RAGEN-2: Reasoning Collapse in Agentic RL
Abstract: RL training of multi-turn LLM agents is inherently unstable, and reasoning quality directly determines task performance. Entropy is widely used to track reasoning stability. However, entropy only measures diversity within the same input, and cannot tell whether reasoning actually responds to different inputs. In RAGEN-2, we find that even with stable entropy, models can rely on fixed templates that look diverse but are input-agnostic. We call this template collapse, a failure mode invisible to entropy and all existing metrics. To diagnose this failure, we decompose reasoning quality into within-input diversity (Entropy) and cross-input distinguishability (Mutual Information, MI), and introduce a family of mutual information proxies for online diagnosis. Across diverse tasks, mutual information correlates with final performance much more strongly than entropy, making it a more reliable proxy for reasoning quality. We further explain template collapse with a signal-to-noise ratio (SNR) mechanism. Low reward variance weakens task gradients, letting regularization terms dominate and erase cross-input reasoning differences. To address this, we propose SNR-Aware Filtering to select high-signal prompts per iteration using reward variance as a lightweight proxy. Across planning, math reasoning, web navigation, and code execution, the method consistently improves both input dependence and task performance.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “RAGEN-2: Reasoning Collapse in Agentic RL”
Overview: What is this paper about?
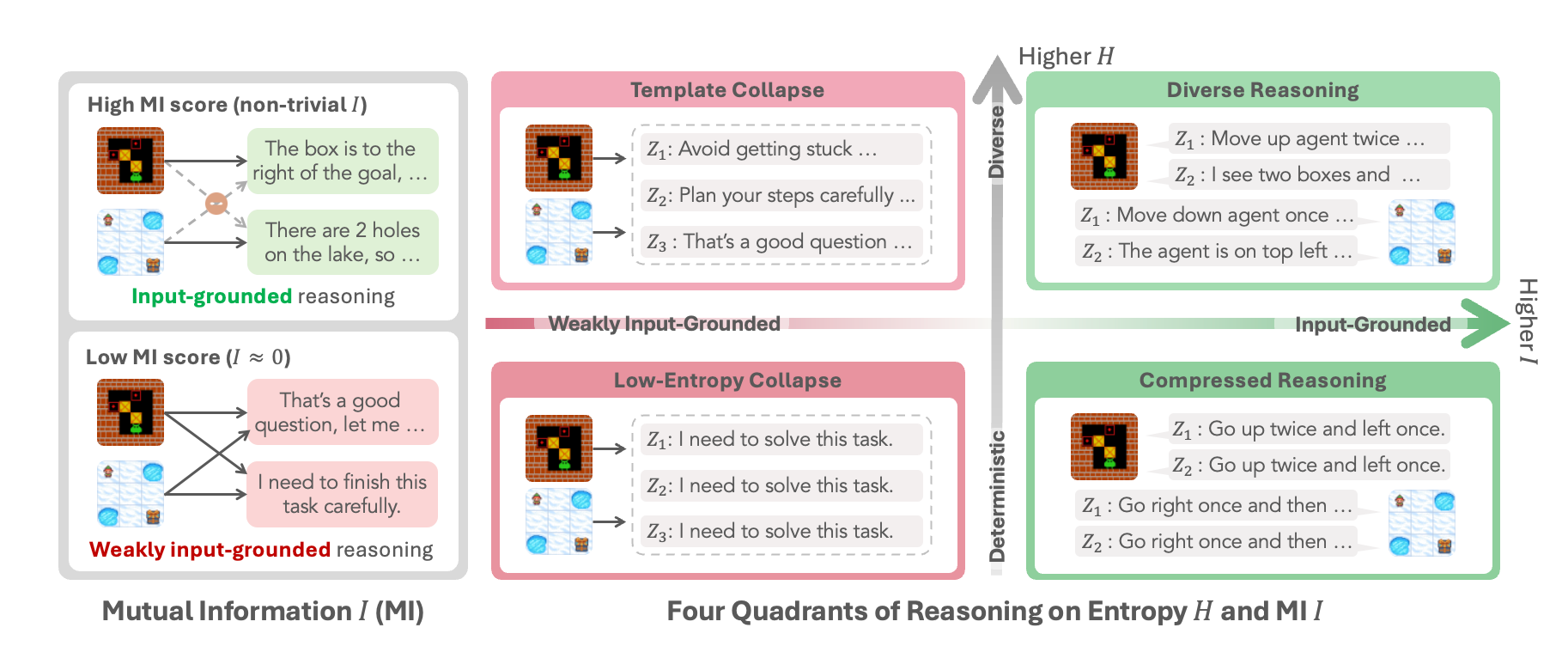
This paper looks at how to train AI “agents” that think and act over multiple steps, like a chatbot that plans, searches the web, or writes code while explaining its thoughts. The authors discovered a hidden problem they call “template collapse,” where the agent’s thinking looks varied and fluent, but actually stops responding to the specific input or task. They show how to detect this problem better and how to fix it so the agent’s reasoning truly depends on the input.
