DreamOmni3: Scribble-based Editing and Generation (2512.22525v1)
Abstract: Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
Sponsor


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DreamOmni3, an AI that can edit and create images using three kinds of hints from you: text, pictures, and quick drawings you make by hand (scribbles). Instead of only telling the AI what to change with words, you can draw circles, arrows, or doodles right on the image (or on a blank canvas) to show exactly where and what you want. This makes image editing and generation much clearer, faster, and more creative.
What questions did the researchers ask?
The team focused on three simple questions:
- How can we let users point to the exact place to edit without struggling to describe it in words?
- How can we train an AI to understand and follow scribbles, text, and images together?
- What model design works best for handling many scribbles and complex edits without getting confused?
How did they do it?
To make this work, the researchers needed both training data and a smart model design.
Creating training data (teaching examples)
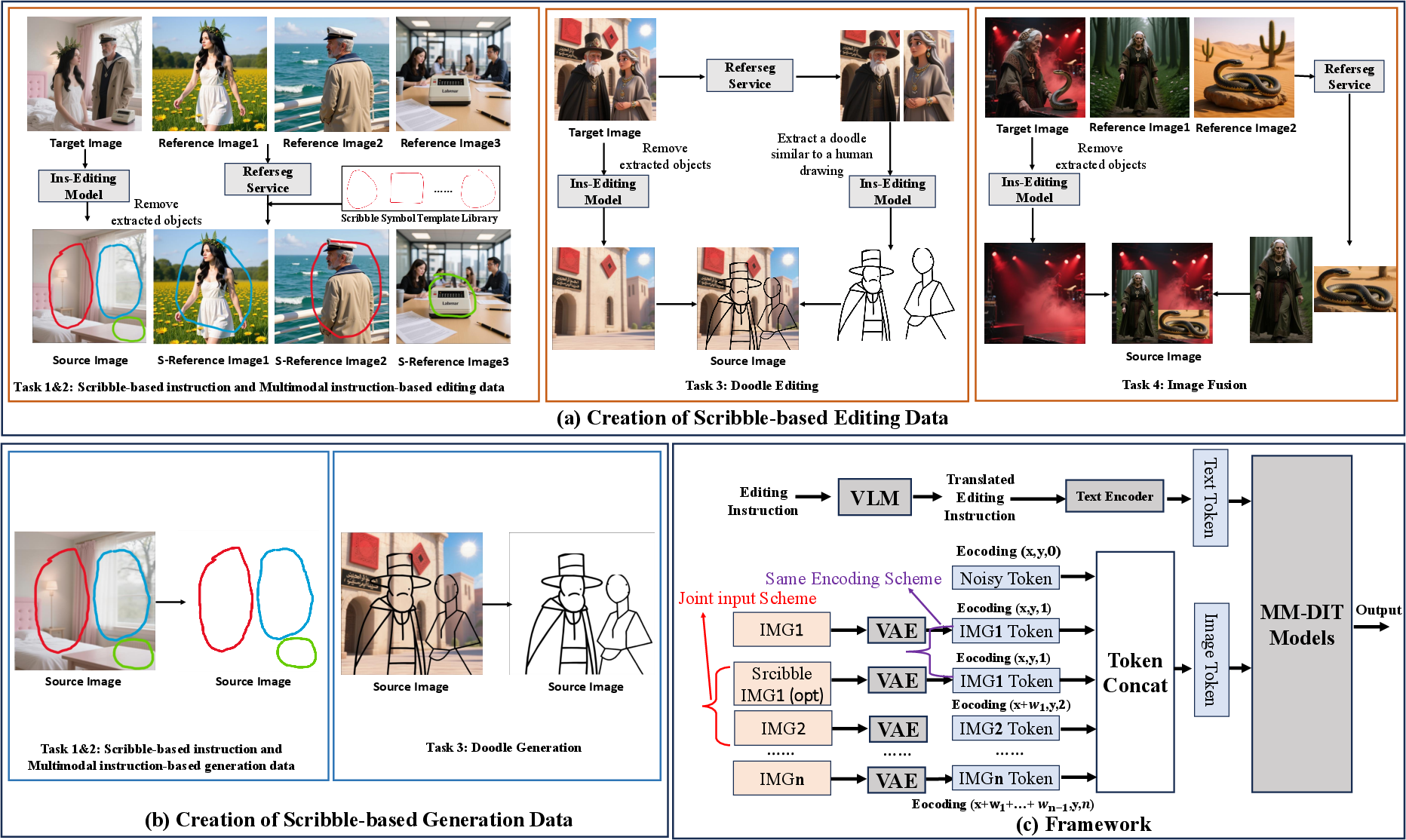
They built a big set of examples where scribbles are used as instructions. Imagine a teacher giving the AI lots of before-and-after images, plus the scribbles and words that explain what changed. They created seven types of tasks:
For editing existing images:
- Scribble + text editing: You draw on the photo and describe the change (like “make this car red” with a circle around the car).
