Barbarians at the Gate: How AI is Upending Systems Research
Abstract: AI is starting to transform the research process as we know it by automating the discovery of new solutions. Given a task, the typical AI-driven approach is (i) to generate a set of diverse solutions, and then (ii) to verify these solutions and select one that solves the problem. Crucially, this approach assumes the existence of a reliable verifier, i.e., one that can accurately determine whether a solution solves the given problem. We argue that systems research, long focused on designing and evaluating new performance-oriented algorithms, is particularly well-suited for AI-driven solution discovery. This is because system performance problems naturally admit reliable verifiers: solutions are typically implemented in real systems or simulators, and verification reduces to running these software artifacts against predefined workloads and measuring performance. We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions. Using penEvolve, an existing open-source ADRS instance, we present case studies across diverse domains, including load balancing for multi-region cloud scheduling, Mixture-of-Experts inference, LLM-based SQL queries, and transaction scheduling. In multiple instances, ADRS discovers algorithms that outperform state-of-the-art human designs (e.g., achieving up to 5.0x runtime improvements or 50% cost reductions). We distill best practices for guiding algorithm evolution, from prompt design to evaluator construction, for existing frameworks. We then discuss the broader implications for the systems community: as AI assumes a central role in algorithm design, we argue that human researchers will increasingly focus on problem formulation and strategic guidance. Our results highlight both the disruptive potential and the urgent need to adapt systems research practices in the age of AI.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about how AI, especially LLMs, is starting to change the way researchers design and improve “systems” — the big computer setups that power things like cloud services, databases, and networks. The authors show that AI can automatically invent and test new algorithms (step-by-step rules) that make these systems faster or cheaper. They call this approach AI-Driven Research for Systems (ADRS). Using an open-source tool called OpenEvolve, they demonstrate that AI can find solutions that beat state-of-the-art human designs in hours, often for just a few dollars of computing cost.
What questions does the paper ask?