Key questions the paper asks
- How can we tell if an AI’s step-by-step reasoning really depends on the input, instead of just following a one-size-fits-all script?
- Why does “template collapse” happen during training?
- What simple change can we make to training to prevent it?
Methods and ideas in simple terms
- Training setup: The agent learns by trial and error (reinforcement learning, or RL). It tries things, gets rewards (scores), and adjusts. While learning, people often track “entropy,” which is a measure of randomness or variety in the agent’s responses. High entropy means the agent isn’t just repeating the same sentence every time.
- Why entropy isn’t enough: Entropy tells us how varied the agent’s words are for a single input, but not whether the agent changes its reasoning across different inputs. An agent can keep sounding varied for each question yet recycle the same general template across all questions. That’s template collapse.
- A better detector: mutual information (MI)
- Think of a “name that question” game. You collect the agent’s reasoning from different questions and ask: from this reasoning alone, can we tell which question it came from?
- If you can match reasoning to the right question often, mutual information is high. That means the agent’s thinking depends on the input. If you can’t, mutual information is low—likely template collapse.
- The authors build practical “MI proxies” that use a simple trick: score each reasoning trace against all questions in the batch to see which question it fits best. No extra models are needed.
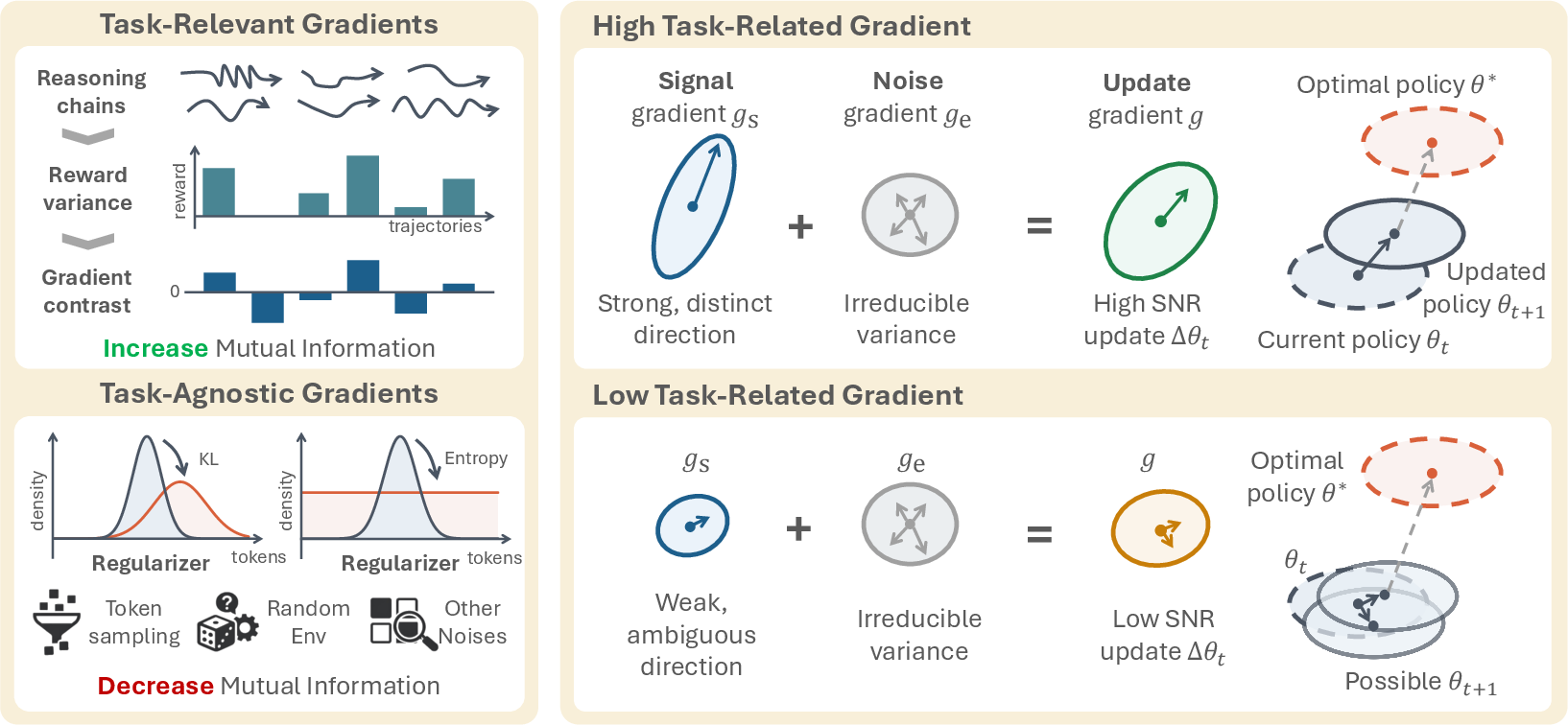
- Why collapse happens: the signal-to-noise ratio (SNR) story
- Imagine trying to listen to a friend in a loud room. If the friend’s voice (signal) is quiet and the room is loud (noise), you’ll miss details and only catch generic words.
