- The paper introduces CLEAR, a composite loss framework that uses reverse training to enhance cross-lingual retrieval for low-resource languages.
- It employs English passages as semantic anchors, integrating InfoNCE, reverse contrastive loss, and KL divergence to strengthen cross-lingual embedding alignment.
- Experimental results show up to 15% improvement in low-resource settings and robust performance in both cross-lingual and monolingual tasks.
CLEAR: Cross-Lingual Enhancement in Alignment via Reverse-Training
Introduction and Motivation
Cross-lingual information retrieval remains susceptible to substantial disparities across language variants, primarily due to the imbalance in linguistic resources and insufficient architectural incentives for cross-lingual alignment during model training. State-of-the-art retrieval systems based on multilingual dense representations exhibit pronounced performance drops on low- and medium-resource languages when compared to English, as empirically evidenced in diverse benchmarks. This model-centric disparity poses critical challenges for the fairness and reliability of retrieval-augmented generation (RAG) and downstream question answering, limiting real-world applicability and scalability.
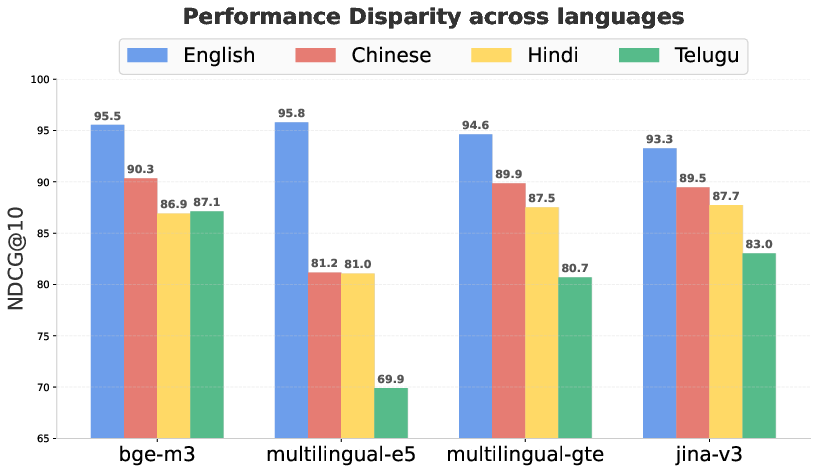
Figure 1: Performance disparity of various embedding models across languages in a cross-lingual setup where English passage with other language queries in the Belebele benchmark.
As demonstrated in Figure 1, the retrieval accuracy for queries issued in low-resource languages is markedly lower than for high-resource or English queries, reflecting an inadequate representational bridge. Existing approaches, such as contrastive learning via InfoNCE loss, focus predominately on direct query–passage pairs. These protocols often fail to address more fundamental cross-lingual alignment, occasionally sacrificing performance in better-aligned languages, and rarely enable robust adaptation when language resources are limited.
CLEAR Loss: Objective and Components
CLEAR (Cross-Lingual Enhancement in Retrieval via Reverse-training) introduces a composite training framework that explicitly targets robust cross-lingual alignment and retrieval capability. The approach is centered on a novel loss construct comprising three synergistic components:
- An English-centric InfoNCE loss LNCEen to retain and regularize the representational topology for English pairs.
- A reversed cross-lingual contrastive loss LCL, where the English passage acts as an anchor (not the query), aligning target language queries with their English passage through reverse training signals.
- A KL-divergence-based term LKL to match the similarity distributions between English pairs and English-to-target-language pairs at a batch level.
The reverse training principle (in contrast to conventional retrieval objectives) induces additional direct and indirect interactions among cross-language embeddings, reinforcing both instance-level and distributional alignment.
