- The paper finds that GPT-5 consistently outperforms other models, achieving over 90% accuracy in English-language CS certification exams.
- It employs rigorous prompt standardization and utilizes Bloom’s Taxonomy to assess model performance across domains and cognitive complexity levels.
- Results reveal domain sensitivity and translation effects, underscoring the need for tailored benchmarking in educational contexts.
Evaluating LLMs for Computer Science Education via Cross-Domain, Cross-Lingual Certification Benchmarks
Experimental Framework and Model Selection
This study addresses the systematic evaluation of LLMs in computer science education, focusing on their capabilities in domain-aligned certification contexts. Four high-performing models—GPT-5, DeepSeek-R1, Qwen-Plus, and Llama-3.3-70B-Instruct—were benchmarked using 1,068 questions extracted from six professional certification exams spanning computer networking, Java programming, and office applications, in both Chinese and English. The research design specifically controlled for prompt engineering, cross-lingual translation quality, and cognitive complexity by referencing Bloom’s Taxonomy.
Figure 1: The Overall Research Framework.
Prompt Standardization and Cross-Lingual Task Setup
Rigorous prompt construction protocols enforced expert role assignments and structured outputs, facilitating domain fidelity and consistency across models. Question datasets were translated bidirectionally using DeepSeek-V3, with subsequent manual verification to mitigate semantic drift and lexical inconsistencies.
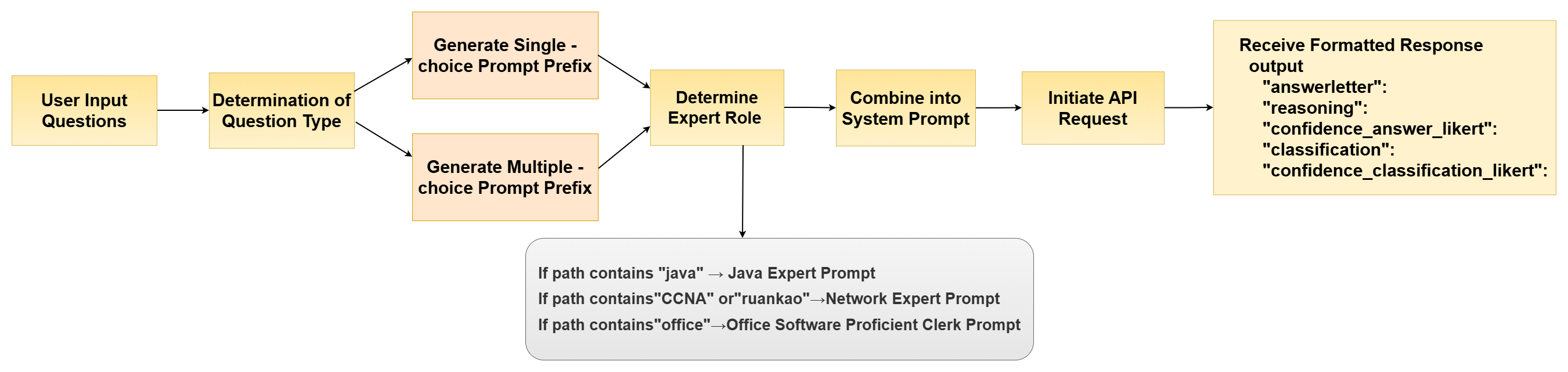
Figure 2: The Prompt Construction Process.
Quantitative Analysis: Domain, Language, and Cognitive Disparities
Analysis of accuracy rates across certification domains revealed that GPT-5 consistently outperformed other models in English-language exams (CCNA, ICDL, OCJP), registering accuracy rates above 90% and exhibiting superior robustness to input perturbations and higher-order tasks relative to baseline. Qwen-Plus demonstrated a marked advantage on Chinese exams, particularly in NCRE Java, where it achieved a 96.5% accuracy rate, surpassing GPT-5 by 3 percentage points. DeepSeek-R1 displayed the most balanced cross-lingual and cross-domain performance, maintaining ≥89% accuracy in five out of six exams. Llama-3.3-70B-Instruct was constrained by significant deficits in advanced reasoning and input robustness, with up to a 28.7-point drop between lower- and higher-order tasks.
