Heterogeneous architectures enable a 138x reduction in physical qubit requirements for fault-tolerant quantum computing under detailed accounting
Abstract: Quantum computer hardware is predicted to scale over hundreds of thousands of qubits coming online in the next decade. Despite significant theoretical and experimental QEC progress, quantum computer architecture has suffered a significant gap, with bottom-up physical-device-driven challenges largely disconnected from top-down QEC-code-driven considerations. In this work, we unify these two views, presenting a complete heterogeneous quantum computing architecture incorporating task-specific hardware selection and QEC encoding, and agnostic to code selection or physical qubit parameters. Our approach further enables special-purpose processing modules, and includes a full microarchitecture for fault-tolerant implementation of interfaces between quantum processing units and quantum memories. Using this architecture and a new fully featured compiler functioning across subsystems at the scale of $1,000$ logical qubits, we schedule and orchestrate a variety of algorithms down to hardware-specific instructions; a detailed accounting of all operations reveals up to 551x reduction in algorithmic logical error and up to 138x reduction in physical-qubit overhead compared to a monolithic baseline architecture. We then consider the factorization of 2048-bit RSA-integers; using an experimentally demonstrated grid-coupling topology, factoring RSA-2048 requires 381k physical qubits and 9.2 days, which can be reduced to 4.9 days via addition of an algorithm-specific accelerator for the Adder subroutine (requiring 439k qubits). Finally, assuming hypothetical long-range coupling, implementing quantum memory using qLDPC codes reduces the resources required for factoring to just 190k qubits and under 10 days. These results and the tooling we have built indicate that heterogeneous quantum-computer architectures can deliver significant, verifiable benefits on realistic hardware.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about building big, reliable quantum computers without needing an impossible number of parts. The authors show a new “heterogeneous” design—meaning different parts of the machine are built for different jobs—that can make quantum computers much more practical. Using this approach, they report up to 138 times fewer physical qubits needed and up to 551 times fewer errors for important tasks, compared to a traditional one-size-fits-all design.
Think of it like a modern computer: you don’t use the same chip to do everything. You have a CPU for general work, a GPU for graphics, memory to store stuff, and a fast connection between them. The authors bring this idea to quantum computers and show it really helps.
The big questions they asked
The paper asks:
- Can we design a quantum computer where different parts specialize in different tasks (computing, storing, and moving quantum information) to save space and reduce errors?
- Can we actually schedule and run large programs using such a design, and count every operation honestly, to see if it really works better?
- How much could this help on hard problems like factoring big numbers (such as RSA-2048), which is a major test for quantum computing?
How they approached it (in everyday terms)
The authors designed a full system and built a detailed compiler to run it end-to-end. Here’s the idea with simple analogies:
- Quantum bits (qubits) are extremely fragile. To keep them safe, we use “logical qubits” made from many “physical qubits,” protected by quantum error correction—like wrapping a delicate object in many layers of bubble wrap.
- In many algorithms, most qubits spend most of their time waiting around (idling). Keeping all of them in an expensive, high-speed “work area” is wasteful.
So they split the machine into specialized parts:
- Quantum Processing Units (QPU): The “workbench.” Small, fast, and designed to perform operations quickly and reliably.
- Magic State Factories (QSF): Think of these like special ingredient kitchens that prepare rare “magic states.” These are needed to perform certain advanced quantum operations. Making them is tricky, so a dedicated unit does it efficiently.
- Application-Specific Accelerators (ASQPU): Like a calculator app built into the system for a subroutine you use a lot (for example, a super-fast adder). It’s not a full general-purpose tool, but it does its one job extremely well.
- Quantum Memory (QM): The “storage room.” A place to keep qubits safe when they’re not being used.
- Static memory (STQM): A short-term, ultra-quiet “shelf” where you can leave a qubit briefly without constantly checking it, like a fast cache.
- Random-access memory (RAQM): Long-term storage with error correction, like RAM that you can access uniformly from anywhere.
- Quantum Bus (QB): The “hallway and conveyor belts” connecting everything. It uses teleportation-like methods (via shared entangled pairs called Bell pairs) to move quantum states safely between units without walking them step-by-step through the crowd.
To make this work in detail, they built:
- Q-NEXUS: The overall hardware architecture (the blueprint of all the parts above).
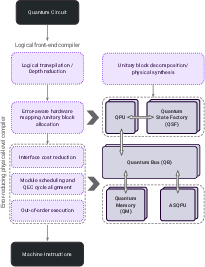
- Q-CHESS: A compiler that acts like the “project manager.” It schedules every instruction, handles different clock speeds (some parts are faster than others), coordinates where qubits move, and ensures all the tiny details are counted. This is key for “detailed accounting,” so the final numbers are realistic.