- Scribble + text + reference image: You also show another image as a style or object example (e.g., “make this dress look like the dress in the reference photo”).
- Image fusion: Cut an object from one image and place it into another, guided by scribbles.
- Doodle editing: You draw a simple sketch (a doodle) where the new object should go, and the AI fills it in realistically.
For generating new images from scratch:
- Scribble + text generation: Draw shapes on a blank canvas and describe what they should become.
- Scribble + text + reference image generation: Do the same, but also provide a reference picture to match style or details.
- Doodle generation: Place a quick sketch on a blank canvas and let the AI turn it into a full scene.
They used tools to automatically find objects in images and then overlaid hand-drawn shapes (like messy circles or boxes) to simulate real scribbles. This gave the AI lots of practice examples.
How the model understands scribbles (the “joint input” idea)
A common older method is to give the AI a “mask” that’s black-and-white: white = “change here,” black = “don’t touch.” That’s like telling someone, “Color only inside these exact lines.” Masks get messy if you have many areas to edit, and they don’t say much about intent.
DreamOmni3 does something more natural:
- It feeds the AI two images at once: the original image and a copy with your colored scribbles drawn on top. Think of placing two transparent sheets on top of each other: one clean photo, one with your marks.
- The colors in your scribbles help the AI tell different regions apart (red circle = change the hat, blue arrow = move the lamp).
- To make sure the AI lines things up perfectly between the clean image and the scribbled one, it uses matching “position labels” on both images. You can think of these like matching grid lines on two maps so every spot matches exactly.
This design is simpler than handling many separate masks and works smoothly with existing image-editing AIs that expect normal color images.
How they tested it
They built a new benchmark (a test set) with real photos and tasks covering all seven scribble scenarios. They checked:
- Did the AI follow the instructions?
- Did people and objects stay consistent (no weird faces or wrong sizes)?
- Were there no obvious visual glitches?
- Did the changes match the scribbled areas?
They used both human judges and smart vision-LLMs (computers that can “look” and “read”) to score results.
What did they find?