- Can AI discover better algorithms for computer systems than humans, and do it faster?
- Why are systems problems a good match for AI-driven discovery?
- How should researchers work alongside AI tools to get the best results?
- What are the best practices for making this AI-driven approach reliable and useful?
How did they do it? (Methods and analogies)
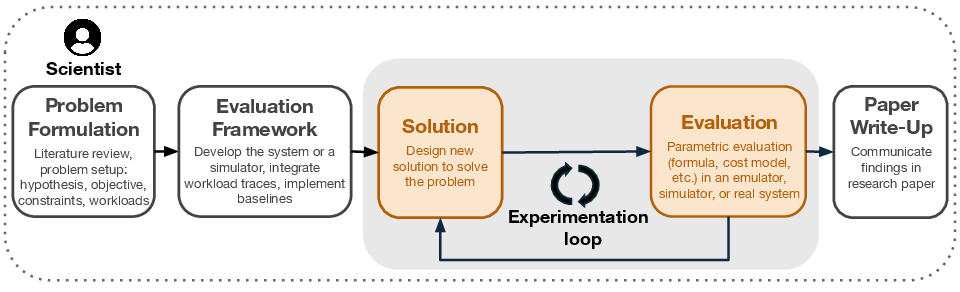
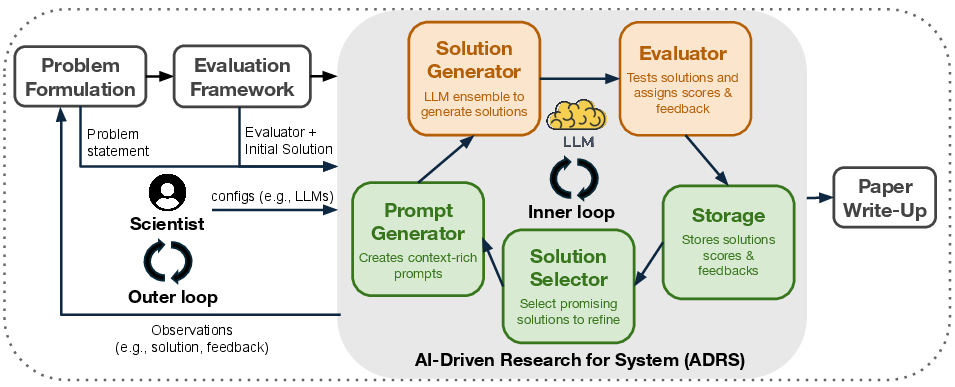
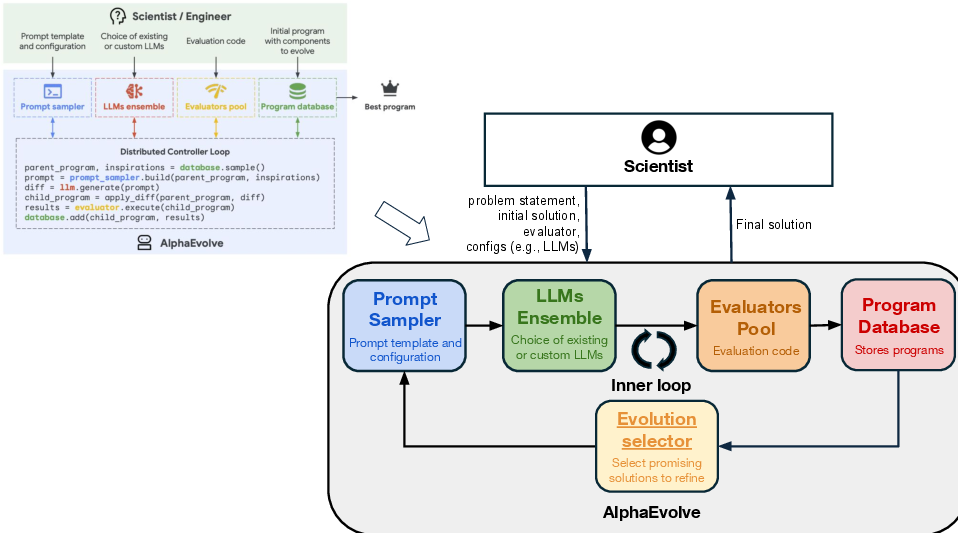
The authors use ADRS, which is like an “AI research assistant” that repeatedly tries ideas, tests them, and then improves based on the test results. Think of it like this:
- Imagine coaching a team. The AI is the coach trying lots of strategies.
- A simulator is the practice field where new plays are tried out safely and quickly.
- A verifier is the referee that checks the score — it measures things like speed, cost, or accuracy.
Here’s the loop the AI runs:
- Generate ideas: The AI writes or edits code for a new algorithm.
- Test ideas: The algorithm runs in a simulator or real system using standard workloads (like practice drills).
- Score results: The system measures performance (for example, faster runtime, lower costs).
- Keep the best, improve the rest: The AI saves the good ideas, learns from tests, and tries again.
Why this works well for systems:
- Systems problems have “reliable referees.” It’s easy to check if something is faster or cheaper by running it and measuring numbers.
- Simulators are cheap and fast, so the AI can try many ideas without breaking real systems.
- Many systems tasks (like scheduling or routing) have small core pieces where changes make a big difference, making AI’s code changes manageable and understandable.
Main findings and why they matter
Using OpenEvolve and strong LLMs (like GPT-4o, o3, and Gemini 2.5 Pro), the paper reports several wins across different systems tasks:
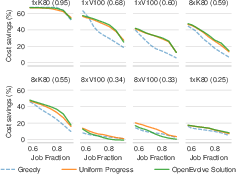
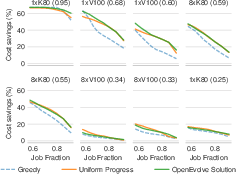
- Cloud job scheduling with spot instances:
- Single-region: AI found policies that saved up to about 16% more money than a published top solution while still meeting deadlines.
- Multi-region: AI discovered a new approach with around 26% lower cost than a strong baseline where no prior best policy existed.
- Mixture-of-Experts (MoE) model load balancing:
- AI designed a way to rebalance work across GPUs that ran about 5 times faster than the best known baseline.
- LLM-based SQL queries:
- AI matched the hit rate of state-of-the-art methods while making the reordering algorithm run about 3–4 times faster.
