- The paper introduces WeatherRemover with a novel UNet-style Transformer that compresses multi-scale feature maps to efficiently remove weather artifacts.
- It integrates an MS-PVT backbone, convolutional attention, and gating feed-forward networks to enhance restoration quality while maintaining computational efficiency.
- Experimental results demonstrate state-of-the-art performance in removing rain, snow, and fog with competitive PSNR and SSIM metrics across diverse benchmarks.
WeatherRemover: All-in-One Adverse Weather Removal with Multi-Scale Feature Map Compression
Introduction and Motivation
Weather-induced image degradation is a significant impediment to robust visual perception and computational photography in intelligent systems, especially autonomous driving, surveillance, and outdoor scene understanding. Existing approaches for adverse weather removal tend to focus on a single type of corruption, exhibit high computational costs, or lack generalization across multiple weather domains. "WeatherRemover: All-in-one Adverse Weather Removal with Multi-scale Feature Map Compression" (2604.06623) introduces an architecture aimed at unified, computationally efficient, and effective removal of heterogeneous weather artifacts such as rain, snow, fog, and their combinations.
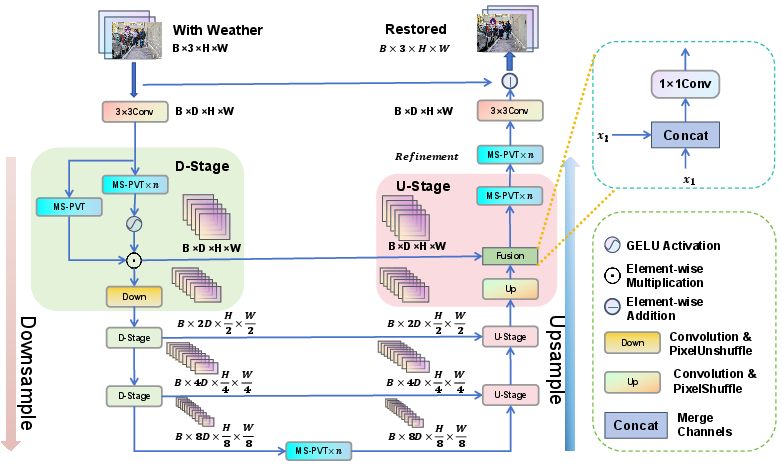
Figure 1: Overview of WeatherRemover structure. The network employs a UNet-style encoder-decoder, multi-scale feature aggregation, and integrated gating mechanisms for efficiency.
The paper advances a succinct UNet-like Transformer design with a strategically integrated gating scheme and multi-scale feature map compression, targeting optimal balance among restoration quality, parameter- and memory-efficiency, and inference overhead.
Architectural Innovations
MS-PVT Backbone and Convolutional Attention
At the core is a pyramidal Vision Transformer variant (MS-PVT), optimizing standard Pyramid Vision Transformer (PVTv2) with tailored adjustments for weather removal. The encoder-decoder backbone leverages pixel-unshuffle/shuffle, hierarchical skip connections, and flexible feature aggregation to maintain spatial and textural fidelity across scales.
Linear SRA and Channel-wise Attention
WeatherRemover's Multi-Scale Attention (MSA) replaces conventional linear projections with a composite of 1×1 convolution and depthwise separable convolutions to efficiently produce query, key, and value tensors—thereby enhancing the ability to extract local context while preserving computational efficiency.
