- The paper reveals that all tested LLM rerankers systematically favor recent content, as shown by significant upward rank shifts.
- The study introduces a diagnostic framework using metrics like Kendall’s tau and sliding window approaches to quantify temporal bias.
- The findings underscore the need for mitigation strategies to balance recency bias, informing future improvements in IR system fairness.
Overview
The paper "Do LLMs Favor Recent Content? A Study on Recency Bias in LLM-Based Reranking" (2509.11353) investigates the presence of recency bias in LLMs used as second-stage rerankers in information retrieval (IR) systems. The study evaluates whether LLMs have an intrinsic bias toward newer documents when employed in reranking tasks, potentially skewing search results and propagating unwanted biases into information retrieval (IR) systems.
Investigating the Recency Bias
This study explores the potential recency bias in LLMs when used as rerankers of search engine result pages (SERPs). The authors inject artificial publication dates into the TREC Deep Learning passage retrieval collections (DL21 and DL22) and observe the shift in rankings by seven different LLMs, including high-capacity and cost-effective models like GPT-3.5-turbo, GPT-4, LLaMA-3 8B/70B, and Qwen-2.5 models. Their experiments reveal that all LLMs favor passages that bear newer dates, leaning heavily towards recent content.
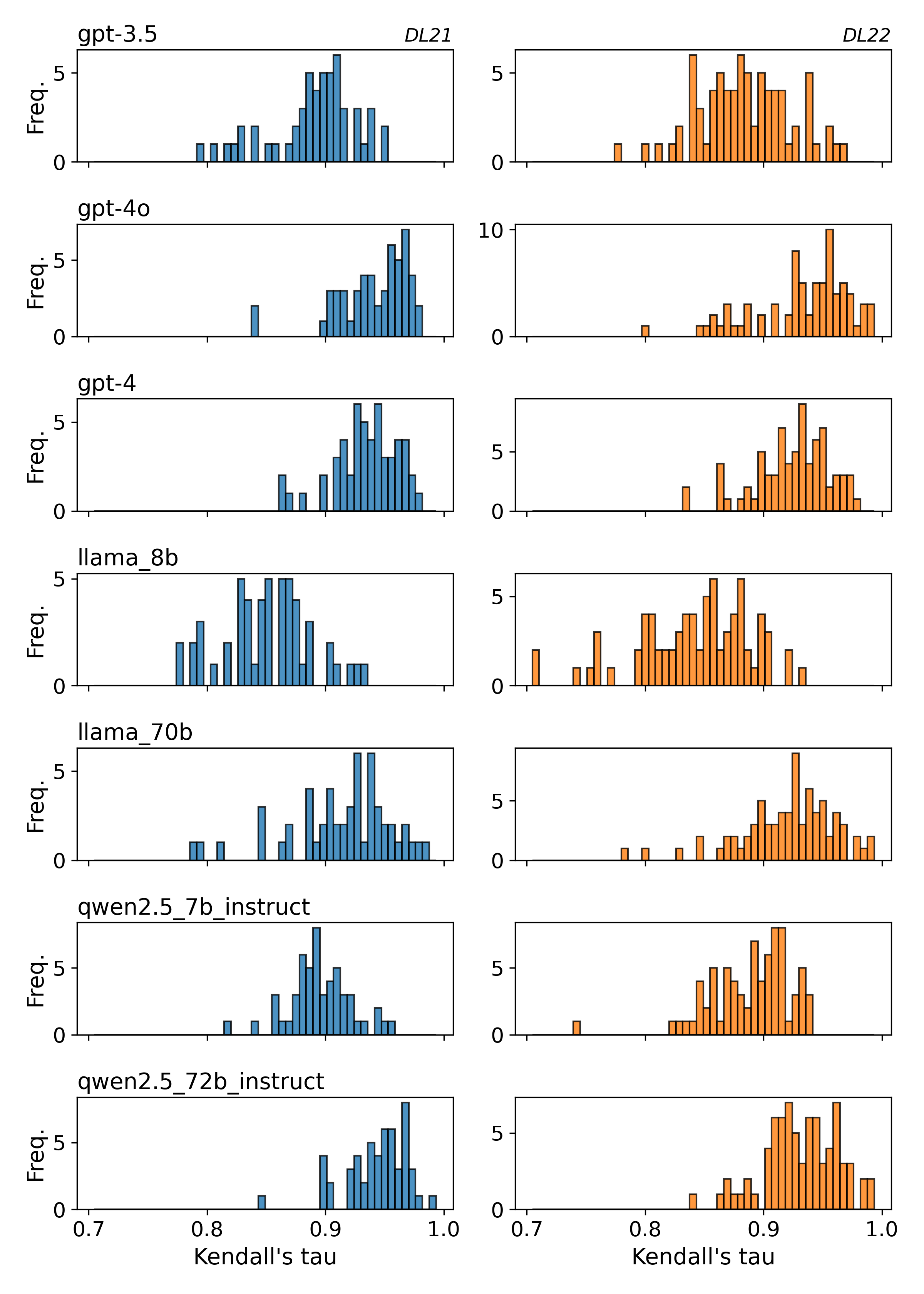
Figure 1: Kendall's tau distributions for each model on DL21 (left) and DL22 (right).
Reranking Experiments and Results
In the listwise reranking experiments, artificial publication dates were prepended to passages retrieved from the TREC 2021 and 2022 Deep Learning tracks. Primarily utilizing a sliding window approach with a size of 10, the experiment sought to assess rank shifts before and after date injection.
Table \ref{tab:rank_shift_metrics} summarizes results using Absolute Average and Largest Rank Shift metrics. It reveals that every model systematically promotes recency, with the largest models being more robust. This trend is corroborated by SERP-Segment level metrics in Table \ref{tab:topk_mean_year_shift_combined}, which shows positive year shifts within the top segments (i.e., mYS<sup>(K))</sup>indicateanoveralltrendtowardsfavoringnewercontent.</p><h2class=′paper−heading′id=′diagnostic−framework′>DiagnosticFramework</h2><p>Thestudyintroducesareranking−basedtestingmethodologyaccompaniedbymetricsthatmeasuretheeffectsofdateinjection,offeringapreciseapproachtodiagnosetemporalbiases.SERP−levelmetricsquantifiedbymAARSand\text{ALRS}_{\text{all},alongsideSERP−Segment−levelmetricslikemYS^{(K)}andmYSG^{(g}$ reveal the scope and distribution of recency effects. The presence of statistically significant shifts across all tested models and settings highlights the value of these new bias-detection methods.
Implications and Future Work
The study underscores the significance of recognizing and mitigating recency bias within LLM-based IR systems. Recency bias in reranking has the potential to overshadow well-established and credible sources of information, which could result in an imbalance favoring less credible, but temporally newer content. Future work will need to expand on these findings by incorporating a wider range of test collections, LLM architectures, and contrasting temporal treatment scenarios to develop a stronger understanding and mitigation strategies for recency bias and other potential biases in LLM-centric IR systems.
Conclusion
In conclusion, this study sheds light on an inherent recency bias in LLM-based reranking systems, illustrating the complexity and systemic nature of temporal biases affecting LLM-based rankings. As LLMs continue to play an integral role in information retrieval, it becomes crucial to address these biases to safeguard the integrity of search results and prevent outdated but credible information from being unduly devalued. Future research should continue to explore the breadth of biases within LLM-enhanced IR systems and develop robust countermeasures to ensure unbiased retrieval performance. This work lays the foundation for such future endeavors, while the proposed diagnostic framework and metric suite serve as tools for researchers aiming to advance LLM-based retrieval technology.