- The paper introduces feedback adaptation as a novel evaluation axis that enables immediate behavioral correction in RAG systems.
- It leverages inference-time feedback patches with dual query-context retrieval to minimize correction lag and enhance generalization.
- Empirical results demonstrate a significant post-feedback accuracy improvement (average gain of 9.7 points) across QA benchmarks.
Feedback Adaptation in Retrieval-Augmented Generation (RAG) Systems
Retrieval-Augmented Generation (RAG) systems combine neural sequence generation with external retrieval, enabling outputs grounded in large knowledge corpora. Despite widespread deployment in question answering and knowledge-intensive tasks, current RAG systems are primarily evaluated via static accuracy metrics, ignoring the critical need for rapid correction and adaptation post-deployment. In practice, system predictions frequently trigger expert or user feedback that requires immediate behavioral adjustment. The paper "Feedback Adaptation for Retrieval-Augmented Generation" (2604.06647) identifies this neglected dimension, formalizing feedback adaptation as a distinct evaluation axis for RAG systems.
Conventional feedback handling entails retraining and redeployment, which induces substantial correction lag—the interval between feedback receipt and observable behavioral change (Figure 1).
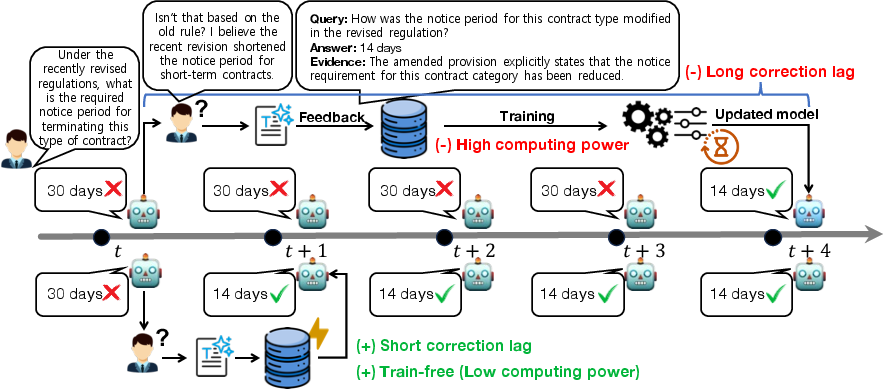
Figure 1: Feedback adaptation illustrates correction lag for training-based updates (upper) and immediate correction for inference-time feedback incorporation (lower).
The authors argue that static evaluation conflates correctness with adaptability, obscuring operational trade-offs crucial to interactive deployments. In real-world usage, rapid propagation of corrections and reliable generalization to semantically related queries are paramount, motivating the need for explicit measurement of adaptation dynamics.
Formalization: Correction Lag and Post-Feedback Performance
The paper introduces two orthogonal metrics to capture adaptation behavior:
- Correction Lag: Quantifies the delay between feedback provision and consistent behavioral correction in subsequent outputs. Training-based methods are structurally limited by computational bottlenecks (e.g., fine-tuning time), resulting in non-negligible lag.
- Post-Feedback Performance: Measures accuracy after feedback incorporation on queries semantically aligned with the feedback instance. This axis reveals the system's ability to generalize corrections beyond rote memorization.
The structural trade-off between latency and adaptation reliability is empirically verified (Figure 2).
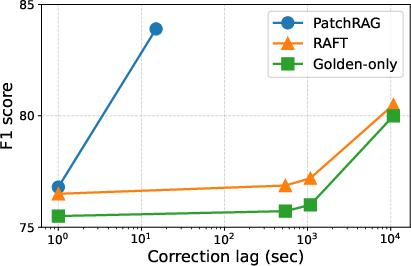
Figure 2: Correction lag versus post-feedback performance (F1) on TriviaQA, showing that inference-time approaches mitigate the trade-off inherent in training-based methods.
