- The paper introduces a model that adapts Ferret with an 'any resolution' technique to magnify mobile UI sub-images for enhanced detail recognition.
- It integrates pre-trained image encoders with language embeddings to execute elementary tasks like icon recognition and advanced tasks such as nuanced interaction.
- Experimental results show superior performance over baselines like GPT-4V, highlighting its potential in accessibility, automated UI testing, and navigation.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
This paper introduces Ferret-UI, a multimodal LLM (MLLM) designed for enhanced comprehension and interaction with mobile user interface (UI) screens. Unlike traditional MLLMs that primarily focus on natural images, Ferret-UI addresses the unique challenges presented by mobile UI screens, such as elongated aspect ratios and smaller objects, by incorporating advanced visual features and resolution techniques.
Architecture and Design
Ferret-UI is built upon Ferret, an MLLM known for its effective spatial referring and grounding capabilities with natural images. To adapt Ferret for UI understanding, the architecture integrates an "any resolution" technique, enabling the model to magnify details within sub-images based on the screen's aspect ratios. This allows Ferret-UI to comprehend the fine-grained visual details crucial for UI screens.
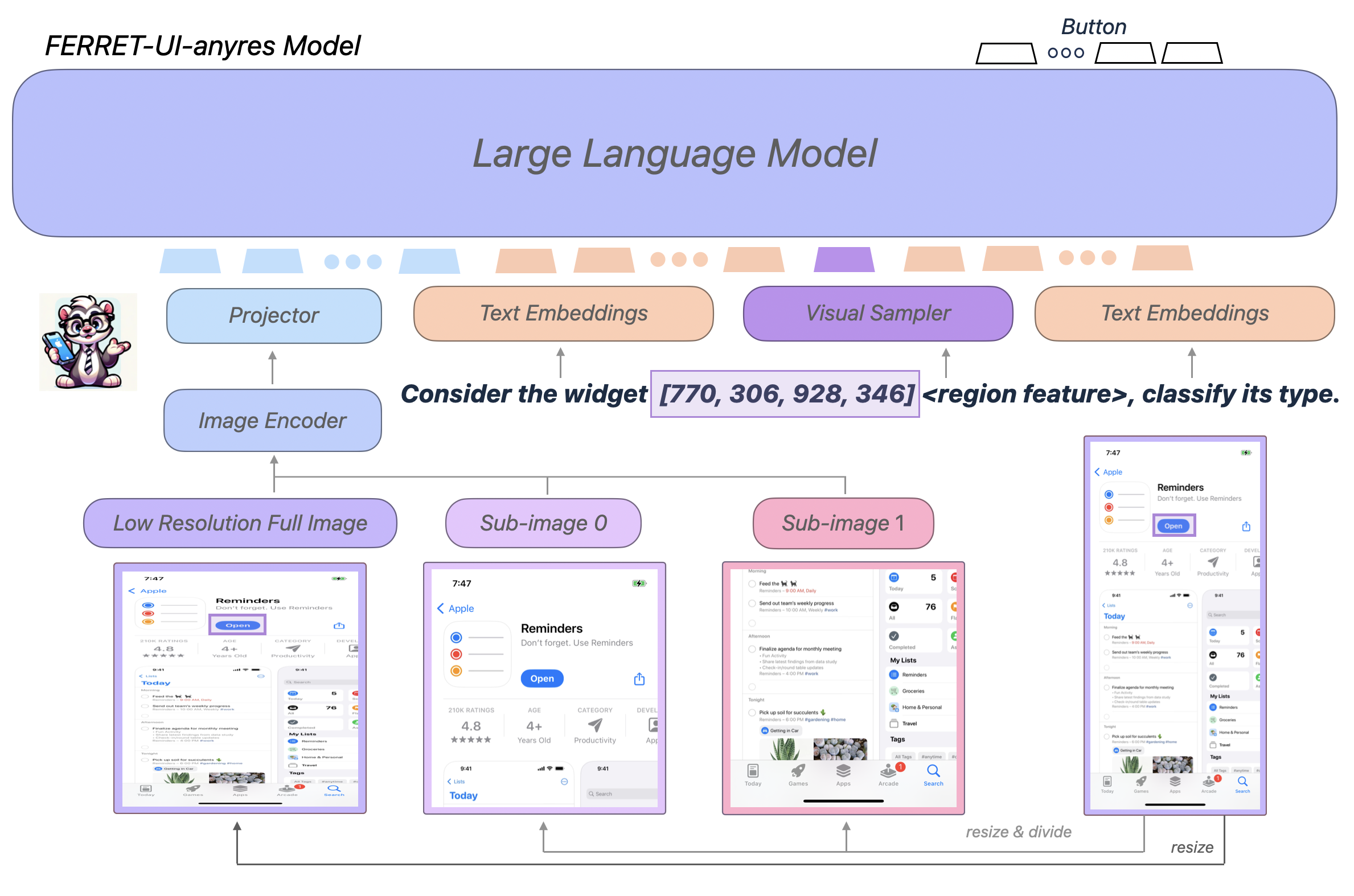
Figure 1: Overview of Ferret-UI-anyres architecture showing the integration of resolution techniques for enhanced UI understanding.