- Transaction scheduling:
- AI rediscovered strong online strategies and improved offline scheduling by around 20–34% compared to a greedy baseline.
Big picture: Many of these wins were produced within a few hours and for only a few dollars to tens of dollars. That’s much faster and cheaper than traditional, months-long research cycles.
What is the impact? (Implications for the future)
- Changing roles for researchers: As AI gets better at discovering and tuning algorithms, human researchers will focus more on choosing the right problems, setting smart goals, and guiding the search — like a head coach setting strategy while the AI runs drills.
- Faster progress: Because verification is measurable and simulators are cheap, ADRS can speed up experiments and encourage bold exploration.
- Best practices: Good prompts, strong evaluators, clear metrics, and diverse test cases make AI’s search more reliable.
- Open challenges: Building faithful simulators for complex systems is hard. The community needs to improve evaluation tools, share benchmarks, and study which AI settings work best for different problems.
In short, AI-driven discovery is already helping systems research produce better algorithms faster. If researchers adapt and team up with AI as a smart assistant, we could see big leaps in performance and cost savings across the computer systems that power much of modern technology.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or left unexplored in the paper, framed so future researchers can act on it.
- Verification reliability: Develop methodologies to quantify and improve evaluator fidelity (false positives/negatives) when using simulators; establish gap-to-reality metrics comparing simulator outcomes to real system deployments across diverse workloads.
- Correctness beyond performance: Incorporate formal correctness checks (safety, liveness, invariants) and equivalence checking for algorithmic changes; define a standard suite of functional tests and runtime assertions to catch latent violations introduced by AI-generated code.
- Reward hacking and evaluator hardening: Detect and prevent “cheating” strategies that game the evaluator (e.g., using shortcuts, exploiting evaluator assumptions); build adversarial evaluators and randomized sanity checks to ensure genuine improvements.
- Generalization and overfitting: Measure cross-workload generalization with held-out traces and distribution-shift scenarios; quantify how feedback-subset selection affects overfitting; introduce protocols for k-fold trace partitions and out-of-distribution stress tests.
- Real-system validation: Move beyond simulators to end-to-end deployment trials in real systems; document roll-out methodology (canary/A-B tests), safety nets, and incident reports; quantify deployment overhead, stability, and operational risks.
- Reproducibility and robustness: Standardize seeds, logging, versioned traces, model snapshots, and environment configs; report run-to-run variance and confidence intervals; provide open repositories with all artifacts for independent reproduction.
- Systematic ablations: Perform controlled ablation studies for evolution strategy (islands vs. greedy), model ensemble composition, iteration budget, prompt structure, feedback granularity, and evaluator features to isolate causal contributors to gains.
- Evaluator construction guidelines: Provide repeatable recipes for building faithful, fast evaluators for complex systems (OS, DBMS, distributed protocols); analyze the speed–fidelity tradeoff and specify when to prefer simulation vs. emulation vs. real-system tests.
- Multi-objective optimization: Extend frameworks to jointly optimize latency, throughput, cost, reliability, and fairness; implement Pareto-front tracking, constraint satisfaction guarantees, and preference-learning to navigate tradeoffs explicitly.
- Human-in-the-loop efficacy: Quantify when and how human feedback improves search (e.g., rubric-based critique vs. code hints vs. constraint edits); measure marginal utility of human guidance and design APIs for structured, low-latency expert input.
- Interpretability and idea extraction: Create tools to automatically distill algorithmic concepts from evolved code (summaries, invariants, decision rules); evaluate whether increased modification scope (multi-component protocols) preserves interpretability.
- Scalability to large codebases: Develop modular, hierarchical evolution and program-analysis-assisted tool-use to manage context limits; verify cross-component interactions and side effects in large, heterogeneous systems.
- Safety and security of generated code: Introduce security scanning, dependency vetting, sandboxing, resource limiting, and fuzzing for evaluator runs; test for privilege escalation, injection, and concurrency vulnerabilities introduced by code changes.
- Benchmarking ADRS for systems: Establish a public benchmark suite of systems tasks (networking, scheduling, storage, DB, MLSys) with baselines, traces, and metrics; align with community standards (e.g., NSDI/OSDI reproducibility checklists).
