RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
Abstract: We introduce region-specific image refinement as a dedicated problem setting: given an input image and a user-specified region (e.g., a scribble mask or a bounding box), the goal is to restore fine-grained details while keeping all non-edited pixels strictly unchanged. Despite rapid progress in image generation, modern models still frequently suffer from local detail collapse (e.g., distorted text, logos, and thin structures). Existing instruction-driven editing models emphasize coarse-grained semantic edits and often either overlook subtle local defects or inadvertently change the background, especially when the region of interest occupies only a small portion of a fixed-resolution input. We present RefineAnything, a multimodal diffusion-based refinement model that supports both reference-based and reference-free refinement. Building on a counter-intuitive observation that crop-and-resize can substantially improve local reconstruction under a fixed VAE input resolution, we propose Focus-and-Refine, a region-focused refinement-and-paste-back strategy that improves refinement effectiveness and efficiency by reallocating the resolution budget to the target region, while a blended-mask paste-back guarantees strict background preservation. We further introduce a boundary-aware Boundary Consistency Loss to reduce seam artifacts and improve paste-back naturalness. To support this new setting, we construct Refine-30K (20K reference-based and 10K reference-free samples) and introduce RefineEval, a benchmark that evaluates both edited-region fidelity and background consistency. On RefineEval, RefineAnything achieves strong improvements over competitive baselines and near-perfect background preservation, establishing a practical solution for high-precision local refinement. Project Page: https://limuloo.github.io/RefineAnything/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a tool called RefineAnything. Its purpose is simple: fix small, messy details in a specific part of a picture (like blurry text, a logo, or a face) without changing anything else in the image. Think of it like using a tiny, precise eraser and pencil on just one spot of a photo, while the rest of the picture stays exactly the same.
What questions the paper tries to answer
- How can we improve tiny local details in a picture while keeping the rest untouched?
- Can we guide the model to edit only inside a user-marked region (like a box or scribble)?
- Is there a smart way to “zoom in” on the edit area so the model does a better job?
- How do we paste the fixed part back into the full image so it looks natural, with no visible seams?
- How well does this approach work compared to other popular image editing tools?
How the method works (in simple terms)
The authors build a system that understands both images and text instructions (multimodal). You can use it in two ways:
- Reference-based: you give it the picture to fix and a reference picture to match (for style, font, identity, etc.).
- Reference-free: you only give it the picture to fix and a short instruction like “sharpen the text inside the box.”
Here are the main ideas, explained with plain language and analogies:
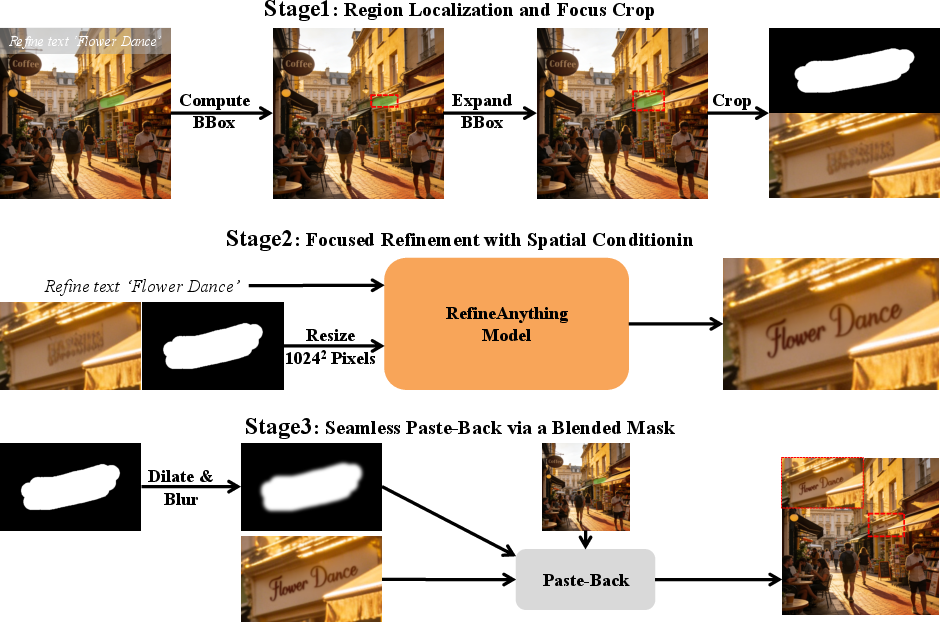
1) Focus-and-Refine: the “magnifying glass” trick
- Problem: Most modern image models process a fixed number of pixels at a time. When the detail you want to fix is tiny, it gets too few pixels and ends up blurry or misshaped.