What they found and why it’s important
Using their architecture and compiler, they tested common building blocks and a full-size challenge. Here are the highlights:
- Big reductions in resources and errors:
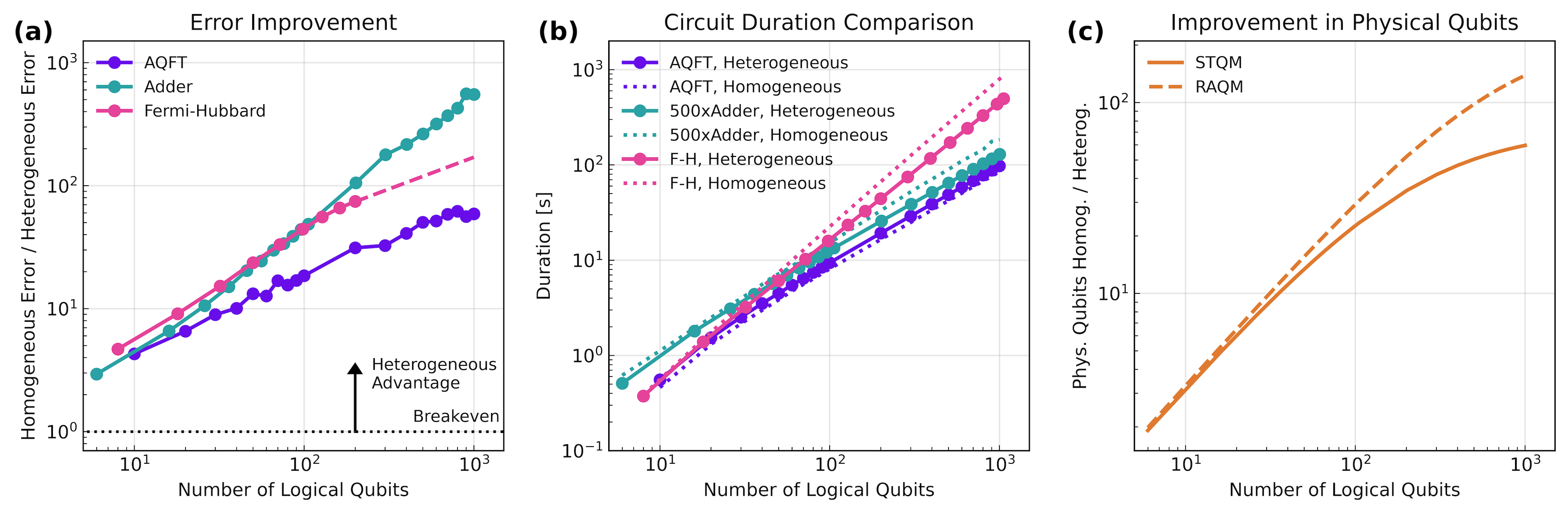
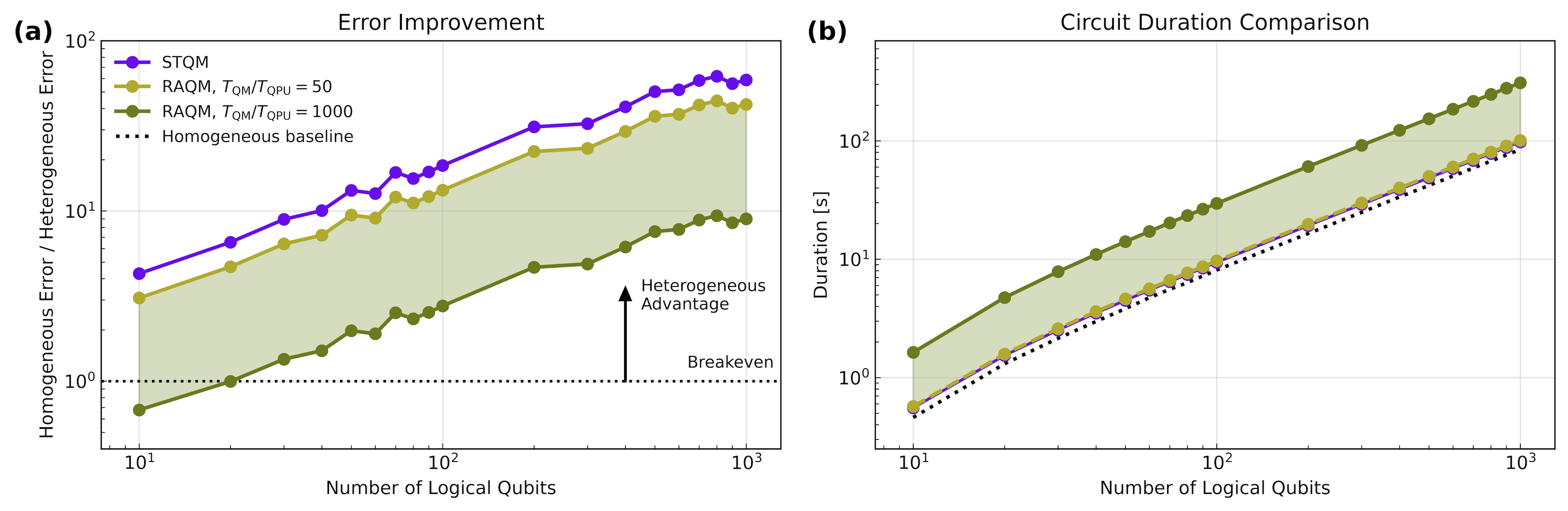
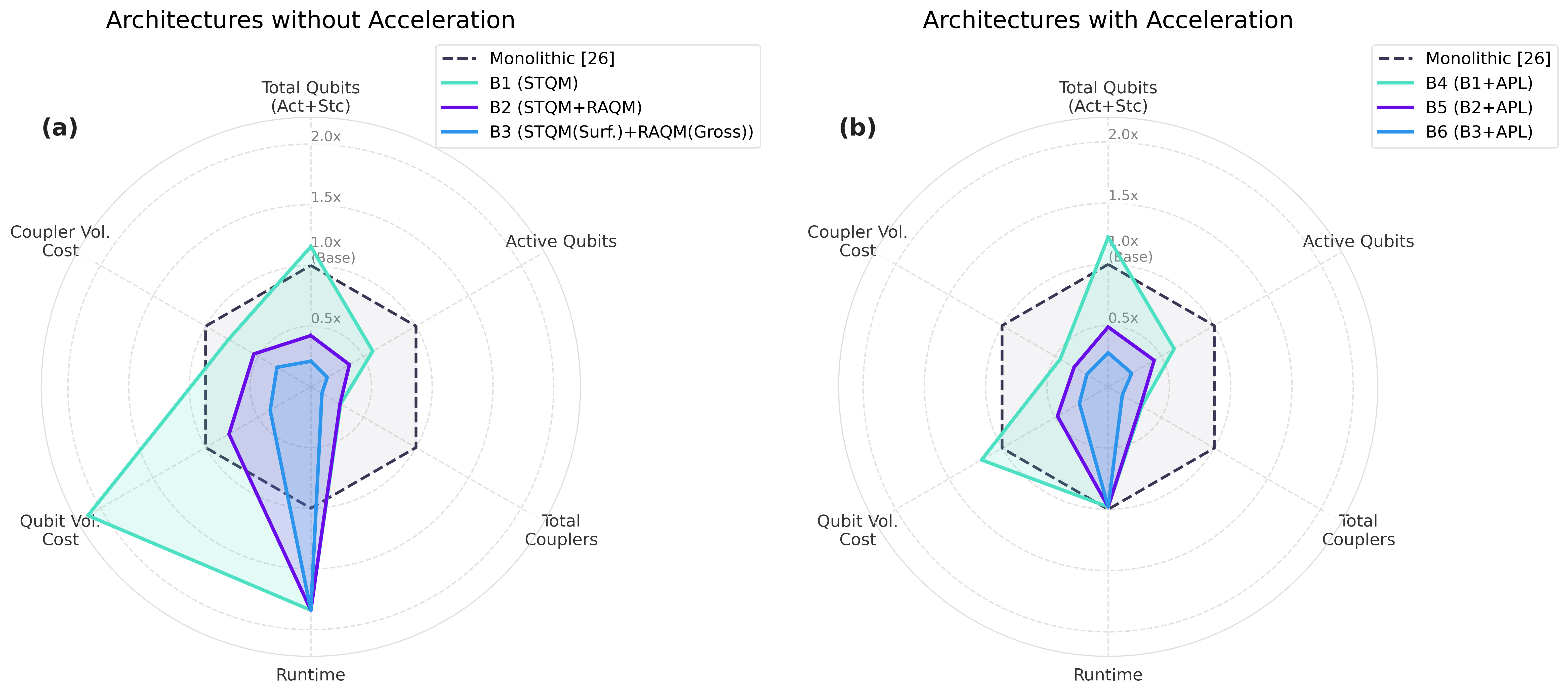
- For the Quantum Fourier Transform (QFT), a key subroutine in many algorithms: 42–59× fewer logical errors and 60–138× fewer physical qubits compared to a traditional “one big block” design.