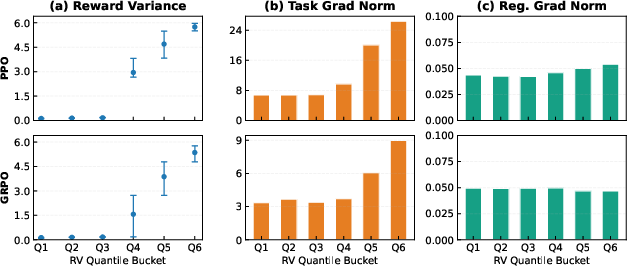
- In training, “signal” comes from clear differences in reward between good and bad attempts on the same question (called reward variance). “Noise” comes from randomness and “regularizers”—general rules that keep the agent from changing too much or becoming too random.
- When reward differences are small (low variance), the training updates are mostly driven by these general rules, not by what’s actually useful for each question. The result: the agent learns safe, generic templates that ignore input details.
- The fix: SNR-Aware Filtering
- Each training round, keep only the questions where different tries actually get meaningfully different rewards (high reward variance). Update the model using those, and skip the rest for that round.
- This focuses training on clear, informative examples, boosting the “signal” the model gets and preventing input-agnostic templates.
Main findings and why they matter
Here are the main takeaways from the experiments across planning puzzles, math problems, web navigation, and code tasks, with different models and training methods:
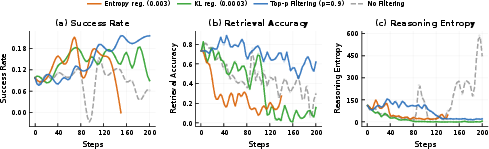
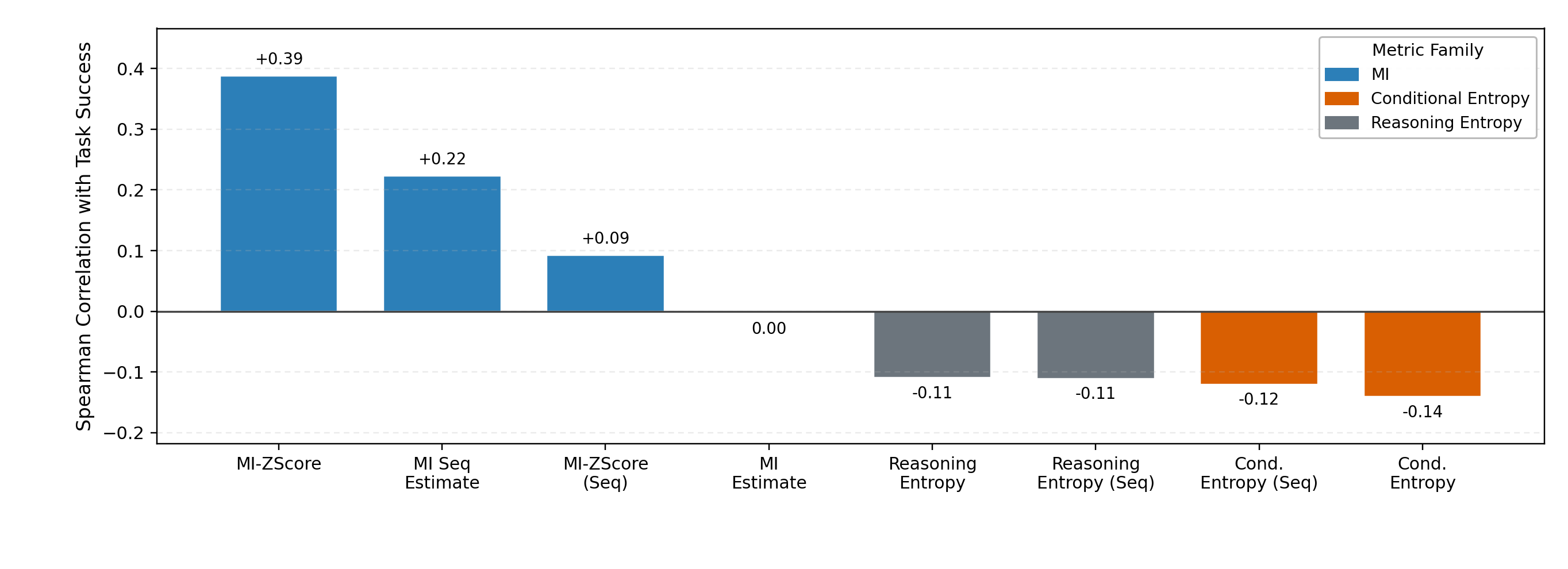
- Mutual information beats entropy for monitoring reasoning quality.
- MI aligns much better with real performance. Entropy can look fine while reasoning is quietly collapsing.
- MI often drops early—before task scores fall—making it a useful early warning sign.
