- The paper introduces a novel fine-grained calibration technique that leverages token-level probabilities to enhance LLM-based automated code revision.
- It demonstrates that minimum token probability outperforms global sequence-level measures, yielding lower calibration errors and stronger rank correlations.
- Local Platt-scaling adapts calibration to diverse code revision tasks, improving bin coverage and supporting reliable developer-AI interactions.
Fine-Grained Confidence Calibration in LLM-Based Automated Code Revision
Introduction and Motivation
LLMs have become central to automating code revision tasks, encompassing program repair, vulnerability mitigation, and code refinement. However, their tendency to generate incorrect outputs remains a barrier to seamless incorporation into developer workflows. Accuracy alone is insufficient for dependable integration: models must also produce well-calibrated confidence scores that transparently reflect the empirical likelihood of correctness. This enables downstream applications—including thresholding, abstention, and expectation management by human users.
Existing work in calibration has largely concentrated on sequence-level statistics, with global Platt-scaling as the dominant post-hoc technique. However, this paradigm fails to address the unique attributes of code revision, where correctness stems from local edit decisions rather than global sequence characteristics. This work hypothesizes and empirically demonstrates that fine-grained, locally sensitive calibration is crucial for the reliable deployment of LLMs in code revision pipelines.
Methods: Confidence Scores and Calibration Paradigms
Sequence-Level vs. Fine-Grained Confidence Scores
Traditional approaches employ sequence-level statistics—normalized sequence likelihood (a geometric mean of per-token probabilities) and average token probability (an arithmetic mean over the sequence). These methods do not sufficiently capture outlier low-confidence edit locations that often determine overall correctness. In response, three fine-grained measures are proposed:
- Minimum Token Probability: Sensitive to the least confident token, reflecting the “weakest link” in the generation.
- Lowest-K Token Probability: Averages the K lowest per-token probabilities (where K is adaptively selected via the Kneedle algorithm), making the score robust to occasional under-confident tokens.
- Attention-Weighted Uncertainty: Weighs token-level uncertainties by downstream attention mass, prioritizing influential edit sites.
This shift from global sequence aggregates to local statistics uncovers granular uncertainty signals tied directly to edit operations.
Local Platt-Scaling
Conventional Platt-scaling is global: a single scalar mapping for all samples in a task, assuming calibration homogeneity. This fails in scenarios with heterogeneous input distributions, as in code refinement tasks where natural covariate shift and diversity are pronounced.
Local Platt-scaling addresses this by employing a clustering procedure (HDBSCAN over UMAP-projected Qwen3-Embedding-8B representations of input/output pairs and raw confidence scores) to partition the validation set into subpopulations, each with a dedicated calibrator. For out-of-cluster samples, a backoff to the global calibrator or uncalibrated score is used.
Experimental Design
Tasks and Datasets
Three automated code revision tasks are targeted:
- Program Repair (DCF-Bug): Fixing conventional bugs in JavaScript/TypeScript repositories.
- Vulnerability Repair (DCF-Vul): Patching security-relevant defects.
- Code Refinement (CR-Trans): Addressing human code review feedback, with substantial linguistic and code diversity.
Multiple correctness metrics are used: exact match (EM), edit progress (EP), and (for vulnerabilities) checks passed via SAST.
Model Suite and Evaluation
The analysis covers 14 open-source, instruction-tuned LLMs, with parameter counts from 7B to 72B, from families heavily utilized in code tasks (Llama, CodeLlama, Qwen, DeepSeek). Standardized zero-shot prompting, deterministic decoding, and uniform evaluation settings ensure comparability.
Key calibration metrics include expected calibration error (ECE), Brier score (B), and bin coverage (BC), capturing both instance-level mismatch and practical ability to threshold over a range of confidences.
Empirical Results
Statistical Foundations
Token-level probability distributions in generated revisions are strongly negatively skewed across models and tasks, as shown by pronounced negative median skewness (Figure 1). Low-probability tokens are rare but highly influential, highlighting the need for fine-grained confidence measures that do not average out these signals.
