- The paper introduces a flow matching approach that models multi-modal trajectory distributions, enabling efficient best-of-N sampling while reducing planning time.
- It employs a transformer-based architecture to fuse point cloud and configuration data, and utilizes a compact MLP flow head for rapid trajectory generation.
- Empirical results show up to 86.7% success in real-world tasks, outperforming traditional planners with lower computational overhead and improved robustness.
Flow Motion Policy: Stochastic Generative Motion Planning with Flow Matching Models
Introduction
The "Flow Motion Policy" (FMP) (2604.07084) proposes a novel, open-loop end-to-end neural architecture for robotic manipulator motion planning, utilizing flow matching as a generative mechanism for path synthesis. Emerging from limitations in deterministic neural planners and the computational bottlenecks of classical sampling-based planners reliant on privileged collision checking, FMP aims to model the inherent multi-modality of feasible path distributions and to enable efficient inference-time optimization via best-of-N sampling. This technical summary unpacks the methodology, architecture, and empirical evaluations that substantiate the proposed framework, situating FMP in the context of neural motion planning research.
Architectural Overview
FMP integrates the flow matching paradigm within a transformer-based neural policy, mapping raw planning observations (point clouds and robot configurations) to action trajectories in high-dimensional configuration spaces. The primary design elements are:
- Parallelized Point Cloud Processing: PointNet++ encoders extract embeddings from both the manipulator and workspace point clouds, capturing spatial relationships crucial for collision avoidance.
- Configuration Embeddings: Joint positions at the current and goal time steps are mapped by MLPs into a shared latent space.
- Transformer Fusion: Embeddings from all modalities are aggregated via a transformer encoder, facilitating rich, cross-modal reasoning.
- MLP Flow Head: A compact MLP models the continuous-time vector field required for flow matching, allowing for efficient integration during inference.
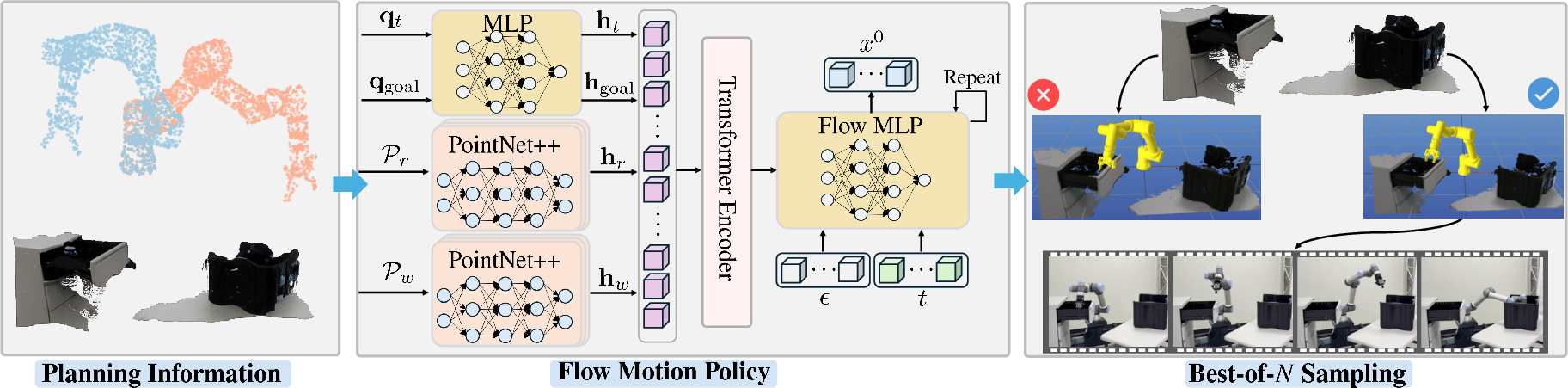
Figure 1: Architecture of FMP, showing parallel point cloud, configuration processing, transformer aggregation, and stochastic flow-based trajectory sampling.