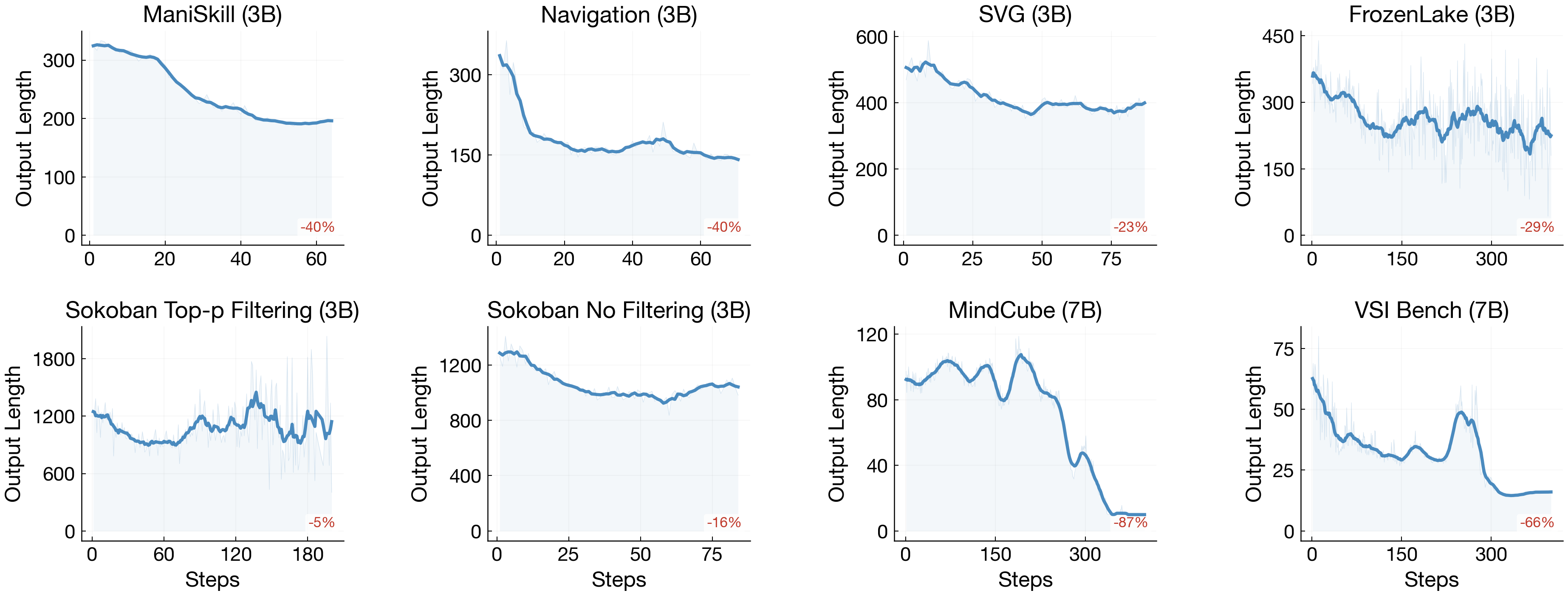
- Template collapse is common without special care.
- Agents start producing shorter, more formulaic thinking. It still looks “varied,” but it stops changing with the input.
- SNR-Aware Filtering improves both reasoning and task success.
- By training more on high-variance (high-signal) prompts, models performed better across many settings.
- A “top‑p” style filter (keeping a variable fraction based on total variance mass) worked better than keeping a fixed number (top‑k).
- It usually adds little to no compute cost and can even speed things up because fewer low-signal updates are used.
- Boundary conditions are clear.
- In very noisy environments (where results are mostly random), reward variance becomes a weaker signal and the advantage of filtering shrinks. This matches the SNR explanation.
What this means going forward
- Better training monitors: Don’t rely only on entropy. Track mutual information to see if the agent’s thinking truly depends on the input.
- More reliable agents: Use SNR-Aware Filtering to avoid “copy-paste thinking.” This makes agents more trustworthy for multi-step tasks like planning, math, browsing, and coding.
- General tool, broad benefits: The approach works with different algorithms, model sizes, and even with images, making it a practical “knob” for more stable, input-sensitive learning.
In short, the paper shows that it’s not enough for an AI to sound thoughtful—it has to think differently when the input changes. Measuring mutual information and training with SNR-Aware Filtering helps ensure exactly that.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Lack of theoretical guarantees for the proposed mutual-information proxies: quantify estimator bias/variance, consistency with true , and conditions under which in-batch cross-scoring is a valid surrogate.
- Sensitivity of MI proxies to batch composition and settings: assess robustness to changes in batch size , group size , prompt diversity, and sequence length; develop batch-invariant or calibrated variants.
- Proxy gaming risk: determine whether models can inflate MI scores by echoing prompt-specific tokens or stylistic cues; design anti-gaming controls and audits.
- Entropy estimation mismatch: the paper uses cross-entropy–based surrogates rather than true ; quantify the discrepancy and explore more faithful entropy estimators for reasoning traces.