- Insight: If you crop the small region and resize that crop to the model’s full working size, the model treats that small area like a big one. Even though you didn’t add new information, the model “pays more attention” to it and reconstructs details much better.
- Steps: 1) Crop the user-marked region with a little margin (for context). 2) Resize that crop to the model’s standard size and refine it there. 3) Paste it back onto the original image.
This is like taking a tiny sticker off a poster, cleaning it under a magnifying glass, and sticking it back on perfectly aligned.
2) Blended paste-back: smooth, seam-free reattachment
- If you paste the refined crop back directly, you might see a hard edge or seam.
- To fix that, the method uses a “soft” mask (a gently blurred edge) so the refined region blends smoothly with the original background. The rest of the image stays pixel-for-pixel unchanged.
3) Boundary Consistency Loss: training the model to respect edges
- During training, the model is penalized more whenever it creates weird seams or mismatched colors along the boundary of the edited region.
- This extra focus at the edges helps the pasted result look natural and seamless.
4) What the model understands
- The system reads:
- The input image
- An optional reference image
- A user-marked region (scribble or box)
- A short text instruction
- It uses a modern diffusion-based generator (a popular type of image model) and a helper component called a VAE (a tool that compresses and reconstructs images). You can think of the diffusion model as a careful painter that removes “noise” step by step to produce a clean edit, guided by the instruction and region.
5) Data and testing
- The authors built a training dataset called Refine-30K with 30,000 examples:
- 20,000 with references (so the model learns to match specific styles or identities)
- 10,000 without references (instruction-only)
- They also created a test set called RefineEval to measure two things:
- How well the edited region matches the correct target
- How perfectly the background stays unchanged
What they found
The method works very well, especially on two fronts that matter most for real work:
- Much better details in the edited region:
- Compared to strong baselines, RefineAnything roughly halves some error measures on the edited region (for example, its MSE goes from about 0.040 to 0.020 and LPIPS from about 0.264 to 0.155). In plain terms, letters look sharper, logos look correct, and fine lines look clean.
- Near-perfect background preservation:
- The parts you didn’t want to change remain almost exactly the same (background error measures are close to zero, and background similarity is about 0.9997 on a 0–1 scale).
- Works with or without a reference:
- With a reference, it better matches identity, fonts, and styles.
- Without a reference, it still follows instructions and improves fine detail more reliably than other tools.
- Efficiency bonus:
- Because it only refines the cropped region, it focuses compute where it matters, making it more efficient and effective for small edits.
Why this matters
- Real-world use cases need perfect small details:
- E-commerce product photos, posters, ads, packaging, UI screenshots, maps, and infographics often live or die by a single letter or thin line.
- Trust and usability:
- If the background changes at all, users notice and might not trust the result. This method keeps everything else intact.
- Practical workflow:
- RefineAnything is like a precision touch-up brush you can add to existing image-generation/editing pipelines.
- Shared resources for the community:
- The new dataset (Refine-30K) and benchmark (RefineEval) make it easier for others to test and improve region-specific refinement methods.
In short, the paper shows a simple but powerful idea: zoom in on the part you want to fix, do a careful edit, and blend it back perfectly. This leads to sharper details exactly where you want them, with the rest of the image unchanged—just what many real-world editing tasks need.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unanswered questions that future work could address:
- Real-world defect generalization: The training/evaluation degradations are synthetic (scribble masks + inpainting). How well does the method repair naturally occurring artifacts (e.g., camera blur, compression, low-light noise, JPEG ringing, low-resolution upscaling errors, OCR-unfriendly fonts, AI-generated text distortions)?
- Distribution shift assessment: Evaluate on datasets with authentic defects (documents, signage, UIs, retail packaging, road signs) rather than synthetic inpaints to quantify domain gap and robustness.
- Text-specific fidelity metrics: Include OCR-based accuracy (character/word error rate), legibility scores, and text layout consistency to evaluate the “text/logo” use cases more directly than CLIP/DINO/LPIPS.
- Identity- and product-specific metrics: For faces/products/logos, add identity verification (e.g., face verification ROC/EER), logo retrieval/verification, and product matching metrics to measure reference adherence beyond generic similarity features.
- Background preservation measurement rigor: Current bg metrics use bounding boxes and are near-trivial due to paste-back. Evaluate with a tight “no-edit” band outside the soft mask, gradient/edge-difference metrics, noise/grain statistics, and color-shift tests to detect subtle spillover.
- Fair baseline protocol: Clarify whether baselines received the same region masks and a focus-and-paste pipeline. Provide a “mask-aware” setting for baselines or a “region-agnostic” setting for all to ensure apples-to-apples comparisons.
- Ablation depth: Beyond the two ablations, analyze sensitivity to crop margin m, dilation radius r, blur kernel k, boundary band widths, LoRA rank, and where LoRA is applied. Report how these choices scale with region size/content.