The flow matching process constructs a continuous normalizing flow between a noise distribution and the empirical trajectory data, regressing the model toward the optimal transport. At inference, trajectories are sampled by integrating the learned vector field from noise, and best-of-N sampling is used to select collision-free plans efficiently.
Best-of-N Sampling and Inference-time Optimization
A critical innovation is the operationalization of best-of-N sampling. FMP generates multiple candidate trajectories in a single inference batch and performs post-hoc collision checking on the resulting paths. Since FMP's generative process is open-loop and decoupled from collision checking during rollouts, it enables parallel, lightweight optimization impossible in classical planners.
Compared to GMM-based approaches (Neural MP) and diffusion-based policies, FMP offers a better trade-off:
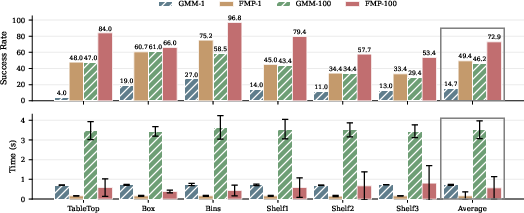
Figure 2: Comparison of planning success rates and planning times between FMP and Neural MP with and without inference-time optimization, highlighting FMP's superior efficiency and utilization of best-of-N sampling.
Empirical Evaluation
Extensive experiments benchmark FMP against classical sampling-based planners (Bi-RRT, BIT*), various learning-based samplers (MPNets, SIMPNet, GAIDE), and other end-to-end neural planners (PerFACT, Neural MP). Key findings include:
- Success Rate and Efficiency: With best-of-N (e.g., N=100), FMP matches or exceeds the planning success of sampling-based baselines while reducing planning time by an order of magnitude.
- Model Compactness: FMP achieves competitive or stronger performance than large neural motion planners (e.g., Neural MP with 20M parameters) with only 1.4M parameters.
- Effectiveness of Stochasticity: Deterministic neural planners suffer from reduced generalization in challenging environments; FMP's stochastic sampling boosts robustness across varied scenarios.
Policy Head Ablations and Generative Framework Comparisons
Ablative studies assess the impact of policy head architecture. FMP's simple MLP flow head offers the highest efficiency, surpassing more complex U-Net/Transformer/DiT heads in planning time, with marginal differences in success rate.
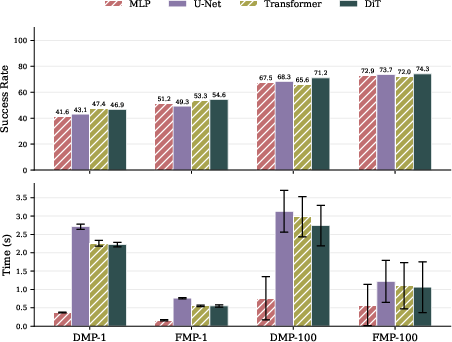
Figure 3: Planning success rate and planning time across various policy heads for FMP and diffusion-based policies, demonstrating MLP-based FMP's efficient performance.
Moreover, comparisons with diffusion-based policies indicate that flow matching provides comparable or superior expressiveness with reduced computational cost, as diffusion models incur significant overhead from iterative denoising.
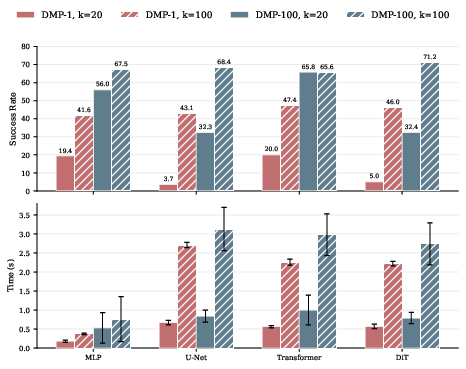
Figure 4: Impact of diffusion timesteps (k) on planning performance, showing planning time increasing rapidly with more timesteps with diminishing gains in success rate.
Hyperparameter and Inference-time Ablations
Studies on the number of sampled trajectories (N) and flow integration steps elucidate the compute-accuracy tradeoffs in inference-time optimization:
- Increasing N progressively improves success rates, but with diminishing returns and linear growth in planning time.