- For other tasks like an Adder and simulating physics (the Fermi–Hubbard model): more than 100× fewer logical errors.
- Across cases, up to 551× fewer algorithmic logical errors were observed.
- Realistic path to factoring RSA-2048:
- Using an experimentally demonstrated “grid” coupling (no fantasy long-range wires) and two QPUs:
- About 381,000 physical qubits
- About 9.2 days of runtime
- Adding a small, specialized Adder accelerator (37 logical qubits) speeds it up:
- About 439,000 physical qubits
- About 4.9 days of runtime
- If future hardware supports long-range connections and uses high-density memory codes (qLDPC) for storage:
- About 190,000 physical qubits
- Under 10 days
Why this matters:
- These are “bottom-up” resource counts that include real-world costs: moving data, waiting times, different module speeds, and making magic states. It’s not just theory; it’s a blueprint that can fit actual hardware limits like wiring and control electronics.
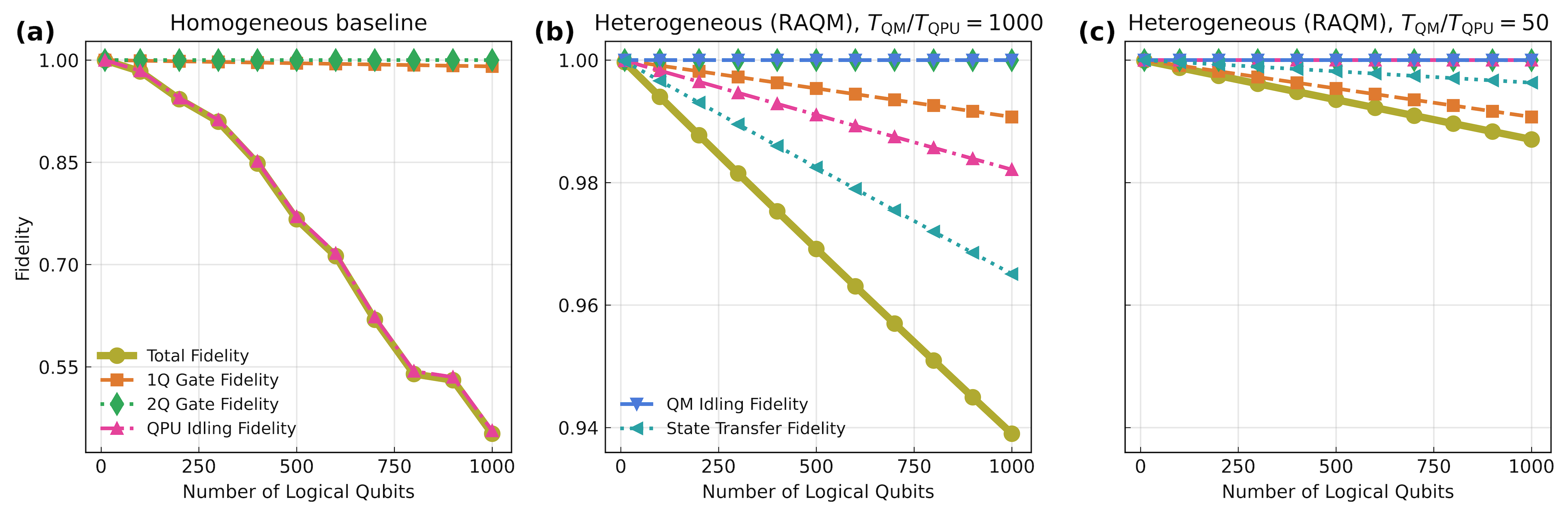
- It shows that separating “where you compute” from “where you store” works very well—especially because many qubits are idle most of the time (around 96–97% in key versions of Shor’s algorithm). Moving them to memory saves space and reduces errors.
What this could mean going forward
- A smarter way to build quantum computers: Instead of trying to make one giant chip that does everything, we can build different modules—each optimized for its job—and connect them. This approach mirrors how modern classical computers evolved (CPU, GPU, RAM, caches, fast interconnects).
- Practical scaling: By storing most qubits in specialized memory and keeping the fast QPU small, we avoid the “tyranny of numbers” problem where wiring, cooling, and control lines become overwhelming.
- Faster progress: The architecture supports mixing different qubit types and different error-correcting codes in the same system. That means labs and companies can pick the best technology for each module and still make it all work together.
- Better planning: Because the authors’ compiler (Q-CHESS) accounts for timing, routing, and all the hidden costs, the estimates can guide real hardware development and help decide which improvements matter most.
In short, the paper shows a practical, modular, and well-measured path to large-scale, fault-tolerant quantum computing—one that uses fewer resources, makes fewer mistakes, and fits better with how actual hardware can be built.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and specific open questions that, if addressed, would strengthen or extend the paper’s contributions.
- Experimental validation: No hardware prototype or end-to-end experimental demonstration of Q-NEXUS/Q-CHESS; identify a minimal viable subset (e.g., single QPU + STQM + bus link) for empirical validation.
- Sensitivity to device parameters: Lack of systematic sensitivity analyses to key assumptions (gate/measurement error rates, cycle times, bus link loss/fidelity, memory T1/T2); quantify thresholds at which the reported 42–551× error and 60–138× qubit savings persist or break down.
- Quantum bus realism: Unspecified bus topology, switching fabric, channel count, and scaling (e.g., optical cross-connect capacity, insertion loss, fanout); provide loss budgets and link budgets that reconcile required Bell-pair rates with realistic photonic/microwave hardware.
- Bus throughput and congestion: No queueing or contention analysis for simultaneous transfers; develop arbitration, scheduling, buffering, and QoS policies and assess their impact on latency and logical error.
- Fault-tolerant transfer protocols (FTTP) detail: Missing fully specified circuits, ancilla counts, and time/space costs for state transfer (including repeated purification and retries); provide failure modes and end-to-end error-budget allocation.
