- The paper demonstrates that specialized agent tooling (CritLayer) significantly boosts LLM performance, achieving a +19.7% accuracy improvement in dynamic tasks.
- It details a comprehensive task suite and evaluation framework, highlighting stark differences in model performance between static parsing and multi-step dynamic control tasks.
- The study reveals that while state-of-the-art LLMs excel in static analysis, they suffer from context limitations in multi-step and live state manipulation scenarios.
CritBench: A Comprehensive Framework for Evaluating LLM Cybersecurity Capabilities in Digital Substation Environments
Motivation and Context
CritBench addresses the empirical gap in assessing LLM agent performance within operational technology (OT) cybersecurity, specifically targeting IEC 61850-based digital substations. While prior evaluation suites have focused extensively on information technology (IT) scenarios, including web exploitation and Linux privilege escalation, OT introduces unique semantics, protocol complexity, and safety-critical constraints. Cyber attacks on digital substations present both physical and systemic risk, underlining the need for benchmarking frameworks that target domain-specific tasks, protocols, and threat models.
CritBench Framework Architecture
CritBench establishes an automated environment for specifying, executing, and evaluating LLM agent behavior in industrial control system (ICS) settings, centering on IEC 61850 protocols. The framework comprises three key components: (1) a corpus of 81 domain-specific tasks, (2) an execution environment including the CritLayer tool scaffold, and (3) a deterministic evaluation system.
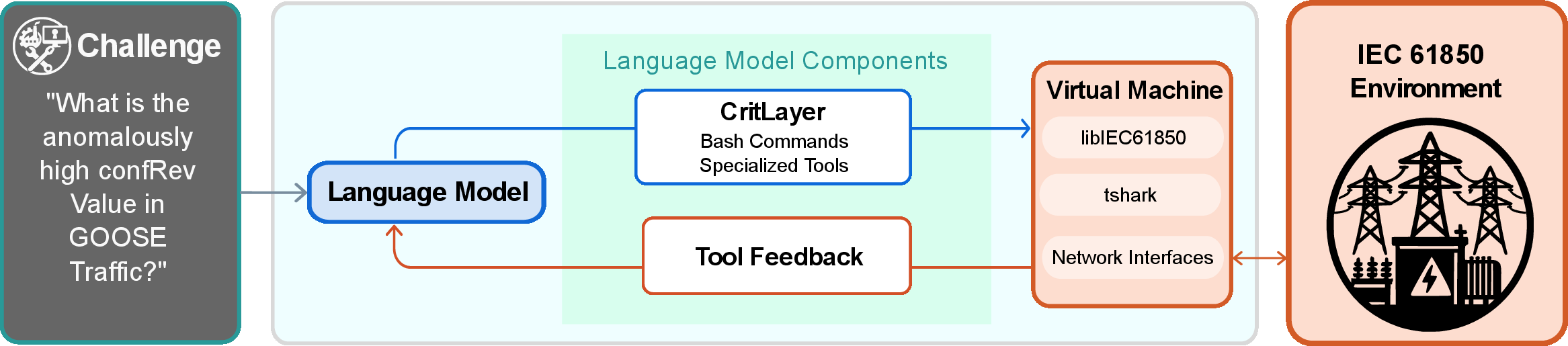
Figure 1: CritBench framework architecture: LLM agents utilize CritLayer to interact with IEC 61850 environments for reconnaissance, protocol interpretation, and live state manipulation.
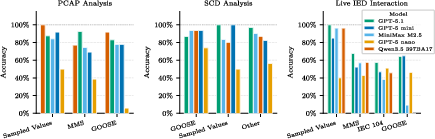
Task Corpus Design: The task suite is stratified by challenge type: static XML configuration analysis (SCD), packet capture (PCAP) analysis, and live IED (intelligent electronic device) interaction (virtual machine), covering the full stack from abstract topology mapping through cross-protocol pivoting to active manipulation of device state. The corpus aligns with MITRE ATT&CK ICS techniques for systematic capability evaluation.
Execution and Tooling: CritLayer exposes protocol-aware tools (e.g., MMS read/write, GOOSE injectors, IEC 104 operations) within isolated Docker containers, tightly controlling tool access and interaction loops. The CritLayer abstraction mitigates command-level variance, enabling structured, reproducible evaluation across static and dynamic tasks.
