- The paper proposes a co-evolutionary ADRS framework that automates evaluator design to continuously refine database algorithms.
- It demonstrates significant performance gains in buffer management, index selection, and query rewriting, achieving improvements up to 6.8× latency reduction.
- The approach integrates LLM-driven code generation with automated evaluator co-evolution, addressing scalability bottlenecks in database optimization.
AI-Driven Research for Databases: Automation and Co-Evolution of Evaluators
Overview and Motivation
"AI-Driven Research for Databases" (2604.06566) analyzes the paradigm shift in database systems optimization triggered by AI-Driven Research for Systems (ADRS), specifically frameworks leveraging LLMs for direct code generation. Traditional database optimization approaches are increasingly unable to manage the rapid complexity growth in workloads and hardware, largely due to reliance on manual algorithm design and black-box ML-based tuning. ADRS transitions this bottleneck to automated solution discovery and evaluation, but practical deployment is hindered by evaluation pipeline limitations: rapidly generated candidate algorithms require robust, high-fidelity evaluation at scale. The primary contribution of this paper is a co-evolutionary ADRS framework that automates evaluator design, enabling scalable, accurate feedback and unlocking continuous algorithmic discovery.
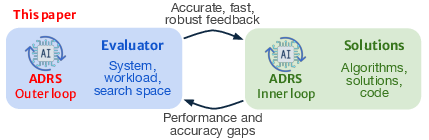
Figure 1: Co-evolution of the evaluator alongside algorithmic solution generation in ADRS.
Automating the Database Systems Research Cycle
The canonical systems research process encompasses problem formulation, evaluation setup, solution generation, solution evaluation, and dissemination. ADRS accelerates this workflow by automating the latter stages, using LLMs to synthesize executable code and evaluate candidate algorithms. The iterative, feedback-driven loop enables exhaustive search across design spaces, exploiting diverse domain knowledge encoded in foundation models. ADRS frameworks have demonstrated superior performance across systems tasks, including discovering load balancing and scheduling policies with substantial gains relative to hand-designed baselines.
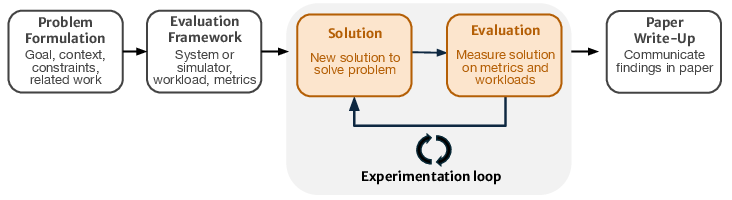
Figure 2: AI automates solution generation and evaluation in the five-stage database systems research process.
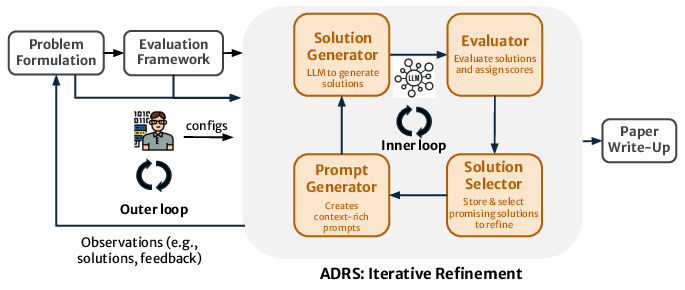
Figure 3: ADRS implements iterative solution discovery and refinement using LLMs.
The Evaluation Bottleneck in ADRS for Databases
Evaluation is the rate-limiting step in ADRS applied to database systems. Database evaluation involves complete system benchmarking, which is prohibitively slow for high-throughput candidate generation. Classical mitigation strategies include system simulation, E2E performance modeling, focused workload selection, and search space pruning, each with inherent trade-offs between speed and fidelity and considerable manual engineering overhead.
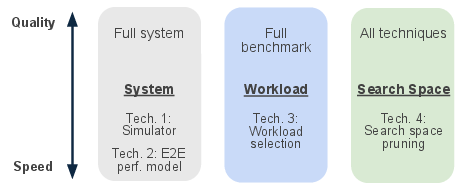
Figure 4: Established techniques for balancing evaluation speed and quality in database ADRS pipelines.
The paper argues that static, hand-engineered evaluators cannot keep pace with the ADRS generation loop. Instead, it proposes automating evaluator development via co-evolution: LLM-driven refactoring of evaluation components in tandem with algorithmic evolution, continuously optimizing both evaluators and candidate solutions.
Case Studies: Co-Evolving Evaluators Across Core Database Optimization Problems
Buffer Management: Simulator Co-Evolution
Automating buffer cache policy optimization requires evolution of accurate simulators to circumvent full-system benchmarking overhead. The paper demonstrates that calibrating simulators against multiple ground-truth baselines exposes critical system state (e.g., scan context, I/O latencies), enhancing policy expressivity and fidelity. A co-evolved lock-free sampling eviction policy yields 19.8% higher hit rate and 11.4% I/O volume savings over state-of-the-art PBM-Sampling in PostgreSQL. Multi-factor scoring, recency tracking, and clean/dirty differentiation drive these gains.
