- The paper introduces COSMO-Agent, a tool-augmented reinforcement learning framework that integrates CAD–CAE pipelines with closed-loop feedback.
- It employs a multi-objective reward function based on actual toolchain logs to efficiently optimize design parameters while managing simulation and execution failures.
- Empirical results show superior success rates, interaction efficiency, and robustness compared to existing LLM and optimization benchmarks.
Problem Statement and Motivation
The paper addresses the critical bottleneck in practical industrial design–simulation loops: automating closed-loop CAD–CAE optimization under coupled, multi-objective constraints and high toolchain instability. Existing approaches—whether optimization algorithms or recent LLM agents—fail to integrate downstream physics-based feedback and robustly handle non-idealities such as CAD/CAE failures, pipeline non-convergence, and parametric invalidity. The manuscript reformulates this as a long-horizon sequential decision-making problem, introducing hard executability constraints and stochastic failure modes as first-class aspects of the learning environment.
COSMO-Agent Framework
COSMO-Agent is a tool-augmented reinforcement learning (RL) framework wherein an LLM acts as a central policy. The entire CAD–CAE pipeline—parametric geometry generation, physics-based simulation, result parsing, and constraint-driven revision—is formalized as an interactive RL environment with explicit modeling of failures and multi-stage feedback.
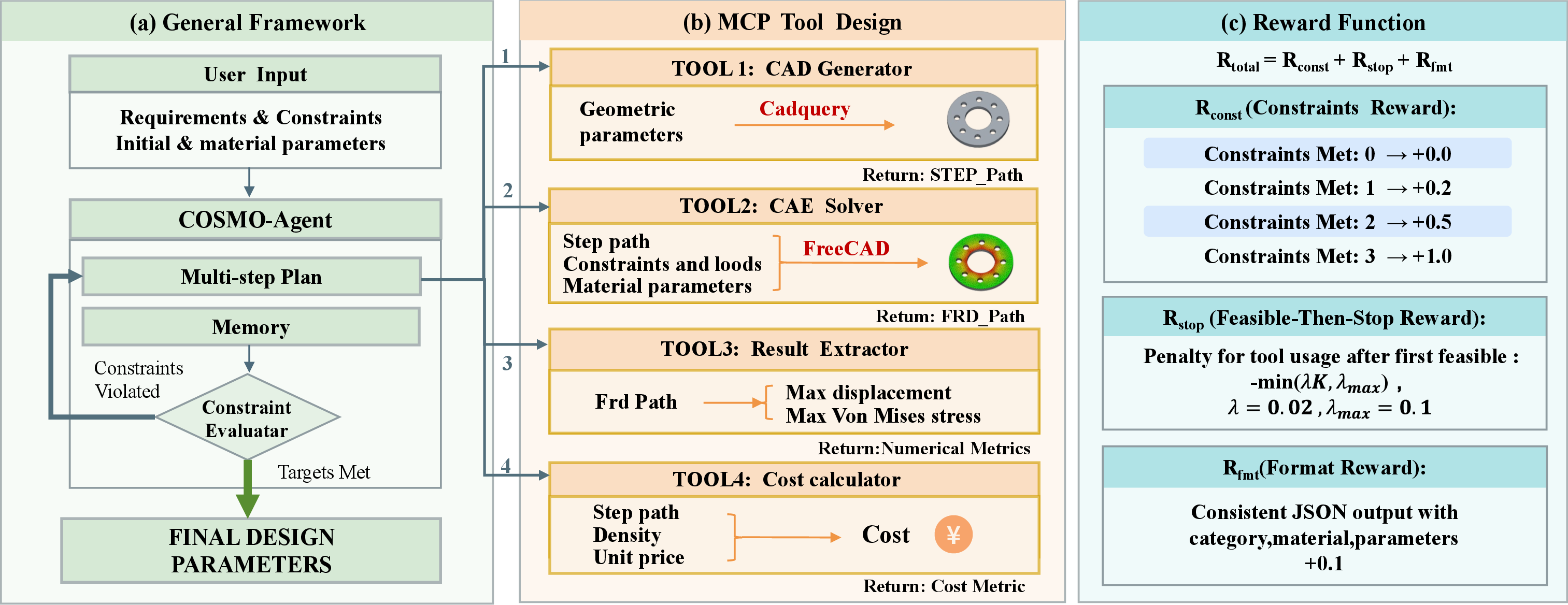
Figure 1: COSMO-Agent overall closed-loop framework with MCP APIs enabling external CAD–CAE tool invocation and a multi-objective reward for RL.