- Code conversion across modules: No concrete, fault-tolerant code-switching protocols (surface/bicycle ↔ qLDPC) with proven correctness, latency, and resource overhead; clarify required intermediate encodings and decoder handoffs.
- Decoder integration and scaling: Absent analysis of decoder types, throughput, and latency across heterogeneous codes; quantify classical compute load and its effect on cycle-time alignment and program stalls.
- Noise model realism: Assumes simplified error models; evaluate impact of leakage, non-Pauli, correlated, time-varying, and crosstalk errors on distillation, purification, code thresholds, and transfer protocols.
- Runtime variance and worst-case bounds: No characterization of stochastic runtime due to probabilistic purification/teleportation; provide distributions (not just means) and tail bounds relevant to SLA-like guarantees.
- Magic-state supply/demand engineering: Underspecified factory sizing, placement, and distribution policies under time-varying demand; analyze pipeline fill/flush times, backlog management, and the runtime impact of supply droughts.
- Static memory (STQM) operating envelope: Unclear maximum safe dwell times without active QEC, error accumulation models (including drift/leakage), and transition protocols in/out of STQM; define calibration and refresh strategies.
- Random-access memory (RAQM) layout and scaling: No quantitative study of SWAP-distance growth, hotspotting, and fragmentation as memory size scales; design placement/routing strategies that minimize average and worst-case access cost.
- qLDPC RAQM feasibility: The “hypothetical long-range coupling” assumption is not supported by a concrete implementation roadmap; compare alternatives using only local connectivity and quantify overhead penalties.
- qLDPC decoder practicality: Missing evaluation of specific qLDPC decoders (latency, accuracy, hardware cost) and their compatibility with real-time scheduling constraints.
- Timing mismatches and buffering: While acknowledged, there is no explicit policy evaluation for buffering, synchronization, and back-pressure across modules with disparate clocks; quantify stall rates and their effect on logical error accumulation.
- Compiler optimality and scalability: Q-CHESS scheduling heuristics and compile-time complexity are unspecified; provide approximation guarantees or empirical optimality gaps, and runtime scaling beyond ~1,000 logical qubits.
- Cache/hierarchy policies: No formal heuristics for when to keep states on QPU vs STQM vs RAQM under uncertain future use and variable transfer latency; evaluate prefetching, eviction, and adaptive policies.
- Multi-core QPU scaling: Limited guidance on load balancing, inter-core communication costs, and when multi-core provides net benefits given bus contention and factory sharing.
- Application-specific accelerators (ASQPU) methodology: Lacks a general framework to identify high-ROI subroutines, co-design their micro-architectures, and validate portability across algorithms; define interface standards and verification practices.
- Benchmark breadth and generality: Results focus on QFT, Adder, Fermi–Hubbard, and Shor; assess broader workloads (e.g., qubitization-based chemistry, error-corrected VQE, amplitude amplification, QAOA variants) to test architectural generality.
- Baseline fairness: Clarify whether the monolithic baseline includes comparable micro-architectural optimizations (e.g., pipelining, buffering) and realistic routing; provide ablation studies isolating each heterogeneous feature’s contribution.
- Error-budget decomposition: Provide per-component contributions (QPU ops, idling, bus transfers, purification, code conversion, RAQM routing, factory errors) to make bottlenecks and trade-offs transparent.
- Physical integration constraints: Absent packaging and cryogenic/thermal analyses for heterogeneous modalities, including photonic feedthroughs, laser delivery, and microwave shielding in large systems.
- Non-qubit resource accounting: No estimates for control/readout wiring, lasers, cryo load, optical components, and classical compute power; include these to validate “tyranny of numbers” mitigation claims.
- Reliability and yield: No discussion of module-level fault isolation, redundancy, and reconfiguration in the presence of defective qubits, dead links, or failed decoders; propose yield models and re-mapping strategies.
- Parallelization of Shor’s outer loop: The work fixes a sequential approach; analyze space–time trade-offs of parallelization within Q-NEXUS (impacts on memory footprint, bus throughput, and factory demand).
- Measurement and feedback latencies: Quantify the effect of disparate measurement speeds and classical feedback paths on pipeline depth and synchronization across modules.
- Scheduling under uncertainty: Develop strategies that adapt at runtime to fluctuating link quality, factory output rates, and decoder backlog while bounding logical error and total time-to-solution.
- Standardized IR and machine ISA: Specify a formal intermediate representation and machine-level instruction set for heterogeneous modules to enable reproducibility and third-party toolchains.
- Security and fault containment: Define how faults or misconfigurations in one module (e.g., a noisy bus segment) are detected, isolated, and prevented from corrupting other subsystems’ logical states.
Practical Applications
Overview
This paper introduces Q-NEXUS, a heterogeneous quantum-computing architecture that cleanly separates computation, communication, and storage, and Q-CHESS, a machine-level, microarchitecture-aware compiler that schedules fault-tolerant programs across modules operating at different clock rates. The work demonstrates large, verifiable gains from architectural heterogeneity and detailed scheduling: up to 551× reduction in logical error and up to 138× reduction in physical-qubit overhead on key subroutines (QFT, Adder, Fermi–Hubbard dynamics), and end-to-end resource estimates for factoring RSA-2048 (e.g., 381k physical qubits and 9.2 days with an experimentally demonstrated grid topology; 4.9 days with an Adder accelerator at 439k qubits; 190k qubits and <10 days assuming qLDPC memory with long-range coupling). Below are actionable applications derived from the architecture, compiler, and analysis.
Immediate Applications
The following can be pursued now with current tools, existing experimental capabilities, and for planning, procurement, and risk management.
- Architecture-driven resource planning and roadmapping (Industry—hardware vendors, cloud providers)
- Use Q-NEXUS’s modular blueprint (QPU, QSF, ASQPU, Quantum Bus, RAQM/STQM memory tiers) to guide chiplet design, interconnect R&D, and scaling plans; leverage the paper’s detailed accounting to set performance targets (e.g., bus fidelity, memory access latency, distillation throughput).
- Dependencies: credible device parameters; access to interconnect prototypes; coordination between hardware, control, and compiler teams.
- Machine-level heterogeneous compilation for realistic resourcing (Academia/Industry—software tooling, benchmarking)
- Adopt or replicate Q-CHESS-style compilers to produce machine instructions and schedules that include routing, buffering, and timing mismatches across modules; use on QFT, arithmetic, and simulation benchmarks to quantify true costs and identify bottlenecks.
- Dependencies: availability/integration of a Q-CHESS-like toolchain; mapping to target hardware’s native gates, cycle times, and connectivity.