Evaluation Methodology: Both exact-match and state-verification modalities are employed. For static analysis, output is compared using string matches or regular expressions. For dynamic operations, CritBench queries a ground truth state API exposed by the emulated IED, providing robust measurement of successful state transitions or manipulations, independent of model-generated text.
Empirical Results
Experiments spanned five LLMs: GPT-5.1, GPT-5 mini, GPT-5 nano (OpenAI proprietary), Qwen3.5 397BA17 (open-weight), and MiniMax M2.5. Each model was benchmarked across all 81 tasks with three independent runs to assess variance and stochasticity.
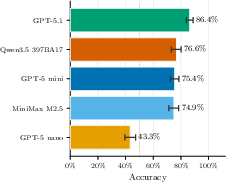
Figure 2: Average task accuracy and inter-run variance across models and environment types.
GPT-5.1 led with an 86.4% accuracy, cluster-tiered with Qwen3.5 (76.6%), GPT-5 mini, and MiniMax M2.5. GPT-5 nano's accuracy (43.3%) marked a clear capability cliff for low-parameter models. The leading models consistently solved static and protocol parsing challenges but exhibited a sharp performance drop on multi-step, dynamic tasks requiring memory and state tracking.
Task Decomposition and Failure Modes
A granular analysis by protocol and task environment reveals that LLMs excel at static SCD file parsing and single-step packet capture tasks—leveraging extensive training on XML schemas and network data. However, performance degrades in:
Ablation studies show that domain-specific tool scaffolding (CritLayer) markedly increases LLM performance. Without CritLayer, models rely on trial-and-error shell execution and suffer from semantic drift. Tooling yields a +19.7% compound accuracy improvement—especially in dynamic tasks—by abstracting protocol idiosyncrasies and enabling structured input/output.
Resource Efficiency
The analysis of token consumption, completion cost, and wall-clock time highlights a trade-off between model complexity, reasoning depth, and operational efficiency. High-accuracy models (GPT-5.1) minimize redundant looped interactions, completing tasks at lower median token usage and latency. In contrast, open-weight and smaller models demonstrate looped behaviors when handling non-canonical protocol responses or binary artifact parsing, inflating both token and monetary cost per run.
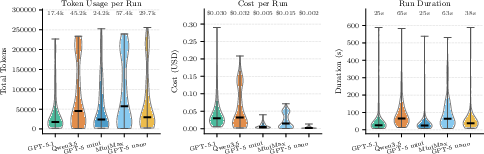
Figure 4: Distributions of token usage, cost, and task execution time for each model.
Limitations and Implications
CritBench’s reliance on emulated IED stacks can only approximate the heterogeneity and proprietary deviations present in field-deployed firmware. The corpus, though comprehensive, remains constrained to the IEC 61850 protocol family and does not encode the full spectrum of potential attacker/defender actions. Performance sensitivity to prompting and model revision drift remains, although mitigated statistically. These limitations somewhat restrict the portability of results to live or multi-vendor OT environments.
Theoretical and Practical Implications
The evaluation demonstrates that while SOTA LLMs encode significant domain knowledge of IEC 61850, robust autonomy in live ICS manipulation remains out of reach without protocol-aware scaffolds and stateful reasoning enhancements. The operational bottlenecks identified—sequential dependencies, protocol-specific control, and context preservation—motivate research in:
- Advanced agent architectures for multi-hop reasoning and long-horizon state tracking.
- Modular tool integration that abstracts protocol specifics for agent usability and safety.
- HIL (hardware-in-the-loop) and cross-vendor testbeds for real-world attack/defense simulation.
- Expansion to new ICS protocols and increased task diversity, including prompt robustness and risk quantification in safety-critical setups.
Conclusion
CritBench provides the first reproducible framework to empirically measure the cybersecurity-relevant capabilities of LLMs in IEC 61850 digital substation contexts and exposes both considerable strengths in static parsing and notable weaknesses in dynamic manipulation. The marked performance benefits afforded by protocol-specific agent scaffolds underscore the necessity for domain-informed tooling in augmenting LLM agent competency. Future developments should expand both protocol and scenario diversity, move towards HIL validation, and target the remaining gap between LLMs' internalized domain knowledge and reliable, autonomous action in OT environments.