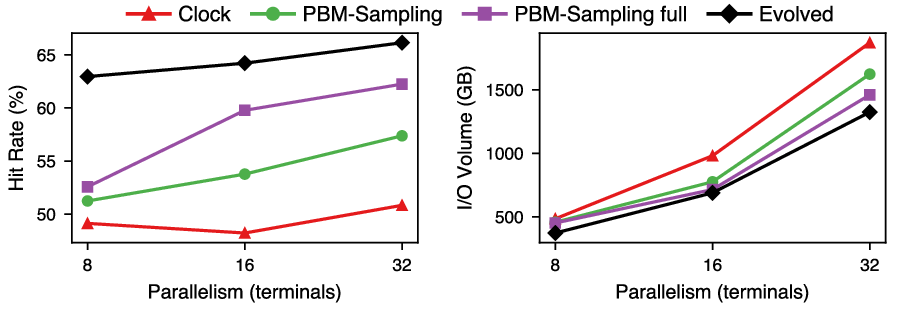
Figure 5: Evolved buffer management policies outperform baselines on TPC-H for varying parallelism.
Index selection is classically evaluated using computational cost models that poorly correlate with query latency. Co-evolving the performance evaluator involves empirically identifying and closing gaps between proxy metrics and end-to-end behavior, denoising latency signals with ordered execution and isolating queries, and dynamically refining the fitness function. The best evolved index advisor achieves 6.3% latency reduction on TPC-DS, 5.8% on TPC-H, and 2.2× lower selection time compared to heuristics (Extend).
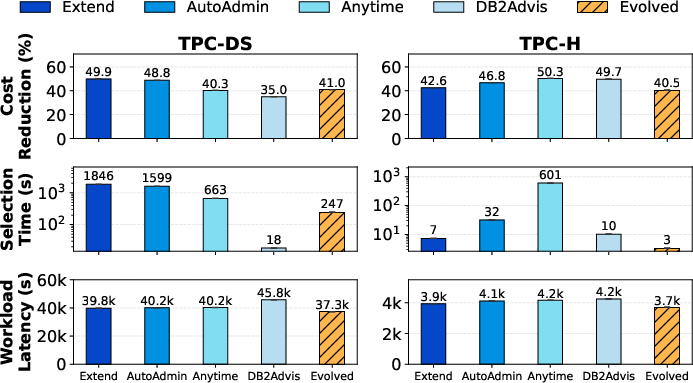
Figure 6: Evolved index selection policies demonstrate strong latency and selection efficiency improvements on TPC-DS and TPC-H.
Query Rewriting: Workload and Search Space Co-Evolution
Evolving deterministic rewrite policies requires empirical mapping of query features to performant rule combinations, targeted workload construction, and rigorous search space pruning. The outer loop drives efficient ground-truth dataset generation, isolating regressions, expanding from prior wins, and restricting rule orderings. The best evolved policy achieves 5.4× average latency reduction on TPC-H and 6.8× on DSB, far exceeding R-Bot and native optimization strategies. Tight feature guards and multi-rule combinatorics avoid regressions and exploit synergistic rule sequences.
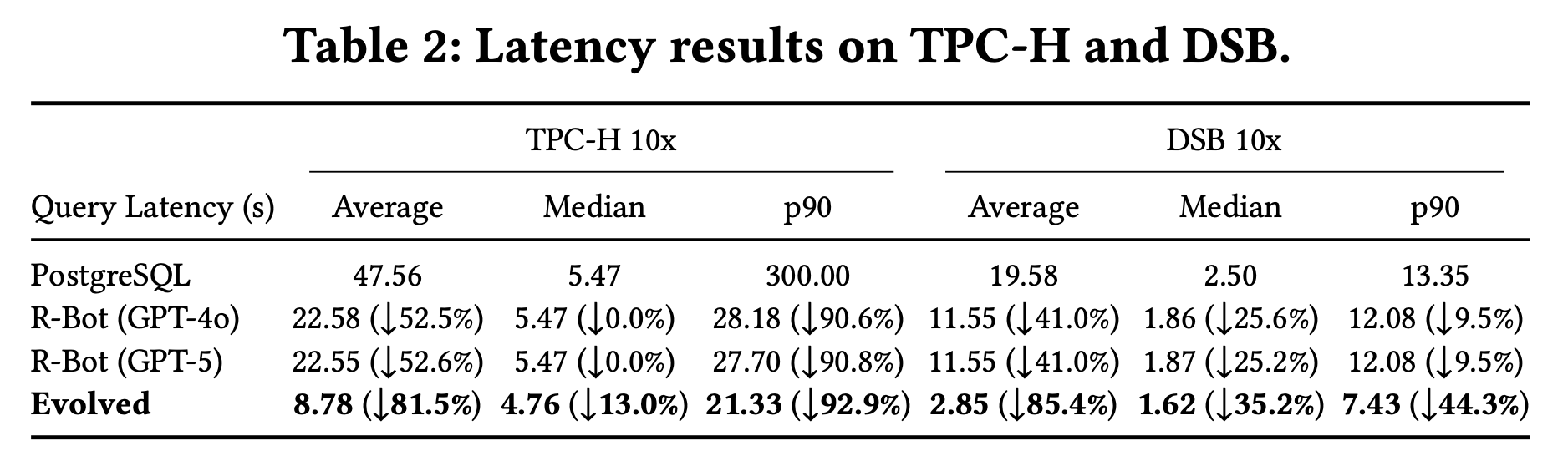
Figure 7: Latency improvements of evolved query rewrite policies across TPC-H and DSB.
