- The paper demonstrates that treating natural language instructions as dynamic reasoning pathways significantly improves GUI grounding performance.
- It presents a two-stage training framework combining supervised fine-tuning and reinforcement learning to optimize multi-perspective reasoning.
- Empirical results show up to 87.3% accuracy on benchmarks, establishing the practical impact of structured reasoning in diverse UI environments.
UI-Ins: Enhancing GUI Grounding with Multi-Perspective Instruction-as-Reasoning
Introduction and Motivation
The paper introduces UI-Ins, a framework for GUI grounding that reconceptualizes natural language instructions as dynamic reasoning pathways rather than static proxies for user intent. GUI grounding, the task of mapping instructions to actionable UI elements, is foundational for GUI agents and broader AGI pursuits. The authors identify two critical bottlenecks in existing approaches: (1) a lack of instruction diversity, with models typically trained on narrow, fixed instruction styles, and (2) pervasive instruction quality flaws in public datasets, with a reported 23.3% flaw rate. Empirical analysis demonstrates that leveraging diverse instruction perspectives at inference can yield up to a 76% relative performance improvement, even without retraining.
Data Pipeline for Multi-Perspective Reasoning
To address data quality and diversity, the authors propose a high-quality data processing pipeline. This pipeline first cleans noisy annotations using OmniParser V2 and IoU-based filtering, ensuring reliable spatial anchors for each instruction. Subsequently, GPT-4.1 is employed to synthesize instructions from four analytical perspectives: appearance, functionality, location, and intent. Each generated instruction undergoes a verification stage to guarantee unambiguous mapping to the target element.
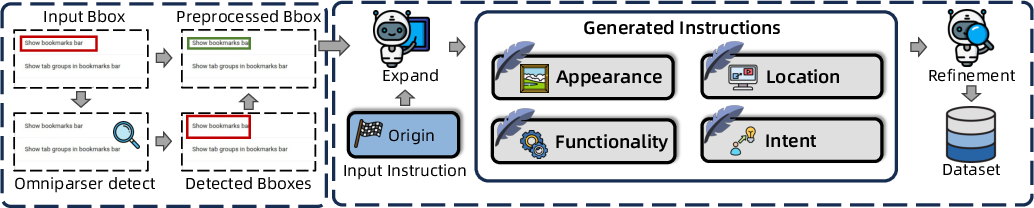
Figure 1: The data pipeline preprocesses bounding boxes, generates multi-perspective instructions via GPT-4.1, and verifies alignment between instructions and ground truth.
This systematic augmentation yields a multi-perspective corpus, enabling models to learn complex reasoning strategies and mitigating the detrimental effects of flawed instructions.
Instruction-as-Reasoning Framework
The core algorithmic contribution is the Instruction-as-Reasoning paradigm, instantiated as a two-stage training framework:
- Supervised Fine-Tuning (SFT): The model is trained to generate intermediate reasoning text from diverse instruction perspectives before predicting the grounding coordinate. The SFT objective maximizes the log-likelihood of concatenated reasoning and coordinate outputs, compelling the model to co-optimize reasoning generation and grounded prediction.
- Reinforcement Learning (RL) via GRPO: Building on SFT, the RL stage incentivizes the model to select the optimal reasoning pathway for each scenario. Prompts are open-ended, encouraging exploration of unconstrained perspectives, including compositional and emergent reasoning. Rewards are computed via point-in-box functions and normalized using Z-score advantages, with policy updates following GRPO.