- Efficiency claims quantification: Provide wall-clock latency, GPU memory, and throughput per region; compare to full-frame editing and to alternative tiling strategies. Include cost when refining many small regions in a single image.
- Multiple region handling: How does the approach scale to many noncontiguous regions (e.g., a page of small texts)? Strategies for batching, conflict resolution in overlapping crops, and global consistency are not explored.
- Extreme region scales: Behavior when the target is extremely small (few pixels at input scale) or covers most of the image; define thresholds where focus-and-refine ceases to help or harms global consistency.
- Theoretical grounding of the “crop-and-resize” effect: Formal analysis of why VAEs reconstruct better under zoom-in reparameterization, whether this holds across VAEs with different bottlenecks/quantizers, and whether it persists in pixel-space DiT models.
- Generality across architectures: Test the focus-and-refine strategy on non-VAE pipelines (pixel-space diffusion, consistency models) and different backbones (UNet vs DiT) to verify universality.
- Compositing limitations: The dilate+Gaussian blending is illumination- and geometry-agnostic. Investigate gradient-domain/Poisson blending, Laplacian pyramid compositing, local color/illumination transfer, and noise/grain matching for harder seams (hair, translucency, motion blur).
- Seam artifact metrics: Introduce boundary-aware quantitative metrics (edge RMSE along a narrow ring, chroma/luma discontinuities, gradient statistics) rather than relying solely on qualitative examples.
- Boundary Consistency Loss design: Explore alternatives (Poisson/gradient-domain losses, multi-scale boundary losses, adversarial seam discriminators) and conduct hyperparameter sensitivity/robustness studies.
- Robustness to imperfect region cues: Measure degradation when the user mask/box is misaligned, noisy, too small/large, or includes background; propose uncertainty-aware or mask-refinement mechanisms.
- Instruction ambiguity and conflicts: Characterize behavior under ambiguous or conflicting instructions (text vs reference), and add automatic conflict detection/resolution strategies or instruction validation.
- Multilingual instruction following: Evaluate instruction adherence across languages/scripts and domain-specific jargon; quantify reliance on the frozen Qwen2.5-VL encoder and its language coverage.
- Data scale and coverage: Refine-30K is relatively small and constructed with closed tools. Quantify category/scene/scale diversity, long-tail coverage (e.g., curved text, reflective materials), and report per-category performance.
- Reproducibility of data pipeline: The use of closed-source VLMs (Gemini) and SAM3 complicates reproducibility. Provide open pipelines or quantify the effect of swapping in open alternatives (e.g., LLaVA, Grounded-SAM variants).
- Evaluation set size and bias: RefineEval includes 67 cases with synthetic degradations. Expand to larger, unbiased benchmarks with naturally degraded inputs, and publish detailed annotations/masks for community use.
- Subjective evaluation dependence on VLM: Reference-free evaluation uses a single VLM judge. Add human studies (blinded pairwise comparisons), multiple automated raters, inter-rater agreement, and robustness checks against prompt framing.
- High-resolution scaling: Analyze performance beyond 1024×1024, memory/latency under 4K–8K workflows, and interactions with tiling/multi-scale refinement and cross-tile seam handling.
- Photometric and noise consistency: Study tonal, noise, and compression consistency between refined crops and original background, especially under heavy JPEG compression or camera noise, and introduce matching modules if needed.
- Long-horizon/iterative editing: Examine cumulative artifacts from repeated focus-and-refine passes, and propose mechanisms to prevent drift or over-smoothing with multiple edits.
- Video and multi-view extension: Temporal consistency, flicker at paste boundaries, and multi-view geometric consistency are unaddressed; design temporally coherent masks, 3D-aware conditioning, or optical-flow-guided blending.
- Reference modalities: Explore using structured references (vector logos, text strings with fonts, canonical product templates) and constraints (OCR-guided losses, stroke-level priors) for stronger fidelity on text/logos.
- Safety and misuse: Address risks of tampering with official documents, safety-critical labels, or identities; propose watermark preservation, edit provenance tracking, or policy filters for sensitive regions/content.
- Full finetuning vs LoRA: Assess whether full or partial finetuning (beyond attention projections) materially improves detail recovery or robustness, and the trade-offs in compute/generalization.
- Automatic focus selection: Replace fixed margin m with content- or uncertainty-adaptive cropping; study learned predictors that propose crop scales/aspect ratios per region to balance context and detail.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging RefineAnything’s region-specific refinement, Focus-and-Refine strategy, and near-perfect background preservation. Each item links to sectors, potential tools/workflows, and key dependencies or assumptions.