- Model choice and licensing: Evaluate ADRS performance with open-weight models to enable reproducibility; assess sensitivity to frontier vs. mid-tier models; disclose licensing constraints and cost implications for academic use.
- Cost, energy, and carbon accounting: Report total cost including setup and iteration, energy use, and carbon footprint; derive cost–quality curves and guidelines for budget allocation; explore energy-aware evolution schedules.
- Fairness and SLO compliance: Test evolved policies for fairness across tenants/jobs/flows; verify adherence to SLOs under contention; add fairness metrics to evaluators and enforce constraints during search.
- Intellectual novelty and provenance: Detect reused patterns or potential training-set leakage (rediscovery of SOTA from public code); propose novelty metrics and disclosure standards for AI involvement and provenance tracking.
- Theoretical guarantees: Provide bounds or convergence analyses on evolution strategies; characterize search landscapes and sample complexity for systems tasks; define conditions under which ADRS outperforms human design.
- Meta-prompt and evolution strategy design: Compare prompt-evolution methods (reflective updates, genetic operators), diversity maintenance, and island topologies; study mode collapse and propose diversity metrics for candidate pools.
- Adaptive evaluator and active learning: Explore evaluators that adapt workloads to probe failure modes; use active learning to select traces that maximally inform search; calibrate feedback granularity to resolve specific error classes.
- Transaction scheduling specifics: For offline gains, establish theoretical optimality/approximation bounds; evaluate compatibility with concurrency control schemes and impact on throughput vs. latency vs. abort rates under realistic contention.
- MoE load balancing coverage: Test across model scales, GPU topologies, interconnects, straggler scenarios, and dynamic load changes; measure throughput/latency impacts beyond rebalance runtime; validate behavior during partial failures.
- Multi-region spot scheduling realism: Model correlated preemptions, region-specific price/availability dynamics, data-transfer costs, and changeover penalties; validate with real cloud traces and assess sensitivity to market shifts.
- LLM-SQL cache reordering generality: Evaluate across diverse schemas, table sizes, skewed distributions, and adversarial query mixes; quantify impact on end-to-end query accuracy and latency, not just prefix-hit rate and preprocessing runtime.
- Robust storage and selection policies: Analyze solution database growth, retrieval bias, and staleness; design selection strategies that maintain diversity and avoid premature convergence; track lineage and mutation history for auditability.
- Negative results and failure taxonomy: Report where ADRS fails or regresses; categorize failure modes (syntax errors, runtime crashes, constraint violations, brittleness); tie failure classes to specific feedback or prompt fixes.
- Integration with formal methods: Combine ADRS with model checking/SMT to enforce invariants; investigate hybrid loops where formal constraints prune candidate spaces or provide counterexamples for learning.
- Community practice and impact: Empirically study how ADRS changes researcher workflow, learning outcomes, and bias; define best-practice guidelines for publication (disclosure, reproducibility, evaluator description) in systems venues.
- Secure evaluator operations: Specify hardened execution sandboxes for untrusted code, resource quotas, and isolation mechanisms; provide policies for third-party contributions and continuous integration safety.
- Data/traces openness: Curate and release representative, licensed traces for systems tasks; annotate with distributional properties and known edge cases; provide generators for synthetic but realistic workloads.
- Statistical rigor: Report significance tests, confidence intervals, and effect sizes for improvements; use stratified analysis across workloads and configurations to avoid aggregate masking.
- Portability and transfer: Study transfer of evolved heuristics to related tasks/systems; define mechanisms to extract, parameterize, and reuse discovered policies as modular libraries.
- Simplicity vs. complexity tradeoffs: Introduce metrics for algorithmic simplicity, maintainability, and operational cost; discourage bloaty changes that marginally improve metrics but harm readability and maintainability.
- Cross-framework comparison: Compare OpenEvolve, GEPA, LLM4AD, and coding-assistant-based pipelines on identical tasks; identify which components (prompting, evolution operators, evaluators) drive differences in outcomes.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s ADRS approach (AI-Driven Research for Systems) and its demonstrated case studies. They leverage reliable evaluators/simulators to automatically generate, test, and select performant algorithms.
