- The paper introduces CubeGraph, a novel framework that integrates hierarchical grid indexing with dynamic graph stitching to address fragmentation in spatio-temporal vector search.
- The paper details a two-phase index construction method that partitions metadata into cubes and connects local graphs via cross-cube neighbors to support efficient beam search.
- The paper demonstrates through empirical evaluation that CubeGraph scales linearly, achieves up to 5× speedup, and maintains over 99% recall under diverse spatial queries.
CubeGraph: Efficient Retrieval-Augmented Generation for Spatio-Temporal Filtered Vector Search
Hybrid similarity search—combining high-dimensional embeddings with spatial and temporal metadata filters—has become indispensable in retrieval-augmented generation (RAG) for applications like geo-tagged multimedia search or event retrieval. Emerging workloads require not only axis-aligned bounding box queries but arbitrary spatial polygons, complex intersections, and temporal windows, demanding unified query processing across semantic and spatio-temporal conditions (Figure 1).
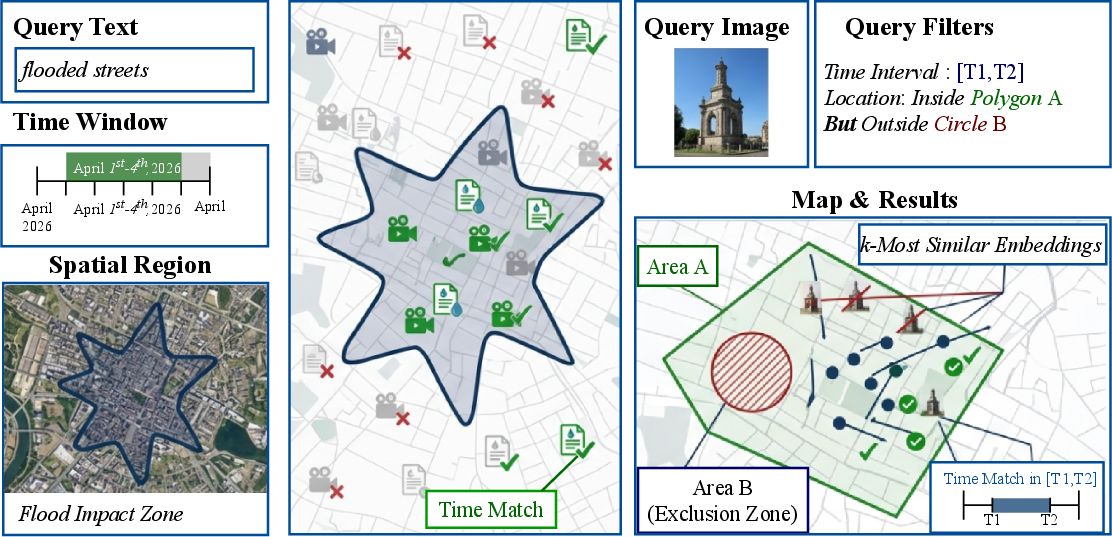
Figure 1: Motivating examples for hybrid vector similarity search with spatio-temporal filters. Each object is embedded as xi and tagged by metadata si, with queries specifying both semantic and spatial-temporal constraints.
Existing approaches (e.g., segment trees, KD-trees, R-trees) nest vector graph indices within spatial trees, leading to fragmentation of the search domain. For multi-dimensional metadata, this incurs O(N1−1/d) or worse subquery overhead, fundamentally degrading global graph connectivity and severely impacting both efficiency and recall, especially for filters with high selectivity or complex geometry. Post-filtering approaches increase distance computations; pre-filtering harms connectivity. The crux lies in bounding the number of domain fragments without undermining navigability.
CubeGraph Framework
CubeGraph (CG) introduces a hierarchical grid index over the metadata space, partitioning into modular cubes at multiple granularities. Each cube maintains a local vector proximity graph. During query execution:
- The query filter identifies cubes whose spatial boundaries intersect the filter.
- The corresponding local graphs are dynamically stitched—adding cross-cube neighbor links—forming a unified, query-specific routing graph that supports single-pass beam search across spatial boundaries.
Hierarchical granularity controls the number and scale of involved cubes, tightly bounding overhead; dynamic integration ensures global connectivity, eliminating the fragmentation bottleneck of tree-based architectures. For each layer, cell adjacency is used for efficient cross-cube linking (Figure 2).