- High-fidelity logo and text fixes in product imagery
- Sector(s): Advertising, E-commerce, Retail, Print
- Tools/Workflows: DAM/PIM pipeline plugin (e.g., “RefineAnything API”); Adobe Photoshop/Figma/Canva extension where users box a defective area (logo, SKU text), optionally supply a brand reference, then auto-refine and paste-back with a diff/approval step
- Dependencies/Assumptions: GPU-backed diffusion inference; brand asset reference libraries; human approval to avoid semantic drift; licensing for Qwen-Image-Edit and VAE stack
- Infographics/UI asset micro-corrections (strokes, icons, small text)
- Sector(s): Software, Design, Education
- Tools/Workflows: Figma/Sketch plugin to refine broken strokes, small icons, or typographic artifacts via bounding box or scribble; export with change mask and SSIM_bg/MSE_bg audit report
- Dependencies/Assumptions: Region annotation available; governance policies for editing UI screenshots; maintain versioned diffs for compliance
- Prepress polish for packaging and print collateral
- Sector(s): Print, CPG, Marketing
- Tools/Workflows: Prepress checklist step that refines tiny misprints or low-density text; integration with RIP workflow; batch mode with scripted boxes around key text/logos
- Dependencies/Assumptions: Avoid altering regulated content (e.g., ingredients, barcodes); maintain audit trail and approvals; high-resolution decode time in SLA
- Document scan enhancement targeted to hard-to-read snippets (pre-OCR)
- Sector(s): Enterprise software, Finance, GovTech, Education
- Tools/Workflows: CLI/SDK that refines only low-contrast words/lines to improve OCR confidence scores; automatic ROI detection + user override masks; export original + refined + mask + OCR deltas
- Dependencies/Assumptions: Strict policy to prevent semantic alteration; immutable provenance logs; be cautious for legal/financial documents
- Creative QA for generative content (localized failure repair)
- Sector(s): Creative ops, Media
- Tools/Workflows: Post-generation microservice that detects defective micro-regions (e.g., warped text) and calls RefineAnything for targeted correction while preserving global composition; automated regression metrics on edited region and background consistency
- Dependencies/Assumptions: MLLM-based defect detectors; approval-in-the-loop; API orchestration
- Archival and museum poster/ephemera legibility touch-ups
- Sector(s): Cultural heritage, Libraries
- Tools/Workflows: Conservator-controlled refinement of small glyphs or torn areas; export mask, diff image, and provenance; preserve patina by strict background lock
- Dependencies/Assumptions: Ethical guidelines to avoid altering historical meaning; store edit metadata; no wholesale restoration without policy review
- Photo retouching for small localized issues (consumer apps)
- Sector(s): Consumer photography
- Tools/Workflows: Mobile app feature to fix eye glare, smudged shirt text, or thin lines; tap-to-select bounding box; on-device or cloud inference with privacy controls
- Dependencies/Assumptions: Compute constraints on-device; privacy and content safety guardrails; fair-use for logos/identity-sensitive content
- Frame-specific VFX patching with strict context preservation
- Sector(s): Film, TV, Advertising
- Tools/Workflows: Nuke/After Effects bridge to refine a localized artifact (e.g., prop text) while keeping the rest untouched; downstream tracking to propagate across frames manually
- Dependencies/Assumptions: No built-in temporal coherence; apply only to single frames or pair with external tracking; render-time budgets
- Brand compliance correction against reference
- Sector(s): Brand management, Retail
- Tools/Workflows: Reference-based refinement to align a captured mark to a canonical reference (colors, kerning) inside selected ROI; automated conformance report
- Dependencies/Assumptions: Accurate reference library; color management/ICC profiles; manual oversight
- Compliance-friendly region-limited editing audit
- Sector(s): Policy, Legal, Media forensics
- Tools/Workflows: Use RefineEval-style background metrics and stored masks to demonstrate that non-target pixels are unchanged; embed C2PA or similar provenance metadata
- Dependencies/Assumptions: Organizational policy adoption; standardized reporting (SSIM_bg, MSE_bg thresholds); secure storage of edit masks and hashes
- Academia: benchmarking and method development
- Sector(s): Academia/Research
- Tools/Workflows: Adopt Refine-30K and RefineEval to benchmark region fidelity vs. background drift; ablate Boundary Consistency Loss and Focus-and-Refine on new backbones (e.g., SDXL, FLUX)
- Dependencies/Assumptions: Access to datasets/weights; compute for fine-tuning; clear licensing for redistribution
- Dataset curation for synthetic images (localized post-fix)
- Sector(s): Robotics, Autonomous systems, CV research
- Tools/Workflows: After generating synthetic training images, auto-refine only text/signage regions for legibility while preserving scene; tag edits in metadata to avoid training on altered evidence without disclosure
- Dependencies/Assumptions: Transparency to downstream consumers; don’t apply to real-world evidence used for perception QA; provenance labels
Long-Term Applications
These use cases require further research, scaling, or engineering (e.g., temporal consistency, real-time constraints, regulatory frameworks).
