- The paper introduces a multi-agent simulation framework that uses trait-conditioned LLMs for iterative legal argumentation.
- It employs deep neural models and reinforcement learning to optimize rhetorical traits and achieve higher win rates in adversarial settings.
- Empirical analysis shows that diverse team configurations and RL-driven trait orchestration significantly boost argument stability and performance.
Strategic Persuasion in Trait-Conditioned Multi-Agent LLM Legal Argumentation
Framework Overview
The paper "Strategic Persuasion with Trait-Conditioned Multi-Agent Systems for Iterative Legal Argumentation" (2604.07028) introduces the Strategic Courtroom Framework, a comprehensive multi-agent simulation environment designed for adversarial legal discourse mediated entirely through LLM-generated natural language. The system operationalizes prosecution and defense as teams or single agents, each instantiated with explicit, interpretable rhetorical or strategic traits, engaging in structured, iterative legal argumentation over synthetic cases. The architecture leverages both large-scale neural models (DeepSeek-R1, Gemini-2.5-Pro) and reinforcement learning for the meta-optimization of persona composition, positioning language itself as the fundamental strategic action space.
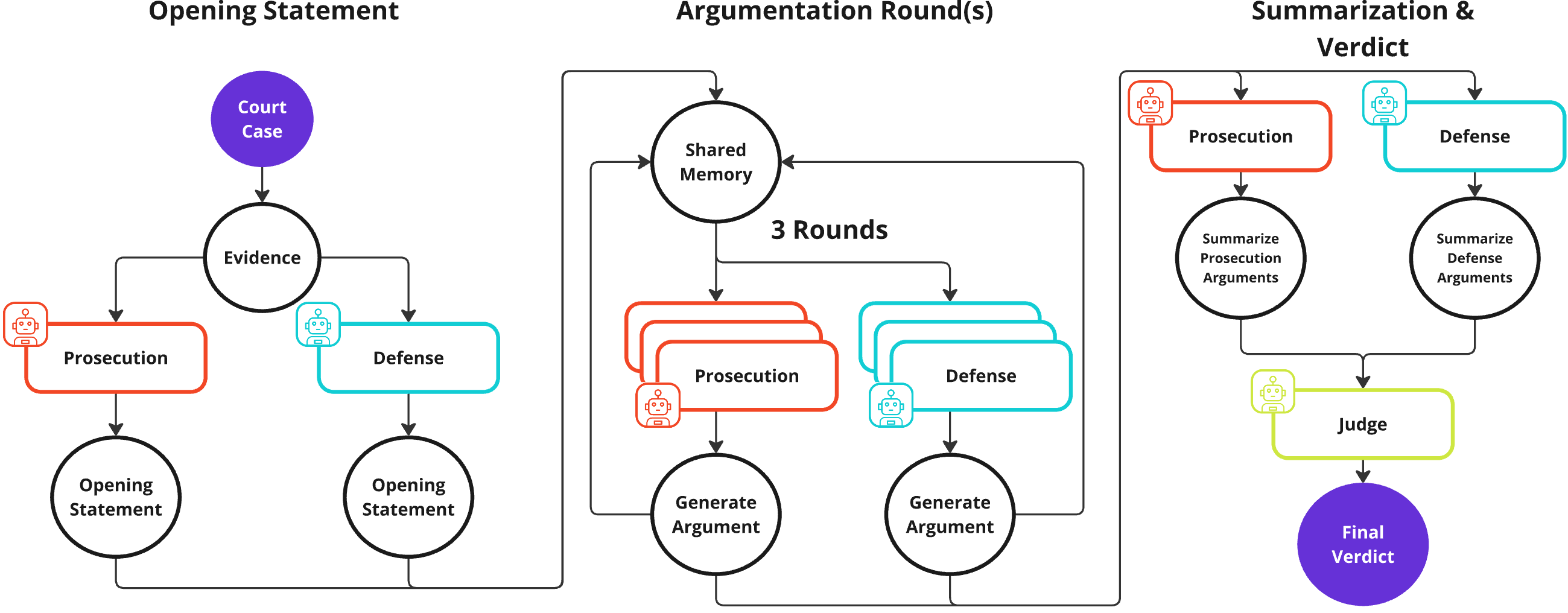
Figure 1: Overview of the Strategic Courtroom Framework. Prosecution and defense teams generate opening statements, engage in multi-round argumentation with shared memory, summarize positions, and a judge produces a final verdict.