Software/Cloud/AI Infrastructure
- Cloud spot scheduling optimizer for deadline-driven jobs
- Sectors: Cloud computing, ML training/inference platforms, FinOps
- Use case: Automatically synthesize region-aware policies that maximize spot usage without missing deadlines; the paper reports up to 16.7% higher savings vs. state of the art (single region) and 26–49% beyond strong baselines in multi-region settings.
- Tools/products/workflows: “Auto-Spot Planner” integrated into workload managers (Kubernetes operators, Ray, Slurm); CI-driven ADRS loop on simulators with A/B canaries; dashboards for safety margins and deadline risk.
- Assumptions/dependencies: High-fidelity simulators with realistic preemption traces; accurate workload models and deadlines; guardrails to prevent SLO violations; access to multiple regions and instance types.
- MoE expert placement and rebalancing for inference serving
- Sectors: AI/ML infrastructure, MLOps, model serving
- Use case: Evolve expert-to-GPU mappings and rebalancing algorithms to reduce tail latency and rebalancing time; the paper reports up to 5× faster rebalancing than an internal baseline at similar balance quality.
- Tools/products/workflows: “ExpertAutoBalance” plug-in for Triton/DeepSpeed/Custom MoE runtimes; continuous ADRS tuning per traffic pattern; replay-based evaluators driven by real request logs.
- Assumptions/dependencies: Load models that reflect production request skew; safe hot-swap of routing/placement; telemetry for drift detection; simulator-to-prod transfer checks.
- GPU/model placement cost optimizer
- Sectors: AI/ML infrastructure, Cloud cost optimization
- Use case: Use ADRS to place models across heterogeneous GPUs/regions for cost/performance; paper reports 18.5% cheaper placements vs. published solution.
- Tools/products/workflows: “Model-to-GPU Planner” for serving clusters; mixed-integer or heuristic baselines augmented with ADRS-generated variants; rolling verification pipelines.
- Assumptions/dependencies: Accurate cost/perf curves per hardware/region; evaluator coverage of real workloads; placement safety constraints (affinity, fault-domain isolation).
Databases and Data Platforms
- LLM-SQL KV cache hit-rate optimizer with fast preprocessing
- Sectors: Data engineering, Analytics, AI applications
- Use case: Reorder tables (rows/columns) to improve KV cache hits during LLM-powered SQL answering; comparable hit rate to SOTA with 3.9× faster preprocessing runtime.
- Tools/products/workflows: “TableReorder Assistant” embedded in ETL; offline ADRS evolution on representative query mixes; fallbacks for data drift.
- Assumptions/dependencies: Access to representative queries; cost-aware evaluators that incorporate I/O effects and cache limits; schema-change monitoring.
- Transaction scheduler tuner
- Sectors: Databases, FinTech platforms
- Use case: Evolve transaction ordering strategies to minimize conflicts and makespan; paper reports 20–34% improvement vs. greedy baselines (offline) and rediscovery of near-SOTA online behavior.
- Tools/products/workflows: “Conflict-Aware Scheduler” module for OLTP engines; ADRS loop seeded with workload traces; shadow replay in staging.
- Assumptions/dependencies: Conflict models that match engine semantics; correctness invariants in the evaluator; workload representativeness.
Networking and Systems Operations
- Telemetry repair and calibration assistant
- Sectors: Networking/Telecom, Cloud operations
- Use case: Repair buggy counters and calibrate telemetry pipelines; paper shows +9% repair score and +30% calibration confidence vs. a published solution.
- Tools/products/workflows: “NetTelemetry Repair Bot” that proposes patch sets; evaluator harnesses that compare against golden traces; human-in-the-loop approval.
- Assumptions/dependencies: Availability of labeled or synthetic “golden” traces; safety checks to prevent regression in critical monitoring; versioned pipelines.
- Multi-cloud data transfer cost optimizer
- Sectors: Cloud/Storage, Enterprise IT
- Use case: Match state-of-the-art transfer cost strategies with ADRS in ~1 hour; embed as a cost-aware policy generator.
