- The paper develops a novel loss-aware geometric approach that augments the quantum geometric tensor with loss gradient information to regulate effective learning rates.
- It introduces conformal loss-aware (CLA) metrics which modulate the learning rates via anisotropic and conformal deformations, achieving faster convergence in both quantum circuits and classical networks.
- Empirical benchmarks show that, while QNG remains robust, CLA-3 can deliver significant speedups and superior performance under favorable conditions, especially in low-noise regimes.
Loss-Aware Geometric Optimization in Quantum Variational Algorithms
Motivation and Background
Natural gradient descent (NGD) methods, grounded in information geometry, employ the Fisher information metric (FIM) in the classical setting or the pullback Fubini-Study metric/Fubini-Study tensor (FS) in the quantum domain to accelerate and stabilize optimization, circumventing the inefficiencies of naive (Euclidean) gradient descent by exploiting parameter-manifold curvature. In quantum variational algorithms (QVAs) such as the Variational Quantum Eigensolver (VQE), this framework underlies the Quantum Natural Gradient (QNG) optimizer. While these approaches are geometry-aware with respect to the underlying probability or quantum state manifold, they are intrinsically insensitive to the geometry of the objective function landscape—the "loss geometry" defined by the expectation values of quantum observables or cost functions. This insensitivity can lead to suboptimal learning rates, especially near regions of the parameter manifold with high curvature in the loss landscape.
The paper "Loss-aware state space geometry for quantum variational algorithms" (2604.05627) systematically addresses this gap by developing a geometric optimization framework that directly incorporates the loss landscape into the metric structure and update rules, leading to a family of loss-aware (LA) and conformal loss-aware (CLA) optimizers, analytically and numerically evaluated in both quantum and classical settings.
Loss-Aware Pullback Geometry and Optimizer Construction
The central theoretical contribution is the construction of a pullback metric on parameter space that explicitly includes the gradient/curvature of the loss function. Given a base manifold M with FIM or QGT gij, the authors consider an ambient manifold M~=M×R, embedding the loss function L(θ) as a hypersurface, and pulling back the block-diagonal metric
g~AB=diag(gij,1)
under this embedding. The resulting induced metric is
gijLA(θ)=gij(θ)+∂iL(θ)∂jL(θ)
This is a rank-1 (anisotropic) deformation of the base metric, enhancing the geometry to account for the tangent vector of the loss. Importantly, this construction does not alter gradient flow direction, but rescales the effective step size in a loss-adaptive, geometrically principled manner. The Sherman-Morrison formula ensures tractable inversion for update computations.
In the quantum setting, the formulation applies with gijFS as the base (the QGT/QMT), respecting U(1)-gauge invariance, ensuring physical meaning for quantum state manifolds. The position-space representation demonstrates how loss-dependent corrections introduce nonlocal contributions to the metric.
To further modulate effective learning rates, the authors introduce a conformal class of metrics:
gijCLA(θ)=Ω2(θ)[gij(θ)+∂iL(θ)∂jL(θ)]
with the conformal factor Ω2(θ) designed to scale distances homogeneously in the parameter manifold. Several instantiations are constructed:
- CLA-1: gij0 (damped stretch, gij1),
- CLA-2: gij2 (geometry shrinkage, capped effective step-size),
- CLA-3: gij3 (providing most aggressive learning rate gains without unstably increasing step-size),
where gij4 is the squared norm of the cost vector in the base metric.
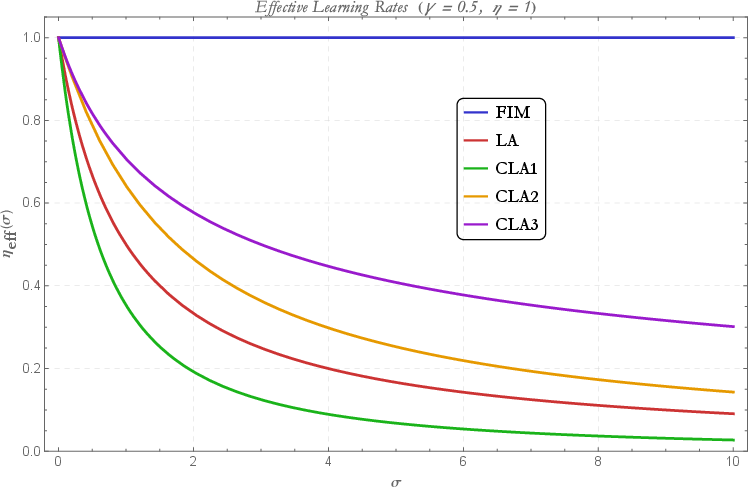
Figure 1: Comparison of effective learning rates for LA geometries as a function of the cost vector norm gij5, demonstrating that CLA-3 achieves the largest admissible rates across the practical parameter range.