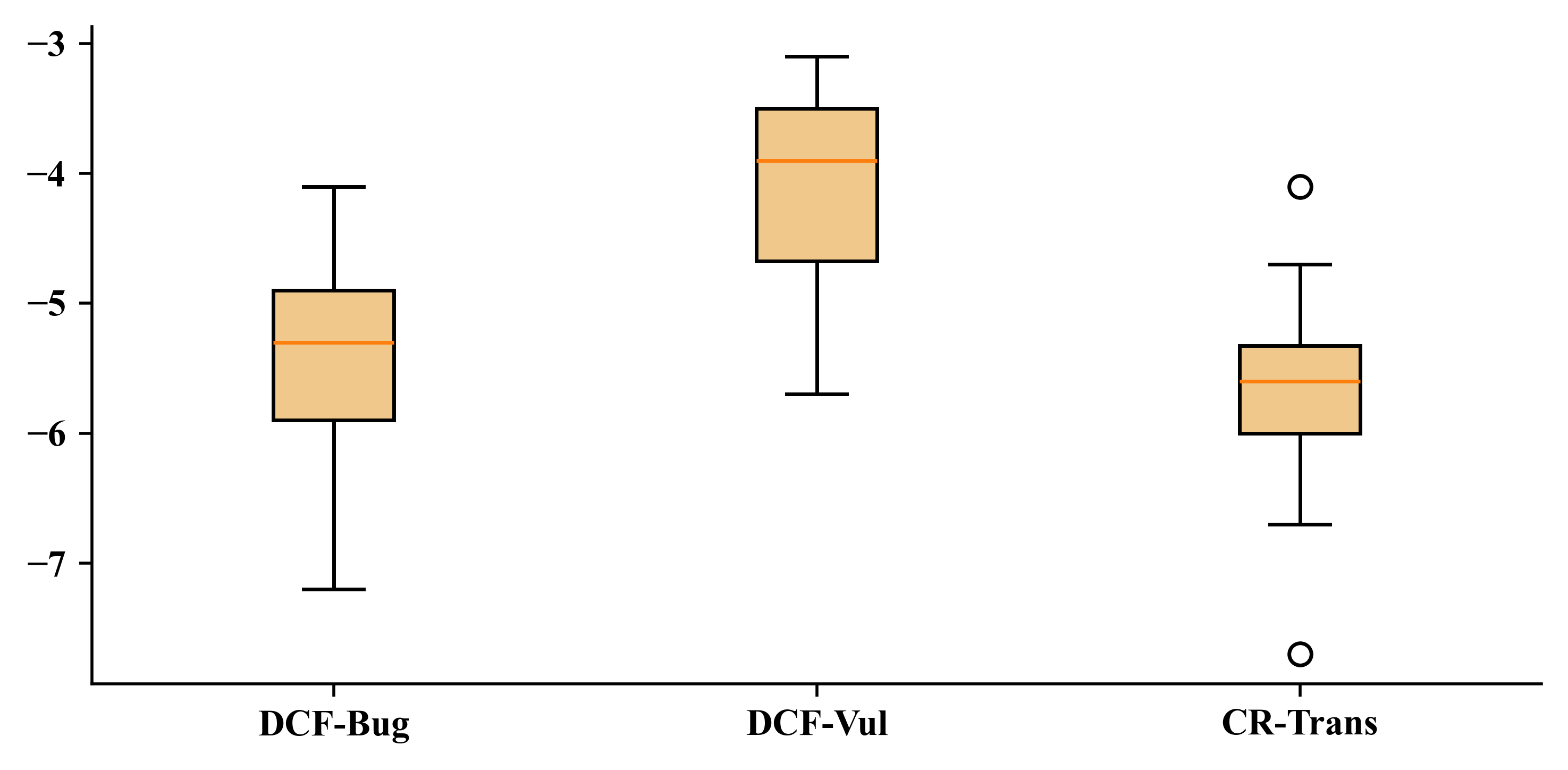
Figure 1: The median skewness γ~1 of token-level softmax probabilities confirms that LLM generations feature clusters of high-probability tokens and rare low-probability outliers, supporting the case for fine-grained confidence metrics.