- Algorithm-specific accelerator design workflow (Industry/Academia—hardware–software co-design)
- Prototype ASQPU modules (e.g., Adder, QFT) and measure space–time tradeoffs; integrate with compilers to place high-frequency subroutines on accelerators for performance gains (as shown for RSA’s Adder).
- Dependencies: physical integration with interconnect; validated accelerator microcode; compatibility with the system’s error-correction stack.
- Magic-state factory (QSF) sizing, placement, and runtime scheduling (Industry—superconducting, trapped-ion labs)
- Plan dedicated distillation pipelines, buffer depths, and connectivity to QPUs to avoid T-state starvation; apply compiler-based rate matching of QSF output to algorithm demand.
- Dependencies: measured distillation yields and cycle times; classical control latency; calibrated transfer paths to/from QPUs.
- Interconnect and quantum bus protocol testing (Industry—photonics/microwave interconnects; Labs)
- Implement and benchmark teleportation-based, fault-tolerant transfer microarchitectures and Bell-pair purification at small scale to validate quantum-bus design choices and error budgets.
- Dependencies: demonstrated entanglement distribution/purification; synchronization electronics; error tracking of transfer protocols.
- Standards-ready metrics and procurement specifications (Policy/Government/Industry consortia)
- Translate detailed accounting into KPIs for RFPs: bus yield/fidelity, memory access latency, logical-cycle timings, distillation throughput, code-conversion costs; align funding calls and milestones to architectural metrics rather than qubit counts alone.
- Dependencies: stakeholder consensus; participation in standards bodies; repeatable metrology.
- Cryptographic risk assessment and PQC migration prioritization (Finance/Cybersecurity/Policy)
- Use the RSA-2048 resource–time projections (9.2 days with 381k qubits under grid coupling assumptions; faster with accelerators) as scenario inputs for enterprise and national PQC timelines and for updating threat models and compliance roadmaps.
- Dependencies: acceptance that timelines depend on engineering assumptions; continuous tracking of hardware progress and code advances.
- Cloud and datacenter capacity planning for quantum workloads (Cloud providers/HPC centers)
- Build scheduling and capacity models using the paper’s timing-aware orchestration (e.g., memory hierarchy, multi-core QPU, routing latencies) to plan module counts, queues, and service-level objectives.
- Dependencies: integration with classical orchestration systems; realistic hardware availability and utilization data.
- Benchmarking suites and open datasets for heterogeneous FT execution (Academia/Industry)
- Package QFT, Adder, and simulation workloads with machine-level schedules to benchmark heterogeneous stacks and validate end-to-end improvements versus monolithic baselines.
- Dependencies: public toolchains and reproducible parameter sets; agreement on benchmark rules and reporting.
- Education and workforce training on stored-program quantum architectures (Academia/Training providers)
- Use Q-NEXUS and Q-CHESS as concrete teaching tools for memory hierarchies, interconnect protocols, and microarchitectural scheduling in FT quantum systems.
- Dependencies: course materials and lab exercises; access to simulators or small modular testbeds.
Long-Term Applications
These require further research, scaling, or development of hardware, codes, interconnects, and control systems.
- Heterogeneous quantum data centers implementing Q-NEXUS (Industry—hardware vendors, cloud providers)
- Deploy multi-module systems with fixed-size QPUs, high-throughput QSFs, ASQPUs, a fault-tolerant quantum bus, and hierarchical RAQM/STQM memory tiers for large-scale workloads.
- Dependencies: robust high-fidelity interconnects; synchronized control stacks; validated error-correction pipelines at scale.
- RSA-2048 (and beyond) factoring capability (Policy/Defense/Finance)
- Realize the paper’s end-to-end factoring scenarios with grid-coupled or long-range-coupled qLDPC memory, updating national cryptographic policies, incident response plans, and deprecation timelines for legacy crypto.
- Dependencies: achieving target physical error rates and logical cycle times; scalable magic-state supply; reliable bus and code-conversion.
- Quantum memory products as modular subsystems (Industry—quantum memory vendors)
- Commercialize RAQM (active QEC, random access) and STQM (static cache-like stores) modules with standardized interfaces to QPUs and buses; offer capacity-driven scaling of quantum data retention.
- Dependencies: memory modalities with ultra-long coherence, practical access latencies, and high-rate codes; efficient decoders; thermal and control integration.
- Application-specific quantum accelerators (ASQPU portfolio) (Industry—vertical solutions)
- Build accelerator lines for QFT/phase estimation, arithmetic (adders/multipliers), chemistry oracles, and T-factory-dense subroutines to reduce runtime and qubit overhead on target verticals (e.g., chemistry, cryptography).
- Dependencies: tight compiler integration; validation of speedups under FT constraints; interoperability over the bus.
- Fault-tolerant quantum bus networks with all-to-all logical connectivity (Industry—photonics/microwave vendors)
- Create rack-scale interconnect fabrics with entanglement distribution, purification, and switching to connect many modules at high fidelity and throughput.
- Dependencies: scalable sources/detectors/transducers; low-loss channels; automated calibration; networked error tracking and recovery.
- Multi-code execution with code conversion (Academia/Industry—codes and decoding)
- Operate surface/bicycle codes in QPUs and high-rate qLDPC codes in memory, with efficient logical code conversion over the bus to maximize density and performance.
- Dependencies: low-overhead, high-fidelity logical code conversion; fast decoders for qLDPC at scale; error-model validation across codes.
- Quantum operating systems for heterogeneous FT orchestration (Software/Cloud)
- Develop runtime services for scheduling, buffering, memory placement (RAQM vs STQM vs QPU), distillation flow control, and transfer optimization across modules with disparate clocks.
- Dependencies: standardized machine-level instruction sets; telemetry and health monitoring; formal verification of safety/liveness properties.
- Industrial-scale quantum simulation for materials and energy (Energy/Chemistry/Manufacturing)
- Use the demonstrated reductions in logical error and qubit counts for core subroutines (e.g., QFT, Trotterization) to reach practically relevant simulations (catalysts, battery materials, superconductors).
- Dependencies: FT hardware scale; domain-specific algorithm/compiler co-design; validated Hamiltonian models and error mitigation within FT.
- Finance and logistics optimization under FT constraints (Finance/Transportation)
- Execute resource-intensive quantum algorithms (phase estimation, amplitude estimation, oracles) more efficiently via accelerators and memory hierarchies to improve solution quality or runtime.
- Dependencies: mature FT stacks; proven advantage for specific instances; integration with classical data pipelines.
- Standards and regulatory frameworks for modular FT systems (Policy/Standards bodies)
- Establish inter-module protocol standards (interfaces, code-conversion semantics, instruction encodings), performance certification, and safety/compliance baselines for quantum data centers.