Feedback Adaptation Method: Inference-Time Incorporation
To demonstrate immediate adaptation, the paper introduces a minimal inference-time instantiation based on feedback patches, stored as tuples (query, answer, context). This mechanism leverages intent-context retrieval, scoring relevance as a convex combination: Si(q)=λ⋅sim(q,qi)+(1−λ)⋅sim(q,ci). The top-k feedback items are used for in-context conditioning during generation, achieving direct and rapid behavioral correction without retraining.
Ablation on retrieval strategies (Figure 3) underscores the necessity of integrating both query and context signals for robust adaptation, confirming that intent-level matching is critical to propagating feedback in the presence of semantic variation.
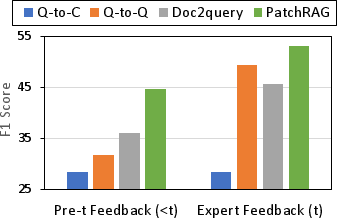
Figure 3: Ablation of query-based retrieval strategies under feedback adaptation on HotpotQA, highlighting the superiority of dual intent-context retrieval.
The balancing parameter λ mediates grounding versus generalization, with empirical results indicating the need for careful tuning to optimize reliability (Figure 4).
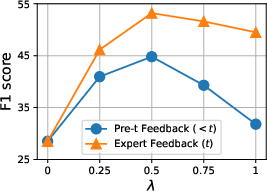
Figure 4: Impact of the balancing parameter λ on feedback adaptation performance, demonstrating the trade-off between content grounding and semantic generalization.
Experimental Evaluation
Evaluation spans standard QA datasets: Natural Questions, TriviaQA, and HotpotQA, using Llama-3 8B as generator and bge-m3 as retriever. The feedback adaptation mechanism achieves:
- The highest absolute post-feedback accuracy (average score 62.3 across tasks).
- The largest post-feedback performance gain (average improvement of 9.7 points)—substantially exceeding training-based baselines.
- Minimal correction lag, allowing immediate behavioral updates after feedback.
Stress tests involving imperfect feedback—poisoned answers, omitted signals, conflicting corrections—demonstrate robustness under realistic deployment conditions. Dense retrievers support stronger adaptation due to higher-quality embedding spaces, while sparse methods (BM25) show limited gains, confirming that embedding fidelity is a bottleneck for semantic generalization.
Qualitative analyses further reveal that intent-context retrieval reliably surfaces actionable feedback even under ambiguous evidence conditions, outperforming standard RAG in challenging, real-world failure scenarios.
Feedback adaptation is positioned distinct from continual learning, knowledge editing, and memory-centric RAG. It targets the temporal propagation of corrections rather than aggregate accuracy or parameter updates. While RAG training-based enhancements and FAQ-based retrieval strategies have addressed robustness and semantic gaps, they inadequately support rapid user-driven adaptation. Inference-time strategies are shown to be essential for immediate behavioral correction, with practical implications for privacy and deployment workflows.
Implications and Future Developments
The formalization of feedback adaptation reframes operational design in RAG systems, challenging the primacy of retraining as the mechanism for behavioral adjustment. Practically, inference-time feedback incorporation enables instant correction with no retraining downtime, rendering systems suitable for high-feedback, interactive environments. Theoretically, the separation of adaptation dynamics from accuracy metrics invites new research on memory reconciliation, conflict resolution, and long-horizon consistency management. As LLMs continue to be integrated into dynamic workflows, robust adaptation protocols will be necessary to ensure reliability and trustworthiness.
Potential risks include privacy concerns related to storing external feedback and documents; deployment must be governed by appropriate data handling and regulatory compliance.
Conclusion
This work introduces feedback adaptation as a new problem setting for retrieval-augmented generation, supported by explicit evaluation axes: correction lag and post-feedback performance. Empirical evidence reveals structural trade-offs in conventional approaches and establishes inference-time feedback incorporation as both practical and efficient. The findings necessitate new research directions in adaptation that bridge the gap between aggregate task accuracy and operational responsiveness, with wide-ranging implications for future AI systems.