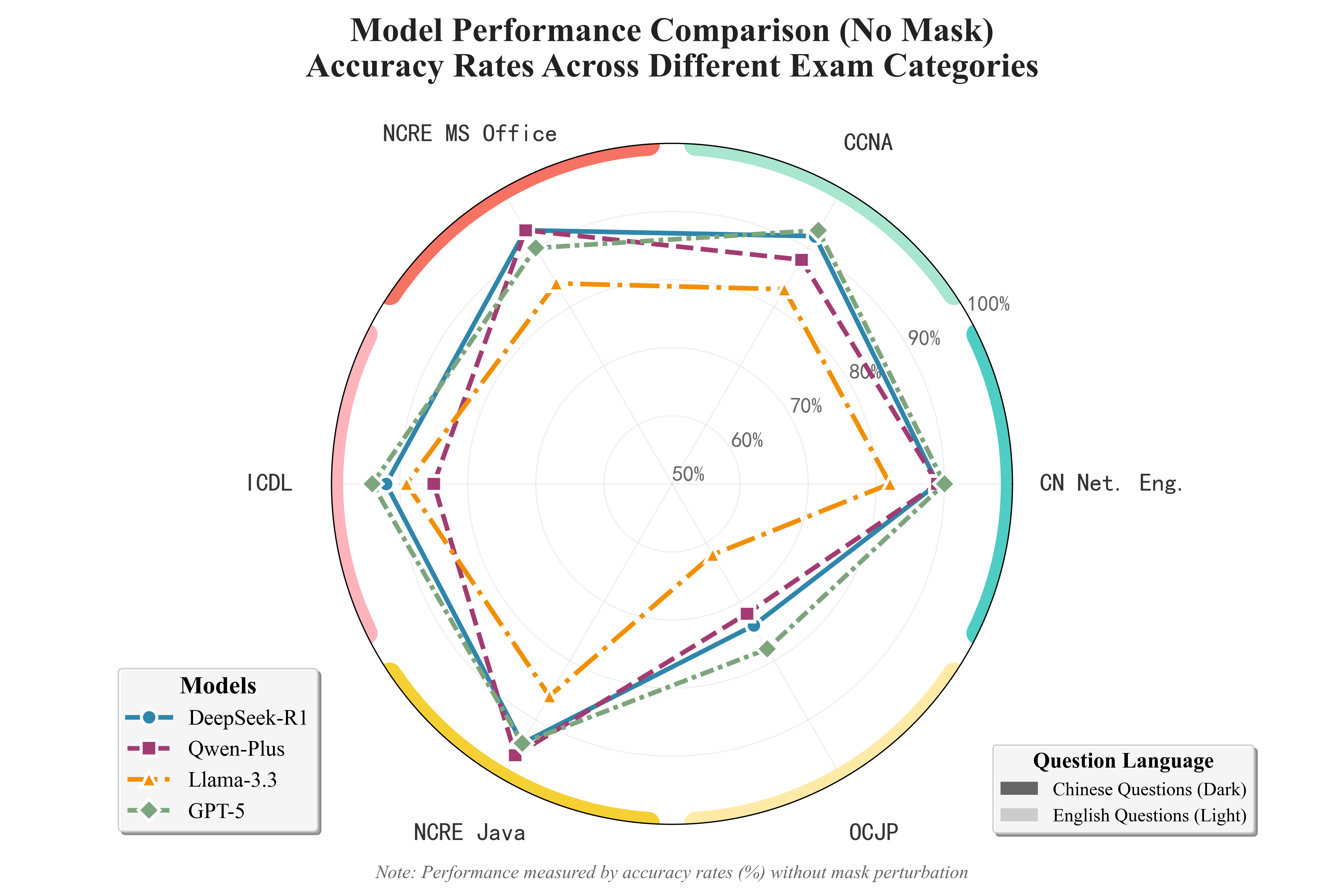
Figure 3: Radar chart of model accuracy rates (no masking) across six professional certification examinations.
Cross-lingual translation effects were asymmetrical: English-to-Chinese translation yielded substantial improvements for Qwen-Plus but, for most models, translation induced only minor accuracy shifts, underscoring GPT-5's language-agnostic reasoning stability. Domain-wise, models exhibited substantial subtopic sensitivity; e.g., Llama-3.3's accuracy on OCJP OOP questions dropped to 59% versus GPT-5’s 84.6%, highlighting architecture-dependent proficiency gaps.