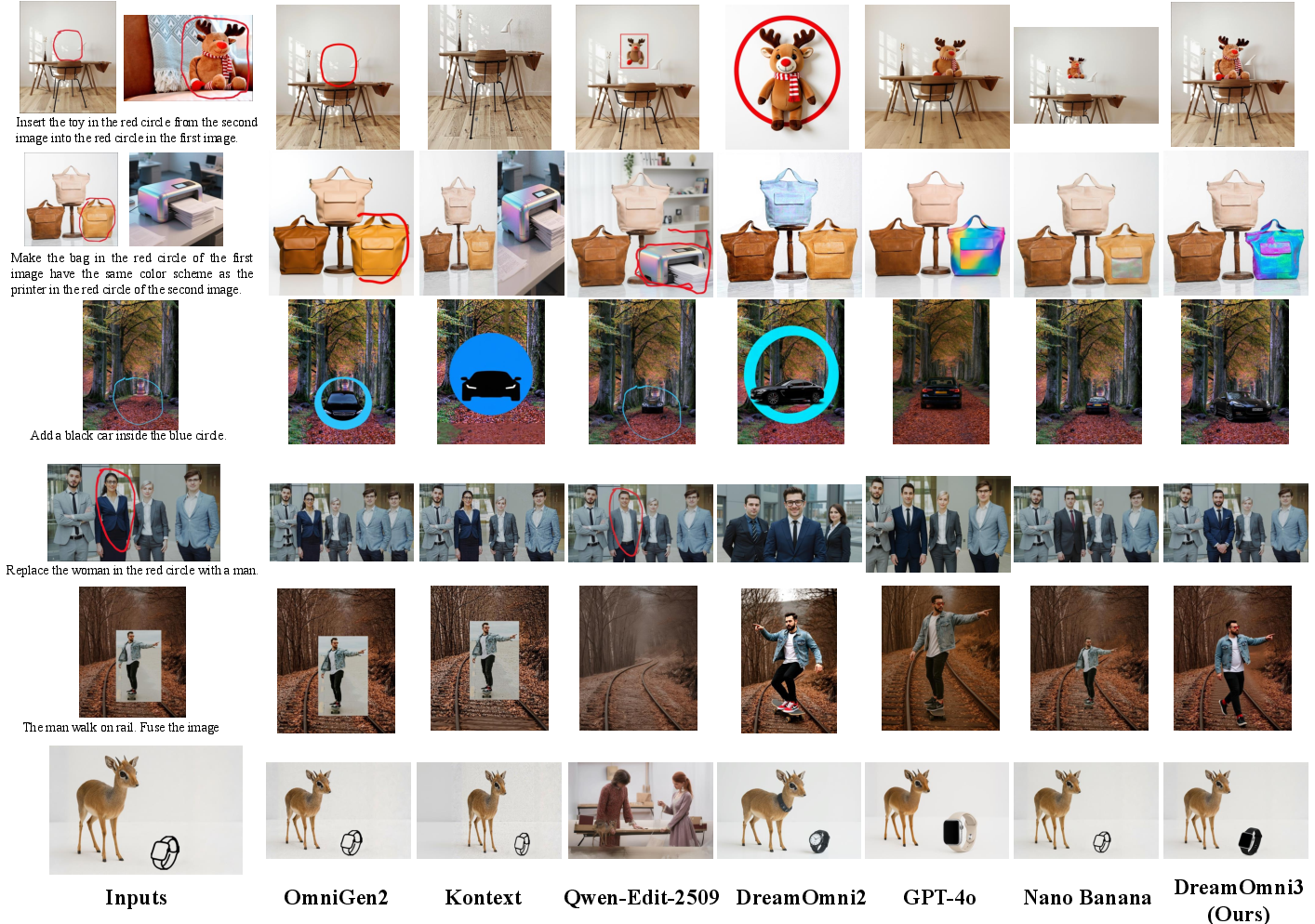
- DreamOmni3 handled scribble-based editing and generation better than several strong open-source models and was competitive with well-known commercial systems.
- The “joint input” trick (giving the clean image plus the scribbled version) clearly improved editing quality, especially when many scribbles were involved.
- Using the same “position labels” for both images helped the model keep details aligned, leading to more accurate and consistent edits.
- Other models often left scribble marks in the final image or made parts look copy-pasted. DreamOmni3 was better at removing the marks and producing natural-looking results in the right places.
Why does this matter?
This work makes image creation and editing more like real drawing and less like programming. Instead of struggling to describe the exact spot to edit, you just point and sketch. That means:
- Easier, faster, and more precise edits for everyday users, designers, and students.
- Smoother creative workflows on tablets and touch screens—draw a shape, write a note, and the AI understands.
- A strong foundation for future tools that mix words, pictures, and drawings in one simple interface.
In short, DreamOmni3 brings us closer to AI tools that understand how people naturally communicate visual ideas—by circling, doodling, and showing, not just telling.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps, limitations, and open questions that the paper does not resolve, framed to guide future research:
- Data realism: The training data relies heavily on synthetic scribbles (a library of ~30 squares/circles) and model-generated doodles (GPT-Image-1), rather than large-scale, diverse, real human scribbles collected from GUIs across devices. How well does DreamOmni3 generalize to truly freehand, noisy, multi-stroke, multi-shape scribbles?
