- The paper introduces a spatiotemporal autoregressive framework (STAR) that fuses memory and explicit geometric guidance for interactive 4D simulation.
- It presents a joint distribution matching distillation (JDMD) method to bridge synthetic–real domain gaps while ensuring robust motion control and visual fidelity.
- Experimental results demonstrate superior performance in dynamic benchmarks with precise camera trajectories and real-time inference speeds.
InSpatio-World: Real-Time 4D World Simulation via Spatiotemporal Autoregressive Modeling
Motivation, Challenges, and Context
The article "InSpatio-World: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling" (2604.07209) targets the critical challenge of constructing world models capable of real-time, high-fidelity, interactive exploration. Existing video generation paradigms based on diffusion or autoregressive strategies reveal marked deficiencies: spatial persistence degradation during long-range navigation, domain gaps between synthetic and real data distributions, and inability to precisely control camera trajectories in dynamic environments. These limitations restrict downstream applications such as embodied intelligence and simulation for autonomous driving.
The authors introduce a framework that unifies spatiotemporal autoregressive modeling with geometric and distributional constraints, enabling the transformation of monocular videos into interactive, controllable, and visually realistic 4D environments.
Figure 1: InSpatio-World enables real-time synthesis and roaming within dynamic scenes from a single video, with explicit spatial roaming, temporal control, and physical realism for downstream tasks.
Spatiotemporal Autoregressive Framework
The core architectural contribution is the Spatiotemporal Autoregressive (STAR) framework, which orchestrates consistent and controllable evolution of dynamic scenes via two coupled modules:
- Implicit Spatiotemporal Cache: Aggregates reference video frames and historical generations within a sliding window, providing both long-range global anchors and short-range memory for temporal stability.