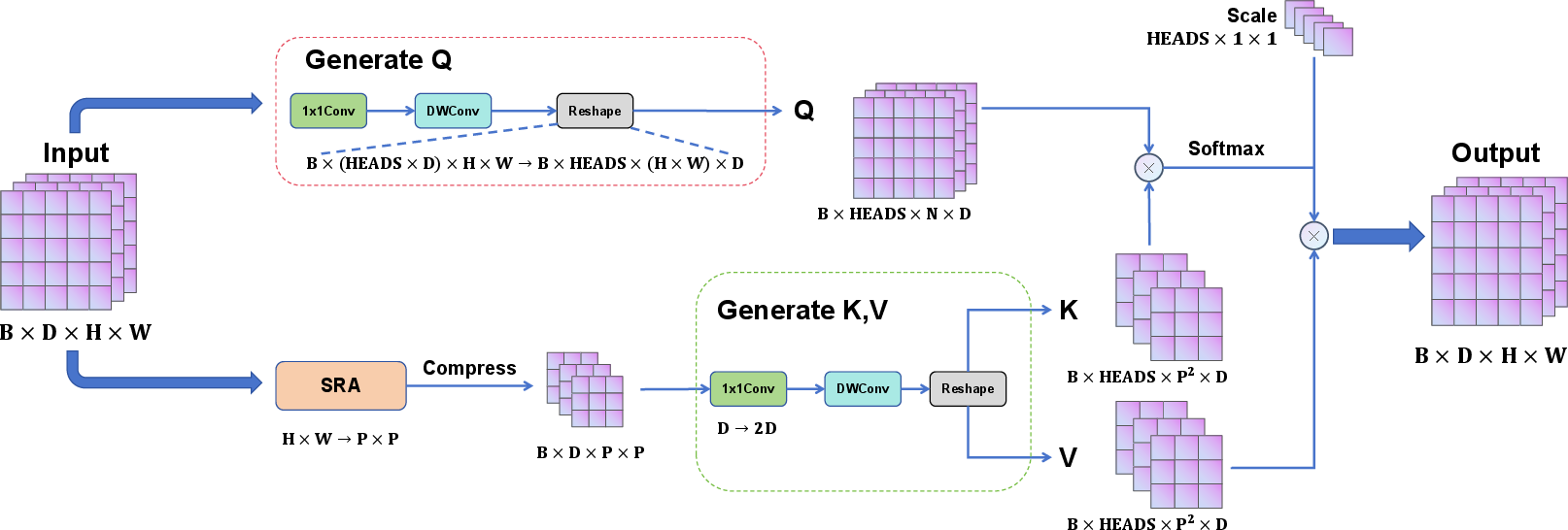
Figure 2: The MSA architecture, illustrating depthwise separable and pointwise convolution synthesis for adaptive multi-head self-attention.
Crucially, the model exploits the linear Spatial Reduction Attention (SRA) from PVTv2, compressing key and value feature maps via adaptive mean pooling, allowing for quadratic-to-linear reduction in attention computation without loss of crucial spatial structure information.
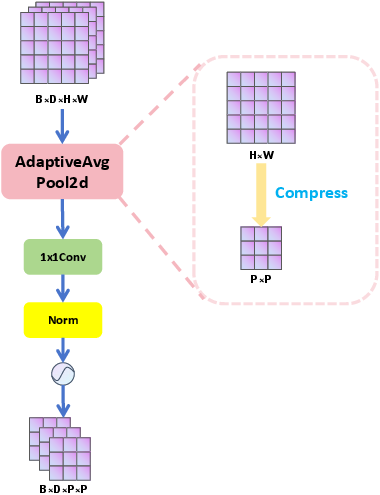
Figure 3: The linear SRA flowchart, showing adaptive pooling for dimensionality reduction prior to attention computation.
Gated Feature Refinement
The architecture introduces a novel Gating Feed-Forward Network (GFN), a dual-path mechanism where one branch is activated and the two are fused through element-wise multiplication post-convolution. This design, informed by properties of GELUs and intermediate normalization, purges redundant or noisy activations, suppresses adverse effects from spurious weather-induced features, and sharpens the focus of subsequent stages.
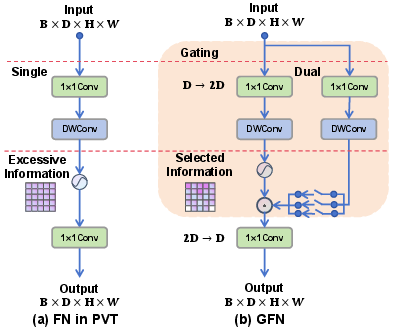
Figure 4: Comparison between PVTv2 and GFN structures, highlighting the architectural divergence in gating-enhanced feature integration.
Each MS-PVT block entwines MSA and GFN in a residual stack, producing stable gradients and effective information selection across all scales.
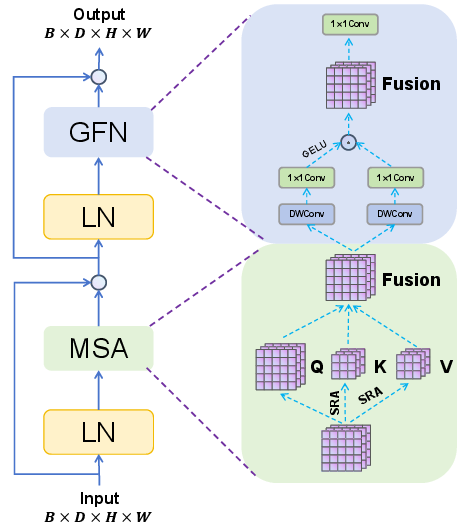
Figure 5: Overall structure of MS-PVT, elucidating the interleaving of convolutional attention and gated FFN pathways.