Fine-grained scores (notably minimum token probability) yield significantly greater separation (higher Wasserstein W1) and stronger rank correlation (Kendall’s τb) between correct and incorrect generations compared to sequence-level scores, across benchmarks (Figures 3–8).
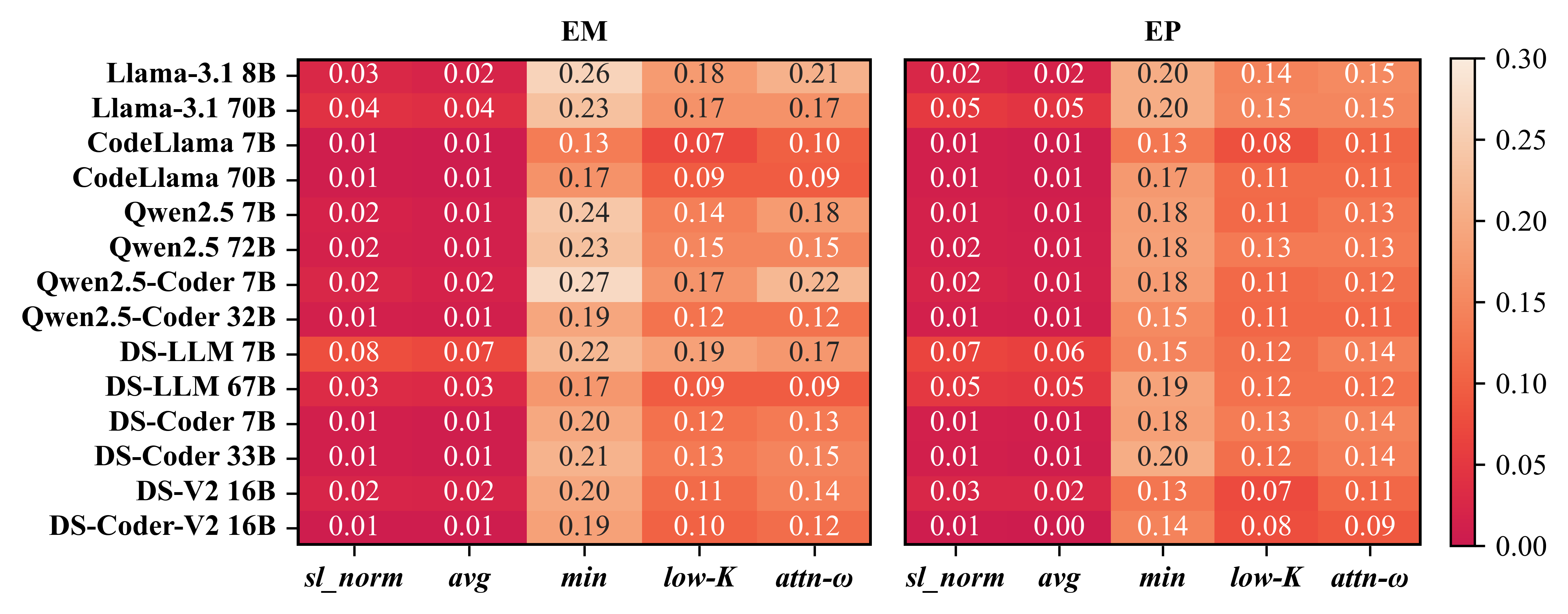
Figure 2: Fine-grained scores achieve higher Wasserstein W1 values in DCF-Bug, indicating better separation between correct/incorrect revisions.