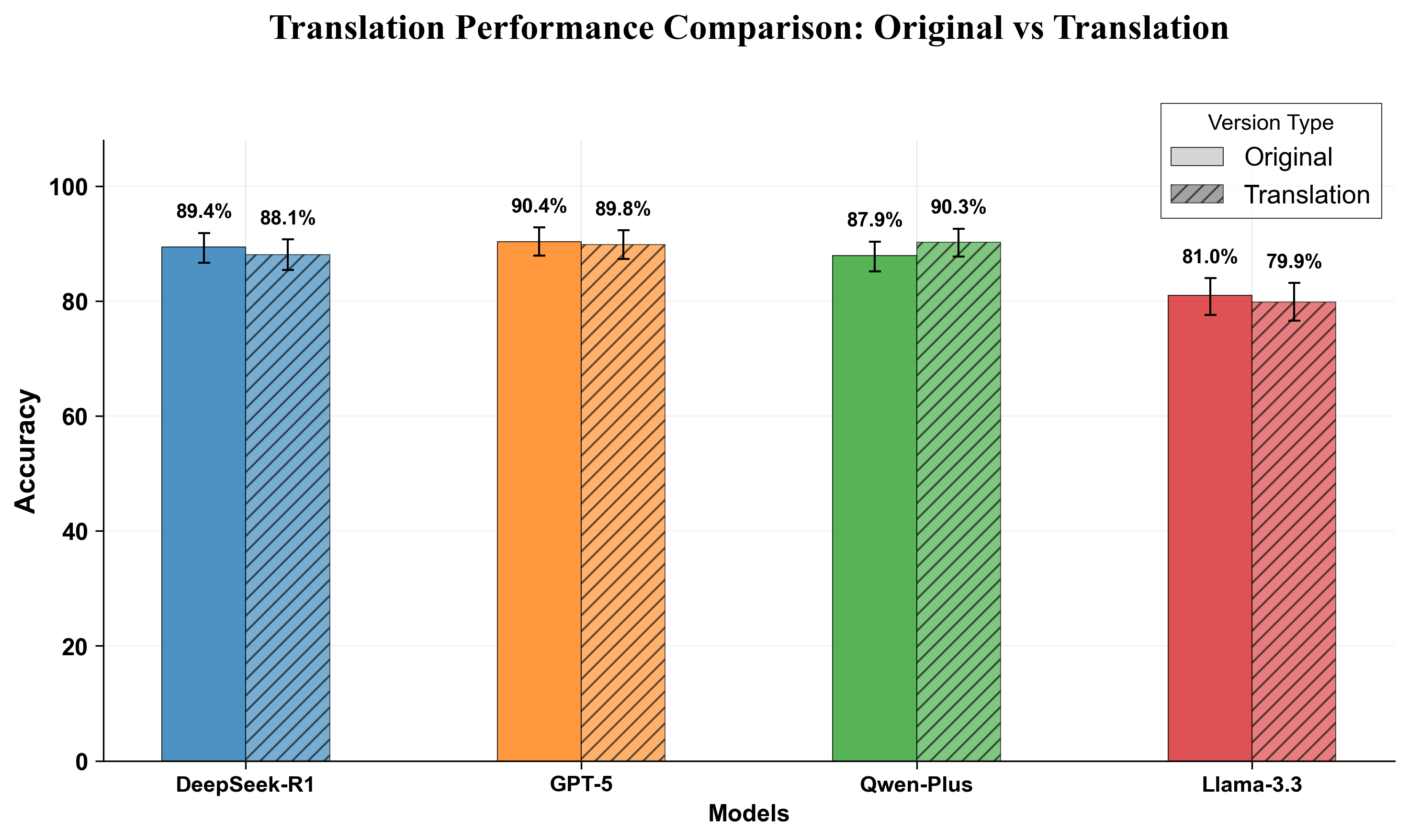
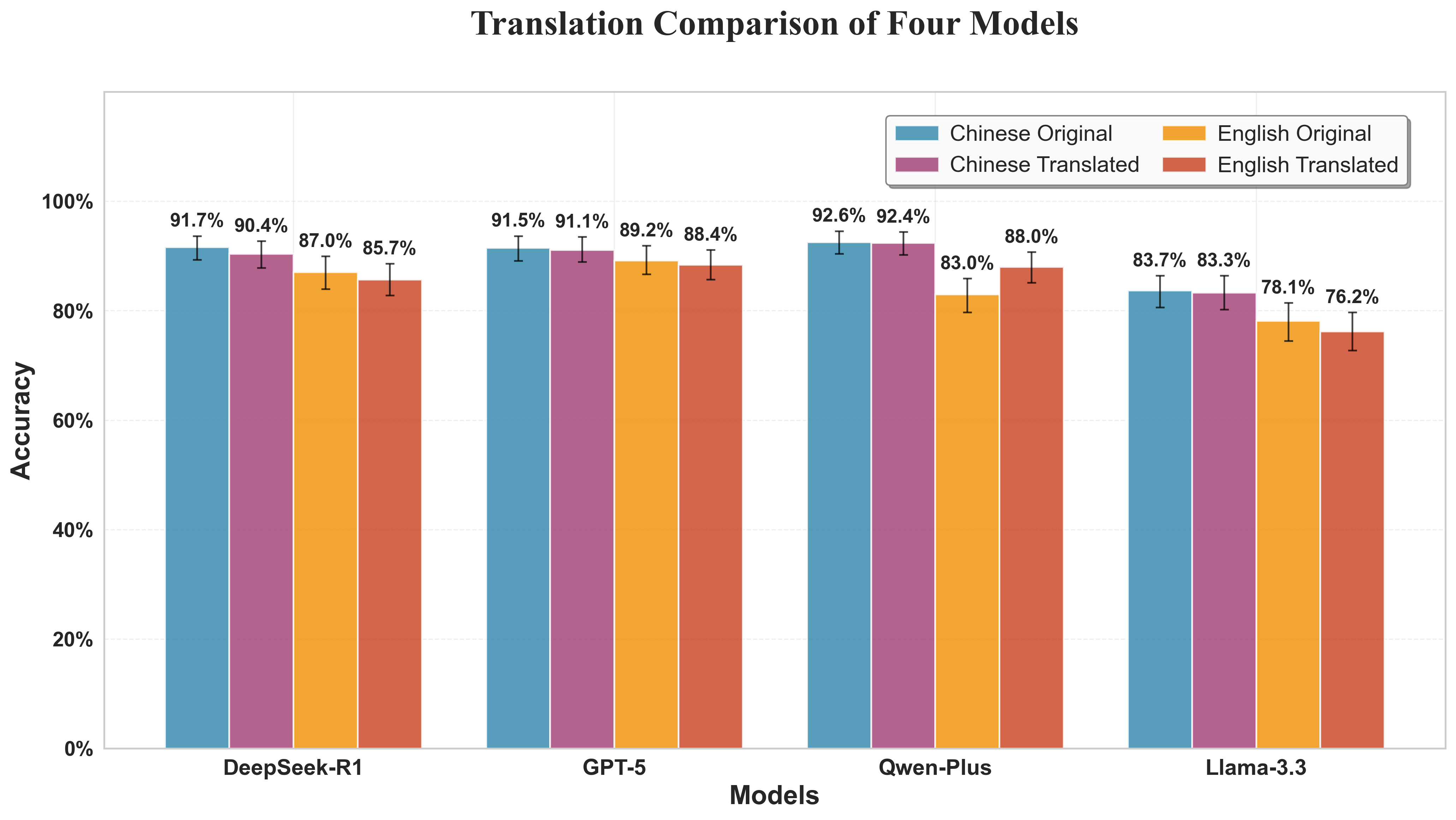
Figure 4: Overall accuracy on original versus translated questions across models.
Cognitive Complexity: Bloom's Taxonomy and Model Resilience
Model performance correlated strongly with question cognitive level: higher-order questions saw universal accuracy reductions. GPT-5 exhibited resilience, with only a 5.8-point gap between lower- and higher-order tasks (91.9% vs. 86.1%), whereas Llama-3.3 dropped precipitously from 84.3% to 55.6%. This pattern confirms knowledge retrieval dominance over analytical synthesis in current LLMs.