- Scope of what is measured: MI is computed on reasoning tokens but excludes action tokens and boundaries; evaluate MI including actions and per-turn action–reasoning interactions.
- Turn-wise dynamics: analyze across turns to identify when collapse emerges within an episode and whether early-turn interventions suffice.
- Computational scalability: benchmark cross-scoring overhead at larger , longer contexts, and larger models; explore approximations (e.g., negative sampling, cached KV reuse, partial scoring).
- Generalization to frontier-scale and diverse model families: validate findings on models beyond 7B parameters and across more architectures and instruction-tuned variants.
- Task and domain breadth: extend evaluation to real-world web automation, complex tool-use pipelines, codebases, robotics, and long-horizon sequential tasks with partial observability.
- Modality breadth: systematically test multimodal agents beyond limited VL settings (e.g., richer visual tasks, speech, and vision-language-action environments).
- Modest MI–performance correlation: the reported Spearman correlations (e.g., +0.39) are moderate; quantify per-task variability, confidence intervals, and when MI fails to predict performance.
- Operational thresholds: define actionable thresholds or control charts for MI that trigger interventions (e.g., filtering, hyperparameter changes) with validated false-positive/negative rates.
- Theory of the SNR mechanism: move beyond qualitative arguments to derive explicit conditions (in terms of reward variance and regularization coefficients) under which regularization dominates task gradients.
- Alternative SNR proxies: investigate proxies that remain informative under high environmental stochasticity (e.g., advantage variance, gradient norm/cosine similarity, Fisher information, per-token/process rewards).
- High-noise regimes: characterize the failure boundary where reward variance becomes non-discriminative and propose noise-robust filtering or denoising methods.
- Adaptive filtering policies: develop principled schedules or controllers to set the keep rate online (e.g., via MI trends, gradient SNR estimates, or Bayesian decision rules) instead of fixed .
- Coverage and distributional bias: quantify how filtering shifts the prompt/state distribution, risks coverage collapse, or harms generalization; design coverage-aware or curriculum-based filtering.
- Exploration trade-offs: assess whether filtering out low-variance prompts suppresses exploration on sparse-reward tasks; test with exploration bonuses or intrinsic motivation.
- Algorithmic generality: evaluate the mechanism and intervention under off-policy actor–critic, V-trace, replay buffers, token-level Q-learning, and population-based training.
- Preference- and process-supervised regimes: test whether template collapse and SNR filtering extend to RLHF/DPO and process-RL settings with learned or human-provided rewards.
- KL/reference dynamics: study how updating the reference policy and varying KL schedules interact with collapse and MI; identify schedules that maintain input dependence.
- Making MI actionable: explore using MI directly in the objective (e.g., maximize with a constraint on ) or as a regularizer alongside PPO/GRPO, and compare to filtering.
- Distinguishing semantic vs. syntactic diversity: develop metrics to ensure high reflects meaningful reasoning diversity rather than superficial variation.
- Signal vs. noise in reward variance: disentangle variance due to task-discriminative differences from variance due to environment/policy stochasticity; refine filtering to prefer the former.
- Long-context and memory effects: examine how scales with context length and history depth, and whether collapse accelerates with longer episodes.
- Template identification and auditing: build methods to extract, cluster, and characterize learned templates to better diagnose, visualize, and target collapse.
- Robustness and safety: assess whether promoting input dependence increases susceptibility to prompt injection or adversarial perturbations; design safeguards and red-teaming protocols.
- Reproducibility and sensitivity: provide comprehensive ablations (e.g., , reward scaling, KL/entropy coefficients, seeds) and report variance to establish stability and transferability of results.
Practical Applications
Overview
This paper identifies a new failure mode in reinforcement-learning-trained, multi-turn LLM agents—template collapse—where agents maintain high within-input “diversity” yet their reasoning becomes input-agnostic across different prompts. It introduces mutual-information (MI)–based online proxies to monitor input dependence of reasoning, explains collapse via a signal-to-noise ratio (SNR) mechanism in policy gradients, and proposes SNR-Aware Filtering (selecting high reward-variance prompts per iteration) that consistently improves both input dependence and task performance across planning, math, web navigation, and code execution. Below are actionable applications and their feasibility.