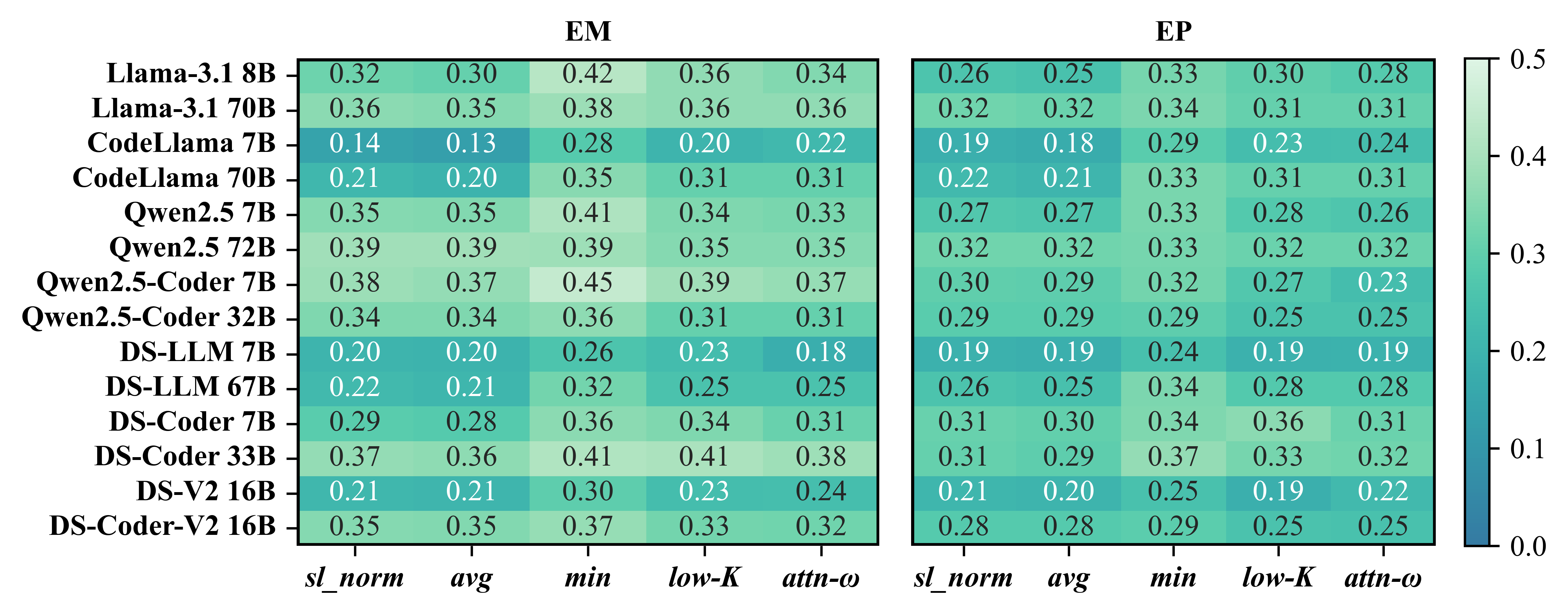
Figure 3: Kendall’s τb shows fine-grained scores better rank correct revisions above incorrect ones in DCF-Bug.
Calibration Under Global and Local Platt-Scaling
Global Platt-Scaling
Fine-grained confidence scores consistently yield lower ECE and Brier error as well as higher bin coverage (up to nine of ten bins), avoiding the “single bin collapse” frequently seen with sequence-level statistics, which precludes practical thresholding (see Figure 4).