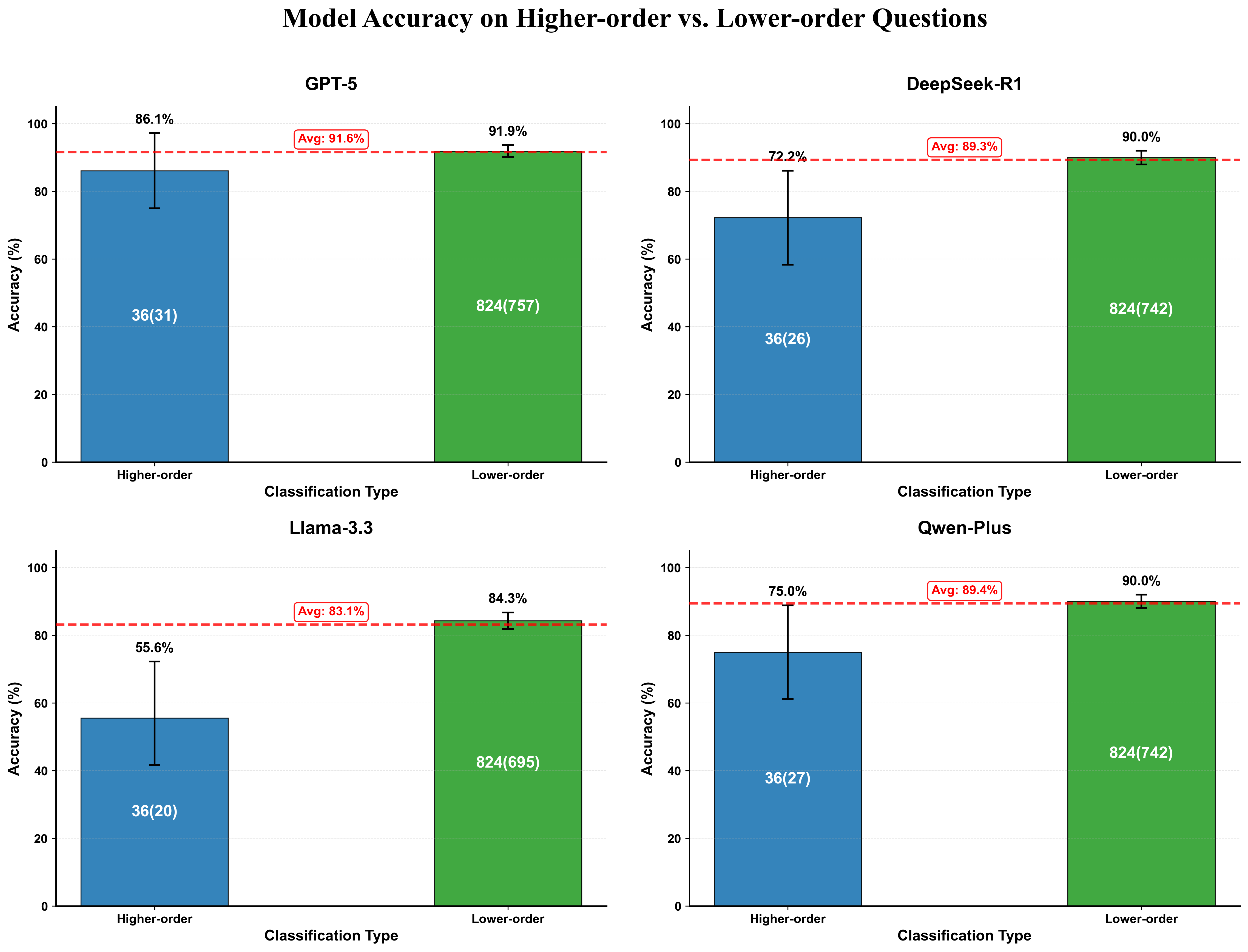
Figure 5: Accuracy on higher-order (blue) and lower-order (green) questions for each model, based on Bloom's revised taxonomy.
Reliability: Calibration and Robustness to Masking
Confidence-accuracy alignment was evaluated using Likert-scaled self-reported confidence. All models demonstrated positive calibration, with highest accuracy for responses rated as “very high confidence.” GPT-5's calibration was particularly tight; DeepSeek-R1 and Qwen-Plus followed closely, while Llama-3.3 rarely assigned maximum confidence, thus constraining its deployment in high-assurance educational pipelines.