- Additional Flow Steps beyond a certain threshold fail to yield substantive improvements in path quality, suggesting the architectural design is not the limiting factor.
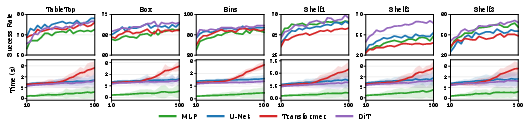
Figure 5: Success rate and planning time for diffusion-based policies as a function of number of sampled trajectories N, demonstrating the compute-scaling trend.
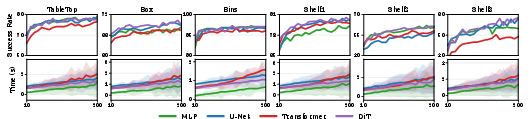
Figure 6: Success rate and planning time for FMP under varying N, confirming efficiency advantages relative to diffusion methods.
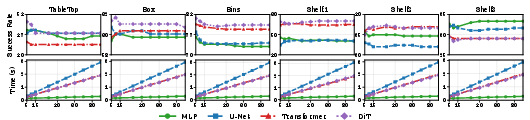
Figure 7: Effect of increasing Euler integration steps during FMP inference (N=1), illustrating minor gains in success.
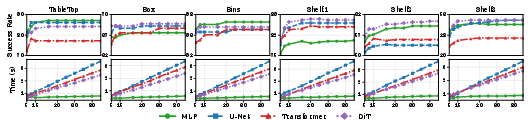
Figure 8: Effect of increasing Euler integration steps with best-of-N sampling (N=100), further validating the efficiency-robustness tradeoff.
Robotic Deployment and Real-World Evaluation
FMP was deployed on UR5e hardware, using a calibrated RealSense D435i to obtain workspace point clouds. Across 30 real-world planning tasks (bins, articulated, shelves), best-of-N0 sampling increased success from 33.4% (N=1) to 86.7% (N=100), demonstrating sample diversity and robustness benefits in non-ideal conditions.

Figure 9: Real-world data acquisition setup with UR5e and RGB-D workspace sensing.

Figure 10: Example executions in various real-world environments by FMP, visualizing planned and executed manipulator trajectories.
Theoretical and Practical Implications
FMP advances the expressive capacity of end-to-end neural motion planners by enabling genuine multi-modality in feasible trajectory synthesis through flow matching. The separation of collision checking from path synthesis allows unprecedented inference-time flexibility: large-scale best-of-N1 parallelism is tractable, and lightweight models mitigate deployment cost. This diverges from prior neural planners that either cannot exploit stochasticity or suffer from over-parameterization and slow denoising.
Practically, FMP offers deployment advantages in time-critical or resource-constrained robotic scenarios where rapid planning is essential. Theoretically, the success of flow matching as a generative backbone for configuration space trajectory modeling suggests new avenues for integration with reactive controllers and policy compositionality, as well as incorporation of temporal consistency and dynamic environment adaptation.
Future Directions
Several aspects remain open for extension:
- Dynamic Environments: Integration with reactive frameworks (e.g., Riemannian Motion Policies, Geometric Fabrics) may bridge the gap between open-loop planning and dynamic obstacle navigation.
- Joint Optimality/Post-processing: FMP's open-loop paths could be further refined with post hoc smoothness or local optimization modules, extending practical performance for execution-critical deployments.
- Generalist Policy Scaling: Leveraging FMP's efficiency, scaling up with larger/heterogeneous datasets or multi-robot/multi-manipulator setups presents a promising trajectory for robust generalist planners.
Conclusion
Flow Motion Policy exemplifies a technically rigorous advance in neural motion planning, demonstrating that continuous normalizing flow and flow matching techniques can efficiently and expressively model the complex, multi-modal landscapes of manipulator motion planning. Its practical and theoretical implications suggest significant future impact in scalable, robust, and deployable robot learning systems.