The model employs a pre-trained image encoder and a projection layer to extract comprehensive image features, supporting both global image context and finer details essential for understanding UI screens. The architecture is designed to process sub-images individually and combine these features with language embeddings to perform tasks such as referring, grounding, and reasoning.
Ferret-UI is trained using a curated dataset specifically tailored for mobile UI screens. The dataset encompasses elementary tasks (e.g., icon recognition, widget classification, OCR) and advanced tasks (e.g., detailed descriptions, conversation interactions), formatted to enhance the model's ability to follow instructions with precise region annotations.
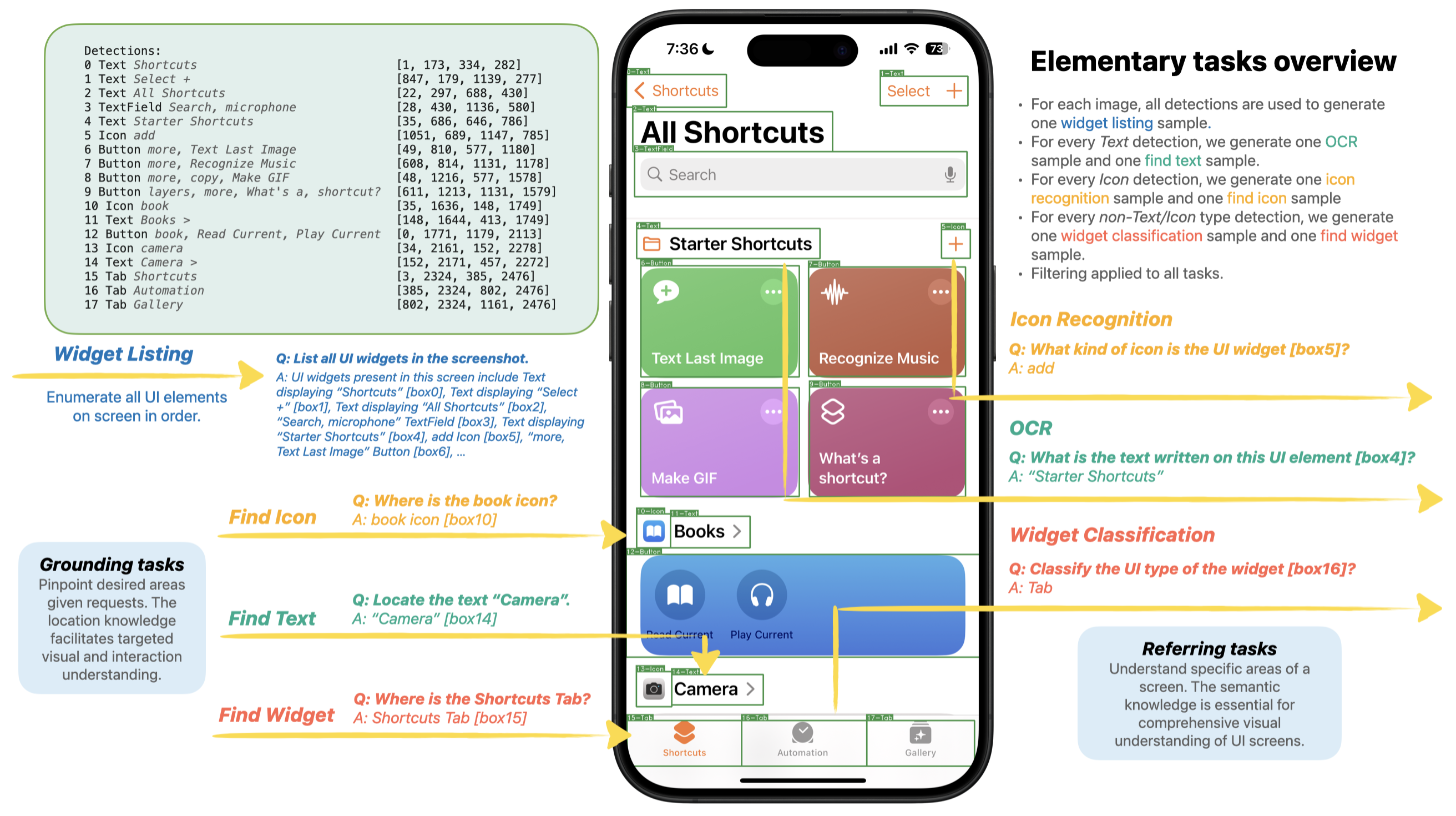
Figure 2: Elementary task data generation overview, highlighting the process of creating training samples from detected UI elements.