- Temporally consistent video region refinement
- Sector(s): Media, AR/VR, Social
- Tools/Workflows: Extend Focus-and-Refine with temporal attention and optical-flow constraints; consistent masks over tracked regions; boundary-aware temporal loss
- Dependencies/Assumptions: New training regime and datasets; acceleration for multi-frame diffusion; flicker suppression
- On-device, real-time refinement for mobile and wearables
- Sector(s): Consumer, AR
- Tools/Workflows: Distilled/consistency models or trajectory-segmented accelerations; NPU/GPU kernels; tap-to-refine UI overlays
- Dependencies/Assumptions: Model compression (e.g., consistency models, LoRA adapters); power/latency budgets; privacy by default
- Multi-view/3D-aware region refinement
- Sector(s): E-commerce (3D product spins), Digital twins, VFX
- Tools/Workflows: Refine a small region consistently across multiple views; geometry-aware paste-back; multi-view boundary consistency loss
- Dependencies/Assumptions: Camera pose/mesh priors; multi-view diffusion or 3D Gaussian/NeRF coupling; dataset support
- CAD-to-visual micro-corrections for manufacturing manuals
- Sector(s): Manufacturing, Energy
- Tools/Workflows: Reference-based refinement using CAD snapshots to correct alphanumeric nameplates or part IDs in photos; logs for compliance
- Dependencies/Assumptions: Strong identity matching; policies forbidding edits on inspection evidence unless labeled as illustrative
- Medical imagery: artifact removal in teaching materials (non-diagnostic)
- Sector(s): Healthcare Education
- Tools/Workflows: Constrain refinements to non-diagnostic annotations (e.g., arrows, overlays) or de-identification regions; maintain immutable originals
- Dependencies/Assumptions: Strict prohibition for diagnostic editing; IRB/compliance review; provenance and watermarking
- Assistive accessibility: auto-legibility enhancement
- Sector(s): Education, Public sector, Accessibility
- Tools/Workflows: Browser/reader extension that refines only low-legibility regions (small fonts, thin lines) while preserving context; togglable view
- Dependencies/Assumptions: Client-side acceleration; non-destructive rendering; user consent and transparency
- Content authenticity frameworks with region-level edit attestations
- Sector(s): Policy, Standards, Media
- Tools/Workflows: Embed mask, diffs, and metrics into C2PA manifests; standardize “region-limited edit” claims verified by background-consistency metrics
- Dependencies/Assumptions: Standards alignment; cryptographic signing and key management; industry adoption
- Robotics/maintenance: readable serial-number capture in the field
- Sector(s): Field service, Industrial IoT
- Tools/Workflows: After capture, refine only the serial-number region for documentation; store mask/diff to separate visualization from archival raw
- Dependencies/Assumptions: Never use refined images for algorithmic inspection; chain-of-custody and dual-storage (raw + refined)
- Auto-correction copilots for designers/developers
- Sector(s): Software, Design
- Tools/Workflows: IDE/Design-tool copilot proposes micro-fixes (e.g., aliasing on tiny icons) with region masks; one-click accept with audit trail
- Dependencies/Assumptions: Reliable defect detection; user-in-the-loop; plug-in SDKs
- Training paradigm upgrades: “refinement head” for general editors
- Sector(s): GenAI platforms
- Tools/Workflows: Add a Focus-and-Refine branch and boundary losses to existing editing models to guarantee background lock and micro-detail recovery
- Dependencies/Assumptions: Access to backbone weights; data and compute for tuning; compatibility with different VAEs/tokenizers
- Real-time AR signage prototyping and A/B testing
- Sector(s): Retail, Events
- Tools/Workflows: Live overlays that refine sign text/art in selected bounding boxes on a captured still, then project to AR mockups
- Dependencies/Assumptions: Low-latency pipelines; clear separation between prototype and production assets; IP permissions
- Legal discovery workflows for demonstrative exhibits
- Sector(s): Legal/Policy
- Tools/Workflows: Produce demonstrative images with localized refinements (e.g., enhanced legibility boxes), bundled with mask, diffs, and authenticity claims
- Dependencies/Assumptions: Jurisdictional rules on admissibility; secure provenance; legal review
Notes on Feasibility and Dependencies
- Model and compute: Current pipeline depends on a diffusion backbone (e.g., Qwen-Image-Edit) and VAE at fixed input resolution; GPU inference is typical for high-res assets.
- Inputs and control: Users must supply a reliable region cue (scribble mask or bounding box); automated ROI detection can help but should allow user overrides.