Immediate Applications
- Implement MI-based “reasoning health” monitors in RL training pipelines
- Sectors: software/ML platforms, agent toolchains (e.g., PPO/GRPO/DAPO users), research labs
- Tools/workflows: add in-batch cross-scoring to compute Retrieval-Acc or MI-ZScore-EMA each iteration; display alongside reward and entropy in training dashboards; alert/early stop when MI trends down while entropy stays high
- Assumptions/dependencies: access to per-token log-probabilities; ability to record “reasoning tokens” separately from actions; batches with multiple prompts to enable cross-scoring
- Use SNR-Aware Filtering (top‑p by reward variance) during RL finetuning of agents
- Sectors: software agents, web automation, code assistants, robotics simulation
- Tools/workflows: sample G≥2 trajectories per prompt; compute within-prompt return variance; retain only top‑p variance mass for each update; expose ρ as a tunable “SNR knob”
- Assumptions/dependencies: reliable per-trajectory reward; moderate environment noise (filtering advantages attenuate when noise is extreme); ability to repartition rollout budget without extra compute
- Replace entropy-only diagnostics with MI-backed hyperparameter tuning
- Sectors: ML Ops, AutoML for RLHF/RLAIF/agent RL
- Tools/workflows: tune KL and entropy bonuses by tracking MI–performance correlation; treat MI increase as a primary objective; use MI to select checkpoints
- Assumptions/dependencies: MI proxies available online; minimal added overhead (cross-scoring reuses rollout samples)
- Reward design to increase informative variance (higher SNR)
- Sectors: web agents, educational tutors, code execution, planning agents
- Tools/workflows: shape rewards to produce non-trivial within-prompt variance (e.g., partial credit, step-wise rewards, diminishing retries); reduce flat, uniformly high/low rewards that weaken task gradients
- Assumptions/dependencies: feasible to instrument granular rewards without inducing reward hacking
- Production drift detection for agent reasoning
- Sectors: customer support, e-commerce assistants, enterprise copilots
- Tools/workflows: periodically batch recent prompts/responses and compute Retrieval-Acc/MI offline to track adaptivity; trigger fallbacks (clarifying questions, human-in-the-loop, alternative policies) when MI drops
- Assumptions/dependencies: privacy-safe logging; background scoring compute; approximate MI from sampled traffic batches
- Dataset and task curation using reward-variance sampling
- Sectors: agent dataset providers, benchmarking consortia, QA/agent suites
- Tools/workflows: pre-screen tasks/prompts by empirical return variance; upweight/retain high-variance tasks in training curricula; prune persistently low-variance tasks that contribute reg-noise
- Assumptions/dependencies: initial exploratory rollouts to estimate variance; stable reward instrumentation
- CI/CD “Reasoning Dependence” checks for agent updates
- Sectors: software engineering (code agents), DevOps for AI agents
- Tools/workflows: add MI-based tests in continuous integration; reject model updates with degraded MI at fixed success rate or vice versa; track template collapse regressions
- Assumptions/dependencies: small held-out prompt sets for scoring; reproducible inference settings
- Governance dashboards and model cards reporting MI
- Sectors: policy/compliance, evaluation firms, safety teams
- Tools/workflows: include MI and Retrieval-Acc in model cards and internal governance dashboards as KPIs of input-dependent reasoning; compare to entropy for context
- Assumptions/dependencies: standardized evaluation prompts; organizational buy-in for new KPIs
- Cost/throughput optimization via filtering
- Sectors: training infrastructure, MLOps
- Tools/workflows: apply SNR filtering to reduce effective batch for gradient steps (reported 26–41% per-step savings in experiments) without hurting performance; automate keep-rate scheduling
- Assumptions/dependencies: fixed rollout budget; careful monitoring to avoid over-filtering (losing coverage/diversity)
- Education and coaching agents: adaptivity safeguards
- Sectors: education, corporate training
- Tools/workflows: use MI on logged tutoring sessions to ensure explanations meaningfully adapt to student inputs; flag/adjust prompts when MI declines
- Assumptions/dependencies: offline analysis (due to batching/cross-scoring); appropriate consent/data handling
Long-Term Applications
- MI-aware regularization and objectives
- Sectors: foundational model training, agent research
- Tools/products: add contrastive/InfoNCE-style terms to maximize input–reasoning dependence while maintaining controlled within-input diversity; integrate with PPO/GRPO variants
- Assumptions/dependencies: additional compute and careful balancing to avoid overfitting; theoretical analysis for stability
- Standardized “Reasoning Dependence Scores” for audits and regulation
- Sectors: policy/regulation, standards bodies, safety audits
- Tools/products: MI-based benchmarks and reporting templates for agentic systems; guidance on acceptable ranges and early-warning thresholds
- Assumptions/dependencies: community consensus on task suites; reproducible protocols; regulatory uptake
- SNR-aware curricula and environment design
- Sectors: robotics, simulation, edtech, enterprise workflow automation
- Tools/products: auto-generate or select tasks that yield informative (not noisy) reward variance; dynamic curricula that maintain high SNR throughout training
- Assumptions/dependencies: task generation pipelines; online SNR estimation robust to environment stochasticity
- Deployment-time adaptivity controllers
- Sectors: healthcare decision support, finance advisory, legal assistants
