- The paper introduces PromptEvolver, a black-box evolutionary algorithm that optimizes natural-language prompts for T2I image reconstruction.
- It employs population-based initialization, crossover, and mutation to overcome drawbacks of embedding and gradient-based methods.
- Quantitative evaluations show up to 7.8% improvement in reconstruction scores and superior outcomes in human evaluations.
PromptEvolver: Evolutionary Optimization for Natural-Language Prompt Inversion in T2I Models
Introduction and Problem Setting
Prompt inversion in text-to-image (T2I) generation aims to recover a natural-language prompt that, when used as input to a T2I model, faithfully reconstructs a given target image. Success in this task requires not only semantic alignment but high fidelity to fine-grained details. Prior approaches predominantly fall into three categories:
- Embedding/Latent Optimization—White-box approaches such as Textual Inversion and DreamBooth optimize pseudo-word embeddings or model parameters. Outputs lack interpretability and transferability.
- Gradient-Based Discrete Optimization—Directly searches in prompt token space; outputs are sometimes ungrammatical and lack naturalness, still requiring white-box access.
- Gradient-Free/Captioning—Leverage VLMs or retrieval/captioning models to generate discrete prompts; limited by single-shot or single-trajectory search, and highly susceptible to local optima.
PromptEvolver addresses all these limitations by employing a black-box, population-based search for fully natural-language prompts using evolutionary methods guided by a strong VLM, operating entirely in discrete, human-editable text space.
Methodological Framework
PromptEvolver formulates prompt inversion as an optimization problem over prompts p that maximize image similarity s between a target image I and images I^∼M(p) produced by a (black-box) T2I model. The fitness function is
p∗=argpmaxEI^∼M(p)[s(I,I^)]
where s can be any image similarity metric—CLIP-based, BLIP, DreamSim, or others. The optimization proceeds as follows:
- Initialization: Use a VLM to generate an initial population of N diverse, information-dense prompts via structured, multi-step analysis of the target image, encouraging diversity in phrasing and focus.
- Evolutionary Loop (~T generations):
- Crossover: Parent prompts are selected by tournament (or uniformly) and combined by the VLM, which uses joint textual and visual context to merge accurate elements and resolve conflicting descriptions.
- Mutation: With probability pm, the VLM proposes fine-grained edits—adding missing details, correcting inaccurate assertions, or increasing specificity—for broader exploration.
- Evaluation: Each prompt is used to generate K images; fitness is the mean similarity to the reference. A caching mechanism is used for efficiency.
- Selection: The top-s0 prompts by fitness survive; others are discarded.
- Termination: After s1 generations, return the highest-fitness prompt and its best reconstruction.
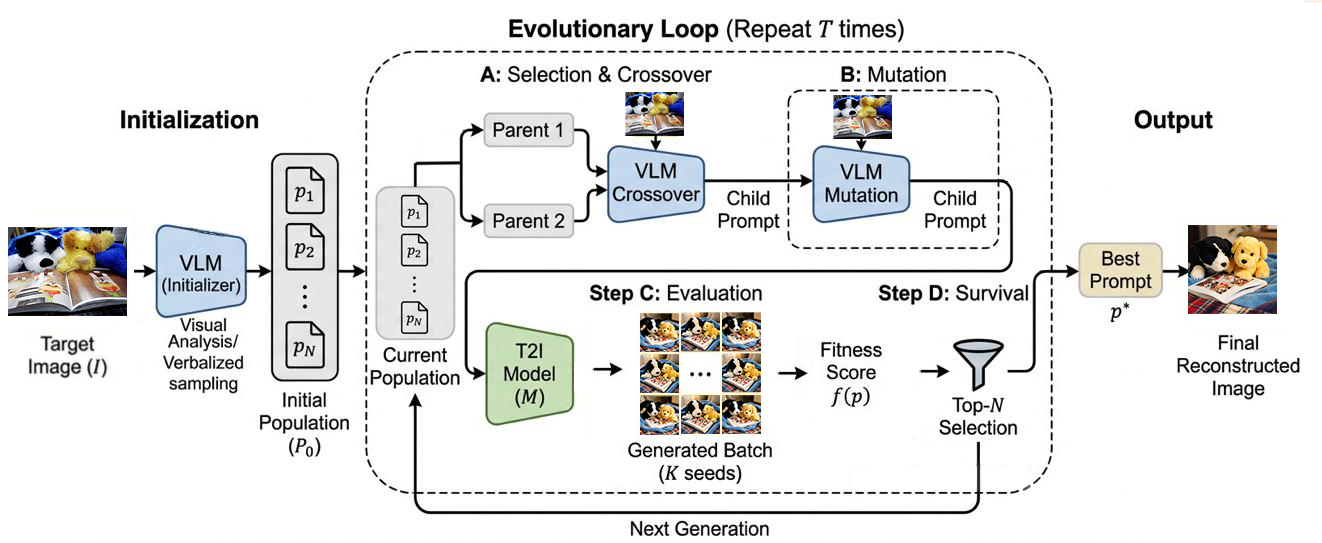
Figure 2: Overview of PromptEvolver—a vision-LLM generates a prompt population, then evolutionary crossover and mutation operators guided by the input image iteratively optimize prompt quality.