- Scribble vocabulary coverage: The paper focuses on circles/boxes and abstract sketches; it does not address common GUI marks such as arrows, underlines, lasso selections, cross-outs, hatching, fill sweeps, gesture strokes (e.g., “move here”), or text annotations. What extensions are needed to interpret these broader scribble semantics?
- Dependency on proprietary services: Data creation depends on Referseg/Refseg (not specified/defined) and GPT-Image-1. Replicability, licensing, and reproducibility risks remain unaddressed. Can open-source replacements achieve comparable quality, and how sensitive is performance to these components?
- Scribble intent parsing: Beyond using color-coded overlays, the method does not specify an algorithm for mapping multiple scribbles to the correct objects/attributes when instructions are ambiguous or when scribbles overlap. How should multi-scribble disambiguation be formalized (e.g., per-scribble referential grounding, color-to-entity mappings, spatial relations)?
- Overlapping/occlusive scribbles: Failure modes when scribbles occlude critical content (in source or references) are not analyzed. How does performance degrade with increasing scribble coverage, thickness, opacity, and overlap?
- Joint input design details: The paper does not describe how the source and scribbled-source images are fused inside MM-DiT (e.g., token concatenation order, cross-image attention, normalization). Without these details, replicability and extensibility are limited.
- Encoding choices vs alternatives: While same index and position encodings improved results, the paper does not compare against stronger alignment mechanisms (e.g., learned cross-image registration, correspondence heads, spatial transformer blocks, or scribble-specific embeddings). What architectures best support pixel-aligned joint inputs?
- Reference-image scribbles: The joint input is explicitly avoided for reference images, even though scribbles there can obscure cues. Under what conditions would joint input for references help, and how can we balance cost vs benefit?
- Evaluation metrics: Success is assessed via VLM pass/fail and human approval rates, without objective measures of edit localization or preservation. Researchers need standardized metrics such as:
- IoU/Dice between intended scribble region and actual edited region.
- Pixel preservation metrics (e.g., LPIPS/SSIM in non-edited areas).
- Scribble removal rate in outputs (for generation tasks).
- Per-category success rates and confusion matrices for abstract attributes vs concrete objects.
- VLM evaluation reproducibility: The system prompts, variance across runs/models, calibration to human judgments, and inter-annotator agreement are not detailed. How can VLM-based evaluation be standardized and made reproducible?
- Train–test separation and leakage: The paper does not state precautions against overlap between training and benchmark images or object categories. Is generalization to out-of-distribution domains, objects, and styles preserved?
- Dataset scale and diversity: With ~80K editing and ~47K generation samples, task coverage and domain diversity (e.g., products, indoor/outdoor, art/illustration, medical/design) are unspecified. How much scaling and broader domain inclusion are required to reach robust performance?
- Contextual realism claims: The paper claims improved reasoning about lighting/shadows/reflections but provides no targeted evaluation of such environmental consistency. Can a benchmark quantify context-aware edits (shadows cast, material consistency, global color balance)?
- Efficiency and latency: Joint input doubles image inputs and likely increases memory/computation, but inference speed, GPU footprint, and interactive latency are not reported. How can the method be optimized for real-time GUI use?
- Multi-turn interactivity: The paper does not study iterative workflows (e.g., successive scribbles and edits in a session), state management, undo/redo, or compounding errors. What architectures and training protocols support robust multi-step interactions?
- Activation logic for LoRA: The paper states that the LoRA “activates” when a scribbled image is input, but detection and fallback logic are unspecified. How is activation triggered (heuristics, metadata, learned gating), and what are misactivation rates?
- Single-model unification: Generation and editing capabilities are trained with separate LoRAs. What are the trade-offs and failure modes of merging them into a single unified LoRA or base model fine-tune?
- Robustness to device/input variability: Thickness, pressure, jitter, resolution, color gamut differences across stylus/mouse/touch inputs are not studied. What normalization strategies are needed for cross-device robustness?