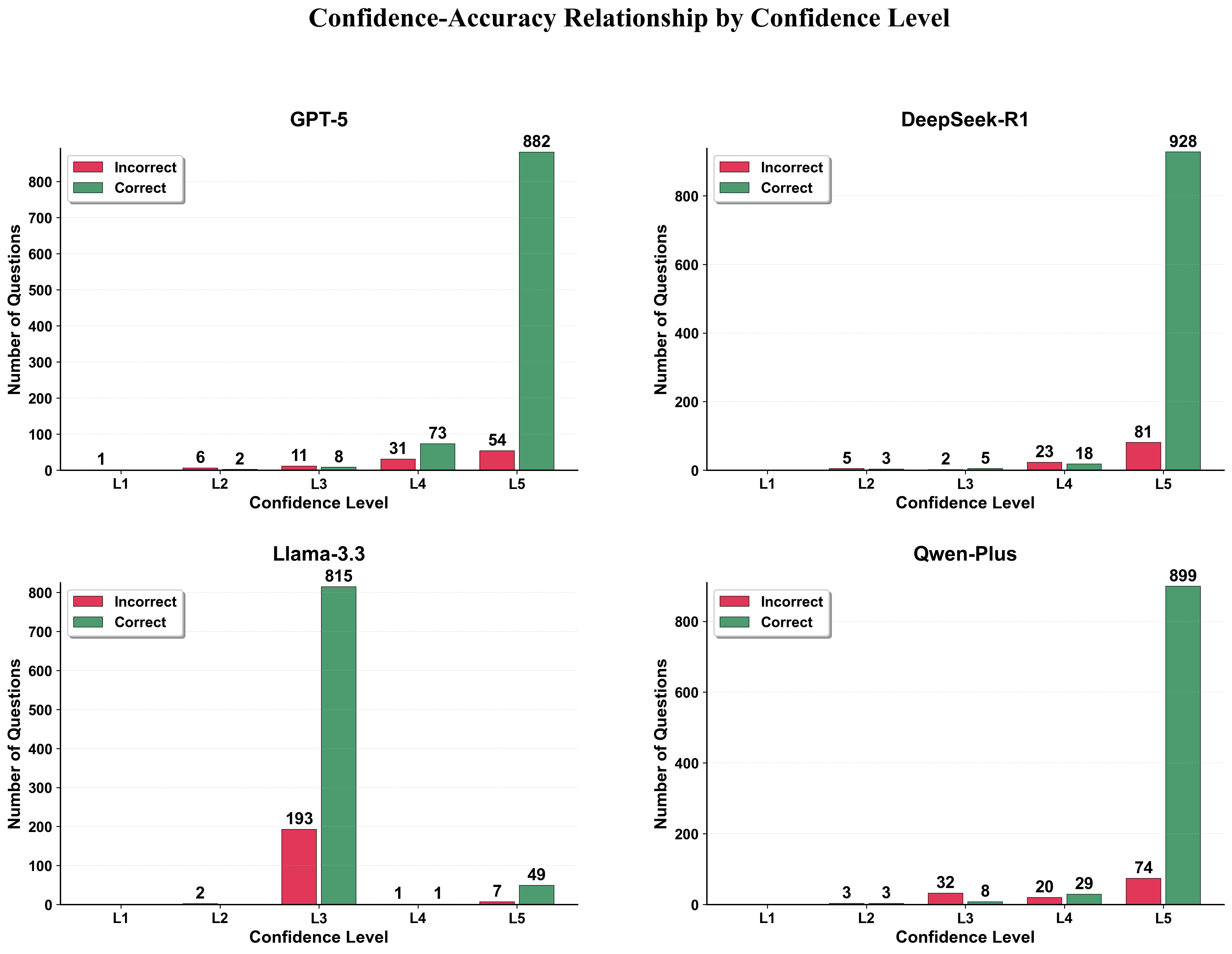
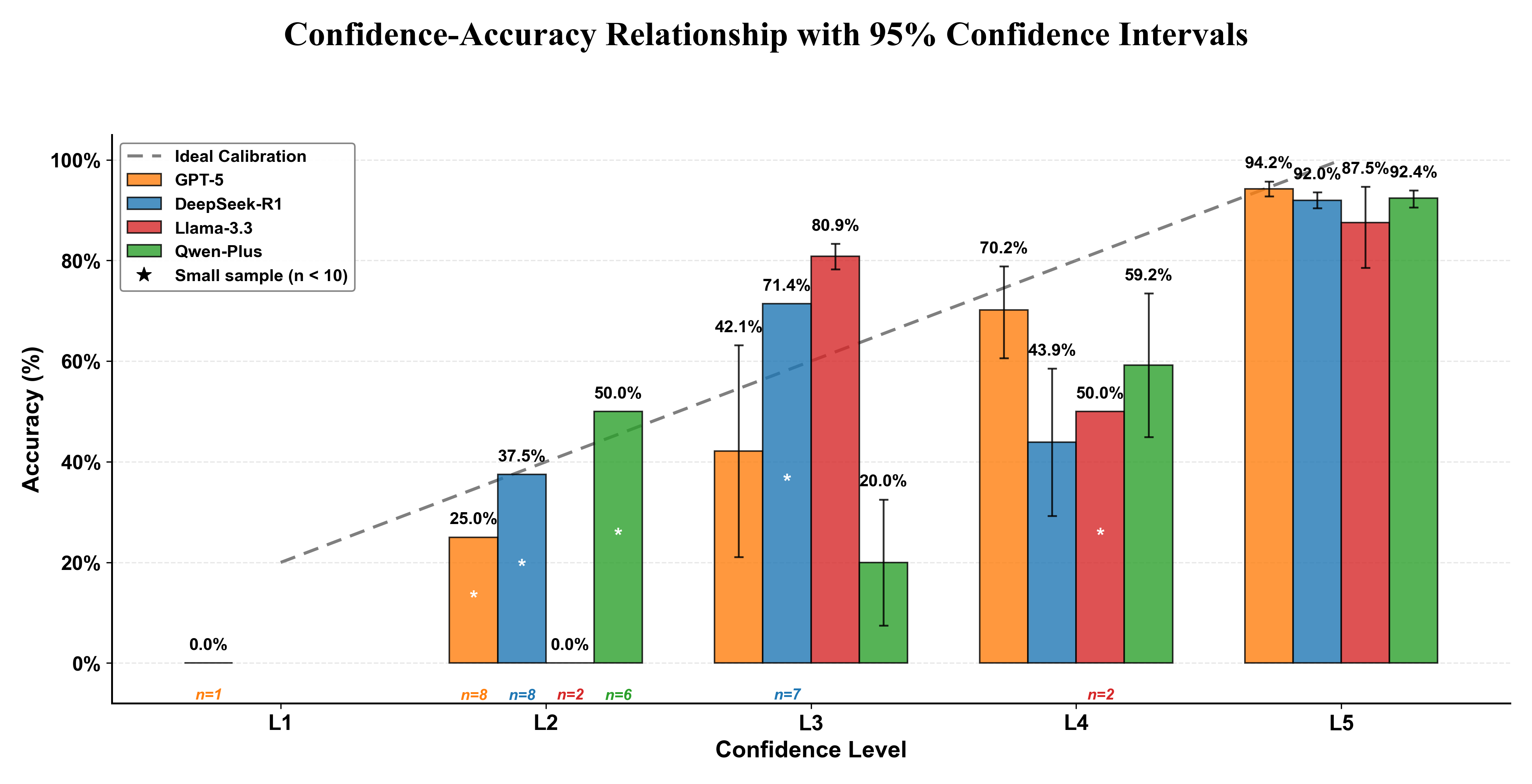
Figure 6: Distribution of correct (green) and incorrect (red) responses across confidence levels (L1--L5) for each model.
Input perturbation via random masking revealed differentiated robustness. GPT-5’s accuracy declined modestly from 90.4% to 74.8% at 60% masking weight, while Llama-3.3’s accuracy dropped drastically to 49.6%. This highlights architecture-driven divergence in contextual recovery and tolerance to fragmented input, critical for real-world classroom applications.