- Tools/products/workflows: “CloudCast Optimizer” in data movers; cost simulators updated with provider pricing; scheduled re-optimization.
- Assumptions/dependencies: Fresh egress/ingress/pricing tables; bandwidth/latency models; data sovereignty constraints encoded in evaluators.
Model Architecture and Compression
- Sparse attention designer (searching density/accuracy tradeoffs)
- Sectors: AI model R&D, Edge inference
- Use case: Evolve sparse attention patterns to improve accuracy-density trade-offs; paper notes 7% average error/density improvement vs. SOTA (pilot).
- Tools/products/workflows: “SparseAttention Studio” for model teams; evaluation on standard NLP tasks; exportable kernels.
- Assumptions/dependencies: Reliable accuracy proxies during search; compatibility with kernel backends; task transferability.
- Adaptive weight compression policy generator
- Sectors: Model compression, Mobile/Edge AI
- Use case: Column-level bit-rate assignment to minimize bits/element while preserving accuracy; early results show comparable compression with modest perplexity degradation—usable as a starting point for human-guided refinement.
- Tools/products/workflows: “AutoQuant Planner” for post-training compression; task-aware evaluators; regression tests for accuracy.
- Assumptions/dependencies: Good calibration datasets; guardrails for accuracy drop; hardware support for variable precision.
Research and Education
- ADRS-as-a-service for systems labs
- Sectors: Academia, R&D organizations
- Use case: Provide a turnkey ADRS environment (OpenEvolve/GEPA) to automate solution discovery in student/research projects; paper shows many tasks solved in hours at <$20 cost.
- Tools/products/workflows: Hosted ADRS runners, simulator registries, evolution-tree visualizations, reproducible seeds; “autograder-style” evaluators for coursework.
- Assumptions/dependencies: Curated, open simulators; budgeted API access to LLMs; academic policies on AI use and attribution.
Developer Tooling and DevOps
- ADRS-augmented coding assistants for algorithm evolution
- Sectors: Software engineering, DevOps
- Use case: Integrate the paper’s loop (prompting, code mutation, evaluation, selection) into IDEs/CI to automatically search algorithm variants under test workloads.
- Tools/products/workflows: Cursor/Windsurf extensions invoking evaluator suites; “evolve-on-PR” jobs; evolution-trace artifacts for code review.
- Assumptions/dependencies: Deterministic and fast evaluator harnesses; non-flaky tests; clear ownership and rollback policies.
Policy and Governance (Operational)
- Reproducible evaluator standards for AI-generated systems code
- Sectors: Government IT, Regulated industries
- Use case: Mandate evaluator-based verification for AI-generated algorithms in procurement and change-management processes to safely adopt ADRS outputs.
- Tools/products/workflows: Standardized evaluator specs, trace repositories, acceptance thresholds, audit logs of evolution history.
- Assumptions/dependencies: Governance buy-in; evaluator quality and openness; IP and data-use compliance.
Long-Term Applications
The following applications require further research, scale-up, or ecosystem development (e.g., higher-fidelity simulators, formal methods, or broader safety/regulatory frameworks).
Cross-Component and End-to-End System Design
- Whole-stack ADRS co-design (compiler ↔ runtime ↔ scheduler)
- Sectors: Software/Cloud, AI infrastructure, HPC
- Use case: Jointly evolve algorithms across layers (e.g., kernel selection, scheduling, memory layout) for global performance/cost gains.
- Tools/products/workflows: Multi-objective evaluators; federated simulators; Pareto-front exploration tools.
- Assumptions/dependencies: Composable, faithful simulators; strong invariants across layers; advanced caching of evaluation runs.
- Distributed protocol synthesis with correctness guarantees
- Sectors: Databases, Distributed systems, Telecom
- Use case: ADRS generates novel protocols (consensus, replication, caching) with formal verification integrated into the evaluator loop.
- Tools/products/workflows: “Verify-in-the-loop” with model checking or proof assistants; counterexample-guided evolution.
- Assumptions/dependencies: Scalable formal methods; expressive yet tractable specs; synthesis that respects liveness/safety under faults.