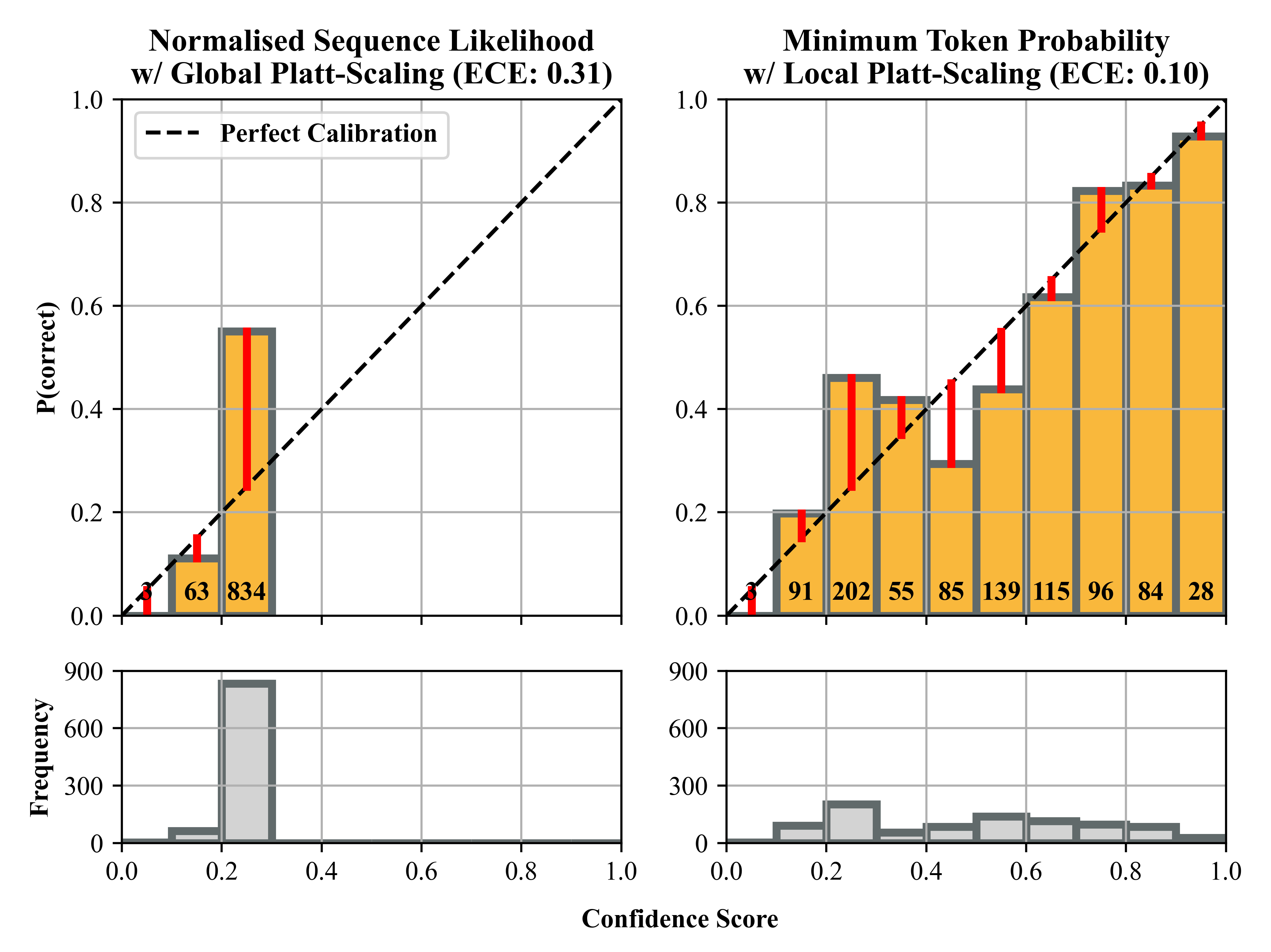
Figure 4: Left: conventional score—mismatched and degenerate. Right: fine-grained/local Platt-scaling—well-calibrated, informative across the confidence range.
Minimum token probability emerges as the top performer, providing robust, monotonic calibration across all tasks and models.