- Dependencies: industry alignment; interoperable reference implementations; certification authorities and test suites.
- Cross-modality supply chains and manufacturing (Industry—semiconductor/photonics/control)
- Build coordinated ecosystems for QPU chips, memory substrates, photonic/microwave interconnects, cryo/control electronics, and calibration software, aligned to heterogenous architectures.
- Dependencies: stable vendor interfaces, IP/licensing frameworks, and long-term component reliability.
- Hybrid quantum–classical HPC integration (HPC centers)
- Co-locate modular quantum systems with exascale HPC to manage pre/post-processing, decoding, and classical feedback loops with low latency and high throughput.
- Dependencies: high-bandwidth classical links, decoder acceleration (e.g., GPUs/FPGAs), co-scheduling with HPC job managers.
Key Assumptions and Dependencies Across Applications
- Physical-layer performance: target gate/measurement error rates and logical cycle times as assumed in the paper’s tables; stability over long runs.
- Interconnects: availability of high-quality Bell-pair generation and purification; reliable photonic/microwave links; low-latency synchronization.
- Codes and decoding: practical, high-rate qLDPC codes (for RAQM) with fast decoders; efficient code-conversion protocols with bounded overhead.
- Control stack: deterministic, low-jitter orchestration across modules with disparate clocks; telemetry for fault detection and recovery.
- Compiler/tooling: access to Q-CHESS-like machine-level schedulers; correctness and performance validation on heterogeneous targets.
- Engineering scale-up: cryogenic capacity, wiring, calibration automation, and yield management compatible with bounded-size QPUs and large memory tiers.
- Ecosystem alignment: standards for module interfaces and instruction sets; supply-chain maturity for cross-modality components.
Glossary
- Adder: An arithmetic subroutine that adds two numbers within a quantum algorithm, often a performance bottleneck in Shor-like circuits. "via addition of an algorithm-specific accelerator for the Adder subroutine (requiring 439k qubits)."
- algorithmic logical error: The effective error rate of a quantum algorithm at the logical level after error correction and scheduling are considered. "up to reduction in algorithmic logical error"
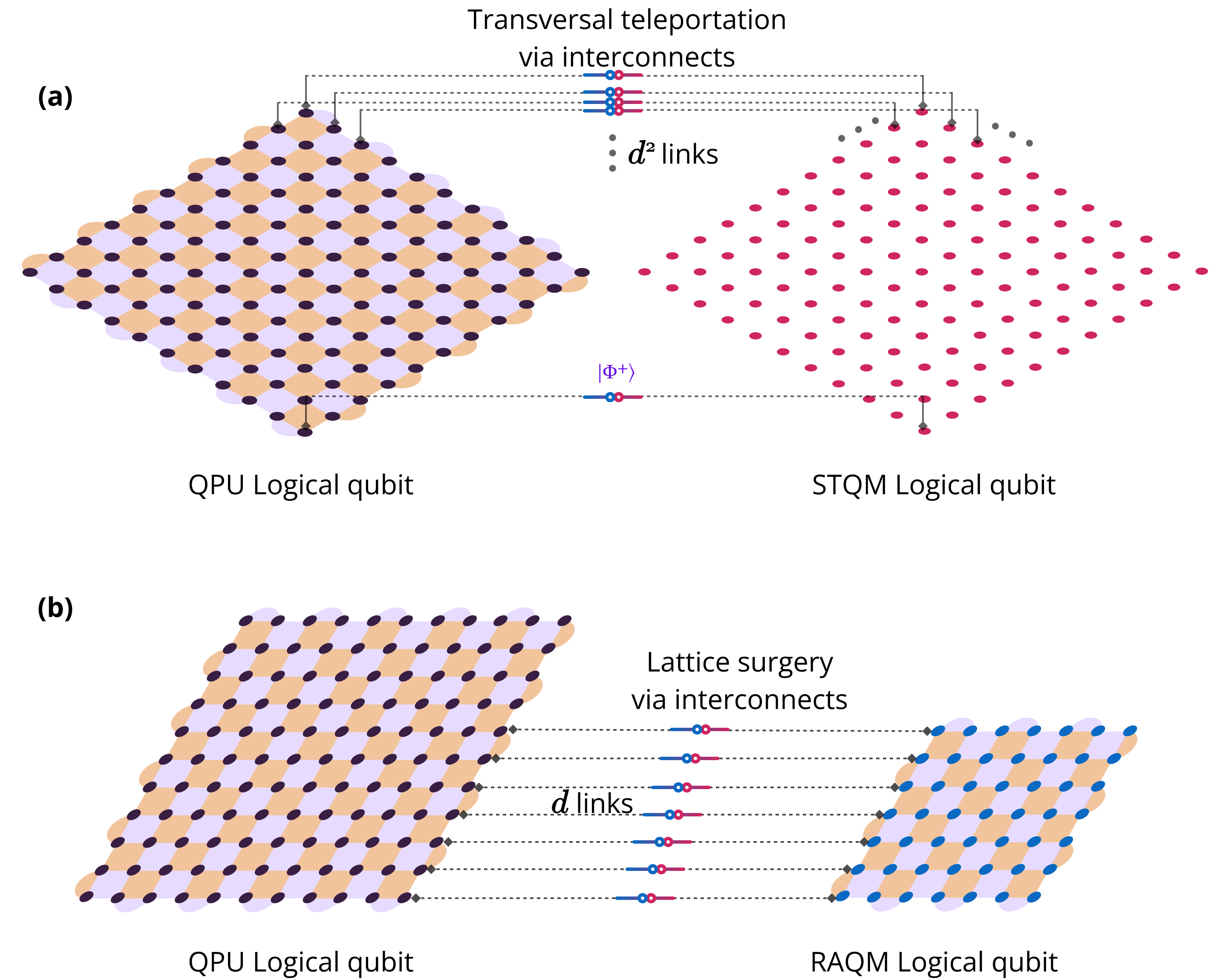
- all-to-all logical connectivity: A connectivity model where any logical qubit can interact with any other via the interconnect, reducing routing overhead. "The interconnect bus mediates all-to-all logical connectivity via optical connections (black lines)"
- application-specific quantum processing unit (ASQPU): A specialized processor that efficiently implements a restricted, frequently used set of quantum operations to accelerate a target algorithm. "The architecture should support APpLication-specific quantum processing units (ASQPU) that apply specialized logic operations to quantum data -- those which occur in a target algorithm with high frequency -- when they reduce execution time or resource overhead."
