- The paper introduces the UI-in-the-Loop paradigm that decouples UI element analysis from action prediction to enhance model interpretability.
- It presents a modular framework with augmented datasets and Group Relative Policy Optimization to improve UI element localization and semantic alignment.
- Empirical results show UILoop-trained models outperform traditional screen-to-action approaches, achieving significant gains in UI comprehension and overall GUI performance.
UI-in-the-Loop: A Paradigm Shift for Multimodal GUI Reasoning
Motivation and Limitations of Screen-to-Action Paradigm
The paper introduces a critical examination of the prevailing "Screen-to-Action" paradigm in multimodal GUI reasoning, highlighting substantial deficiencies in model interpretability and UI element comprehension. Empirical evaluation reveals that state-of-the-art MLLMs and GUI agents exhibit suboptimal performance in explicit localization, semantic description, and practical usage of UI elements—with average scores consistently below 0.1 across these facets. This deficit directly impairs GUI task completion, demonstrating that correct UI element understanding is necessary for robust interactive agents, while misleading information exacerbates failure rates.
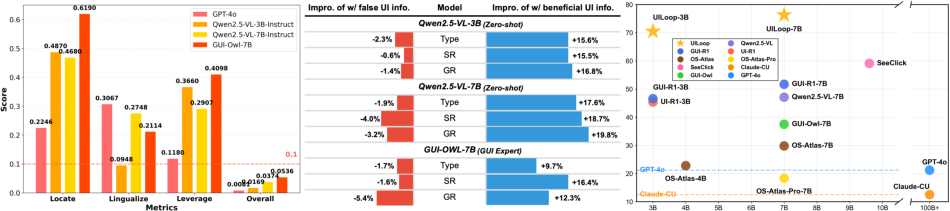
Figure 1: Comparative evaluation of UI element localization, semantic function description, practical usage, and relative performance gains with correct/misleading UI info; UILoop outperforms existing Screen-to-Action methods on Android Control-High.
Conceptualization: UI-in-the-Loop (UILoop) Paradigm
To address these entrenched limitations, the UI-in-the-Loop (UILoop) paradigm is proposed, reframing GUI reasoning as a cyclic "Screen–UI Elements–Action" process, in contrast with the opaque "Screen-to-Action" pipeline. UILoop formalizes explicit mastery of UI elements as a prerequisite for action decision. By decoupling UI element analysis from action prediction, the paradigm enhances model interpretability, enabling reasoning traceability through intermediate representations and facilitating intrinsic learning of interface layout, semantics, and actionable affordances.

Figure 2: Schematic contrast between "Screen-to-Action" and the proposed "Screen-UI Elements-Action" paradigm.
Framework Design: Benchmark and Reinforcement Fine-Tuning
UILoop is realized via a modular framework encompassing data augmentation, benchmark construction, and reinforcement fine-tuning.
UI Comprehension-Bench Construction
Existing datasets under-annotate fine-grained UI information. UI Comprehension-Bench is constructed through augmentation—annotating screens with OmniParser V2 for UI element coordinates, selection via GPT-4o for functional relevance, followed by human curation. This dataset comprises 26,207 samples, with comprehensive metadata for (instruction, screen, key UI elements, action), enabling three dedicated evaluation metrics: Locate (coordinate accuracy), Lingualize (semantic alignment), and Leverage (utilization correctness).
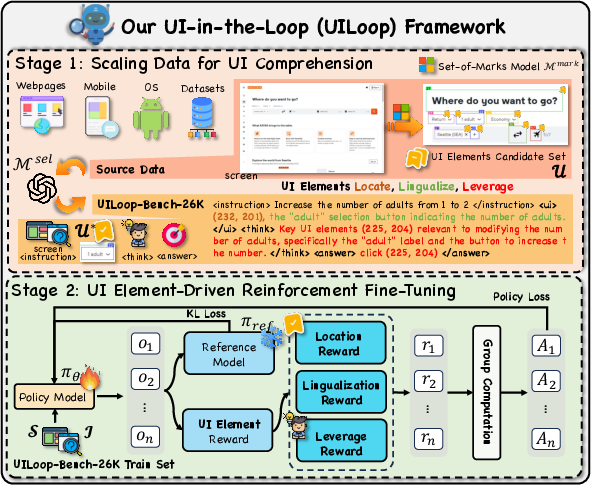
Figure 3: Overview of the UI-in-the-Loop (UILoop) framework, illustrating both data synthesis and RL-based fine-tuning.