Efficacy of Local Platt-Scaling
Error heterogeneity becomes stark in tasks with greater covariate and scenario diversity—especially code refinement (CR-Trans). Here, global Platt-scaling cannot reduce ECE below 0.14; local Platt-scaling, in contrast, reduces ECE by up to 0.16 and increases bin coverage by up to five bins (Tables summarized in the main text).
UMAP visualization of embedding space (Figure 5) illustrates the pronounced shift and diversity between train/test distributions in code refinement, necessitating sample-specific calibration.
Figure 5: UMAP of Qwen3 embeddings for CR-Trans inputs/outputs highlights diversity and covariate shift—driving the need for local calibration.
Optimal cluster counts in local Platt-scaling tend to be higher in DCF-Bug (modest heterogeneity) and smaller in CR-Trans (few, highly distinct clusters), confirming that the nature of the code revision task governs calibration strategy (Figure 6).
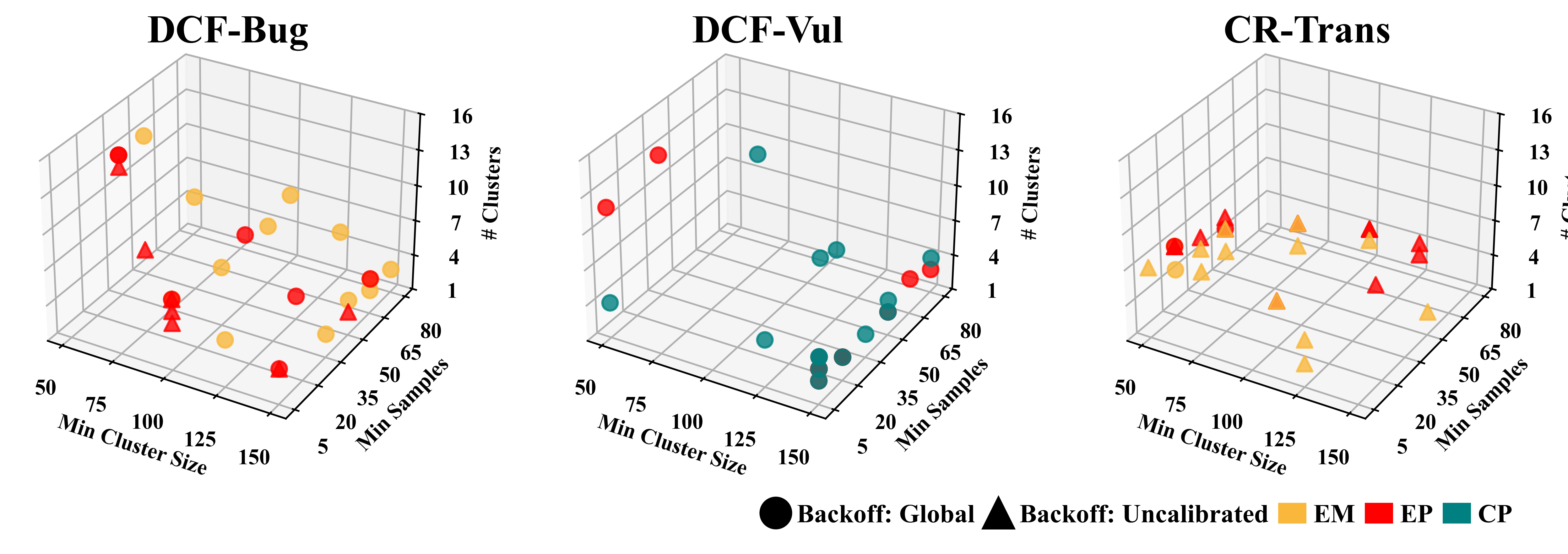
Figure 6: Optimal clustering and calibration settings vary by task, with CR-Trans tending towards smaller, distinct clusters.
Hyperparameter sensitivity is moderate for code refinement, but the optimal configuration stabilizes with as little as 20–40% of new test data, making practical deployment feasible (Figure 7).