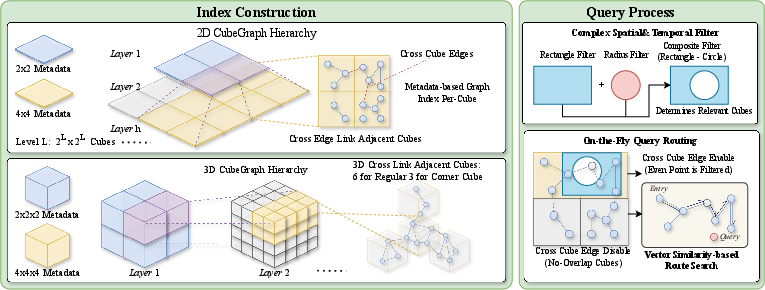
Figure 2: CubeGraph partitions the metadata space hierarchically, assigns objects to cubes, builds local graphs, and merges those intersecting the query filter via cross-cube edges, ensuring unified nearest-neighbor search.
Index Construction and Memory Layout
CubeGraph’s construction is a two-phase process:
- Phase 1: The metadata space is hierarchically partitioned; each cube’s local graph (e.g., HNSW) is constructed independently.
- Phase 2: For each cube and its adjacent counterparts, cross-cube edges are established by nearest neighbor propagation across cube boundaries, enabling seamless routing (Algorithm 2).
In terms of storage, each data point appears in exactly one cube per layer, with intra-cube and cross-cube neighbor lists maintained separately (Figure 3), ensuring efficient filter evaluation during search.
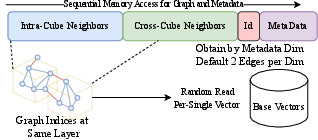
Figure 3: CG’s memory layout: nodes are layered by spatial granularity, maintain intra- and cross-cube neighbor lists, facilitating efficient spatial predicate evaluation during traversal.
Query Processing Strategies
Two query strategies are proposed:
- Predetermined Cube Search: For simple filters (bounding boxes), all intersecting cubes are precomputed; search is restricted to these cubes and cross-cube edges only between them.
- On-the-Fly Merged Search: For complex, irregular filters (polygons, circles), cube intersection is dynamically discovered during graph search; cubes are activated as qualifying points are encountered.
Both strategies ensure that the number of merged cubes is controlled (typically O(1) for bounded aspect ratios), preserving navigability and beam search efficacy. The elastic factor—a ratio estimating what fraction of traversed nodes satisfy the filter—is analytically bounded above for most practical filters, ensuring stable recall/throughput trade-offs.
Theoretical Analysis
Space complexity of CG is O(N⋅L⋅(M+m⋅Mcross)); index build is parallelizable and scales linearly with dataset size. Query time is O(C+k/e), independent of dataset cardinality, provided proper layer selection based on filter characteristic length.
- Optimal Layer Selection: For each query, select the grid layer whose cube size matches the filter granularity, minimizing the number of merged cubes and maximizing elastic factor.
- Aspect Ratio Impact: For filters with high aspect ratio, merged cube count grows linearly; the elastic factor—and thus query efficiency—degrades quadratically.
Empirical Evaluation
CG is benchmarked on SIFT1M, YFCC, MSMARC10M, and Deep100M, using real and synthetic metadata. Across diverse queries (rectangular, circular, polygonal, composed filters), CG delivers:
- Up to 5× speedup over $\ACORN$-γ and $\POST$, with stable recall exceeding 99% for standard workloads.
- Excellent scalability on Deep100M (si0M vectors), maintaining high recall at si1–si2 Qps.
- Robustness under varied metadata distributions (uniform, skewed, clustered)—skewed distributions yield higher throughput due to concentrated search space.
- Efficient query processing for both axis-aligned and irregular filters; composed and polygonal filters show negligible throughput loss compared to boxes.
- Controlled merge count is critical for efficiency; merging more than si3–si4 cubes impairs performance and recall (Figure 4).

Figure 4: Metadata attribute distributions (uniform, real geo, synthetic) across datasets, demonstrating CG’s adaptability to diverse spatial query workloads.
Implications and Future Directions
CubeGraph advances state-of-the-art filtered vector search by natively bridging high-dimensional similarity and arbitrary spatio-temporal filtering. The framework’s hierarchical structure and dynamic graph stitching robustly address fragmentation, enabling practical deployment in RAG systems, spatial analytics, and multi-modal search engines. Extensions towards GPU acceleration, complex relational join queries, and user-specific dynamic indexing are envisioned.
On a theoretical front, CG provides a concrete analytical structure for understanding the interaction between filter geometry, partition granularity, and search graph connectivity—offering insights applicable to distributed and partitioned search systems.
Conclusion
CubeGraph establishes an efficient, theoretically grounded framework for hybrid vector similarity search with arbitrary spatial and temporal predicates (2604.06616). The hierarchical grid and dynamic stitching architecture enable bounded merge counts, strong recall, and throughput, robust to filter complexity and scalability demands. The paradigm sets a foundation for future research on adaptive indexing and query optimization in spatially-aware retrieval-augmented generation.