
- Practical deployment: Semi-online RL enables scalable training of GUI agents without the infrastructure and cost overhead of online RL.
- Generalization: The approach bridges the gap between single-turn and multi-turn capabilities, critical for real-world automation.
- Evaluation: SOP sets a new standard for efficient, reliable offline evaluation of multi-turn agents.
Future directions include extending semi-online RL to more diverse environments, integrating richer forms of synthetic reasoning in patch modules, and exploring adaptive patch thresholds. Further, the paradigm may generalize to other domains where offline data is abundant but online interaction is costly or risky.
Conclusion
UI-S1-7B, trained with Semi-online RL, demonstrates that simulating online RL dynamics on static trajectories—augmented with adaptive patching and dual-level advantage optimization—enables efficient, robust, and generalizable GUI automation agents. The approach achieves state-of-the-art results among 7B models on multi-turn benchmarks, with strong alignment between offline evaluation and real-world performance. Semi-online RL represents a scalable, effective framework for advancing practical, high-performing GUI agents.