Quantitative and Qualitative Results
Desnowing and Rain Removal
On Snow100K-L, WeatherRemover yields state-of-the-art (SOTA) PSNR of 32.26 dB on single-weather, surpassing Restormer and DRSformer. In real-scene snowy conditions (DAWN), it excels at fine detail recovery, although it exhibits limitations under heavy snowfall at low resolutions—demonstrating slightly lower SSIM than ConvIR-B but with a significant PSNR advantage.

Figure 6: Desnowing visual comparisons revealing fine detail preservation and snow removal efficacy in complex backgrounds.

Figure 7: Real-scene desnowing, substantiating robust performance in natural snow, with limitations under severe occlusion.
For raindrop removal on RainDrop-A, WeatherRemover achieves a PSNR of 32.99, outperforming heavyweight diffusion models like RainDropDiff, as well as Restormer and I2R2Net, while maintaining less than one third the parameters of diffusion-based approaches.

Figure 8: Raindrop removal visualizations, demonstrating precise elimination of large occlusions and superior detail reconstruction relative to SOTA baselines.
On Outdoor-Rain (rain+fog), the model achieves SOTA PSNR (32.56), outperforming all other Transformer, CNN, and generative counterparts while operating with a moderate parameter count and memory footprint.

Figure 9: Single-weather deraining and dehazing: Background and detail fidelity in challenging rain/haze composites.

Figure 10: Real-scene rain and dense fog removal, showcasing WeatherRemover's effectiveness and limitations in highly cluttered, real-world occlusions.
Multi-Weather Expansion
The single-encoder-decoder paradigm of WeatherRemover enables extension to multi-weather removal using the All-Weather dataset. While inference time is slightly higher than TransWeather, the PSNR gain is substantial (up to 10–11%, depending on context), and SSIM is preserved.
Computational, Memory, and Scaling Analysis
WeatherRemover places itself between the extremes of parameter-heavy SOTA models (Restormer, DRSformer) and ultra-lightweight but narrow LMQFormer and TransWeather. On MACs, memory, and inference latency, WeatherRemover attains a position competitive with, and in many cases outperforming, broad multi-weather transformer models.
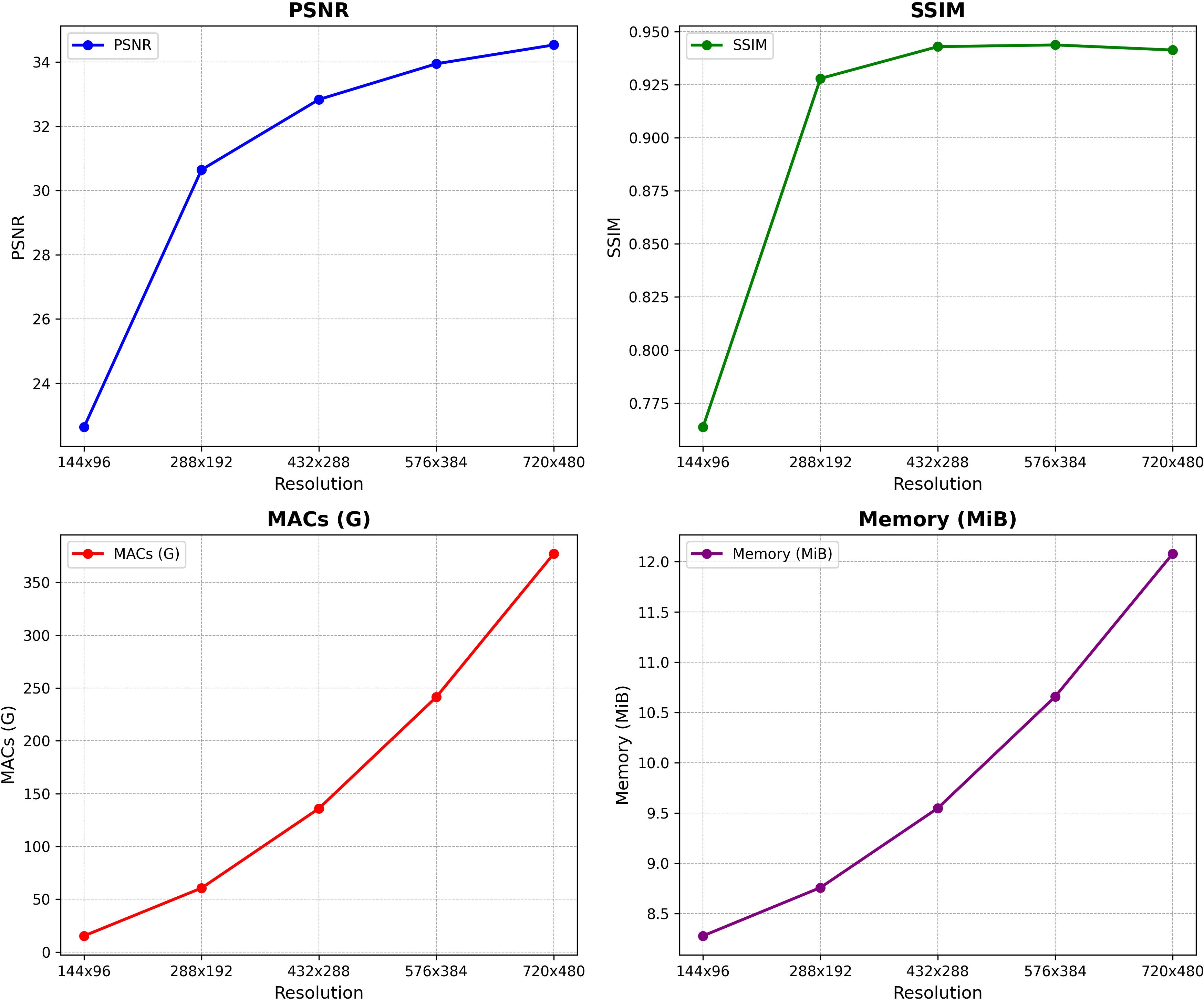
Figure 11: Model performance vs. resolution, denoting a strong correlation between restoration metrics (PSNR/SSIM) and computational/memory demands as resolution increases.
Theoretical and Practical Implications