Performance of LA and CLA optimizers is benchmarked on both quantum circuits (six-qubit variational circuits with block-diagonal QGT approximation) and classical MLPs (MNIST), comparing against standard QNG and first-order optimizers. Bayesian hyperparameter optimization is utilized for fair cross-method comparison, with convergence criteria based on relative error thresholds and trimmed mean statistics across circuit/task ensembles.
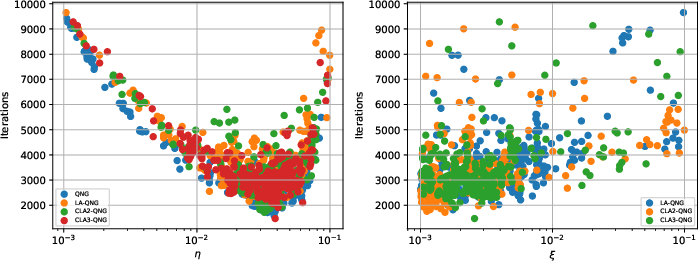
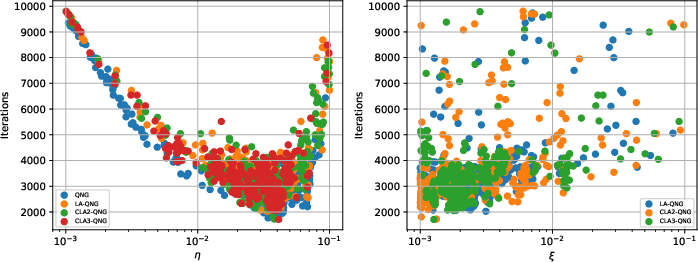
Figure 2: Optimization landscapes for all methods as functions of learning rate and curvature-related hyperparameter gij6, for noisy and noiseless settings.
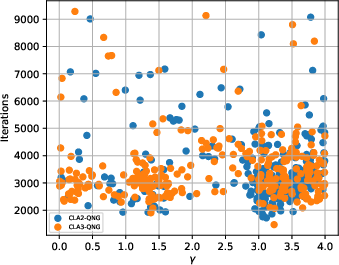
Figure 3: Two-dimensional learning landscapes, contrasting noisy and noiseless regimes; high-dimensional parameter scans for gij7 and gij8.
Best-performing regions are characterized by stable learning rate plateaus; increased gij9 in CLA-3, e.g., supports larger step-sizes without loss of convergence.
Comparative Results: Quantum Variational Circuits
Headline numerical findings:
- QNG achieves the fastest median convergence rate and is most robust overall, especially at worse quantiles of the optimization time distribution. This supports continued use of QNG as a default in quantum variational optimization.
- CLA-3 frequently attains the fastest convergence in favorable runs, often exceeding QNG on “easy” circuit instances. For win-rate at the tightest error threshold, CLA-3 outperforms QNG (e.g., 60% vs 20% in noiseless setups).
- CLA-2 and classical LA-NG variants yield more conservative dynamics but can offer increased stability in certain settings.
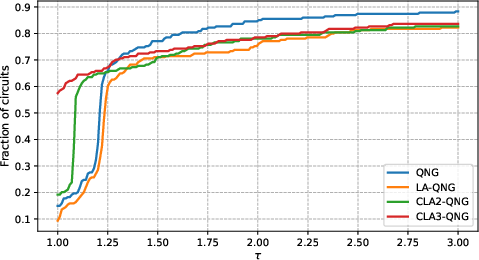
Figure 4: (a) Median and interquartile convergence curves for noisy and noiseless cases; (b) Dolan–Moré performance profiles for each method, showing fraction of circuits solved within a multiplicative factor of the best solver.