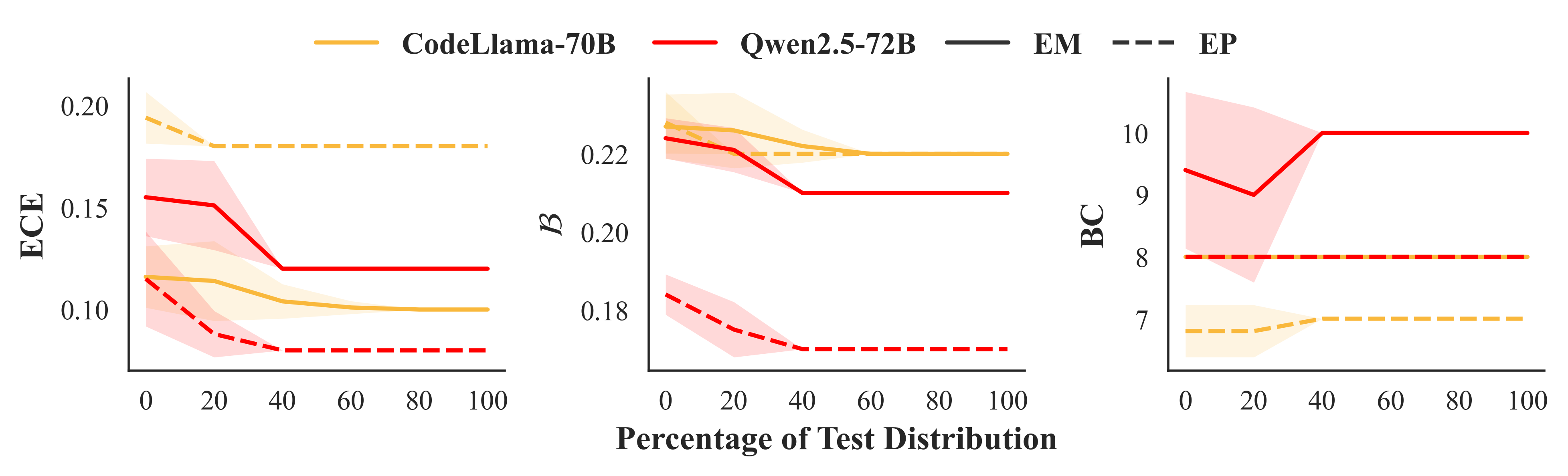
Figure 7: Calibration effectiveness quickly plateaus with modest validation data, supporting tractable deployment of local Platt-scaling.
Theoretical and Practical Implications
These results refute the sufficiency of sequence-level, globally calibrated confidence estimates in code revision contexts. They underscore that LLM code revision correctness is driven by sparse, local signals and by sample-specific error profiles, particularly in tasks with open-ended natural language or code variability.
Practically, the recommendation is:
- Program/Vulnerability Repair: Use minimum token probability + global Platt-scaling for most cases (for latency); local Platt-scaling only if absolute calibration fidelity or wide bin coverage is critical.
- Code Refinement: Always deploy minimum token probability with local Platt-scaling—global approaches are inadequate due to error heterogeneity and distribution shift.
The findings highlight that fine-grained, white-box calibration strategies should be favored in LLM-driven software engineering tools—to enable abstention, safe delegation, and trustworthy developer–AI interaction.
Conclusion
This study provides systematic evidence that both fine-grained confidence estimation and locally adapted calibration are critical for reliable automated code revision using LLMs. Minimum token probability, paired with local Platt-scaling, yields significant reductions in calibration error and enhances the utility of confidence scores for downstream decision-making.
Future research should advance calibration methods robust to out-of-distribution detection, extend to chain-of-thought/multistep agentic frameworks, and explore universal, adaptive calibrators for AI-augmented software engineering.
References
- "Fine-grained Approaches for Confidence Calibration of LLMs in Automated Code Revision" (2604.06723)