- Background preservation and trust: Paste-back with blended masks yields near-perfect background consistency; organizations should log the mask, diffs, and background metrics (SSIM_bg, MSE_bg) for auditability.
- Legal and ethical guardrails: Avoid semantic changes to regulated content (medical, legal, financial); maintain originals and full provenance; be cautious with identity-sensitive faces/logos.
- Licensing and IP: Ensure rights to model weights, datasets (Refine-30K), and references; comply with brand guidelines and copyright.
- Operational fit: Integrations as plugins, APIs, or microservices should include human-in-the-loop approvals, automated defect detection, and clear versioning.
Glossary
- AdamW: An optimizer that adds decoupled weight decay to Adam for better generalization. "We use AdamW~\cite{adam} (lr , $0.9$, $0.999$, weight decay $0.01$, )"
- BF16: A 16-bit floating-point format (bfloat16) that speeds training while preserving dynamic range. "BF16, batch size $8$, and train for $20$K steps."
- Boundary Consistency Loss: A training objective that upweights errors near edit boundaries to reduce visible seams. "We further introduce a boundary-aware Boundary Consistency Loss to reduce seam artifacts and improve paste-back naturalness."
- CLIP: A vision–language embedding model used to measure image–text semantic alignment. "and strengthens semantic alignment with higher DINO~\cite{zhang2022dino,oquab2023dinov2}/CLIP~\cite{clip} similarities"
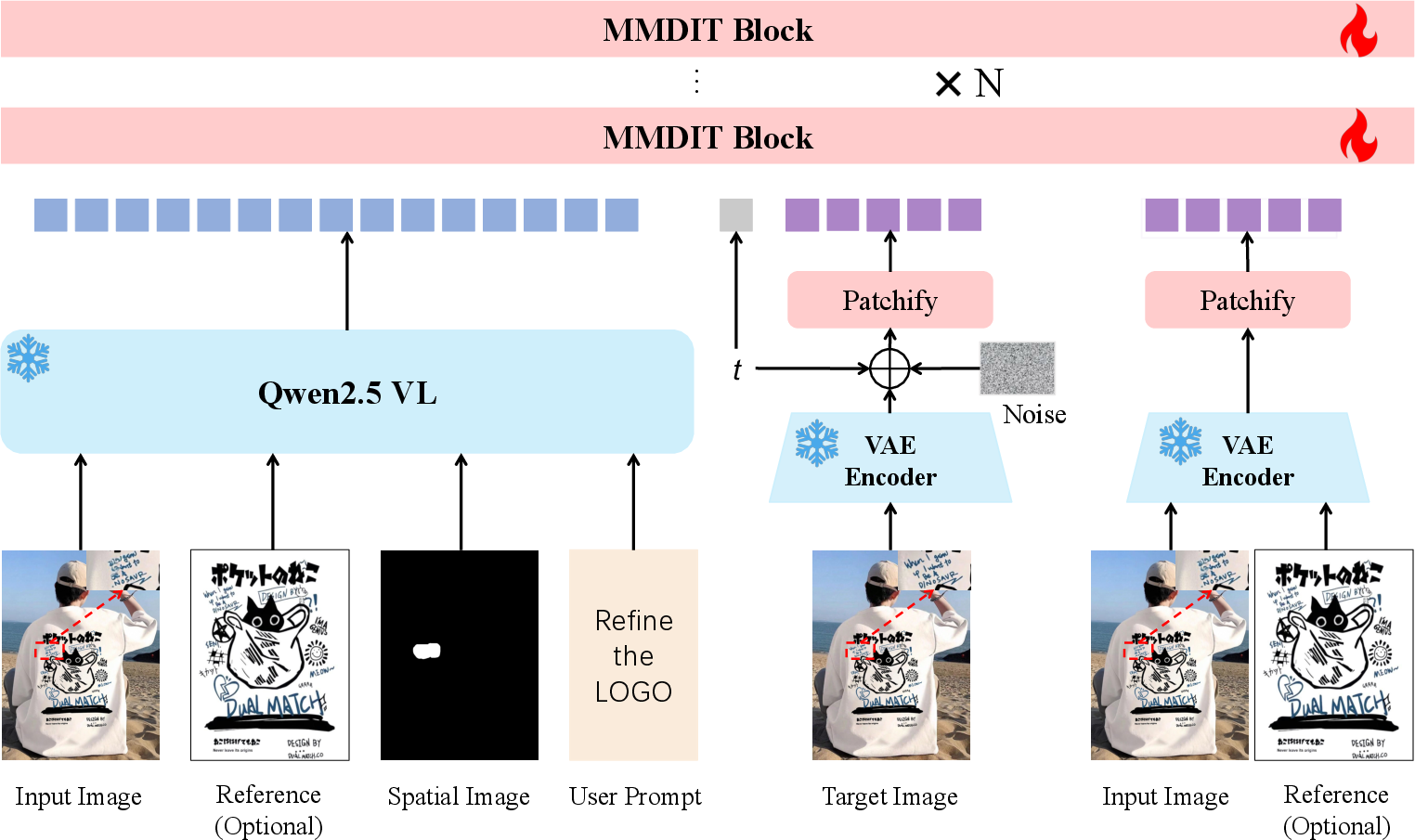
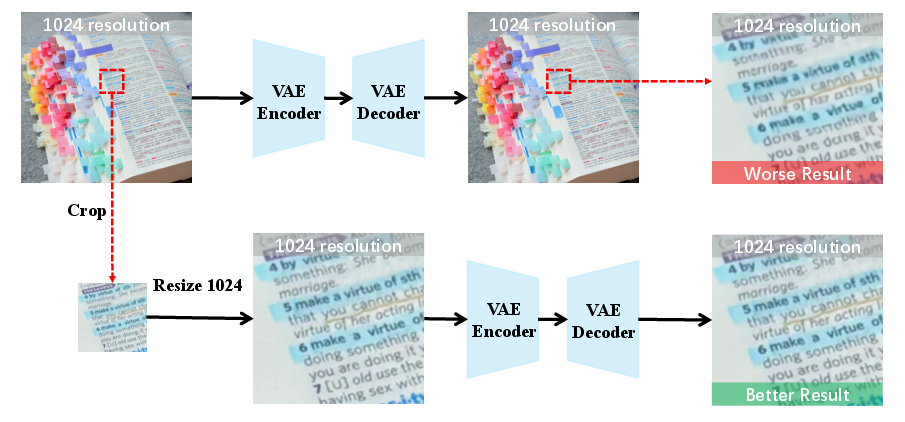
- Crop-and-Resize: Focusing on a region by cropping it and scaling to the model’s input size to improve local reconstruction. "Building on a counter-intuitive observation that crop-and-resize can substantially improve local reconstruction under a fixed VAE input resolution,"
- Denoiser: The network module in diffusion models that iteratively removes noise from latents. "We adopt the MMDiT denoiser from Qwen-Image~\cite{wu2025qwen}."