Win-rate results across error thresholds reveal the robustness/peak-performance tradeoff (QNG for overall robustness, CLA-3 for best-case speed):
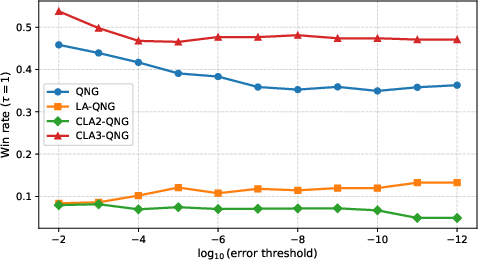
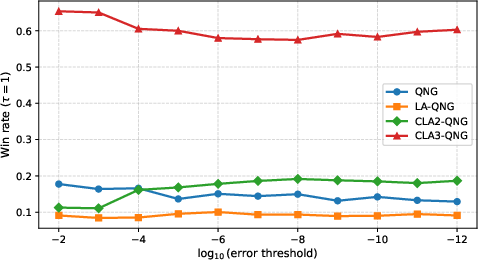
Figure 5: Win-rate curves as a function of error threshold for each optimizer; CLA-3 wins more frequently in tight convergence regimes.
Classical Optimization: Fisher-Preconditioned Neural Nets
Classical MLP optimization is compared using Adam, SGD-RMS, Fisher NG, LA-NG, CLA-2, and CLA-3 methods (with K-FAC Fisher approximation). As in the quantum case, curvature-aware methods (especially CLA-3 and LA-NG) converge significantly faster and reach superior minima versus standard first-order methods (Adam/SGD). Time-to-threshold validation accuracy is significantly reduced for CLA-3 and F-LANG.
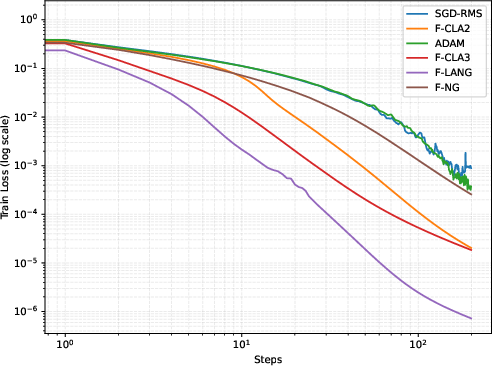
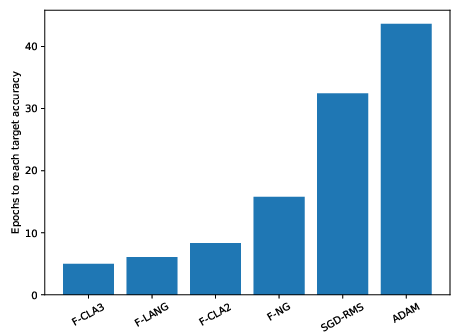
Figure 6: Training loss and epochs-to-threshold-accuracy for classical MLPs; CLA-3 enables the fastest task completion.
The authors provide an information geometric underpinning for the LA metric via divergence expansions. Beyond standard Hermitian geometry, biorthogonal constructions are developed, enabling the definition of non-Hermitian, operator-weighted, and non-metric LA geometries. This yields:
- Gauge-invariant LA quantum geometric tensors (QGTs) and Berry curvatures sensitive to both state and observable parametrics,
- Decomposition into real/imaginary and symmetric/antisymmetric components, revealing "flipped" curvature contributions,
- Explicit dual M~=M×R0-connections generalizing the classical information geometric structure to quantum settings.
These analytic structures connect the LA optimization to the deeper landscape of quantum information geometry and operator theory.
Geometric and Physical Implications
The appendix examines analytic properties for exponential-family models, illustrating how LA metric deformations preserve or transform hyperbolic curvature and the scale invariance of the statistical manifold. LA and CLA metrics alter the effective Ricci scalar and NG trajectories, with figures detailing these dependencies for parameter coordinates and kernel widths.
