- The paper introduces token-level temperature scaling as a computationally efficient method that significantly improves semantic calibration and discrimination in LM QA.
- It systematically evaluates a suite of semantic confidence measures and demonstrates up to 80% reduction in calibration error across diverse benchmarks.
- The study highlights TS's practical advantage by avoiding overfitting and ensuring robust uncertainty quantification compared to more complex techniques.
Improving Semantic Uncertainty Quantification in LLM QA via Token-Level Temperature Scaling
Introduction and Motivation
Semantic uncertainty quantification (UQ) for LMs underpins safe and reliable deployment in generative tasks such as question answering (QA). Traditionally, most evaluation in this domain has centered on discrimination—how well confidence measures separate correct from incorrect outputs—while neglecting calibration, i.e., the degree to which predicted confidences match true correctness probabilities. However, calibration and discrimination address orthogonal facets of reliability, and the systematic omission of calibration has left core aspects of semantic UQ for LMs underexplored.
The paper "Improving Semantic Uncertainty Quantification in LLM Question-Answering via Token-Level Temperature Scaling" (2604.07172) comprehensively addresses this gap, providing the first large-scale evaluation of both semantic calibration and discrimination across a broad family of semantic confidence (SC) measures, and analyzing how various token-level calibration techniques propagate to semantic prediction space. The central claim is that optimised, global temperature scaling (TS) is a computationally light yet exceptionally powerful tool for improving not only token-level calibration but also the quality and reliability of semantic-level uncertainty estimates in modern LMs.
Semantic Confidence Measures: Novel Taxonomy and Evaluation
The authors introduce and formalize a spectrum of SC measures built atop clustered generative outputs, leveraging natural language inference (NLI) for semantic grouping. In addition to two prior measures—empirical semantic confidence (E-SC) and likelihood-based semantic confidence (L-SC)—they propose five new metrics (ML-SC, IC-SC, B-SC, T-SC, G-SC) to span diverse priors and likelihood weighting schemes. This systematic diversity in SC metrics serves not only to disentangle the effect of calibration on final UQ properties but also to expose latent redundancy and diversity among measures.
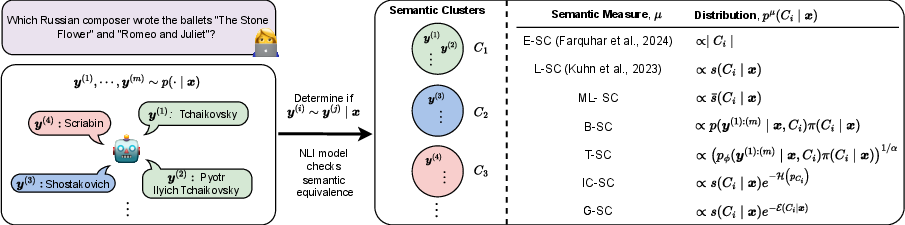
Figure 1: Schematic depiction of how diverse semantic confidence measures are constructed from clustered model generations and token-level statistics.
Empirical findings indicate that while these SC measures often exhibit high mutual correlation under default (or heuristic) temperature settings, this alignment breaks down under optimised temperature scaling, revealing their distinct operational regimes (see Figure 2). This underscores the necessity of evaluating and calibrating a wide set of SC measures rather than relying on a single proxy.
Calibration Techniques for Semantic UQ
The analysis spans a matrix of calibration methods: uncalibrated base models, fixed-temperature heuristics (as advocated by prior black-box UQ work), adaptive temperature scaling (ATS), Platt scaling, and global token-level TS. The comparative study highlights the inefficacy and systematic semantic miscalibration of both default and fixed-temperature heuristics, but—critically—demonstrates that optimised TS consistently pushes semantic calibration error lower and improves discrimination (AUROC) across all datasets and LMs studied.
Notably, while more expressive methods like ATS and Platt scaling achieve lower token-level negative log likelihood (NLL) on held-out calibration sets, they tend to overfit semantically unimportant tokens (e.g., filler words), leading to degradation in sequence-level semantic calibration and discrimination. The single global temperature of TS, in contrast, provides an Occam’s-razor inductive bias, regularizing semantic UQ without sacrificing sequence-level expressivity.
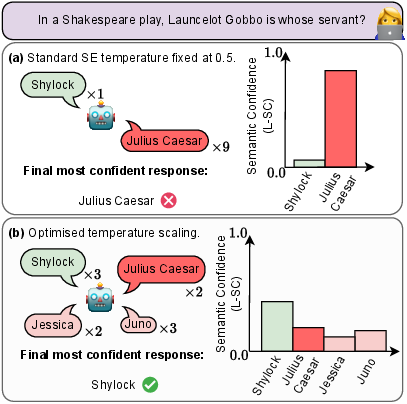
Figure 3: Example demonstrating how optimising the temperature parameter sharpens semantic confidence distributions and better aligns them with semantic correctness.