- Diffusion Transformer: A transformer-based architecture for diffusion models that scales better than UNets. "the community has moved from UNet backbones to better-scaling Diffusion Transformers, such as Hunyuan-DiT~\cite{li2024hunyuandit}, PixArt~\cite{pixart}, SD3~\cite{sd3}, and FLUX~\cite{flux}."
- DINO: A self-supervised vision model used for feature similarity evaluation. "and strengthens semantic alignment with higher DINO~\cite{zhang2022dino,oquab2023dinov2}/CLIP~\cite{clip} similarities"
- Flow-matching denoising objective: A training objective that matches predicted velocity to target flow for diffusion sampling. "Following Qwen-Image~\cite{wu2025qwen}, we adopt the flow-matching denoising objective on the focused crop in latent space."
- Focus-and-Refine: A strategy that refines a focused crop and pastes it back to enforce local detail and background preservation. "We propose Focus-and-Refine and a boundary-aware Boundary Consistency Loss to enable high-quality refinement with seamless paste-back."
- Gaussian smoothing: Applying a Gaussian filter to soften masks or images for seamless blending. "we apply morphological dilation and Gaussian smoothing to obtain a blended mask:"
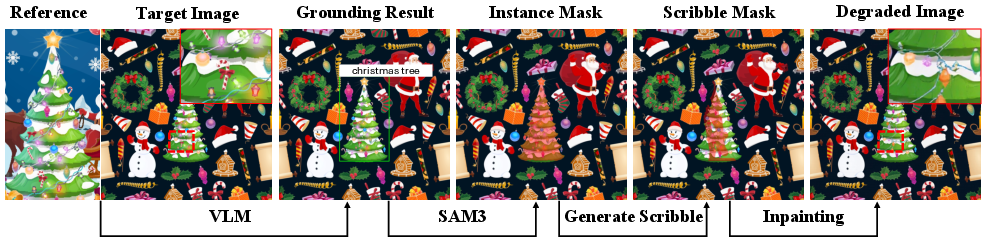
- Grounding (VLM grounding): Using a vision–LLM to localize and align objects across images. "constructed with VLM grounding, SAM-based segmentation, and controlled inpainting degradations"
- Inpainting: Filling or altering selected regions of an image, typically guided by a mask. "we synthesize degraded inputs via inpainting within the annotated regions, using Flux-fill \cite{flux}, SDXL \cite{sdxl}, and Qwen-Edit \cite{wu2025qwen}"
- Joint-attention: A conditioning mechanism that attends jointly to multimodal tokens during denoising. "These tokens provide high-level guidance (e.g., semantics and instruction intent) to the denoiser via joint-attention~\cite{zhou2025dreamrenderer,sd3,li2024hunyuandit,yang2024cogvideox,wu2025qwen}."