- Color coding limitations: The approach depends on scribble colors for disambiguation; it does not cover color-blindness, color collisions, or inconsistent color spaces. What non-color encodings (shape, labels, stroke patterns) can improve reliability?
- Generative fidelity in fusion: Image fusion uses cropping/resizing without explicit geometry/illumination harmonization (e.g., shading, perspective, scale context). How can harmonization (relighting, geometric alignment, shadow synthesis) be integrated and evaluated?
- Failure analysis of DreamOmni3: The paper describes issues in other models (e.g., “yellowing,” collage artifacts) but not DreamOmni3’s own typical errors. A taxonomy of DreamOmni3 failure modes would guide targeted fixes.
- Zero-instruction scribble-only tasks: While “doodle” tasks exist, rigorous evaluation of purely scribble-driven edits/generation (no text) is absent. How far can the system go with scribble-only intent, and how should ambiguity be handled?
- Security/adversarial marks: The system’s susceptibility to adversarial scribbles (e.g., carefully crafted strokes that cause undesired edits) is not studied. What defenses or validation steps are needed?
- Ethical and safety considerations: Face editing, identity preservation, and bias/fairness across demographics are only briefly mentioned via “consistency” checks. What safeguards and audits should be implemented for responsible deployment?
- Benchmark transparency: The benchmark composition, category distribution, and prompts are deferred to the supplementary. A clear, publicly documented, and versioned benchmark (with licenses, stats, and evaluation scripts) is needed for community comparability.
- Cross-architecture generality: The solution is tailored to Kontext/MM-DiT. How transferable are the joint-input and encoding schemes to other backbones (e.g., SDXL, PixArt-α, LDMs with ControlNets, diffusion transformers with different tokenizers)?
- Video and 3D extension: The method targets images; scribble-driven video editing/generation and 3D scene control remain open, with challenges in temporal coherence and spatial consistency.
- Scalability studies: No scaling-law or data-ablation analyses are provided (e.g., performance vs dataset size, variety of scribble types, number of scribbles per image). Which data dimensions most impact performance?
- UI/UX validation: Usability studies (e.g., how intuitive color-coding is, error rates, time-to-success, perceived control) are missing. What interaction designs maximize user intent capture and minimize confusion?
These gaps suggest concrete directions: building large, real human-scribble datasets; designing robust scribble semantics and disambiguation; standardizing objective evaluation of localization and preservation; optimizing joint-input architectures and efficiency; and expanding to richer modalities and interactive workflows.
Glossary
- AGI: Artificial general intelligence; a general-purpose, human-level AI capability. "They exhibit strong multimodal understanding, responding to real-world visuals, marking progress toward world models and AGI."
- attention module: A neural network component that refines feature interactions by focusing on relevant parts of the input. "GLIGEN~\cite{gligen} improved this by introducing an attention module and encoding bounding boxes through Fourier embeddings."
- binary masks: Pixelwise binary maps indicating regions to edit or preserve. "For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme..."
- Canny edge detection: A classic algorithm for detecting edges in images using gradients and non-maximum suppression. "We avoid using Canny edge detection due to users' imperfect drawings, which require aesthetic corrections from the model."
- CLIP: A vision-LLM that aligns images and text embeddings for similarity-based evaluation. "Traditional metrics, such as DINO~\cite{dino} and CLIP~\cite{clip}, are not sufficient to accurately evaluate the complex and diverse instruction-based editing and generation tasks we propose~\cite{dreambench++}."
- compressed object IDs: Compact identifiers representing objects’ features for insertion or control within masked regions. "(3) Some approaches~\cite{smartmask,mao2025ace++,insertanything} inject compressed object IDs from a reference image into the masked region to insert specific objects."
- DINO: A detection/recognition framework often used as an evaluation proxy; here, deemed insufficient for complex edits. "Traditional metrics, such as DINO~\cite{dino} and CLIP~\cite{clip}, are not sufficient to accurately evaluate the complex and diverse instruction-based editing and generation tasks we propose~\cite{dreambench++}."
- doodle editing: Editing by inserting or transforming content guided by abstract sketches. "For doodle editing, we crop the edited objects from the target image, generate sketches, and place them back into the source image."