Empirical Evaluation: QA Benchmarks and Major Results
The empirical protocol leverages state-of-the-art open models (Llama-3, Mistral-8B, Qwen-2.5) on widely used short-form QA datasets (TriviaQA, Natural Questions, SQuAD), with robust calibration-validation-test splits and multiple independent runs per configuration. Key performance metrics include adaptive calibration error (ACE), area under the ROC curve (AUROC) for discrimination, Brier scores, and curves for selective prediction.
Major numerical findings include:
- Across all models and benchmarks, TS reduces semantic calibration error by up to 80% and substantially increases AUROC relative to both base and fixed-temperature baselines (see Figure 4).
- TS outperforms ATS and Platt scaling, even though these achieve lower training NLL at the token level, indicating superior generalization to semantic prediction tasks.
- Selective prediction accuracy (retaining only high-confidence answers) is steepest—i.e., yields greatest error filtering—for TS across SC measures and datasets (Figure 5), emphasizing its value in risk-controllable LLM deployment.
- Calibration gains saturate as the number of generated samples per input increases (Figure 6), with robust performance even at modest sample counts (10–15 per prompt).
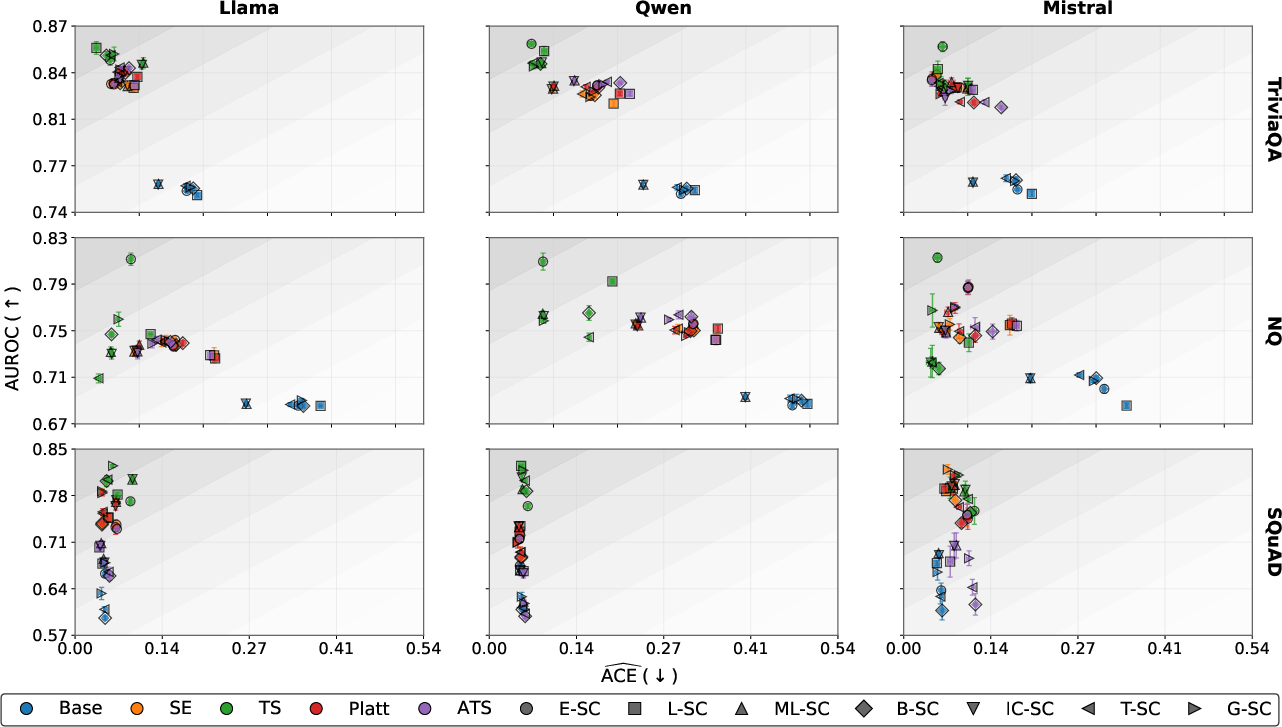
Figure 4: Calibration–discrimination scatter showing mean ACE (↓) and AUROC (↑) for SC measures and calibration techniques.