This pipeline uniquely positions VLMs as both prompt generators and evolutionary operators; textual fluency and semantic alignment are enforced at each evolutionary step.
Comparative Evaluation and Results
Experiments span five datasets with diverse visual/semantic properties (Lexica, MS-COCO, CelebA, Flickr8K, LAION-400M), using a consistent set of T2I/VLMs (FLUX.2-klein-4B, Qwen3-VL-Instruct) and four different image similarity metrics.
Across all datasets and metrics, PromptEvolver systematically outperforms:
- Embedding-level and latent-space approaches (PEZ, STEPS, DreamBooth variants) that optimize for image similarity but lack semantic transparency
- Gradient-free methods (CLIP Interrogator, VGD) and VLM-Baseline single-shot descriptions
Notably, PromptEvolver achieves up to 7.8% improvement in image reconstruction score compared to state-of-the-art baselines. Furthermore, its reconstructions are consistently preferred in 54.5% of pairwise human evaluations (p = 0.003), indicating a statistically significant gain in perceived match to reference images.

















Figure 4: Side-by-side comparison of PromptEvolver and VLM-Baseline on difficult prompt inversion cases, highlighting robustness on spatial/attribute matching, counting, and scene layout.












Figure 3: Qualitative comparison on five datasets—PromptEvolver reconstructions (middle) vs. VLM-Baseline (bottom) demonstrate greater fidelity to original reference images, especially for scene structure, style, and compositional detail.
Qualitative Analysis
PromptEvolver-optimized prompts not only improve faithfulness to the reference on standard perceptual/image-text similarity metrics but are also more interpretable and directly editable by users. Example ablation and prompt evolution flows demonstrate that the evolutionary process—by fusing parent prompts and targeted VLM-guided mutation—can recover small but crucial visual details (e.g., text, colors, spatial relationships) that initial captioning and previous approaches systematically miss.
Ablation: Robustness and Design Choices
- The use of structured, multi-step analysis prompts in the VLM improves convergence and output quality, but results are broadly robust to template style, VLM variant, and mutation rate.
- Incorporating spatial emphasis in prompt generation/optimization and varying mutation rates provides modest improvements, but overall, evolutionary optimization itself is the critical driver.
- PromptEvolver’s natural-language outputs are fluently human-readable (mean NLL under Mistral-7B: ~2.9), in strong contrast to prior approaches (NLL 4–7).
Implications and Future Directions
Practical Utility
PromptEvolver is T2I-model and metric-agnostic, requiring only black-box access to image generation. Its outputs are natively cross-model and facilitate:
- Transfer of style/content between T2I models by reusing evolved prompts
- Downstream editing via interpretable, granular prompt modifications
- Enhanced transparency and auditability of generative model outputs through semantic reverse engineering
Theoretical Significance
By fully operating in interpretable natural-language space, PromptEvolver illuminates the mapping between images and linguistic structure and sidesteps barriers associated with continuous/latent representations. The evolutionary strategy’s preservation of population diversity addresses local minima and single-run failure cases ubiquitous in prior work.
Prospects for AI Research
The PromptEvolver framework is modular—future research can expand its capabilities by:
- Scaling to multimodal inverse problems (video, 3D, audio-visual)
- Incorporating more sophisticated VLMs or multi-agent evolutionary mechanisms
- Leveraging richer fitness functions incorporating human feedback or task-specific priors
- Applying prompt inversion in generative model debugging and interpretability contexts
Conclusion
PromptEvolver establishes a new paradigm for prompt inversion by leveraging evolutionary optimization in natural-language space, using strong VLMs as core operators. It delivers state-of-the-art reconstruction fidelity in prompt inversion while maintaining fluency, interpretability, and model-agnosticity. This approach meaningfully advances prompt engineering for T2I and sets a robust methodological baseline for future research on semantic inversion and model auditing.