- doodle generation: Generating images or content from user-provided sketches on a canvas. "For doodle generation, we extract the edited objects from the target image, generate sketches, and place them on a blank canvas at the same position."
- edge maps: Binary or sparse representations emphasizing image edges to guide editing or preservation of structure. "MagicQuill~\cite{magicquill} introduces auxiliary inputs such as edge maps or low-resolution images to help maintain contour and color consistency."
- Fourier embeddings: Encodings that map coordinates (e.g., boxes) into a higher-dimensional space using sinusoidal functions to aid spatial conditioning. "GLIGEN~\cite{gligen} improved this by introducing an attention module and encoding bounding boxes through Fourier embeddings."
- grounding resampler: A module that aligns (grounds) visual features to specified entities and spatial constraints. "MS-diffusion~\cite{ms-diffusion} employs a grounding resampler to associate visual information with specific entities and spatial constraints."
- image fusion: Combining content from a reference image into a source image at specified locations. "For image fusion, we extract the edited objects from the reference image and paste them onto the corresponding position on the source image."
- Image inpainting: Filling in or regenerating selected regions of an image while maintaining surrounding context. "Image inpainting~\cite{diffir,smartbrush,Paintbyexample,dreamomni,llmga} is a common technique where users paint over the area they wish to modify."
- index encoding: A learned or fixed identifier embedding used to distinguish multiple input images/channels. "we use the same index encoding and position encoding scheme for both the source image and the scribbled source image."
- joint input scheme: Feeding both the original and annotated (e.g., scribbled) versions of an image to the model to preserve details and convey intent. "we propose a joint input scheme that feeds both the original and scribbled source images into the model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small low-rank updates into large models. "We train our model using LoRA with a rank of 256."
- Mask-based Editing: Editing workflows that operate within user-specified masked regions. "Mask-based Editing refers to editing operations performed on selected regions or items of an image."
- Mask-based Generation: Generative image workflows constrained to or guided by given masks. "Mask-based Generation incorporates masks into the image generation process to control content within specific regions."
- MM-DIT models: Multimodal Diffusion Transformer models that process images (and possibly text) within a diffusion framework. "we input both the source image and the scribbled source image into the MM-DIT models."
- multimodal instruction-based editing: Editing guided by combined modalities (e.g., text plus images) rather than text alone. "we categorize scribble-based editing into four types: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing."
- multimodal instruction-based generation: Generation guided by multiple input modalities (e.g., text and images). "we categorize scribble-based generation into three types: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation."
- position encoding: Spatial encodings added to model inputs to retain location information. "we use the same index encoding and position encoding scheme for both the source image and the scribbled source image."
- position shift: A spatial offset applied in encoding to distinguish different image roles or avoid pixel confusion. "for the reference image, to distinguish it from the source images and avoid pixel confusion, we adopt the same position shift and index encoding scheme as in DreamOmni2 (Fig.~\ref{fig:method}~(c))."
- Referseg: A referencing/segmentation service used to locate objects for editing or generation. "We use Referseg service to locate the editing objects in both the reference and target images."
- scribble-based editing: Editing that leverages user-drawn marks to indicate regions, objects, or intentions. "We introduce two highly useful tasks for unified generation and editing models: scribble-based editing and scribble-based generation."
- scribble-based generation: Generating images conditioned on user scribbles that specify layout or content. "We introduce two highly useful tasks for unified generation and editing models: scribble-based editing and scribble-based generation."
- Subject-driven generation: Generation that preserves or targets a specific subject’s identity or attributes. "The current unified generation and editing models primarily focus on instruction-based editing and subject-driven generation."
- Vision LLMs (VLMs): Models that jointly process and reason over visual and textual inputs. "These issues are difficult for Vision LLMs (VLMs) to detect accurately."
- world models: Internal models that capture aspects of the real world to support understanding and reasoning in AI systems. "They exhibit strong multimodal understanding, responding to real-world visuals, marking progress toward world models and AGI."
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging DreamOmni3’s scribble-aware multimodal editing/generation, joint input scheme (original + scribbled image), and image fusion/doodle capabilities.