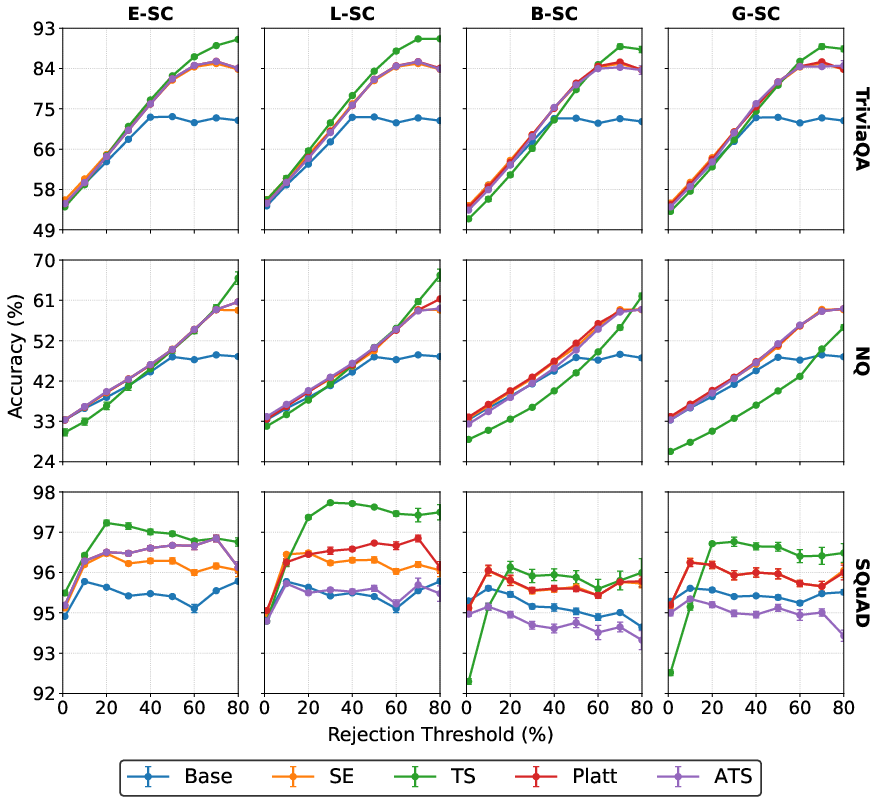
Figure 5: Selective accuracy curves for Qwen show sharper accuracy improvement at low coverage under temperature scaling.
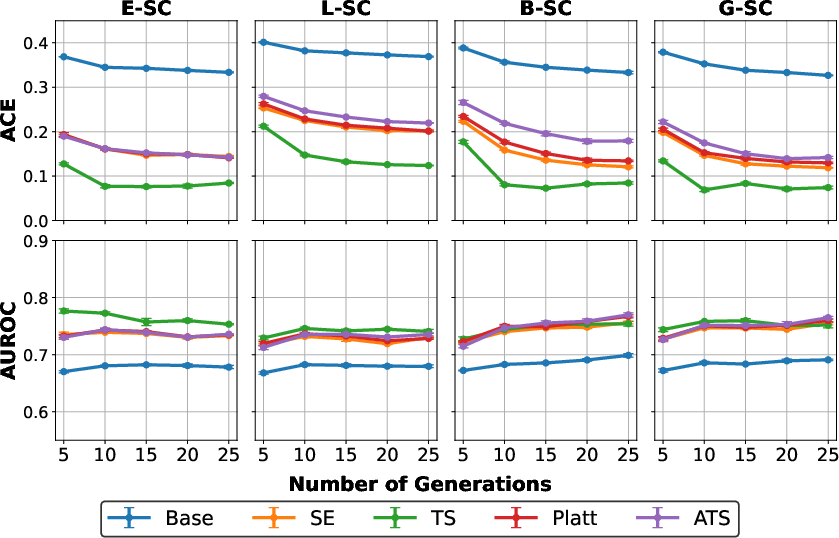
Figure 6: Effect of sample count on semantic calibration and discrimination outcomes for Llama.
Additional experiments demonstrate that TS not only reduces mean calibration error but also increases the diversity of operational SC measures (as per correlation matrices in Figure 2), confirming that fixed-temperature approaches mask structure that becomes actionable post-calibration.
Theoretical and Practical Implications
The paper’s results have several theoretical and practical implications:
- Calibration and Discrimination Independence: The findings validate the necessity of joint evaluation. Strong discrimination (AUROC) does not guarantee, nor is guaranteed by, calibration (ACE/Brier)—mirroring known issues from classification.