- Tools/products: fast MI surrogates to predict when a model’s reasoning is becoming template-like; invoke clarifying questions, route to specialists, or halt automated actions when MI is low
- Assumptions/dependencies: latency constraints; lightweight MI predictors (e.g., discriminators trained on cross-scoring signals)
- Multi-agent orchestration using MI as a routing signal
- Sectors: enterprise agent platforms, robotics fleets, customer operations
- Tools/products: route tasks to agents with higher MI on similar inputs; demote or retrain agents that show collapse; ensemble selection based on MI signals
- Assumptions/dependencies: shared telemetry; cross-agent comparability; fair routing policies
- Robust SNR estimation under high stochasticity
- Sectors: robotics in the wild, complex simulators, high-noise web environments
- Tools/products: variance estimators corrected for environment noise; off-policy SNR weighting; Bayesian variance models to separate signal from stochasticity
- Assumptions/dependencies: additional sensors/metadata on environment randomness; research into unbiased estimators
- Privacy-preserving MI diagnostics
- Sectors: healthcare, finance, government
- Tools/products: local/cellular batching for cross-scoring; hashed or feature-space MI proxies; secure enclaves for logging/scoring sensitive traces
- Assumptions/dependencies: privacy tech stack; acceptable trade-offs in MI fidelity
- Extending beyond RL to supervised/feedback pipelines
- Sectors: instruction tuning, process supervision, RLAIF
- Tools/products: MI proxies to select training examples that elicit input-dependent chains-of-thought; filtering low-variance (low-signal) examples in process datasets
- Assumptions/dependencies: availability of reasoning traces (policy constraints may hide CoT); alternative proxies if CoT is not logged
- Integrated “Reasoning Health Kit” for agent platforms
- Sectors: LLMOps vendors, open-source toolchains (TRLX, veRL, RLlib, LangChain/AutoGen ecosystems)
- Tools/products: plug-and-play library offering MI monitors, SNR filters, RV sampler, dashboards, and CI integrations
- Assumptions/dependencies: ecosystem adoption; standardized APIs for log-prob access
- Theory-driven SNR controls and guarantees
- Sectors: academia, advanced labs
- Tools/products: formal bounds linking reward variance, gradient norms, and MI; principled schedules for KL/entropy vs SNR; proofs of convergence without template collapse
- Assumptions/dependencies: further theoretical development; controlled experimental validation
Notes on Feasibility and Dependencies
- Core dependencies common across applications:
- Access to per-token log-likelihoods and explicit “reasoning token” channels during training/analysis.
- Group sampling (G≥2 trajectories per prompt) and well-instrumented reward signals.
- Moderate environment stochasticity; extremely noisy settings dilute the usefulness of reward variance as an SNR proxy.
- Privacy and compliance policies permitting logging and cross-scoring of prompts/reasoning for MI computation; if restricted, develop lightweight or privacy-preserving proxies.
- Known boundary conditions from the paper:
- MI is a better leading indicator of performance than entropy in multi-turn agent RL; entropy alone can be misleading.
- SNR-Aware Filtering benefits fade in extremely high-noise environments; filter use should be coupled with noise-aware variance estimation.
- Filtering can reduce per-step compute while improving outcomes, but over-filtering risks narrowing task coverage and introducing bias—monitor both MI and task diversity.
Glossary
- Advantage: The expected additional return from taking an action compared to a baseline under the current policy. "where is the advantage."
- Advantage estimate: A sample-based estimate of the advantage using returns relative to a prompt-level baseline. "the advantage estimate is "
- Cauchy–Schwarz inequality: A fundamental inequality in linear algebra used to bound norms and inner products; here used to upper-bound the task-gradient norm by reward variance. "The Cauchy-Schwarz inequality gives (Appendix~\ref{app:rv-snr}):"
- Closed-loop multi-turn agent reinforcement learning: An RL setting where the agent interacts with an environment over multiple turns, using observations and prior reasoning to inform future actions. "We study closed-loop multi-turn agent reinforcement learning~\cite{wang2025ragenunderstandingselfevolutionllm},"
- Conditional entropy: The average uncertainty in the reasoning given the input; measures within-input diversity. "For comparison, conditional entropy "
- DAPO: A reinforcement learning algorithm variant used for stabilizing LLM agent training. "DAPO itself also includes a filtering/acceptance step;"
- Dr. GRPO: A variant of GRPO designed for more stable optimization in reasoning RL. "Here, DAPO and Dr.\ GRPO are recent strong baselines that directly target stable training and mitigate collapse-like failure modes."
- Entropy bonus: A regularization term that encourages exploration by rewarding higher-entropy policies. "The standard PPO/GRPO objective contains regularization terms (KL divergence, entropy bonus) that act uniformly across all inputs regardless of their content:"
- Entropy regularization: Penalizing low-entropy policies to maintain diversity in action or reasoning outputs. "Sampling noise and input-agnostic regularization (KL divergence and entropy regularization~\cite{schulman2017proximalpolicyoptimizationalgorithms, xu2025epoentropyregularizedpolicyoptimization}) dilute this signal."
- Exponential moving average (EMA): A smoothing technique that maintains a decayed average over time for stability in monitoring. "We apply z-score normalization and exponential moving average (EMA) to stabilize training monitoring, yielding MI-ZScore-EMA."