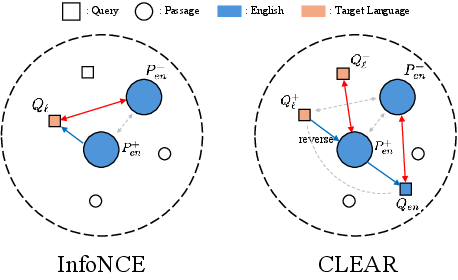
Figure 2: Comparison of the core idea of CLEAR with the standard InfoNCE loss, emphasizing increased direct and indirect cross-lingual interactions centered around the English passage.
This formulation yields multidirectional supervision. Rather than merely pulling queries and passages closer in a single direction, CLEAR recursively aligns English queries, passages, and target-language queries—leveraging English passages as semantic bridges. Notably, the reversal scheme is essential for leveraging in-batch negatives from the query space during cross-lingual training, thus improving representational diversity and generalizability.
Experimental Findings
CLEAR's efficacy is validated via fine-tuning multiple widely-used multilingual embedding models (bge-m3, multilingual-e5, gte-multilingual, jina-v3) on high-quality, fully parallel benchmarks like Belebele and XQuAD, encompassing diverse typological categories (Arabic, German, Chinese, Russian, Spanish, Hindi, Vietnamese, Telugu, Bengali).
Key findings include:
- Robust Gains in Low-Resource Settings: CLEAR improves retrieval effectiveness in low-resource languages by up to 15% relative to base models, and by up to 4 nDCG@10 points over InfoNCE, particularly for Bengali and Telugu (highly underrepresented in pretraining corpora), while maintaining or improving English performance.
- Generalization to Unseen Directions: CLEAR trained only with English passages and target-language queries yields substantial improvements even when evaluated in target-language-passage and English-query directions, evidencing robust, bidirectional cross-lingual grounding.
- Multilingual Training: CLEAR demonstrates scalability and effectiveness in multilingual setups, where all languages are trained jointly. Not only does CLEAR improve cross-lingual retrieval, but it also enhances monolingual retrieval—suggesting strengthened semantic entanglement across the shared embedding space.
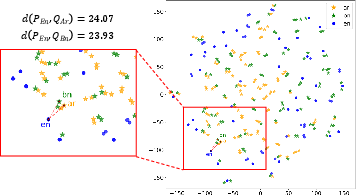
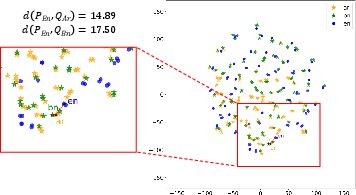
Figure 3: T-SNE visualization of multilingual-e5 embeddings after CLEAR training, showing reduced distance between gold pair representations across language boundaries.
The embedding space induced by CLEAR is more compact and language-agnostic, as visualized by the close proximity of English and target language pairs in Figure 3, affirming the impact on geometric alignment.
Analysis and Ablation
Ablation studies confirm the necessity and complementarity of each CLEAR component:
- The passage bridge (English passage as anchor) delivers the most significant single-component boost, validating its role as a universal semantic fulcrum.
- The reverse loss direction is critical for cross-perspective regularization; removing it undermines overall generalization and considerably reduces nDCG@10, especially in low-resource languages.
- The KL-divergence term contributes to finer matching at the batch distributional level, slightly improving the semantic consistency of the embedding topology without incurring a computational penalty.
The overall architecture displays robust insensitivity to modest deviations in the weighting of loss components, as detailed via sensitivity analysis (see Figure 4).