Data Analysis
The benchmark includes 1,576,068 UI elements with less than 4% marked as ground truth keys. Identification is challenging, with over a quarter of samples containing only a single GT element among distractors. Coverage rates for UI reasoning exceed 90% for most actions, confirming the logical coherence of key elements.
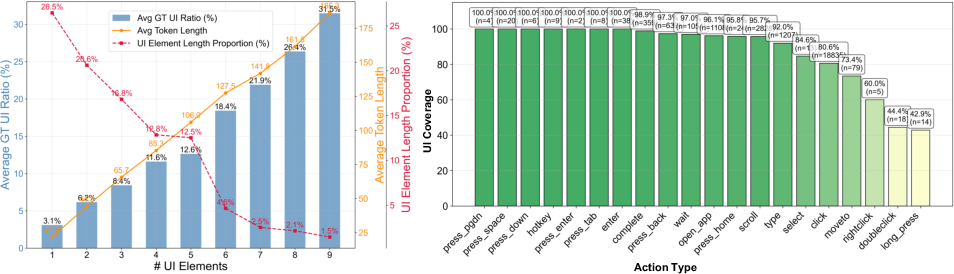
Figure 4: UI Comprehension-Bench statistics: GT UI element distribution and semantic description token lengths; effective usage of GT elements in action inference.
UI Element-Driven Reinforcement Fine-Tuning
UILoop employs Group Relative Policy Optimization (GRPO) RL, integrating specialized rewards:
- Format Reward: Enforces structured output for transparency.
- Location Reward: Quantifies spatial accuracy vs. GT coordinates.
- Lingualization Reward: Measures semantic similarity between predicted and GT descriptions.
- Leverage Reward: Assesses correctness of actionable usage.
These components are hierarchically composed to prioritize locating and semantically understanding key UI elements before learning their functional actuation.
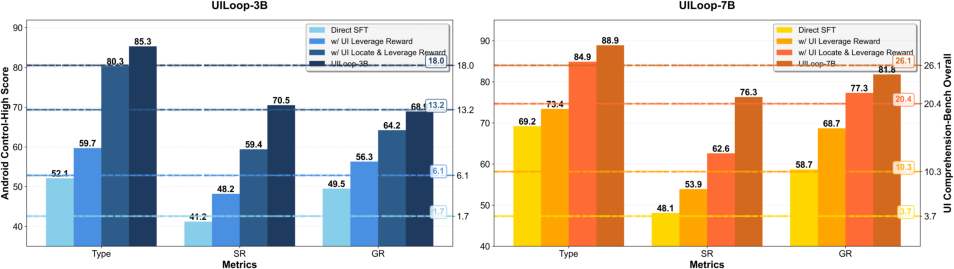
Empirical Results: UI Comprehension and GUI Reasoning
Extensive experiments on ScreenSpot-Pro and Android Control-High benchmarks establish the superiority of UILoop-trained models. UILoop outperforms baselines—including zero-shot and SFT/RFT "Screen-to-Action" MLLMs—by substantial margins. Notably:
Ablation and Case Analysis
Ablation demonstrates the necessity of all reward components—Leverage alone improves metrics, Locate Reward augments GR, and Lingualize Reward enhances SR. Case studies reveal UILoop's explicit reasoning trace: in instructions with visually ambiguous elements, UILoop correctly localizes and semantically interprets the intended action target, circumventing typical pitfalls of direct screen-based approaches.