- Scribble-first plugins for creative tools (software, design)
- Sectors: software, media/advertising, product design
- Tools/products: “DreamOmni3 Brush Edit” plugin for Photoshop/Procreate/Figma/Canva
- Workflow: users draw color-coded scribbles to mark regions; add text/image instructions (e.g., “make the circled sofa mid‑century green”); the joint input preserves non-edited pixels and applies edits precisely; multi-reference images enable object/style transfer.
- Assumptions/dependencies: model weights and license availability; GPU (or strong CPU) inference; UI support for color-coded scribbles; integration with existing asset pipelines.
- E‑commerce product imagery editing (marketing, retail)
- Sectors: e‑commerce, marketing
- Tools/products: “Product Visual Editor” integrated into CMS/DAM; batch variant generation
- Workflow: merchandisers scribble to recolor areas, add a logo from a reference image, or insert accessories via image fusion; export watermark-bearing variants for A/B testing.
- Assumptions/dependencies: brand safety guardrails; rights for reference assets; QC to avoid misleading imagery; scalable inference for catalog volume.
- Real estate/interior staging (property tech, design)
- Sectors: real estate, interior design
- Tools/products: “Instant Staging” app for listings; design consult tools
- Workflow: agents/designers circle walls/furniture to change color/style; insert reference furniture; generate photoreal outputs while preserving non-edited regions.
- Assumptions/dependencies: disclosures for edited listings; content provenance/watermarks; domain-tuned prompts or LoRA for indoor scenes.
- Education and classroom creativity (academia, edtech, daily life)
- Sectors: education, edtech
- Tools/products: “Doodle Classroom” for LMS; children’s art apps
- Workflow: learners doodle on a white canvas; the model generates full scenes or objects aligned to the sketch and instruction (e.g., “turn this doodle into a coral reef”); teachers scaffold visual storytelling or concept illustration.
- Assumptions/dependencies: content filters; safe-image constraints; low-compute versions for school devices; age-appropriate UX.
- Rapid UI/mockup generation (software design)
- Sectors: software, UX/UI
- Tools/products: Figma plugin for wireframe-to-visual mockups
- Workflow: designers scribble component regions (buttons/cards/hero image), provide style references, and generate high-fidelity mockups; iterate by re‑scribbling multiple colored regions.
- Assumptions/dependencies: domain adaptation for UI imagery; consistent symbol/color mapping; asset reuse compliance.
- Dataset synthesis and augmentation via scribbles (academia, ML R&D)
- Sectors: academia, software
- Tools/products: open-source pipeline built on DreamOmni3 + Refseg to create controlled edit/generation datasets
- Workflow: researchers scribble to localize objects and systematically alter attributes (color/shape/context), producing paired data for training detection/segmentation/editing models.
- Assumptions/dependencies: availability of Refseg-equivalent services; licensing for DreamOmni2/3 data; reproducible scripts and evaluation harnesses.
- Mobile social photo editing (daily life)
- Sectors: consumer apps
- Tools/products: smartphone editor to remove photobombers, change outfits, add props
- Workflow: users circle a distractor to remove, doodle a desired accessory, or fuse an object from a reference image; export/share with visible provenance options.
- Assumptions/dependencies: efficient on-device/edge inference or cloud backends; privacy handling; robust artifact suppression.
- Generative model auditing with DreamOmni3 benchmark (policy, platform safety)
- Sectors: platform safety, standards
- Tools/products: evaluation suite using the DreamOmni3 benchmark + VLM-based checks; “pass-rate” dashboards
- Workflow: teams run models through scribble-based tasks to assess instruction-following, region alignment, artifact rates; compare to human ratings.
- Assumptions/dependencies: acceptance of VLM-based metrics; transparent reporting; alignment with internal content policy.
Long-Term Applications
Below are forward-looking use cases that require further research, scaling, domain adaptation, or policy/regulatory development.
- Real-time video scribble editing and AR overlays (media production, XR)
- Sectors: film/TV, AR/VR
- Tools/products: “Live Doodle Edit” for video; AR scene editing via color-coded gestures
- Workflow: creators scribble on live video frames to change props, styles, or lighting; temporal consistency and latency constraints ensure smooth output.