- Inductive Bias in Calibration: TS's constraint to global sequence-level adjustment makes it resistant to overfitting spurious token-level patterns, and ensures that semantic UQ improvements are robust and generalizable. More complex calibrators, while more expressive, tend to capture dataset or sampling artifacts with negative consequences for semantic reliability.
- Plug-and-Play Methodology: TS is computationally minimal and can be implemented as a single scalar parameter post-hoc, requiring no model modification or expensive per-token optimization. The authors argue this practical efficiency makes it well-suited for real-world deployment, especially with LLMs that already require task- and domain-specific adaptation for optimal operation.
- Semantic Calibration Beyond QA: While the focus is on short-form QA, the need to extend these techniques to tasks with more ambiguous semantic correctness (e.g., summarization, open-form generation) is noted, and new evaluation frameworks are needed.
Limitations and Future Directions
The principal limitation of the present evaluation is the focus on well-defined generative QA, where semantic correctness admits a crisp, binary categorization. Extending semantic calibration and evaluation metrics to more complex NLG tasks with inherently partial or multi-faceted correctness remains an open research area. Similarly, the clustering quality relies on high-fidelity NLI, and extending both clustering and correctness evaluation to long-form or multi-entity outputs will likely require novel models or additional human-in-the-loop validation.
Conclusion
This work demonstrates, through rigorous empirical and methodological evaluation, that optimising a single, global temperature parameter at the token level yields consistent and substantial improvement in both the calibration and discrimination of semantic uncertainty estimates for LMs in QA. These gains persist across metrics, models, and a rich family of semantic confidence measures—often eclipsing those achievable with far more complex and computationally demanding token-level recalibrators.
The results provide both a new baseline and a strong practical recommendation: post-hoc token-level temperature scaling should be standard practice for semantic UQ in generative LMs. More broadly, the findings motivate a shift toward comprehensive, joint evaluation protocols for UQ that distinguish between calibration and discrimination, and further research into extending semantic calibration to diverse NLG domains.
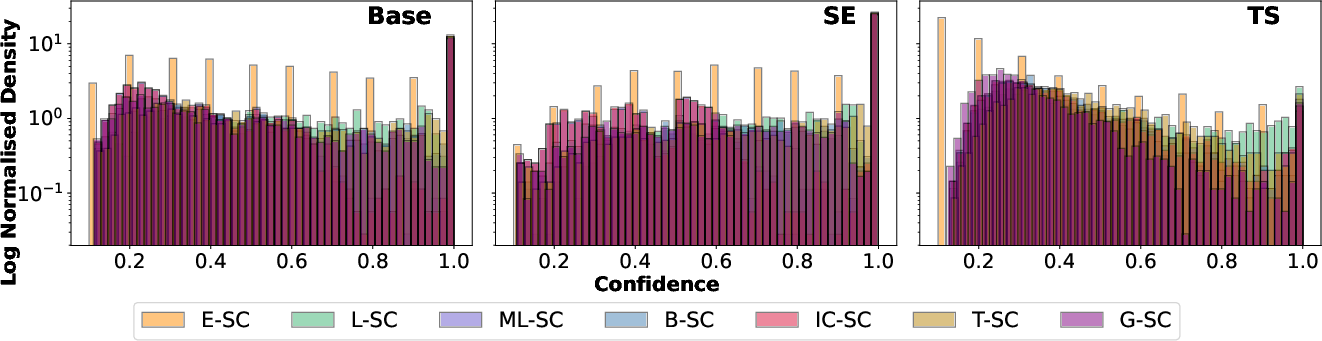
Figure 7: Distributions of semantic confidence measures across calibration methods, illustrating the reduction in overconfidence and better class separation after temperature scaling.
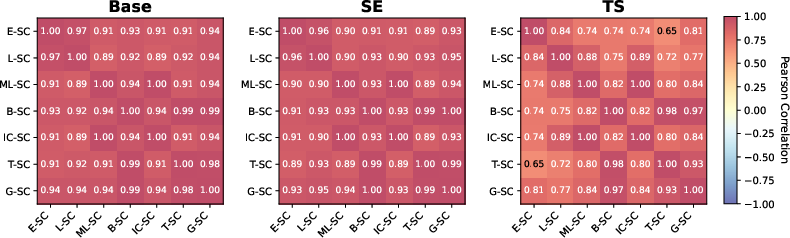
Figure 2: Pairwise Pearson correlations between SC measures show that optimised temperature scaling increases measure diversity, reducing redundancy and exposing complementary uncertainty signals.