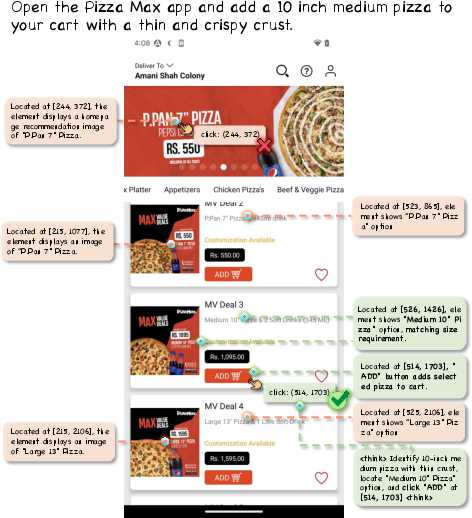
Figure 6: Case comparison between Screen-to-Action and UILoop approaches, emphasizing interpretability through explicit UI element semantic reasoning.
Dataset Demonstrations and Action Diversity
Representative examples from UI Comprehension-Bench highlight the difference in annotation richness and traceability for open_app, type, and click actions. This allows models to robustly generalize across action modalities.
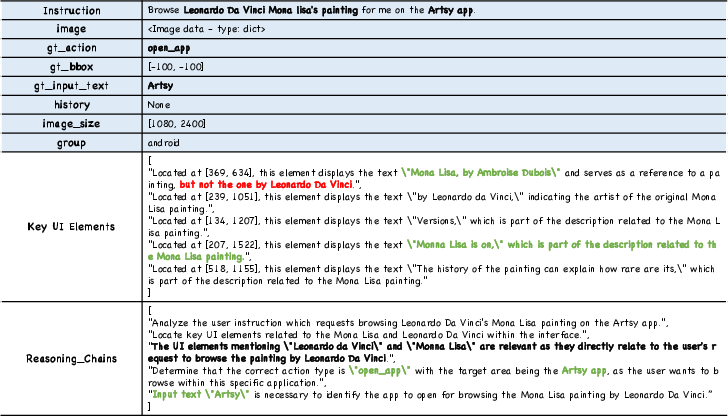
Figure 7: Example case with open_app actions and key UI elements from UI Comprehension-Bench.
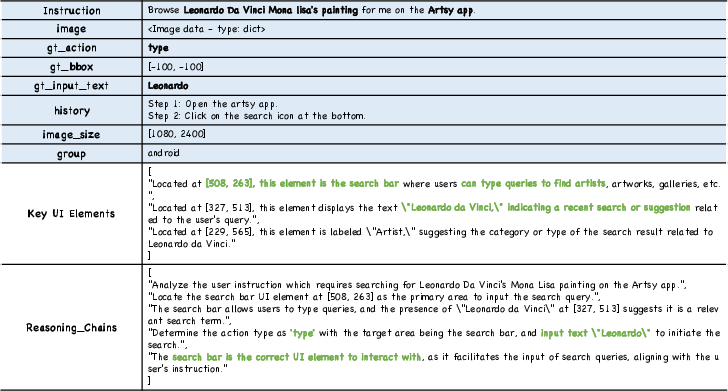
Figure 8: Example case with type actions and associated reasoning chain.

Figure 9: Example case with click actions depicting semantic-functional annotation.
Error Analysis
UILoop achieves markedly reduced error counts for Locate, Lingualize, and Leverage error types, demonstrating advanced mastery in UI element handling relative to leading Screen-to-Action models.