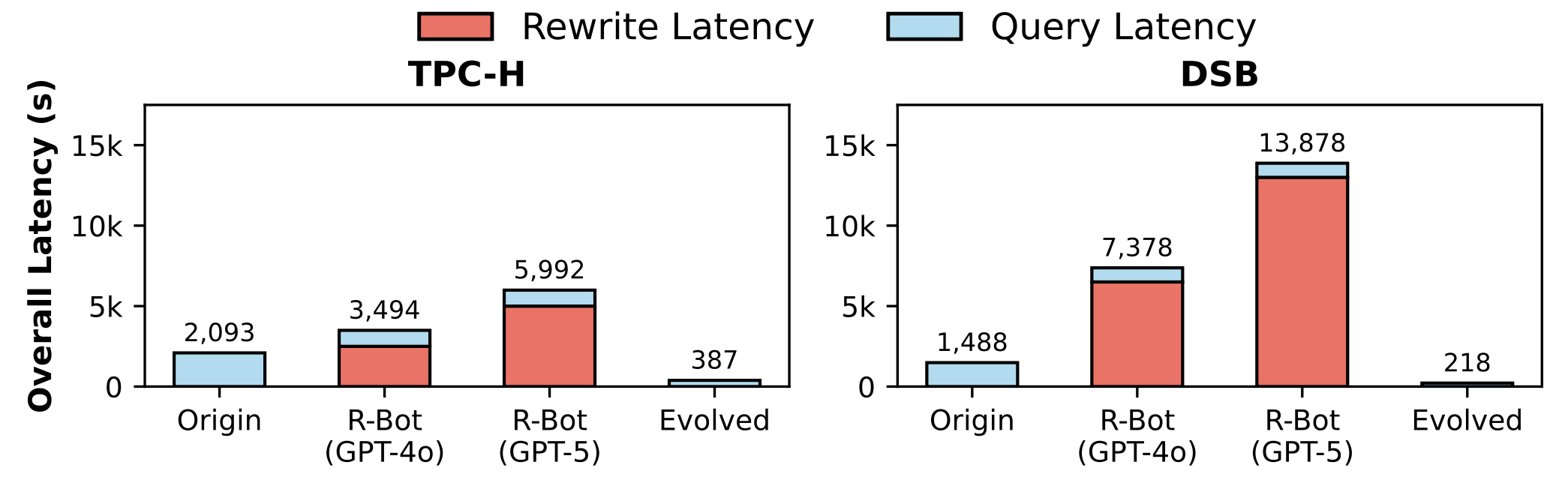
Figure 8: Overall rewrite plus execution latency of evolved policies, outperforming both native and LLM-based baselines.
Practical and Theoretical Implications
The findings validate automated evaluator co-evolution as a critical enabler for ADRS in databases. White-box code generation yields deployable and interpretable solutions, which are not susceptible to runtime inference overhead or unpredictable behavior characteristic of black-box learned models. Results highlight significant performance gains actualized by policies discovered via co-evolution, alongside robust generalization across benchmarks and workloads.
On a theoretical level, the co-evolutionary framework extends open-ended program synthesis and evolutionary algorithm paradigms to complex, stateful systems. As foundation models improve, ADRS frameworks will likely synthesize larger-scale structures, integrate formal verification for semantic correctness, and optimize workloads beyond performance metrics, possibly extracting application-level specifications to guarantee correctness.
Future Directions
- Generalization to Other Subsystems: Extending co-evolution to concurrency, transaction scheduling, and logging, integrating formal semantics and verification.
- Workload and Specification Extraction: Automating formalization of implicit application constraints for workload-centric optimization, potentially via LLM code reverse engineering.
- Agent-First Database Architectures: Re-architecting databases for modularity and predictable evaluation, enabling seamless component swapping by AI agents and supporting instance-optimized deployments.
- Human-AI Research Workflow Integration: Redefining the role of database researchers in problem specification, evaluator orchestration, and goal setting––rather than manual system engineering.
Conclusion
Automated evaluator co-evolution within ADRS frameworks overcomes the principal scalability barrier for database optimization using LLMs, substantiated across buffer management, index selection, and query rewriting core tasks. This methodology yields novel, high-performance algorithms that are interpretable and efficiently deployable. The implications extend to future AI-integrated database architectures, shifting the research focus toward precise specification and orchestration over manual code and evaluation design, paving the way for agent-first, self-adaptive systems optimization.