The training samples are meticulously crafted to represent a broad range of UI understanding tasks. For elementary tasks, sub-image features are leveraged to improve recognition and classification accuracy, while advanced tasks utilize text descriptions and multi-turn conversations generated using GPT-4, ensuring comprehensive coverage of UI elements.
Ferret-UI is evaluated against existing open-source UI MLLMs and the GPT-4V model across various UI tasks. Experimental results highlight Ferret-UI's superior performance on elementary UI tasks, with notable improvements over baseline models like Ferret and GPT-4V.
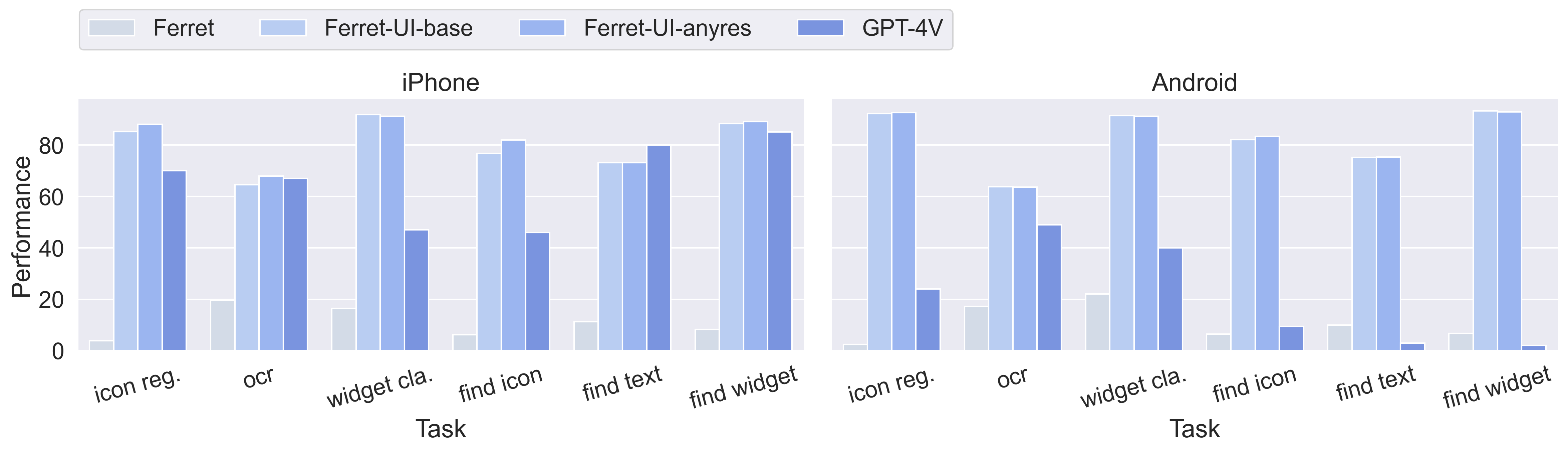
Figure 3: Performance comparison on elementary UI tasks, demonstrating Ferret-UI's robustness and precision.
Advanced task performance assessments indicate Ferret-UI's ability to engage in nuanced discussions, enabling goal-oriented actions and function inference. Despite training exclusively on iPhone screens, Ferret-UI exhibits considerable transferability, outperforming competitors in advanced tasks on both platforms.