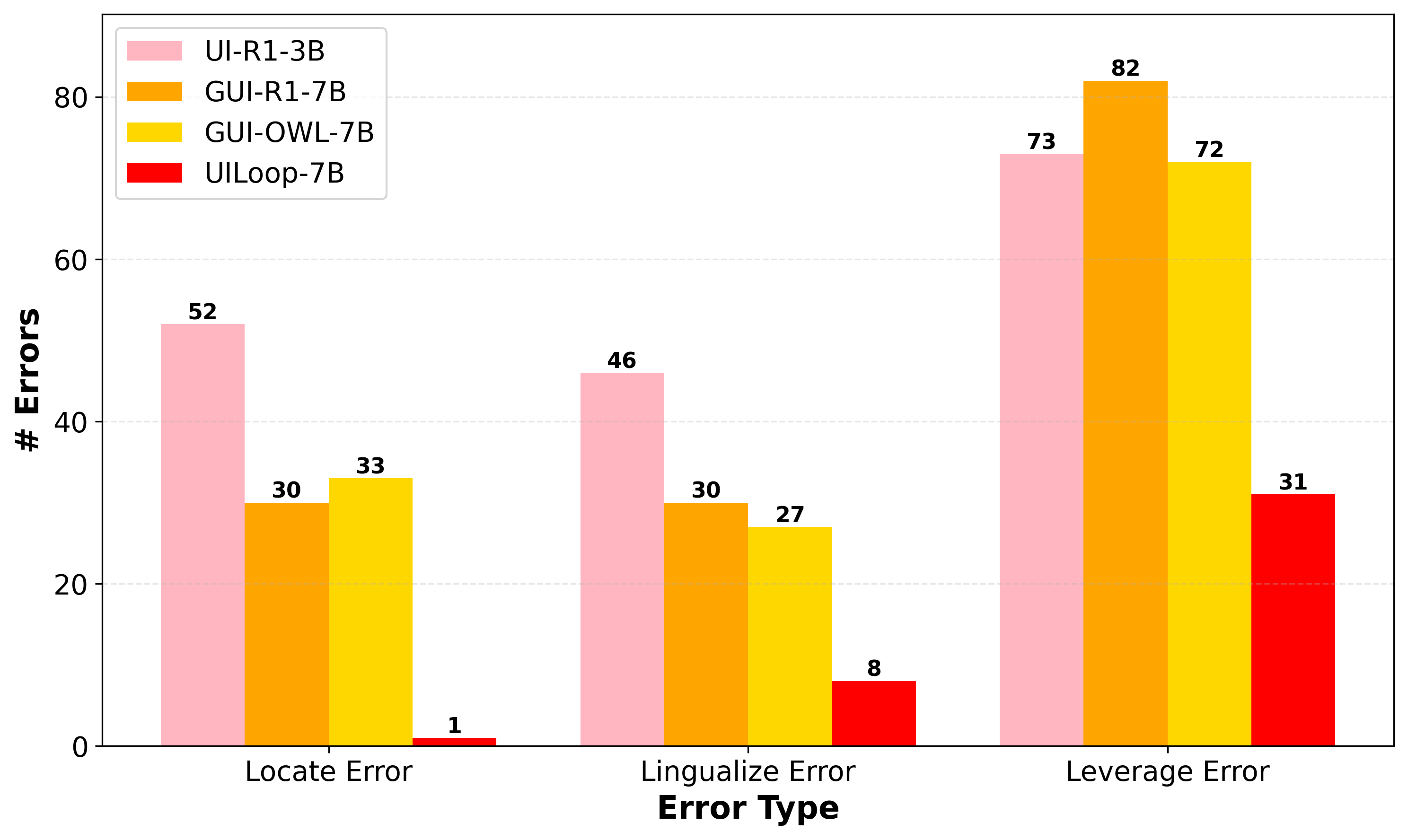
Figure 10: Cross-model analysis of error types, showing UILoop's advantage in minimizing common UI-related reasoning failures.
Implications and Future Directions
The introduction of UI-in-the-Loop fundamentally realigns objective functions for multimodal GUI agents, moving away from black-box action prediction toward transparency and intrinsic UI element comprehension. Practically, this enables more reliable, interpretable automation across heterogeneous GUI environments, supporting application domains such as office productivity, web browsing, and device control. Theoretical implications suggest improved sample complexity for downstream RL fine-tuning, enhanced zero-shot reliability, and better transferability across UI domains.
The limitations noted—such as the lack of coarse-grained UI layout modeling and primary focus on Qwen2.5-VL—motivate future work on hierarchical UI representations and broader MLLM generalization. The paradigm may catalyze principled advances in vision-language-action architectures and agent reasoning interoperability.
Conclusion
The paper delineates the critical missing link in existing "Screen-to-Action" approaches for GUI agents and provides a systematic UI-in-the-Loop paradigm with explicit UI Element-Driven RL fine-tuning. Empirical results on extensive benchmarks substantiate bold claims regarding both interpretability and actionable performance gains. The UI Comprehension-Bench establishes a robust foundation for advancing GUI agent capabilities, and UILoop marks an inflection point in multimodal agent reasoning methodology (2604.06995).