- Explicit Spatial Constraint Module: Maps user interaction (camera pose instructions) to deterministic geometric guidance using depth-based warping and pose accumulation, enforcing persistent spatial structure during viewpoint transitions.
For each generation chunk, the STAR processes reference, historical, and geometric conditions through an integrated pipeline that injects all conditioning signals into a Diffusion Transformer. By adopting chunk-wise backpropagation and relative position encoding, the framework achieves full-link differentiability and numerical stability even for extended sequences.
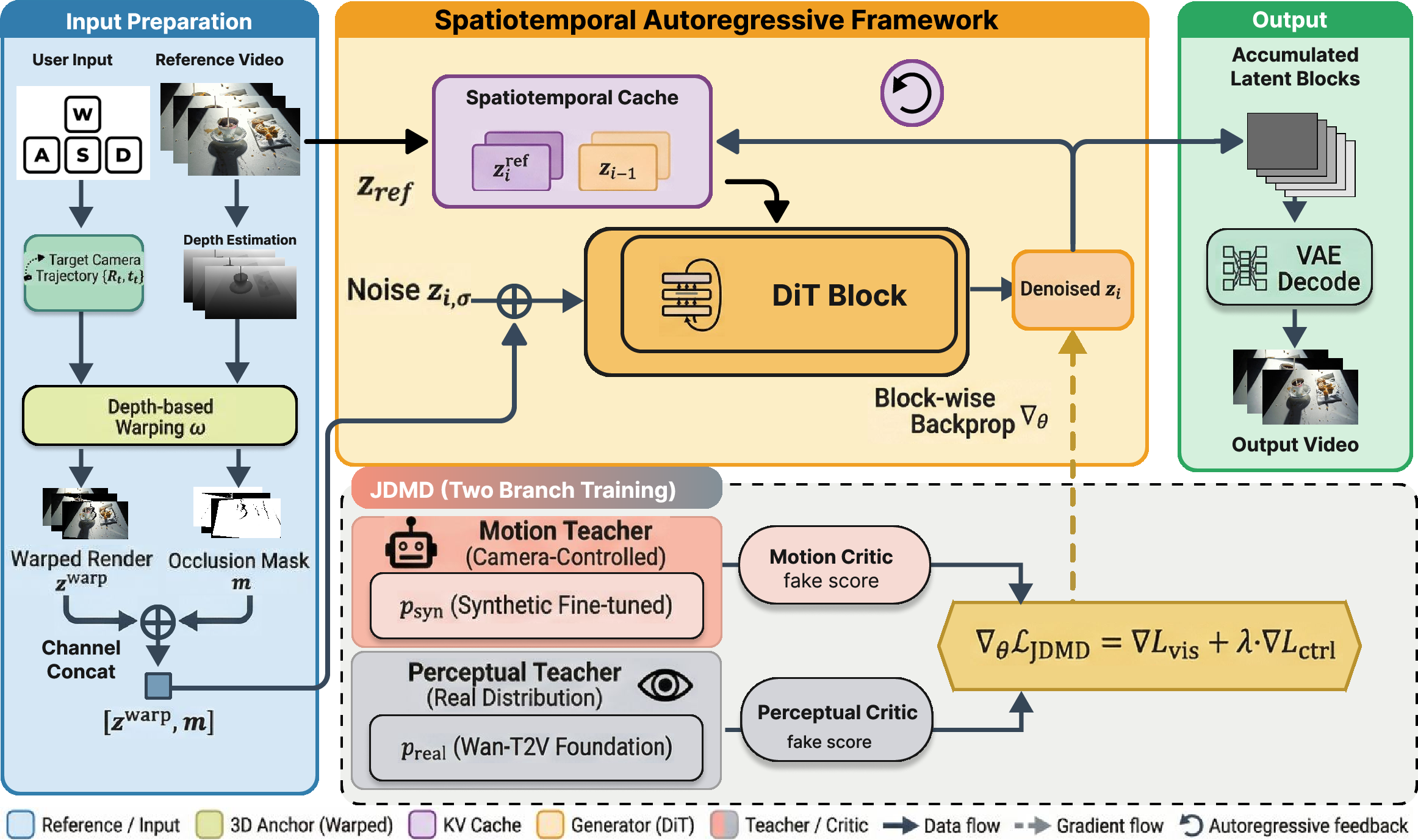
Figure 2: STAR and JDMD pipeline: Reference and historical information populate a spatiotemporal cache; explicit geometric warping translates user instructions to geometric constraints. JDMD employs dual-teacher distillation for perceptual and motion guidance.
Joint Distribution Matching Distillation (JDMD)
To counteract domain shifts induced by synthetic data, JDMD is introduced—a multi-task distillation mechanism employing distinct teacher models: one for motion/control (video-to-video from synthetic data), and one for perceptual fidelity (text-to-video from real data). Through weight sharing and alternate activation of distillation losses, the student model achieves high-precision control and alignment with real-world visual distributions, breaking the previous zero-sum trade-off between geometric accuracy and photometric quality.
This dual-teacher paradigm assures that motion conditioning dominates when controlling camera trajectories, while visual fidelity is calibrated against the real video distribution, enabling strict adherence to both spatial structure and realistic textures.
Experimental Evaluation
Evaluation is conducted across three tasks: WorldScore-Dynamic benchmark for interactive scene generation, long-term image-to-video synthesis (RE10K), and camera-controlled generative video rerendering (OpenVid/Blender datasets).
- WorldScore-Dynamic Benchmark: InSpatio-World achieves a score of 68.72 with significantly lower compute overhead than alternatives, demonstrating superior balance between geometric control and generation fidelity.