Production-Embedded, Closed-Loop Optimization
- Always-on “autonomic” ADRS in production
- Sectors: Cloud, CDN, FinTech, AdTech
- Use case: Safe online evolution of policies using shadow traffic and guarded rollouts to continuously adapt to drift.
- Tools/products/workflows: Online evaluators with guardrails, canary metrics, automated rollback; policy versioning and lineage tracking.
- Assumptions/dependencies: Robust safety policies; low-risk domains first; organizational readiness for algorithmic change management.
- Evaluator marketplaces and benchmarks
- Sectors: Software tooling, Open science
- Use case: Shared, certified evaluators and trace corpora per domain (OS scheduling, storage, networking), enabling comparable ADRS results.
- Tools/products/workflows: Evaluator registries, standardized APIs, leaderboards for “evolved algorithms.”
- Assumptions/dependencies: Community governance; incentives for high-fidelity simulators; legal clarity around dataset sharing.
Safety-Critical and Regulated Domains
- ADRS for healthcare/industrial control with verified safety envelopes
- Sectors: Healthcare IT, Energy, Manufacturing
- Use case: Evolve scheduling/resource policies under strict safety constraints (e.g., ICU bed/ventilator allocation; microgrid dispatch).
- Tools/products/workflows: Hybrid evaluators combining simulation and digital twins; formalized safety envelopes.
- Assumptions/dependencies: Trustworthy domain simulators; regulatory approval pathways; rigorous post-deployment monitoring.
- Policy frameworks for AI-generated algorithm attribution and audit
- Sectors: Government, Standards bodies
- Use case: Define audit trails, accountability, and IP treatment for ADRS-produced code and decisions used in public systems.
- Tools/products/workflows: Provenance metadata for evolution artifacts; red-team evaluations; conformance testing.
- Assumptions/dependencies: Clear legal consensus on AI-generated IP and liability; standardized reporting schemas.
Advanced Research Workflows
- “AI PI” research agents that co-own solution discovery
- Sectors: Academia, Corporate R&D
- Use case: ADRS expands from solution search to hypothesis generation, ablation planning, literature-grounded ideation, and automated paper drafts.
- Tools/products/workflows: Integrated RAG over literature; experiment planners; meta-evaluators for novelty and rigor.
- Assumptions/dependencies: Strong retrieval grounding; bias/ hallucination safeguards; new authorship/attribution norms.
- Formalized ADRS pedagogy and curricula
- Sectors: Education
- Use case: Course labs where students define problems and evaluators while ADRS iterates on solutions—training future researchers for advisor-style roles.
- Tools/products/workflows: “ADRS Lab Kits” with scaffolding for problem specs and evaluators; rubrics for evaluator quality.
- Assumptions/dependencies: Access to model APIs or local LLMs; institution policies on AI use.
Broadening the Technical Frontier
- From simulator-based validation to verified deployment pipelines
- Sectors: All systems domains
- Use case: Tooling that quantifies and mitigates sim-to-real gaps; automated stress-test generation and robustness checks as part of evolution.
- Tools/products/workflows: Domain randomization in evaluators; counterfactual trace synthesis; discrepancy metrics driving further evolution.
- Assumptions/dependencies: Measurable sim-to-real error models; scalable stress testing; integration with production telemetry.
- Low-cost, on-prem ADRS with open models
- Sectors: SMEs, Privacy-sensitive domains
- Use case: Run ADRS locally using open LLMs and hardware-efficient evaluators to reduce dependency on proprietary APIs.
- Tools/products/workflows: Quantized local LLMs; caching, replay, and offline evaluation; reproducibility-first pipelines.
- Assumptions/dependencies: Sufficient local compute; competitive open models for code/reasoning; maintenance expertise.
In all cases, feasibility hinges on:
- Evaluator quality: fidelity, coverage, and correctness constraints are decisive; poor evaluators can lead to overfitting or unsafe policies.
- Representative workloads: evaluation traces must match real usage patterns and update regularly.
- Safe deployment workflows: gating via CI/CD, canaries, rollbacks, and human oversight.