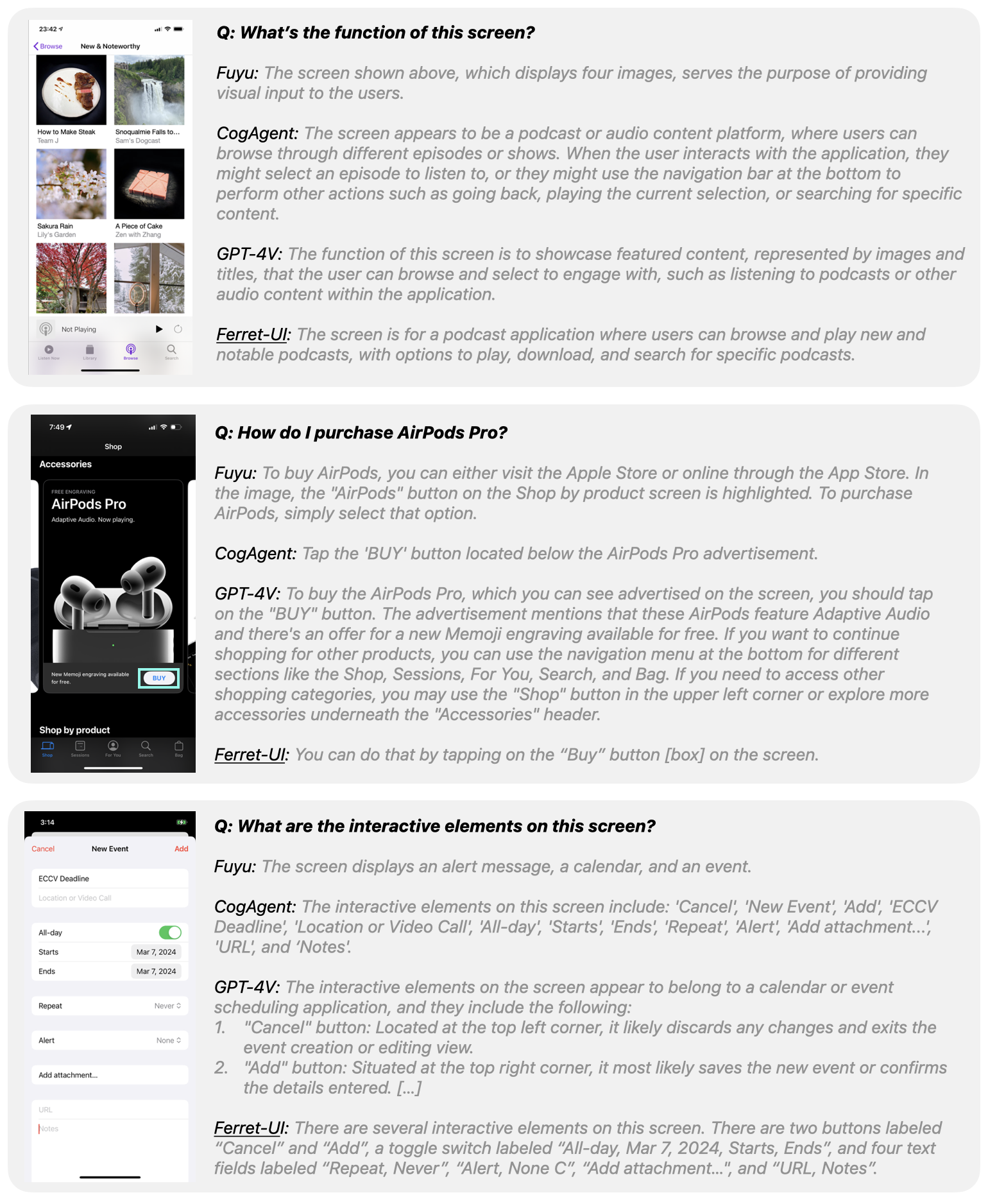
Figure 4: Advanced task visualization, illustrating differences among various models.
Implications and Future Directions
Ferret-UI represents a significant step forward in mobile UI understanding, with potential applications in accessibility, app testing, and usability studies. Its robust architecture and diverse datasets ensure precise UI comprehension and interaction capabilities, paving the way for advancements in automated UI navigation and accessibility solutions.
The integration of resolution techniques alongside sophisticated model training posits a transformative approach to mobile UI interaction. Future research may explore extending these capabilities to include more complex UI interactions and broader device compatibility, enhancing the overall utility and scalability of Ferret-UI.
Conclusion
Ferret-UI effectively addresses the challenges posed by mobile UI screens, setting a new benchmark for UI understanding with multimodal LLMs. Its comprehensive architecture and task-oriented dataset highlight the model's capability to perform complex referring, grounding, and reasoning tasks, thereby enhancing the interaction experience for both developers and end-users in mobile environments. Through rigorous evaluation, Ferret-UI has proven its capacity to outperform existing models, establishing itself as a leading solution in the domain of UI-centric multimodal language modeling.