- Bell-pair generation: The creation of entangled qubit pairs used as a resource for teleportation-based communication. "where Bell-pair generation enables teleportation-based state transfer."
- Bell-pair purification: A protocol that boosts the fidelity of entangled pairs by combining multiple noisy pairs to distill higher-quality entanglement. "Using an experimentally demonstrated Bell-pair purification scheme"
- bivariate bicycle codes: A family of quantum LDPC codes with favorable properties for implementing logical operations in certain architectures. "surface-codes \cite{Litinski2019} and bivariate bicycle codes \cite{Yoder2025}"
- CCZ-state: A multi-qubit magic resource state enabling implementation of the non-Clifford controlled-controlled-Z (CCZ) gate in fault-tolerant computation. "delays in CCZ-state supply"
- code conversion: The process of reliably transforming a logical state from one quantum error-correcting code to another. "the quantum bus should therefore support code conversion"
- code distance: A parameter of a quantum error-correcting code that determines how many physical errors can be detected/corrected and influences logical error rates. "reporting outcomes in terms of physical qubit numbers, code distances, and asymptotic error scaling."
- code-first: An approach where architectural choices are primarily driven by properties and assumptions of a single error-correcting code. "the key structural and analytic ``code-first'' approaches have been maintained"
- dilution refrigerator: An ultra-low-temperature cryostat used to operate certain qubit technologies (e.g., superconducting qubits). "a single dilution refrigerator"
- fault-tolerant transfer protocols: Procedures that move quantum information between modules while preserving encoded fault-tolerant properties. "with a MiCRo-architecture that includes fault-tolerant transfer protocols and resource generation."
- Fermi–Hubbard model: A fundamental model in condensed matter physics used to study interacting electrons on a lattice, often targeted by quantum simulation algorithms. "For dynamic simulations of the FermiâHubbard model and for arithmetic (Adder)"
- grid-coupling topology: A hardware connectivity layout where qubits are arranged on a grid with local couplings. "using an experimentally demonstrated grid-coupling topology"
- grid topology: A regular two-dimensional lattice connectivity constraint used to model realistic nearest-neighbor device couplings. "Further limiting physical connectivity to grid topology accounts for otherwise challenging growth in coupler counts, frequency collisions, and calibration burden"
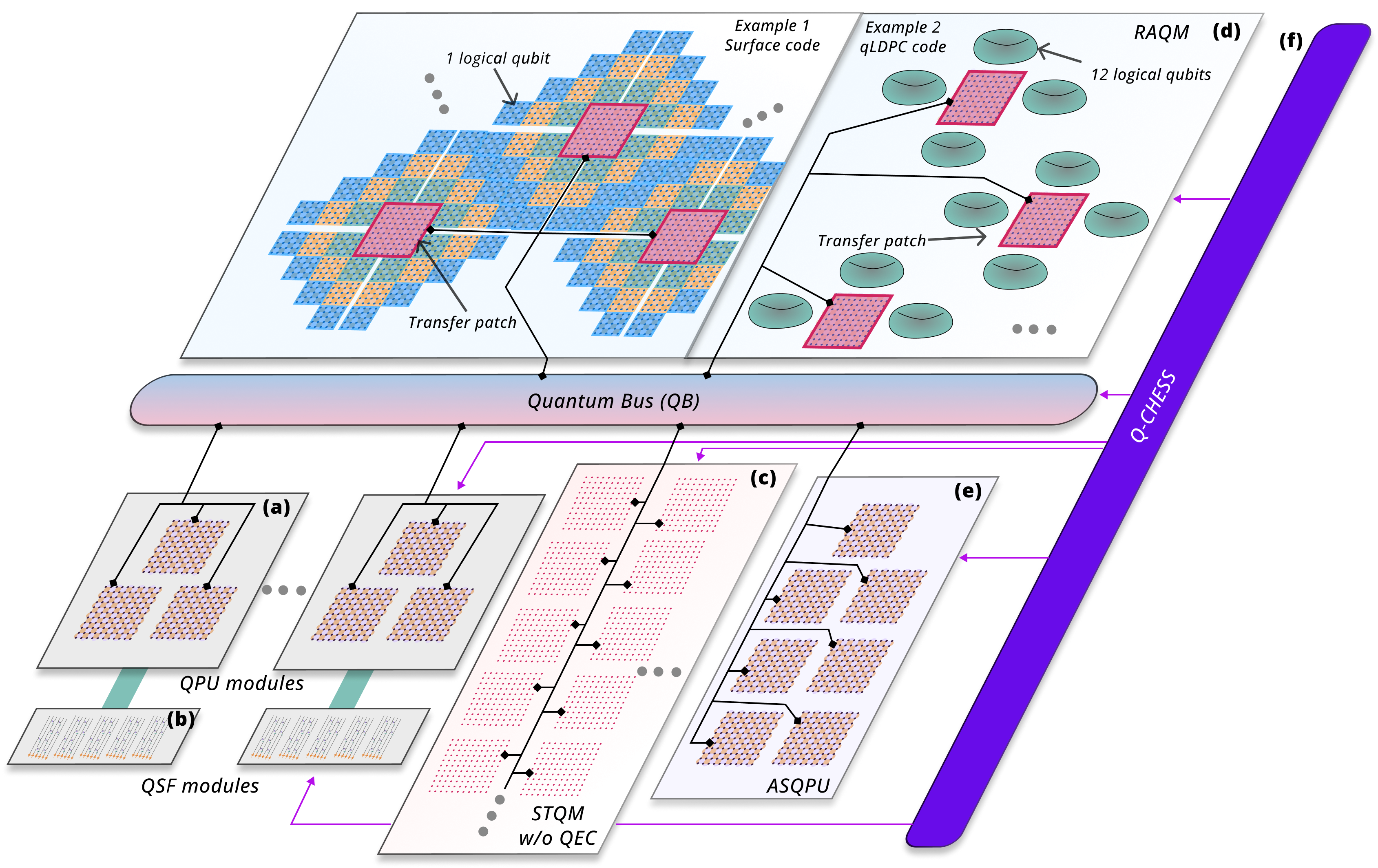
- heterogeneous quantum computing architecture: A system design that combines different types of hardware modules (and possibly qubit modalities/codes) specialized for distinct roles. "presenting a complete heterogeneous quantum computing architecture incorporating task-specific hardware selection and QEC encoding"
- logical clock cycles: Discrete time steps at the logical layer during which encoded operations or error-correction rounds are scheduled. "on average each qubit is inactive for of logical clock cycles."