Trait Taxonomy and Agent Architecture
Central to the framework is a principled trait taxonomy comprising nine traits mapped to four archetypes—Rhetoricians, Technicians, Gladiators, and Diplomats—derived from Aristotelian rhetorical principles but implemented via trait-conditioned prompting. Each agent’s system prompt explicitly encodes its assigned trait bundle, shaping rhetorical stance, strategy, tone, and argument structure.
The combinatorial space is systematically explored with teams of size n=3, yielding 84 unique trait configurations, supporting robust evaluation of interactions among diverse persuasive strategies. The trait-based conditioning provides a granular mechanism to empirically dissect the effectiveness of not only individual rhetorical strategies but also their complementarities in both team and adversarial contexts. All agents, including judges, are instantiated from the same model backend within an experimental condition to isolate behavioral effects.
Trait Importance and Specialization
Empirical evaluation spans 10 synthetic but plausible legal cases, with teams sampled from all trait permutations. Elo ratings serve as the principal metric, updated on a per-trial basis and weighted by judge confidence. The normalized importance analysis across three SoTA models (DeepSeek-R1, Gemini-2.5-Pro, GPT-5) consistently highlights quantitative and charismatic traits as disproportionately contributing to winning argumentative configurations.
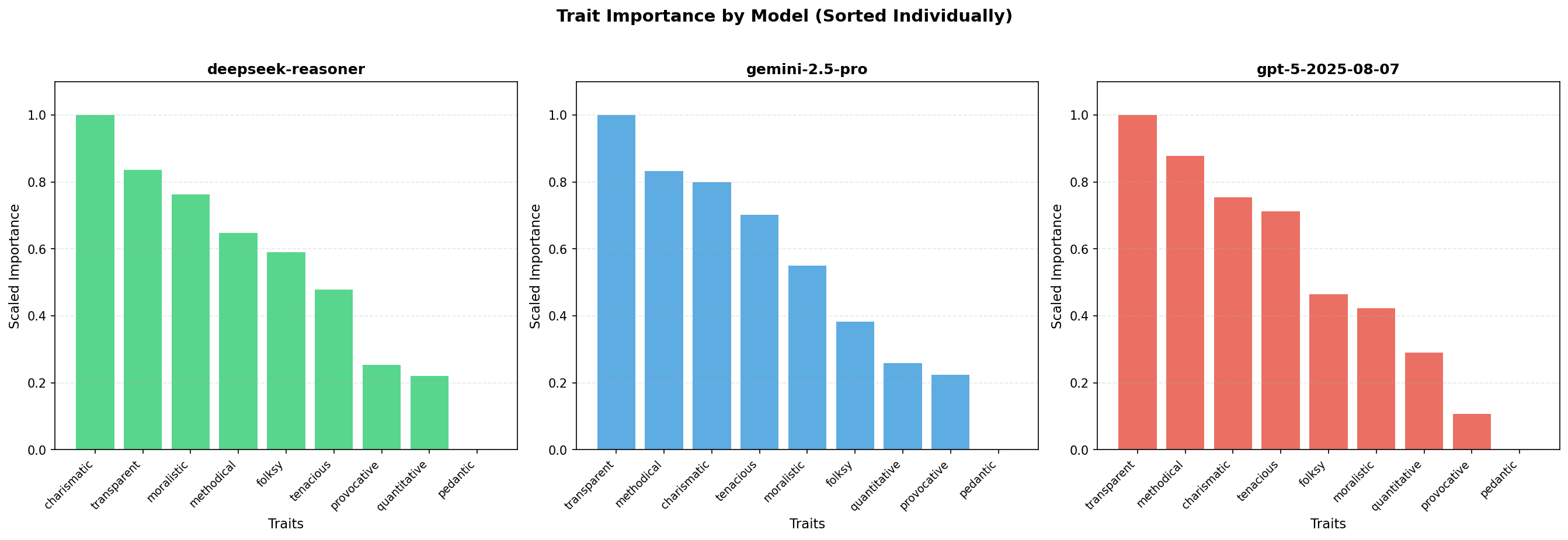
Figure 2: Normalized trait-importance scores derived from model-based rankings of three-trait combinations across DeepSeek-R1, Gemini-2.5-Pro, and GPT-5. Higher values indicate traits more frequently ranked as most important within winning configurations.