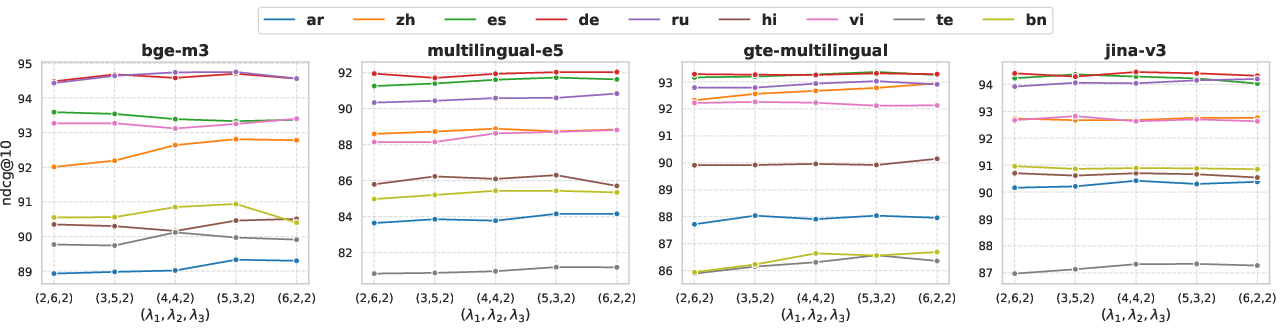
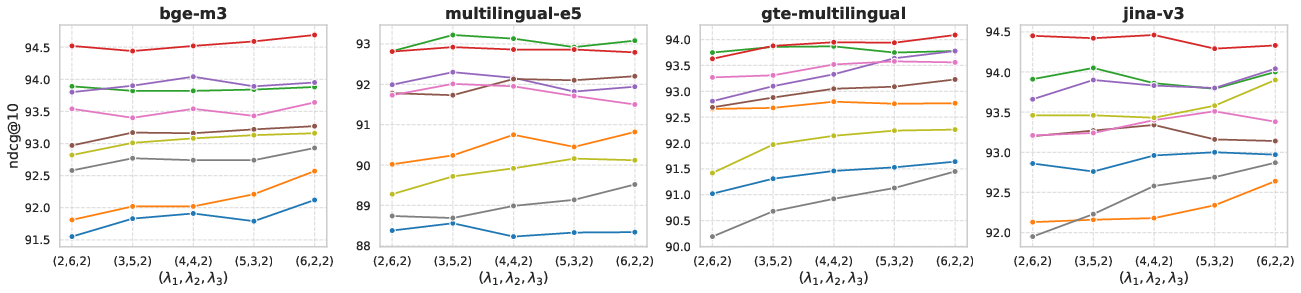
Figure 4: Performance variation depending on the loss component weights (λ1, λ2, λ3) across multiple languages.
Practical and Theoretical Implications
CLEAR offers a practical protocol for enhancing multilingual retrieval systems. From a deployment perspective, CLEAR is attractive—requiring only parallel queries with English passages for training, as opposed to parallel passages or full document translations. Additionally, the method is robust to translation model quality, as it only demands consistent query-level semantics.
Theoretically, CLEAR demonstrates that bidirectional, bridge-based supervision is more effective for learning intrinsically shared cross-lingual spaces compared to traditional contrastive or distillation-based approaches. This suggests that incorporating strategic reversal and anchoring in contrastive objectives could form the basis for further improvements in dense multilingual representations, especially under resource constraints. The balance achieved between English and non-English proficiency sets CLEAR apart from methods prone to catastrophic forgetting or capacity dilution in the dominant language.
Prospective Directions
Potential future directions include:
- Application of CLEAR to scenarios involving cross-lingual pairs not centered on English, extending the passage-bridge principle to arbitrary language pivots.
- Exploration of CLEAR-like objectives in task transfer or generative scenarios beyond retrieval (e.g., cross-lingual summarization or generation).
- Investigation into combinatorial adaptation with parameter-efficient fine-tuning or adapters for even greater applicability in compute-constrained or low-latency environments.
- Application to low-resource or endangered language documentation using machine-translated queries.
Conclusion
CLEAR advances cross-lingual alignment and retrieval by formalizing a composite loss that leverages reverse training and semantic anchoring. This paradigm demonstrates consistent and substantial improvements—most notably for low-resource languages—while mitigating the usual trade-off with English monolingual proficiency. The method generalizes to multilingual joint training and upholds robust embedding space topology, highlighting both its theoretical relevance and practical applicability for global multilingual information access (2604.05821).