- logical patches: Encoded logical-qubit regions in a lattice-based code representation that may need routing for operations or transfers. "logical patches must be routed to the nearest transfer patch"
- logical SWAP: A logical operation that exchanges the positions (or identities) of two encoded qubits, often used for routing on constrained topologies. "LoNG-range routing of quantum data should be handled by the QB when it reduces logical (SWAP) operations."
- magic state: A specially prepared non-stabilizer state used to enable non-Clifford gates in fault-tolerant schemes. "Magic states for non-Clifford operations on quantum data shall be generated by a specialized quantum state factory (QSF)."
- magic state distillation: A process that converts many noisy magic states into fewer, higher-fidelity ones necessary for reliable non-Clifford computation. "Magic state distillation is a dominant overhead in fault-tolerant resource estimates"
- micro-architecture: The detailed, low-level organization and protocol design that governs how components implement instructions and transfers. "with a MiCRo-architecture that includes fault-tolerant transfer protocols and resource generation."
- non-Clifford operations: Quantum gates outside the Clifford group (e.g., T, CCZ) required for universal quantum computation and typically more costly fault-tolerantly. "Magic states for non-Clifford operations on quantum data shall be generated by a specialized quantum state factory (QSF)."
- nonlocal physical connectivity: Hardware capability allowing interactions between qubits that are not adjacent in physical layout. "the nonlocal physical connectivity, required in \cite{Yoder2025} using qLDPC codes, is achievable in memory"
- photonic interconnects: Optical channels and components used to connect quantum modules over distance, enabling entanglement distribution and state transfer. "photonic \cite{Monroe2014} or transduction-based \cite{Heya2025} interconnects applied to enable connectivity between modules."
- qLDPC codes: Quantum low-density parity-check codes that offer high rate and favorable scaling for storage, sometimes at the expense of gate simplicity. "implementing quantum memory using qLDPC codes reduces the resources required for factoring"
- quantum bus (QB): A communication fabric that moves quantum states between modules, often via teleportation over entangled links. "The architecture shall include a quantum bus (QB) for communication of quantum information between modules"
- quantum compiler (Q-CHESS): A micro-architecture-aware toolchain that schedules, routes, and synthesizes machine-level instructions for heterogeneous systems. "Control of quantum data shall be performed by Q-CHESS: a Quantum Compiler for Heterogeneous Execution Scheduling and Synthesis, which is micro-architecture aware and outputs Machine-level instructions."
- quantum error correction (QEC): Techniques using redundancy and measurement to protect quantum information from noise and enable scalable computation. "quantum error correction (QEC)"
- quantum Fourier Transform (QFT): A key subroutine that performs the discrete Fourier transform on quantum amplitudes, central to algorithms like Shor’s. "For the Quantum Fourier Transform (QFT) --- a subroutine critical to many implementations of Shorâs algorithm \cite{Kutin2006} --- our heterogeneous framework achieves a reduction"
- quantum memory (QM): A storage module designed for long-lived preservation of quantum states, decoupled from compute-intensive hardware. "The architecture shall include a dedicated quantum memory (QM) tier for storing IDLe quantum data."
- quantum processing unit (QPU): A fixed-size compute module that executes universal fault-tolerant logic on a bounded number of logical qubits. "Computation of universal fault-tolerant quantum logic on quantum data shall be performed within fixed-size quantum processing unit(s) (QPU)."
- quantum state factory (QSF): A dedicated module for producing and distilling resource states (e.g., magic states) needed for non-Clifford gates. "Magic states for non-Clifford operations on quantum data shall be generated by a specialized quantum state factory (QSF)."
- random-access quantum memory (RAQM): A memory tier with approximately uniform access latency regardless of where a state is stored, supporting active QEC during storage. "The architecture should include a random-access quantum memory (RAQM) tier capable of storing quantum data with uniform access latency."
- routing: The process of moving logical qubits within or across modules to satisfy gate connectivity constraints, typically incurring SWAP overheads. "Routing is a dominant contributor to fault-tolerant overhead"
- Shor’s algorithm: A quantum algorithm for integer factorization that leverages period finding, often used to assess resource requirements. "For the Quantum Fourier Transform (QFT) --- a subroutine critical to many implementations of Shorâs algorithm \cite{Kutin2006} ---"
- static transversal quantum memory (STQM): A short-term storage tier relying on ultra-long coherence without active error correction, deferring QEC to the QPU. "a distinct ``Static'' transversal quantum memory (STQM) tier that defers active QEC to the QPU"
- stored-program architecture: A computing paradigm where instructions and data are stored in memory and fetched for execution, inspiring the quantum design analogy. "establishing the stored-program architecture."
- syndrome extraction: The process of measuring stabilizers to detect errors in an error-correcting code without collapsing logical information. "By eliminating the need for continuous syndrome extraction and feedback"
- teleportation-based state transfer: Moving quantum states by consuming entanglement and classical communication, avoiding direct qubit movement. "Bell-pair generation enables teleportation-based state transfer."
- T-cultivation: The generation and refinement of T-type magic states to supply non-Clifford gates in fault-tolerant circuits. "fully account for the physical qubits required for fault tolerant state-transfer and high quality T-cultivation,"
- transduction-based interconnects: Interfaces that convert quantum information between different carrier types (e.g., microwave-to-optical) for long-range links. "photonic \cite{Monroe2014} or transduction-based \cite{Heya2025} interconnects applied to enable connectivity between modules."
- transversal teleportation: A code-level operation where teleportation is applied transversally across encoded blocks, preserving fault tolerance. "enabling transversal teleportation between the dedicated transfer patches"
- transversality: A fault-tolerance property allowing certain logical gates to be implemented by applying gate operations independently across code blocks. "transversality is not relevant in memory where logical operations between encoded qubits are not anticipated"
- transfer patch: A designated region or patch used to interface memory code patches with the interconnect for state transfers. "logical patches must be routed to the nearest transfer patch"
- toroidal manifolds: Donut-shaped topological structures used to illustrate or implement certain code layouts (e.g., bicycle codes). "Toroidal manifolds (donuts) illustrate a module of 12 qubits in the ``Gross\" bivariate bicycle code."
- tyranny of numbers: A scaling challenge where system complexity (e.g., wiring/interconnects) grows rapidly with component count, hindering straightforward scaling. "the quantum industry is now confronting its own ``tyranny of numbers''"
- ultra-long coherence (ULC): Exceptionally long qubit coherence times that allow storage without frequent error correction. "ultra-long coherence times (ULC)"
- von Neumann: Refers to the foundational stored-program computing architecture and its design principles, used here as an analogy for quantum systems. "and traces back to the original proposal by von Neumann et al."
Collections
Sign up for free to add this paper to one or more collections.