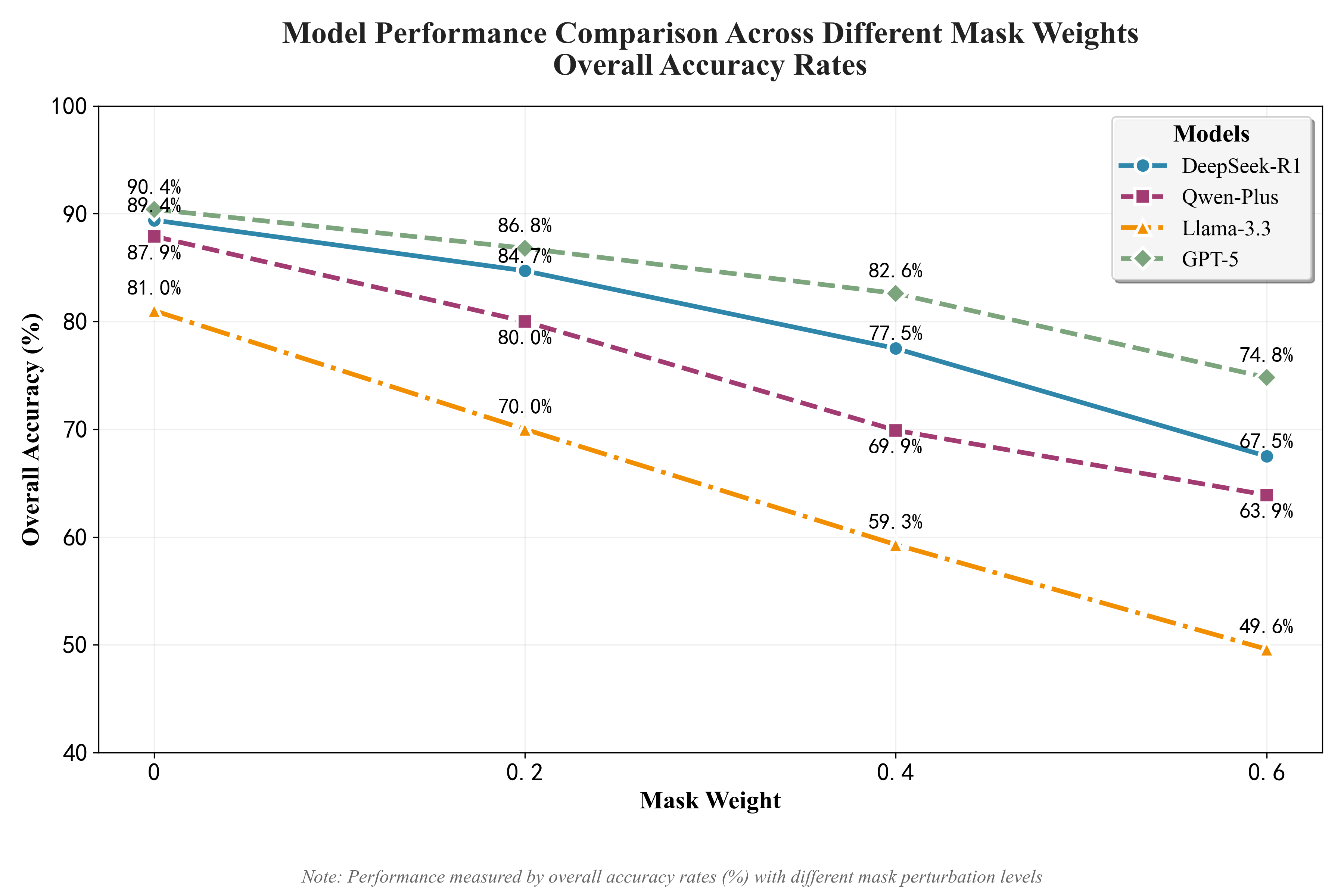
Figure 7: Example of uniform random word-level masking applied to a sample question stem at different mask weights.
Implications, Limitations, and Prospects
The empirical findings reveal several fundamental principles:
- Language Dependency: Cross-lingual robustness is model-specific; curriculum designers should select LLMs matched to instructional language and consider translation-induced accuracy shifts.
- Domain Sensitivity: Proficiency gaps across subdomains mandate domain-specific benchmarking for deployment decisions.
- Cognitive Complexity Constraint: Advanced models like GPT-5 are required for higher-order learning objectives; open-source variants lag substantially.
- Calibration and Robustness: Confidence filtering is an effective strategy for education support; however, robustness to noisy/incomplete input is not uniformly addressed by contemporary models.
- Objective Metrics Superiority: Low inter-model agreement on perceived difficulty ratings limits the utility of subjective LLM evaluations; accuracy and cognitive classification deliver more reliable signals.
Limitations include restriction to multiple-choice standardized certifications, exclusion of open-ended and interactive assessment formats, and absence of human baselines. Future directions involve extension to broader CS domains, integration of generative tasks, benchmarking against human experts, and improvement of cross-lingual pretraining and architectural robustness.
Conclusion
Certification-oriented evaluation of leading LLMs uncovers nuanced performance profiles across domain, language, and cognitive axes. While models like GPT-5 are reliably proficient in both factual and higher-order reasoning in computer science exams, translation effects and input fragmentation expose persistent weaknesses in open-source models, demanding context-sensitive deployment strategies. Calibration, resilience to perturbation, and domain tuning should be regarded as essential discriminators for LLM adoption in educational contexts.