Quantitative agents drive performance through rigorous logical exposition and data-backed arguments, while charismatic agents inject credibility and emotional salience. Diplomat traits like transparent and methodical exhibit strong synergy effects, particularly when deployed in composite teams.
Team Diversity and Argument Depth
Heterogeneous teams—those in which agents are assigned complementary, non-overlapping traits—consistently achieve higher average Elo and win rates than homogeneous teams or single-trait agents. This supports the hypothesis that team diversity systematically expands strategic coverage, mitigates failure modes associated with trait over-specialization, and enables adaptive response to varying judge preferences and opposing strategies.
Optimal argumentation depth is found empirically; three-round iterative protocols yield a marked decrease in verdict reversal rates and increased stability without significant repetition or degeneration in argumentative quality. Overly deep interactions confer diminishing returns and increased verbosity, a notable constraint for practical multi-agent deployments.
RL-Optimized Trait Orchestration
The framework incorporates a RL-based Trait Orchestrator, fine-tuned via LoRA on a Qwen2.5-1.5B-Instruct backbone, trained to maximize defense win rate and judge confidence by generating defense team traits conditioned on both the case and opposing prosecution team. This orchestrator is evaluated head-to-head against exhaustive search and static human-designed baselines.
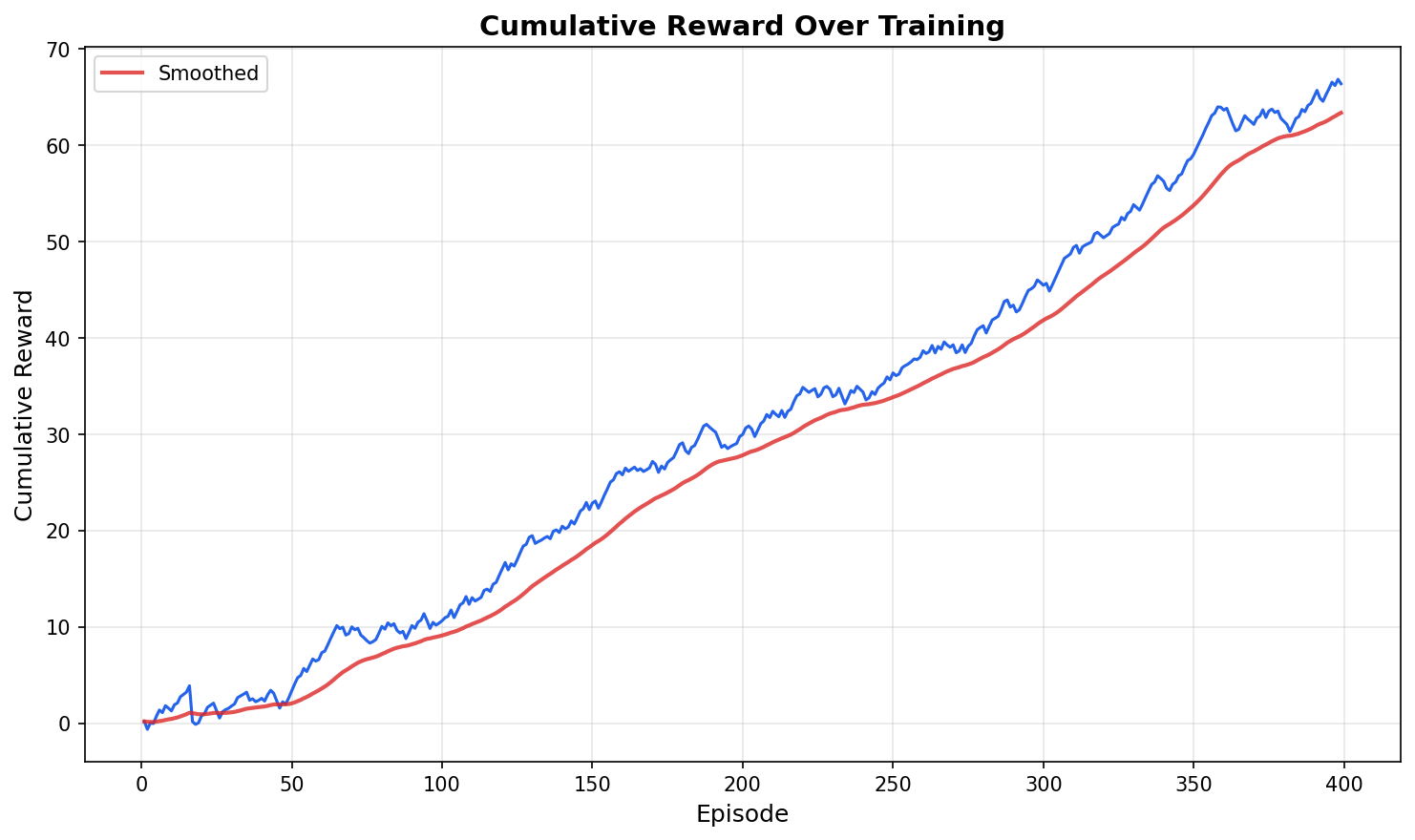
Figure 3: Cumulative reward of the RL-based Trait Orchestrator during training, showing convergence toward stable positive returns as trait generation improves.
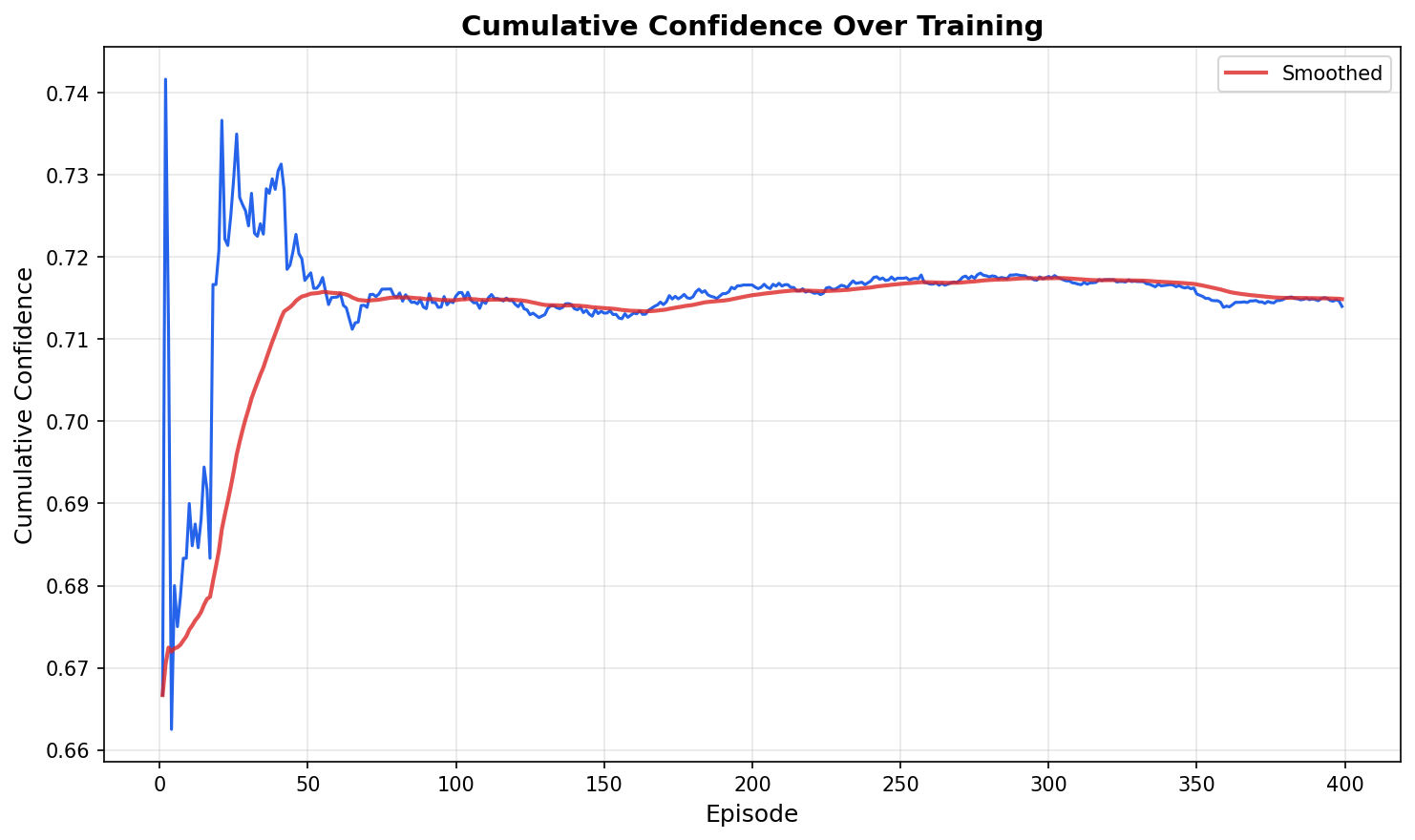
Figure 4: Cumulative judge confidence over training episodes for the RL-based Trait Orchestrator, illustrating increasing certainty in favorable defense outcomes.
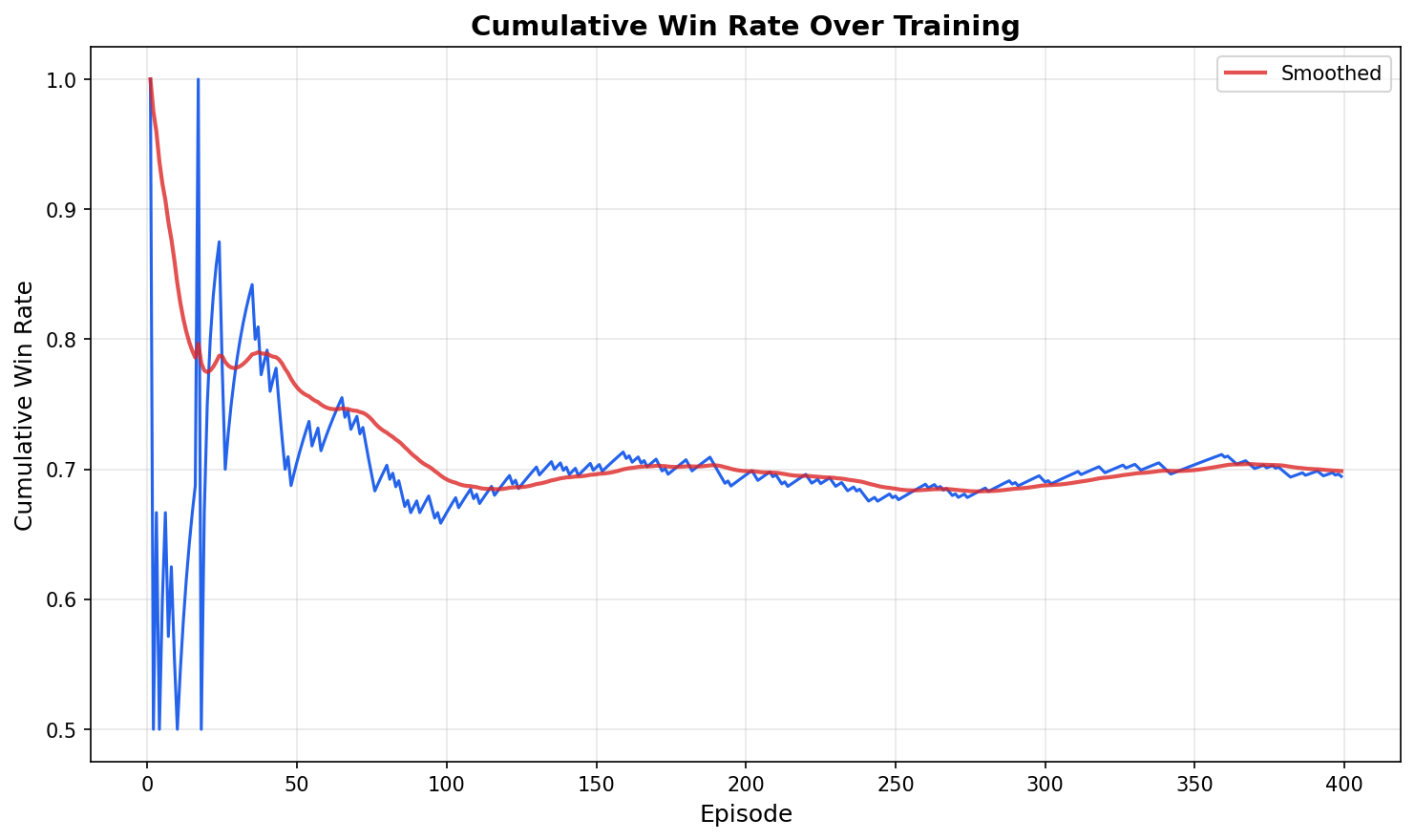
Figure 5: Cumulative defense win rate over training episodes for the RL-based Trait Orchestrator, demonstrating learning progress compared to early random performance.
RL orchestration achieves a superior average defense Elo and win rate (41.1%) relative to the best static two-trait or three-trait static baselines, and frequently discovers trait combinations and semantic hybrids not present in the original taxonomy. Failure modes include trait collapse and superficiality, which are partially mitigated via diversity regularization.
Theoretical Implications
The results sharply demonstrate that natural language can be productively formalized as a high-dimensional strategic action space in sequential games with uncertainty—analogous to, but more expressive than, atomistic symbolic action spaces in classical game theory and argumentation. Persona-conditioned LLM agents emerge as