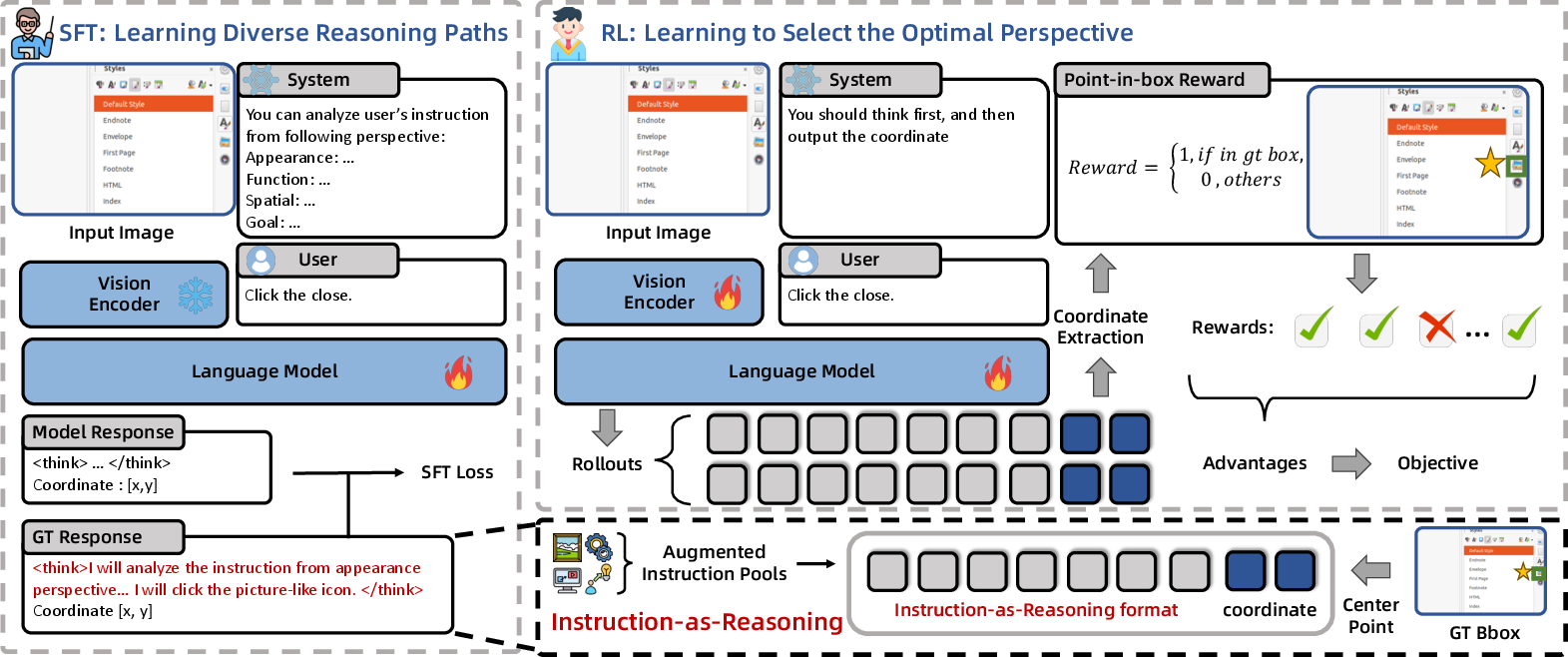
Figure 2: Instruction-as-Reasoning leverages diverse instructions as explicit reasoning pathways in SFT, then enables unconstrained exploration in RL for optimal perspective selection.
This framework not only instills multi-perspective reasoning but also mitigates policy collapse, a common failure mode in SFT+RL pipelines, by fostering diverse exploratory rollouts.
Experimental Results
UI-Ins-7B and UI-Ins-32B are evaluated on five grounding benchmarks and the AndroidWorld online agent environment. Quantitative results demonstrate consistent state-of-the-art (SOTA) performance:
- UI-I2E-Bench: UI-Ins-32B achieves 87.3% accuracy, outperforming all baselines.
- ScreenSpot-Pro: UI-Ins-32B attains 57.0% accuracy, with substantial gains on challenging software domains.
- MMBench-GUI L2: UI-Ins-32B scores 84.9%, with larger improvements on advanced instruction subsets.