- Assumptions/dependencies: high-throughput inference; temporal training (extending DreamOmni3/DreamVE); robust tracking; low-latency hardware.
- In-situ AR/VR co‑creative interior and architectural design (design, retail)
- Sectors: architecture, furniture retail
- Tools/products: headset-based environment editor; 3D asset fusion
- Workflow: users mark surfaces/objects in mixed reality and apply reference styles or insert catalog items; render physically plausible results in 3D.
- Assumptions/dependencies: 3D-aware generation; spatial mapping; lighting/shadow consistency; safety and usability testing.
- Healthcare education and planning (medical training, publishing)
- Sectors: healthcare, medical education
- Tools/products: anatomy teaching set builder; surgical planning mock-ups
- Workflow: educators scribble regions on diagrams or anonymized scans to generate teaching materials or simulate variations; strict watermarking and provenance maintained.
- Assumptions/dependencies: no diagnostic use; regulatory compliance; strong domain constraints; ethics review; dataset de-identification.
- Human-robot interaction via visual scribble grounding (robotics, manufacturing)
- Sectors: robotics, industrial automation
- Tools/products: HRI interface where operators mark objects/areas on camera feeds to instruct pick-and-place or inspection
- Workflow: operators color-code multiple targets; model grounds scribbles to objects and relays tasks; robot executes with feedback.
- Assumptions/dependencies: precise spatial grounding; integration with control stacks; safety protocols; real-time performance.
- Accessibility-first visual communication (public services, education)
- Sectors: accessibility, public sector
- Tools/products: assistive editor for non-verbal or low-literacy users
- Workflow: users convey intent via scribbles/doodles; system generates visual messages, instructions, or edited content aligned to the marks.
- Assumptions/dependencies: inclusive UX design; content safety; affordable deployment; language-independent evaluation.
- Enterprise DAM with audit-ready regional edit provenance (marketing ops, compliance)
- Sectors: enterprise marketing, compliance
- Tools/products: “Scribble Provenance” layer tracking color-coded regions, instructions, references, and outputs
- Workflow: teams co-edit assets; every regional change is logged with colors/indices; approvals and rollback supported.
- Assumptions/dependencies: standardized metadata schemas; regulatory buy-in; watermarking and disclosure norms.
- Standards and regulation for scribble-driven image manipulation (policy, governance)
- Sectors: policy, standards bodies
- Tools/products: guidelines for disclosure, watermarking, and auditing of regional edits; benchmark-based certification
- Workflow: platforms adopt clear signals indicating edited regions; regulators use evaluation suites to audit content integrity.
- Assumptions/dependencies: multi-stakeholder consensus; international alignment; robust, open benchmarks.
- Edge/on-device deployment via distillation and LoRA activation (software, mobile)
- Sectors: mobile, embedded systems
- Tools/products: compressed DreamOmni3 variants; task-specific LoRA packs
- Workflow: apps load lightweight base models and activate small LoRAs for scribble tasks; preserve privacy and reduce latency.
- Assumptions/dependencies: model compression/distillation research; hardware acceleration; memory/compute constraints.
- Multi-user collaborative co-editing with conflict resolution (enterprise, creative suites)
- Sectors: creative collaboration, SaaS
- Tools/products: real-time multi-scribble editors with per-user color channels and consensus tools
- Workflow: teams concurrently mark regions; the system resolves overlaps and merges intents; version control tracks changes.
- Assumptions/dependencies: concurrency control, identity mapping to colors/indices; network latency handling.
- Cross-modal training resources for spatial grounding (academia, ML)
- Sectors: academia, ML research
- Tools/products: large-scale scribble-text-image datasets for grounding “where” + “what”
- Workflow: build datasets where colored scribbles encode region semantics; train VLMs/diffusion to improve controllable generation and detection.
- Assumptions/dependencies: dataset scale and diversity; annotation quality; open licensing; benchmark evolution.
Collections
Sign up for free to add this paper to one or more collections.