- Access and governance: model/API costs, data/IP compliance, and organizational readiness for algorithmic evolution at speed.
Glossary
- AI-Driven Research for Systems (ADRS): An approach that uses iterative LLM-driven generation, evaluation, and refinement to automatically discover systems algorithms. "We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions."
- AlphaChip: A DeepMind system that applies reinforcement learning to produce manufacturable chip layouts. "AlphaChip~\cite{alphachip2024} uses RL to generate production chip layouts."
- AlphaDev: An AI system that discovers efficient low-level algorithms using search and reinforcement learning. "AlphaDev~\cite{alphadev} extended these ideas to discover efficient low-level algorithms"
- AlphaEvolve: A framework that evolves computer science algorithms via AI and evaluation loops. "AlphaEvolve~\cite{alphaevolve} is a system developed by Google DeepMind that uses artificial intelligence to automatically discover and design novel, high-performance computer science algorithms."
- AlphaFold: An AI system for predicting protein structures with high accuracy. "AlphaFold~\cite{alphafold}, which achieved breakthroughs in protein structure prediction."
- AlphaZero: A reinforcement learning and search-based system that masters complex games from self-play. "AlphaZero~\cite{silver2018alphazero}, which demonstrated how search and RL can master games"
- Cardinality estimation: Predicting the number of rows that will be processed or returned by a query plan operator in a database. "cardinality estimation~\cite{balsa, NeuroCard}"
- Changeover delay: The setup time incurred when switching to a new resource after a preemption. "Each preemption incurs a changeover delay, representing the setup time on a new instance."
- Congestion control: Algorithms that modulate sending rates to prevent or alleviate network congestion. "congestion control~\cite{jay2018internet}"
- Context window: The maximum amount of text (tokens) an LLM can attend to within a single prompt/session. "the codebase of the real system is often too large to fit within the context window of current LLMs."
- GPU kernel: A performance-critical function executed on GPUs, often requiring specialized optimization. "GPU kernel code generation and optimization~\cite{ouyang2025kernelbench}"
- Island-based population model: An evolutionary search strategy where multiple sub-populations evolve in parallel with occasional migration to maintain diversity. "island-based population models"
- KV cache: A key–value cache used to reuse attention computations and speed up LLM inference. "maximize the hit rate in a KV cache when performing LLM inference."
- Learned indexes: Machine-learned models that replace or augment traditional database index structures. "learned indexes~\cite{kraska2018caselearnedindexstructures}"
- LLM ensemble: Using multiple LLMs together to generate, refine, or select candidate solutions. "an LLM ensemble for code generation"
- MAP-Elites algorithm: A quality–diversity evolutionary algorithm that searches for high-performing solutions across diverse behavioral niches. "MAP elites algorithm"
- Makespan: The total time required to complete a set of jobs or transactions from start to finish. "Minimize makespan in transaction scheduling."
- Mixture-of-Experts (MoE): A neural architecture that routes inputs to specialized expert networks to improve efficiency or capacity. "Mixture-of-Experts (MoE) model"
- MOEA/D: A multi-objective evolutionary algorithm that decomposes a problem into scalar subproblems optimized simultaneously. "MOEA/D"
- NSGA-II: A widely used multi-objective evolutionary algorithm based on fast non-dominated sorting and crowding distance. "NSGA-II"
- Pareto frontier: The set of non-dominated solutions in multi-objective optimization where improving one objective worsens another. "advances the Pareto frontier of the research process."
- Physical device placement: Assigning computation (e.g., neural network operations) to hardware devices to optimize performance or cost. "physical device placement~\cite{Mirhoseini2017DeviceICML}"
- Preemption: The involuntary termination or eviction of a running job or instance by the platform or scheduler. "preempted at any time."
- Reinforcement learning (RL): Learning to make sequences of decisions via trial and error to maximize cumulative reward. "Reinforcement learning (RL) and other learning-based techniques"
- Service Level Objective (SLO): A target threshold for a service metric (e.g., latency) that must be met. "latency SLOs"
- Telemetry: The automated collection and reporting of system metrics from running environments. "network telemetry counters and calibration."
Collections
Sign up for free to add this paper to one or more collections.