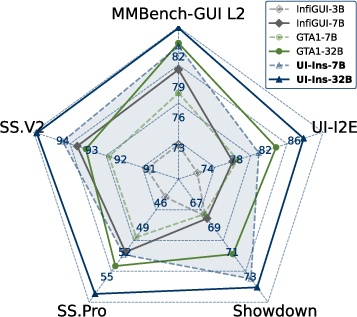
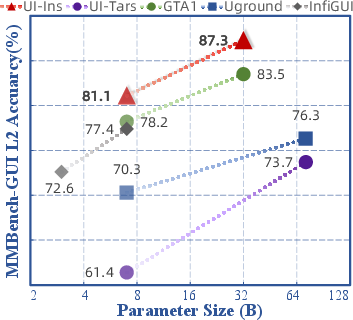
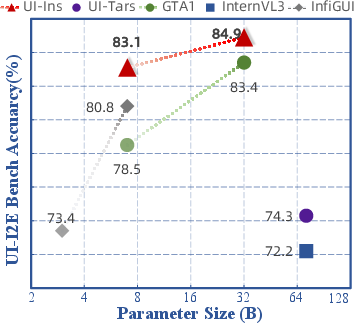
Figure 3: Performance comparisons of UI-Ins and other state-of-the-art methods.
On AndroidWorld, UI-Ins-7B (as executor under a GPT-5 planner) achieves a 74.1% success rate, surpassing strong closed-source models and demonstrating robust agentic potential in dynamic, real-world environments.
Ablation and Analysis
Ablation studies confirm the necessity of both SFT and RL stages, with removal of either resulting in significant accuracy degradation. The intermediate reasoning step is shown to be critical, with its absence causing >10% drops on key benchmarks. Comparisons between free-form reasoning (FFR) and Instruction-as-Reasoning (IR) reveal that FFR degrades performance, while IR consistently improves accuracy, validating the structured reasoning approach.
Instruction-as-Reasoning also stabilizes SFT+RL training by preventing policy collapse, as evidenced by substantial accuracy gains during RL when initialized with IR-based SFT.
Emergent Reasoning Capabilities
Qualitative analysis reveals that UI-Ins models develop emergent capabilities beyond the four predefined perspectives:
- Strategic Selection: The model dynamically selects the most effective reasoning perspective per scenario.
- Compositional Integration: Multiple perspectives are synthesized into cohesive reasoning chains.
- Novel Perspectives: The model generates entirely new analytical angles, such as group affiliation or UI element state, not seen during training.
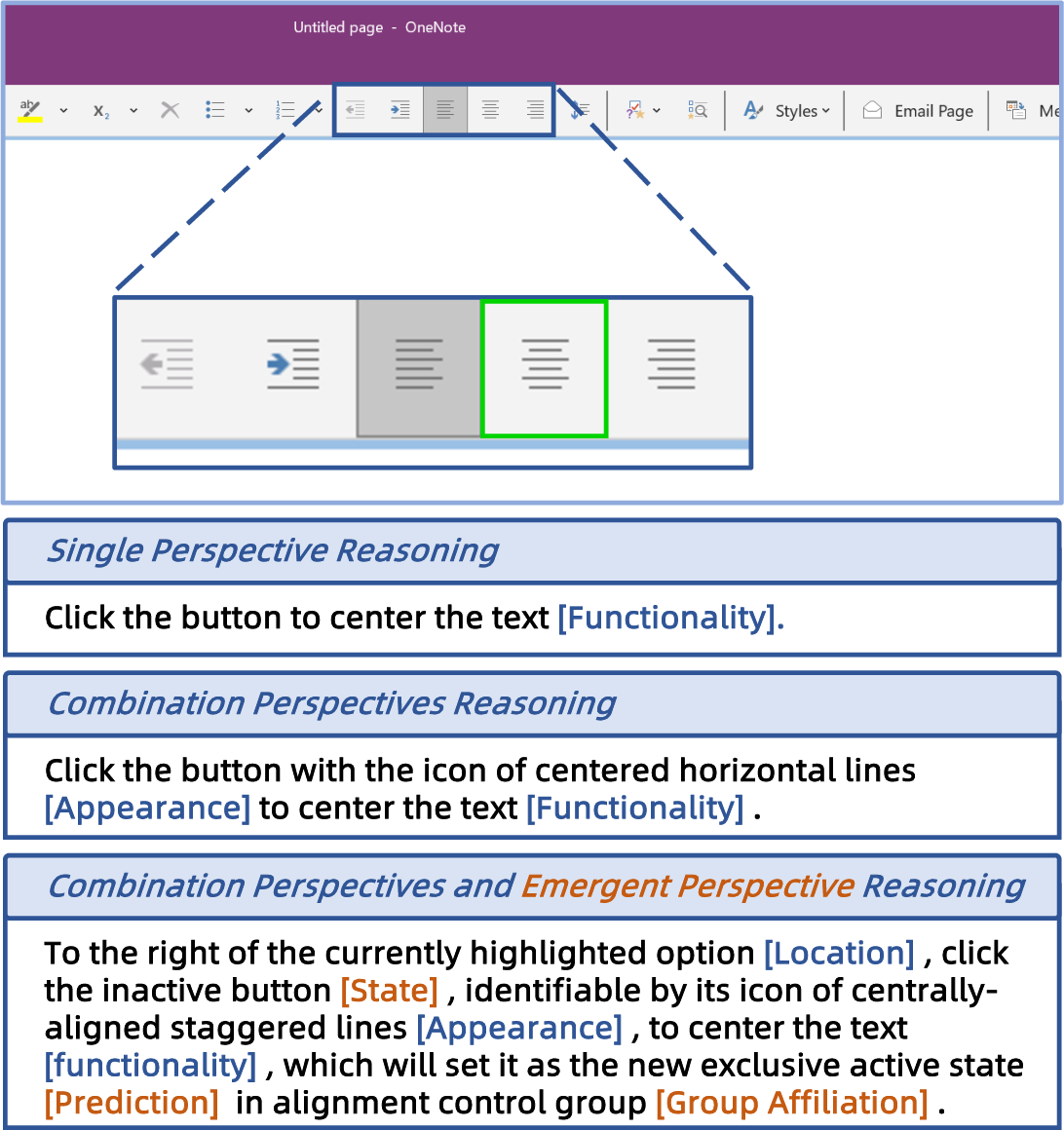
Figure 4: Different reasoning capabilities of UI-Ins, including compositional and emergent perspectives.
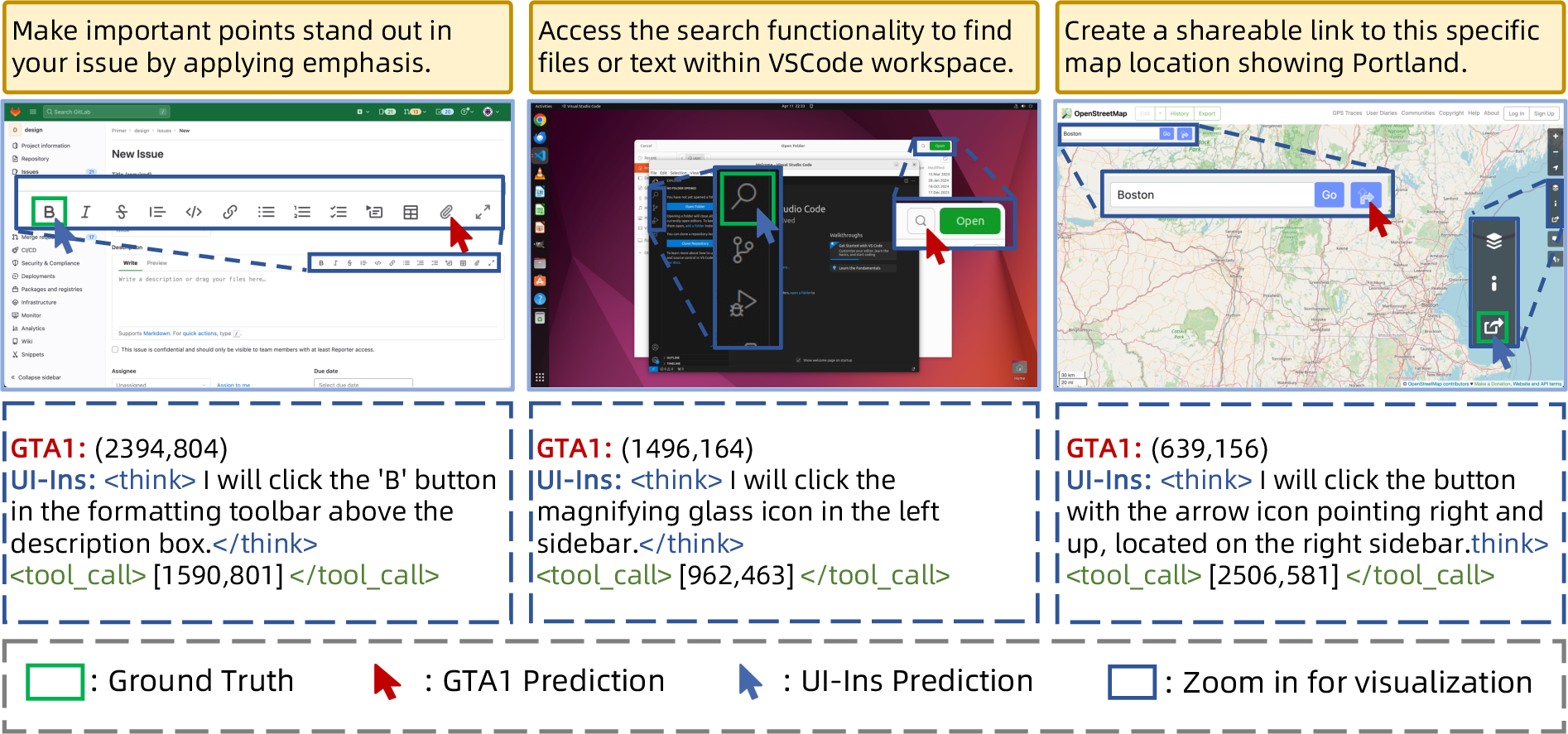
Figure 5: UI-Ins-7B succeeds on ambiguous grounding tasks by leveraging diverse reasoning, outperforming GTA1-7B.
Error Analysis
Three primary failure modes are identified:
- Lack of Domain-Specific Knowledge: Errors arise when external knowledge is required for correct grounding.
- Layout Understanding Deficiency: The model sometimes fails to interpret UI structure for precise action localization.
- Visual Ambiguity and Hallucination: Visually similar distractors can lead to incorrect selections.

Figure 6: Error analysis of UI-Ins, highlighting domain knowledge gaps, layout understanding failures, and hallucinations.
Implications and Future Directions
The Instruction-as-Reasoning paradigm demonstrates that structured, multi-perspective reasoning is essential for robust GUI grounding. The approach yields strong empirical gains, mitigates policy collapse, and unlocks emergent reasoning capabilities. Practically, UI-Ins models are well-suited for deployment in real-world GUI agents, with demonstrated stability and reliability in dynamic environments.
Theoretically, the work suggests that reasoning diversity and quality are central to grounding performance, challenging the prevailing view of instructions as static inputs. Future research may explore further expansion of reasoning perspectives, integration of external knowledge sources, and adaptation to more complex, multi-turn agentic tasks.
Conclusion
UI-Ins reframes GUI grounding by treating instructions as dynamic reasoning pathways, supported by a high-quality, multi-perspective data pipeline and a two-stage SFT+RL training framework. The resulting models achieve SOTA performance across diverse benchmarks and exhibit strong agentic capabilities. The work provides compelling evidence for the importance of instruction diversity and structured reasoning in GUI grounding, with broad implications for the design of intelligent agents and multimodal systems.