- Latent diffusion: Diffusion performed in a compressed latent space (via a VAE) for efficient generation. "the Stable Diffusion family (SD1.5~\cite{stablediffusion}, SDXL~\cite{sdxl}) popularizes latent diffusion,"
- Latent space: A compact representation space produced by encoders (e.g., VAEs) where diffusion operates. "where a variational autoencoder (VAE)~\cite{vae} maps images into a compact latent space for denoising,"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method applied to attention projections. "We fine-tune Qwen-Image-Edit~\cite{wu2025qwen} (2509 version) with LoRA~\cite{hu2022lora}"
- LPIPS: A learned perceptual image similarity metric that correlates with human judgment. "LP stands for the LPIPS metric, and DINO stands for the DINOv2Large metric."
- MMDiT: A multimodal diffusion transformer backbone used as the denoiser. "a diffusion backbone built from MMDiT blocks (trainable, e.g., via LoRA~\cite{hu2022lora,xu2024ctrlora})"
- Mixture-of-Transformers (MoT): An architecture that couples distinct transformer experts for understanding and generation. "BAGEL~\cite{bagel} proposes a Mixture-of-Transformers (MoT) design that couples an understanding model with a generator"
- Morphological dilation: A mask operation that expands regions to provide context or enable blending. "we apply morphological dilation and Gaussian smoothing to obtain a blended mask:"
- Morphological erosion: A mask operation that shrinks regions, often used with dilation to define boundaries. "boundary band uses Eq.~\ref{eq:boundary_band} with dilation/erosion kernel sizes $r_{\text{out}=r_{\text{in}=16$;"
- Multimodal conditioning tokens: Tokenized representations that encode images, region cues, and text for conditioning. "We encode the input (and optional reference) image, the region cue, and the instruction into multimodal conditioning tokens."
- Multimodal encoder: A model that jointly encodes text and images into shared representations. "a frozen multimodal encoder (Qwen2.5-VL~\cite{Qwen2.5-VL})"
- Paste-back: Compositing a refined crop back onto the original canvas, typically with blending to avoid seams. "while a blended-mask paste-back guarantees strict background preservation."
- Patch token sequences: Sequences of tokens formed from image patches and latents for transformer processing. "We pack them with the noisy target latent into patch token sequences and concatenate along the sequence dimension before feeding them into the MMDiT backbone."
- SAM (Segment Anything Model): A segmentation model used to produce object masks from prompts or boxes. "constructed with VLM grounding, SAM-based segmentation, and controlled inpainting degradations"
- Scribble mask: A freeform user-drawn mask indicating the region to edit. "given an input image and a user-specified region (e.g., a scribble mask or a bounding box)"
- Seam artifacts: Visible discontinuities at boundaries between edited and original regions. "We further introduce a boundary-aware Boundary Consistency Loss to reduce seam artifacts"
- Semantic alignment: The degree to which generated content matches intended semantics or references. "and strengthens semantic alignment with higher DINO~\cite{zhang2022dino,oquab2023dinov2}/CLIP~\cite{clip} similarities"
- SSIM: Structural Similarity Index; a perceptual metric for image fidelity. "SSIM~\cite{wang2004imagessim}"
- UNet: A convolutional encoder–decoder backbone historically used in diffusion models. "the community has moved from UNet backbones to better-scaling Diffusion Transformers"
- Upsampling: Increasing the spatial resolution of a cropped region to allocate more model capacity. "cropping a small target region and upsampling it to the same resolution as the full image"
- VAE: Variational Autoencoder; compresses images into latents for efficient diffusion and decodes outputs. "the Stable Diffusion family (SD1.5~\cite{stablediffusion}, SDXL~\cite{sdxl}) popularizes latent diffusion, where a variational autoencoder (VAE)~\cite{vae} maps images into a compact latent space for denoising,"
- VAE latent: The encoded representation of an image in VAE space used for conditioning and generation. "We encode the input and optional reference images into VAE latents as low-level fine-grained visual conditioning:"
- VGG: A deep CNN whose features are used as a perceptual metric for image comparison. "reduce MSE by 0.020 (50\%), LPIPS by 0.109 (41\%), and VGG by 0.139 (26\%),"
- VLM: Vision–LLM; jointly processes images and text for tasks like grounding and evaluation. "We therefore adopt a VLM-based evaluator (Gemini2.5-Pro)"
Collections
Sign up for free to add this paper to one or more collections.