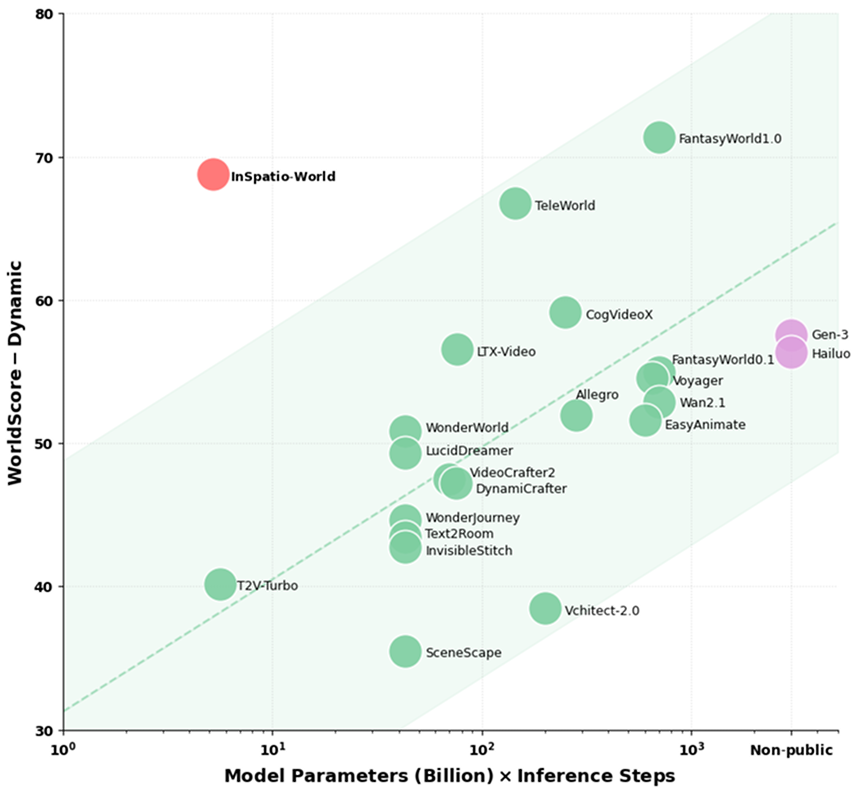
Figure 3: InSpatio-World attains a dynamic score of 68.72 on WorldScore-Dynamic with efficient compute utilization, surpassing other models.
- Long-term Image-to-Video Generation: The system attains FID 42.68 and FVD 100.55 on RE10K-Long, outperforming runners-up (e.g., LingBot-World) by substantial margins, particularly in camera trajectory precision (rotation error 2.8762 vs. 11.981).

Figure 4: Unlike baseline methods that suffer drift and warping, InSpatio-World sustains trajectory control and geometric consistency through long sequences.
- Camera Controlled Video Rerendering: On both OpenVid and Blender, InSpatio-World achieves best-in-class FID/FVD, visual quality (VBench metrics), and maintains near-perfect camera trajectory compliance. Structural and textural fidelity remain high even under complex camera instructions, outperforming TrajectoryCrafter, ReCamMaster, and NeoVerse.

Figure 5: Rerendering results highlight InSpatio-World’s superior structural and textural fidelity under camera control, closely matching ground truth trajectories.
Practical and Theoretical Implications
The framework advances high-precision, interactive video generation under real-time constraints. The dual anchoring strategy—implicit memory through ST-Cache and explicit geometric guidance—establishes robust spatial continuity and suppresses drift. The dual-teacher JDMD enables practical deployment scenarios by bridging synthetic-real domain gaps, suggesting generalizability in simulation, robotics, and agent-based synthetic datasets.
The 24 FPS real-time inference on H-series GPUs and competitive 10 FPS on consumer GPUs endorse its suitability for interactive downstream tasks. The explicit geometric memory proxy is a promising foundation for efficient semantic mapping and spatial comprehension in embodied AI.
Limitations and Future Directions
While spatial consistency and trajectory control are significantly improved, persistent memory for fine-grained textural details in dynamically generated regions and seamless omnidirectional view transitions in highly dynamic environments remain open challenges. The explicit geometric anchoring is currently optimized for static regions. Extension to semantic memory systems and incorporation of stronger physical priors in autoregressive modeling could enable closed-loop simulation at broader spatiotemporal scales.
Conclusion
The InSpatio-World framework constitutes an authoritative advancement in interactive 4D world simulation, combining spatiotemporal autoregressive modeling, explicit geometric constraints, and distribution-aligned distillation. Empirical benchmarks substantiate its claim of breaking the zero-sum trade-off between geometric control and photorealistic fidelity, setting new benchmarks for real-time, precise, and visually realistic navigation in generated worlds. The methodology lays foundational groundwork for future research into persistent semantic memory and physically guided generative modeling for autonomous systems and embodied intelligence.