The paper highlights the non-triviality of unified weather removal—weather types differ not only in spatial statistics but also in their interaction with image content and context. WeatherRemover's systematization of multi-scale convolutional attention, spatial reduction, and gating represents a significant methodological contribution for dense prediction tasks requiring context-aware restoration. The explicit ablation studies present compelling evidence for the effectiveness of (1) dual-branch gating in FFN, (2) joint 1x1 and depthwise separable convolutions for Q/K/V, and (3) channel attention mechanisms.
Pragmatically, the design produces a model with sufficient efficiency for deployment in quasi-real-time applications, such as fixed-location cameras in adverse environments, and points toward future adaptation for embedded and edge deployment.
Limitations and Future Directions
Despite strong empirical performance, WeatherRemover exhibits bottlenecks under severe occlusion, particularly in dense snow and low-res imagery, signifying a need for improved long-range context integration (possibly via additional global attention layers or context rescaling). Its computational load, while superior to other Transformer-based approaches with similar capacity, still lags behind the most lightweight models in practical systems constrained by energy or latency budgets.
Incremental learning for seamless addition of new weather categories without catastrophic forgetting remains an open challenge, to be tackled via continual learning frameworks and task reweighting.
Finally, while mean frame rates around 7–9 FPS are achieved in single-weather benchmarks, aggressive gating or more lightweight token-mixing strategies are mandatory for dynamic real-time vision (e.g., video or high-frequency image streams).
Conclusion
WeatherRemover (2604.06623) establishes an effective, unified approach to adverse weather removal, excelling in both single- and multi-weather scenarios with a well-structured vision Transformer architecture. Its combination of MS-PVT, efficient attention computation, and gating feed-forward network delivers SOTA or near-SOTA performance across an array of benchmarks while maintaining a computational profile suitable for practical end-to-end systems. Its successful deployment promises to boost high-level vision reliability in the wild, with substantial implications for robust perception in AI-enabled outdoor platforms and autonomous systems. Continued advancement should focus on even greater efficiency, adaptability to incremental weather categories, and more generalizable context integration.