a powerful substrate for studying both micro-level rhetorical tactics and macro-level team dynamics in adversarial settings. The ability of RL-trained systems to meta-optimize over high-level rhetorical policy classes (i.e., trait sets), rather than token-level utterances, provides a scalable path for learned strategic heterogeneity and context-conditioned adaptability.
Moreover, the increased stability and performance of trait-diverse, multi-round systems affirms core tenets of cooperative game theory—coverage, adaptability, and complementarity—when instantiated in LLM-mediated discourse.
Limitations and Extensions
Several limitations are acknowledged. All cases are synthetic and manually vetted; real-world external validity remains an open question. Judges are LLMs with minimal prompt-level conditioning (fair, ethical), raising concerns over systematic linguistic biases and potential overalignment. Extension to multi-judge (jury) panels and integration with human-in-the-loop evaluation remain natural next steps. The current trait set is static per trial; enabling adaptive intra-trial trait switching or dynamic strategic folding is a promising direction for future research. Human evaluation of generated argument artifacts and cross-model judge analysis should further strengthen claims of generality and validity.
Broader Applications and Future Directions
The Strategic Courtroom Framework generalizes beyond law to any domain where adversarial or high-stakes discourse is central: international negotiation, corporate bargaining, educational debate, and collective decision-making are all within scope. The empirical finding that learned, dynamically adaptive persona composition can outperform static, human-designed archetypes paves the way for autonomous, self-improving agents capable of persuasive reasoning, negotiation, and argumentation in complex multi-agent environments.
As LLM capabilities in reasoning and long-horizon planning continue to advance, treating language as a formal action space will increasingly allow simulation, analysis, and automation of nuanced strategic communication.
Conclusion
The paper advances the study of discourse-mediated strategic interaction by providing a principled framework for adversarial, trait-conditioned, multi-agent LLM argumentation, validated across thousands of simulated trials. It demonstrates—quantitatively and qualitatively—that orchestrating agent-level heterogeneity, optimal argumentation depth, and RL-driven trait policy selection yields consistent gains in adversarial settings. This work contributes both a methodological platform and a set of empirical findings supporting language as a first-class strategic substrate in multi-agent systems, recommending future research on learned persona adaptation, evaluation protocols, and deployment in broader strategic domains (2604.07028).