- GRPO: An RL optimization algorithm (Group Relative Policy Optimization) used for training reasoning-capable policies. "The standard PPO/GRPO objective contains regularization terms (KL divergence, entropy bonus) that act uniformly across all inputs regardless of their content:"
- In-Batch Cross-Scoring: A procedure that scores each generated reasoning sequence against all prompts in the same batch to approximate input–reasoning dependence. "Method: In-Batch Cross-Scoring."
- KL divergence: Kullback–Leibler divergence; a measure of how one probability distribution diverges from a reference distribution, used as a regularizer. "The standard PPO/GRPO objective contains regularization terms (KL divergence, entropy bonus) that act uniformly across all inputs regardless of their content:"
- Marginal entropy: The overall entropy of the reasoning ignoring the input; combines input dependence and within-input diversity. "and marginal entropy "
- MI-ZScore-EMA: A stabilized mutual-information proxy that z-scores matched-minus-marginal log-likelihoods and applies EMA over time. "We apply z-score normalization and exponential moving average (EMA) to stabilize training monitoring, yielding MI-ZScore-EMA."
- Mutual information (MI): An information-theoretic measure of how much observing the reasoning reduces uncertainty about the input; captures input dependence. "Across diverse tasks, mutual information correlates with final performance much more strongly than entropy, making it a more reliable proxy for reasoning quality."
- Mutual information proxy: A computable estimator that approximates MI between inputs and reasoning without external models. "We propose a mutual information (MI) proxy~\cite{coverthomas2006elements} that scores each reasoning chain against all batch inputs to measure input dependence, without external models."
- Nucleus sampling: A sampling strategy that retains the top cumulative-probability mass; here, used by analogy for selecting prompts by reward-variance mass. "analogous to nucleus sampling~\cite{holtzman2020curiouscaseneuraltext} but ranking by per-prompt reward variance rather than token probability."
- Policy gradient: A class of RL methods that update policy parameters in the direction of performance gradients; here, considered under SNR analysis. "Our core finding: when policy gradient updates are dominated by input-agnostic noise rather than task-discriminative signalâlow signal-to-noise ratio (SNR)âreasoning drifts toward templates that appear diverse within each input but ignore cross-input differences."
- PPO (Proximal Policy Optimization): A widely used RL algorithm that constraints policy updates to stabilize learning. "We compare PPO \citep{schulman2017proximalpolicyoptimizationalgorithms}, DAPO \citep{yu2025dapo}, GRPO \citep{shao2024deepseekmathpushinglimitsmathematical}, and Dr.\ GRPO \citep{liu2025understandingr1zero} for up to 400 rollout--update iterations."
- Regularization gradient: The component of the update gradient arising from regularizers (e.g., KL, entropy) rather than task returns. "Regularization gradient is flat: $\|g_{\text{reg}\|$ (from KL and entropy terms) remains constant across all buckets, applying uniform contraction to every reasoning chain regardless of its source prompt or reward signal."
- Retrieval-Acc: A discrete mutual-information proxy measuring how often the true prompt is recovered by cross-scoring. "Retrieval-Acc (discrete, interpretable): We define"
- Reward variance: The variance of returns across trajectories for the same prompt; used as an SNR proxy to select high-signal updates. "Low reward variance weakens task gradients while input-agnostic regularization remains constant, erasing input dependence."
- Signal-to-noise ratio (SNR): The ratio of task-informative gradient signal to noise from sampling and regularization; low SNR leads to template collapse. "We further explain template collapse with a signal-to-noise ratio (SNR) mechanism."
- SNR-Aware Filtering: A training strategy that prioritizes prompts with higher reward variance to boost task-signal dominance in updates. "To address this, we propose SNR-Aware Filtering to select high-signal prompts per iteration using reward variance as a lightweight proxy."
- Spearman correlation: A rank-based correlation metric used to relate diagnostic scores (e.g., MI proxies) to task performance. "Empirically, Retrieval-Acc and MI-ZScore-EMA achieve positive Spearman correlation with final task performance ( for Trajectory MI-ZScore), substantially above entropy metrics, which show negative correlations ( to ), confirming entropy is misleading in direction (Figure~\ref{fig:F08})."
- Teacher-forced log-likelihoods: The log probabilities computed by conditioning on the ground-truth previous tokens, used to score reasoning under different prompts. "we compute teacher-forced log-likelihoods for every pair"
- Top-k filtering: A selection strategy that keeps a fixed number of highest-ranked items per iteration; less adaptive than Top-p in this setting. "The advantage over Top-k filtering is particularly noteworthy:"
- Top-p filtering: A selection strategy that keeps items until a cumulative mass threshold is reached; here, applied to reward-variance mass over prompts. "Top-p filtering consistently achieves higher success rates throughout training compared to both alternatives."
- Trajectory: A sequence of observations, reasoning tokens, actions, and rewards collected over an episode. "forming a trajectory ."
- Z-score normalization: Standardization by subtracting a mean and dividing by a standard deviation to stabilize metrics across batches. "We apply z-score normalization and exponential moving average (EMA) to stabilize training monitoring, yielding MI-ZScore-EMA."
Collections
Sign up for free to add this paper to one or more collections.