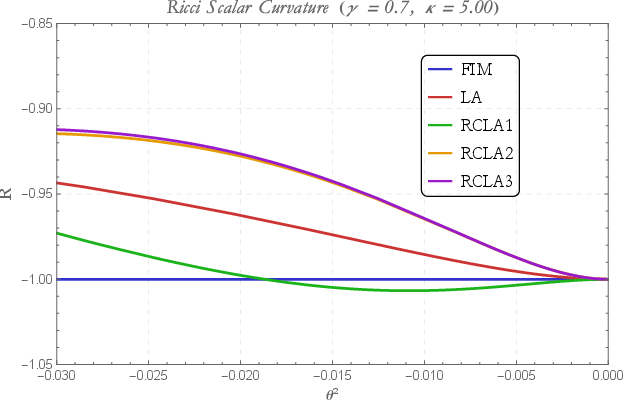
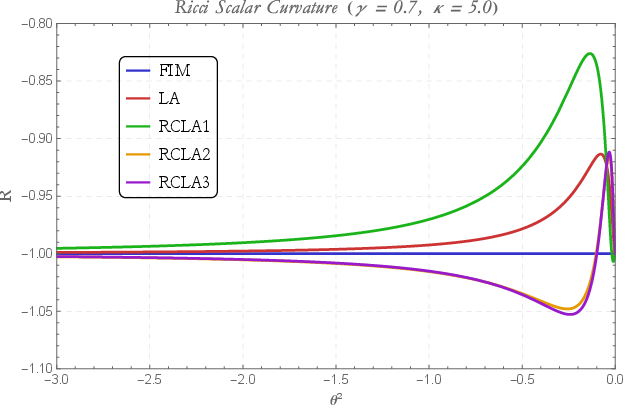
Figure 7: Ricci curvature variation with parameter M~=M×R1 for all five metric families, confirming persistence of negative (hyperbolic) curvature structure.
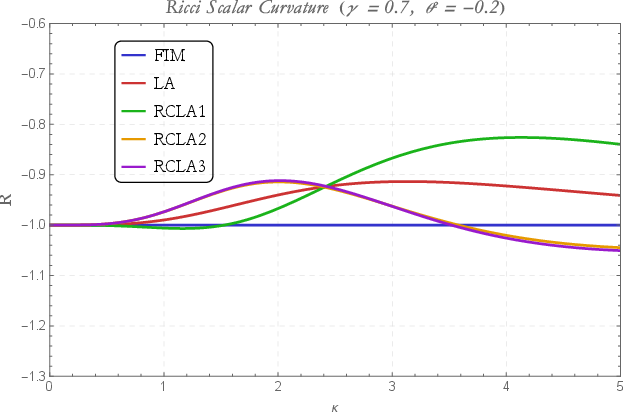
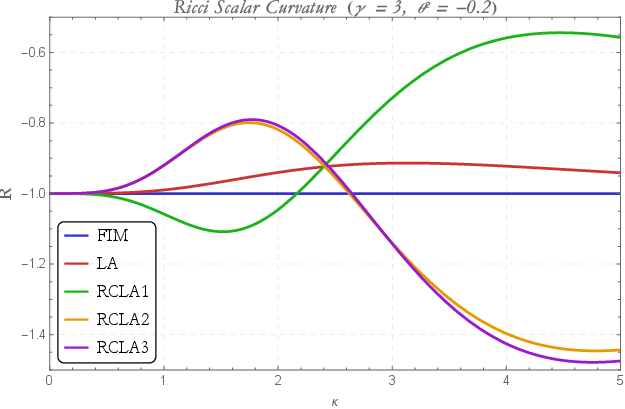
Figure 8: Ricci scalar dependence on Gaussian kernel width M~=M×R2 and conformal scaling parameter M~=M×R3, elucidating the geometric flexibility of the LA/CLA constructions.
Conclusion
This work provides a rigorous and flexible geometric protocol for loss-aware optimization, applicable in both quantum and classical variational scenarios. By incorporating the loss landscape via anisotropic and conformal deformations of the information metric, the derived methods regularize step-sizes in high-loss-curvature regions and permit aggression in flatter regimes, improving convergence efficiency.
Empirical results underline that, while standard QNG delivers the best robustness and typical performance, properly tuned CLA-3 schemes can provide best-case speedups, and outperform conventional optimizers on significant task subsets. In both quantum and classical regimes, information-geometric curvature-aware algorithms remain competitive or dominant, particularly in data/parameter-rich or ill-conditioned scenarios. The extension of these ideas to non-Hermitian and gauge-invariant quantum geometry represents a promising avenue for further research, tying optimizer design to the structure of quantum observable manifolds and potentially to families of monotone quantum metrics (2604.05627).
Future directions include:
- Analytical study of stability and convergence for non-Hermitian LA geometries,
- Application to noisy/interacting quantum circuits with elaborate observables,
- Exploration of LA/CLA-type updates in reinforcement learning and meta-learning in AI,
- Systematic integration with low-rank and tensor-network-based QGT approximations,
- Investigation of the connection between metric deformations and complexity measures or phase transitions in quantum many-body systems.
References: (2604.05627)