The design workflow is realized as repeated episodes: the LLM receives a problem prompt containing design requirements, constraints, and parameterizations, then orchestrates tool usage:
- CAD Generator: Produces parametric solid geometry.
- CAE Solver: Executes FEM simulations under prescribed material, load, and boundary scenarios.
- Result Extractor: Parses maximum displacement and von Mises stress metrics from solver output.
- Cost Calculator: Assesses economic constraints.
The LLM iterates, revising design parameters and material assignments, until all constraints (on displacement, stress, cost) are satisfied, or the step budget is exhausted. Each action and tool response is recorded, and the policy is trained to optimize not only feasibility but also efficiency (minimal tool calls) and robustness to execution failures.
Reward Design and Learning Objective
The RL training signal is multi-objective. The reward function integrates three components:
- Constraint Satisfaction: Stepwise and terminal rewards for meeting physics and economic constraints.
- Feasible-Then-Stop Penalty: Penalizes superfluous tool invocations after constraints are first met, incentivizing minimal interaction.
- Structured Output Consistency: Ensures the model’s outputs are reproducible and valid, expressed as parseable JSON tied to actual tool outputs.
Uniquely, reward computation is derived from the actual toolchain rollout logs (not costly re-simulations or superficial JSON regression), thereby ensuring optimization is grounded in real pipeline behavior and penalizes patterns that exploit spurious proxy metrics or hallucinate non-executable designs.
Dataset and Benchmark
To operationalize this closed-loop objective, the authors release an industry-aligned benchmark consisting of ∼20,000 CAD–CAE optimization tasks across 25 component categories. Each task couples parametric geometry, detailed constraints, material library, and executable toolchain configurations (down to CAE boundary and material assignments). Importantly, the dataset stratifies on generalization by designating five part categories for out-of-distribution assessment.
Empirical Results
COSMO-Agent is benchmarked against leading open and closed-source LLMs, including Qwen variants, Intern-S1 models, Claude-Sonnet-4.5, and Gemini-3-Flash, all tested under identical pipeline, prompt, and tool budgets. Key results:
- Full Success Rate (FSR): COSMO-Agent (8B) achieves 74.5% FSR on the main test set, exceeding Intern-S1 (32.0%), and Gemini-3-Flash (67.5%)—the latter being a notable strong proprietary baseline.
- Constraint Breakdown: Displacement (87.5%), stress (76.0%), cost (93.5%) satisfaction rates all lead among reported systems.
- Interaction Efficiency: COSMO-Agent averages 6.72 tool calls versus Gemini’s 9.32, demonstrating greater sample efficiency under step budgets.
- Structured Output: 100% of test cases yield parseable, executable JSON results, unlike 98% for Gemini, addressing practical challenges in downstream deployment.
- Generalization: On five unseen categories, COSMO-Agent maintains FSR at 75.0%, with open-source and closed-source baselines lagging significantly (e.g., Intern-S1 at 35%, Gemini at 57%). The model’s robustness to category shift underscores the value of RL over tool-augmented closed-loop feedback.
Ablation studies underscore that GRPO-based RL is indispensable: disabling RL drops FSR from 74.5% to 26.0%. Further, replacing rollout-log-based reward with a naïve re-simulation check encourages tool call minimization and “guessing” behaviors, verifying the necessity of RL grounded in full intermediate toolchain feedback.
Qualitative Illustration
Qualitative visualizations show COSMO-Agent’s capacity for multi-round feedback-driven design refinement, e.g., jointly minimizing displacement and cost by material switching and incremental geometric modification. The agent autonomously sequences CAD updates, simulation runs, and result extraction, converging to viable solutions.
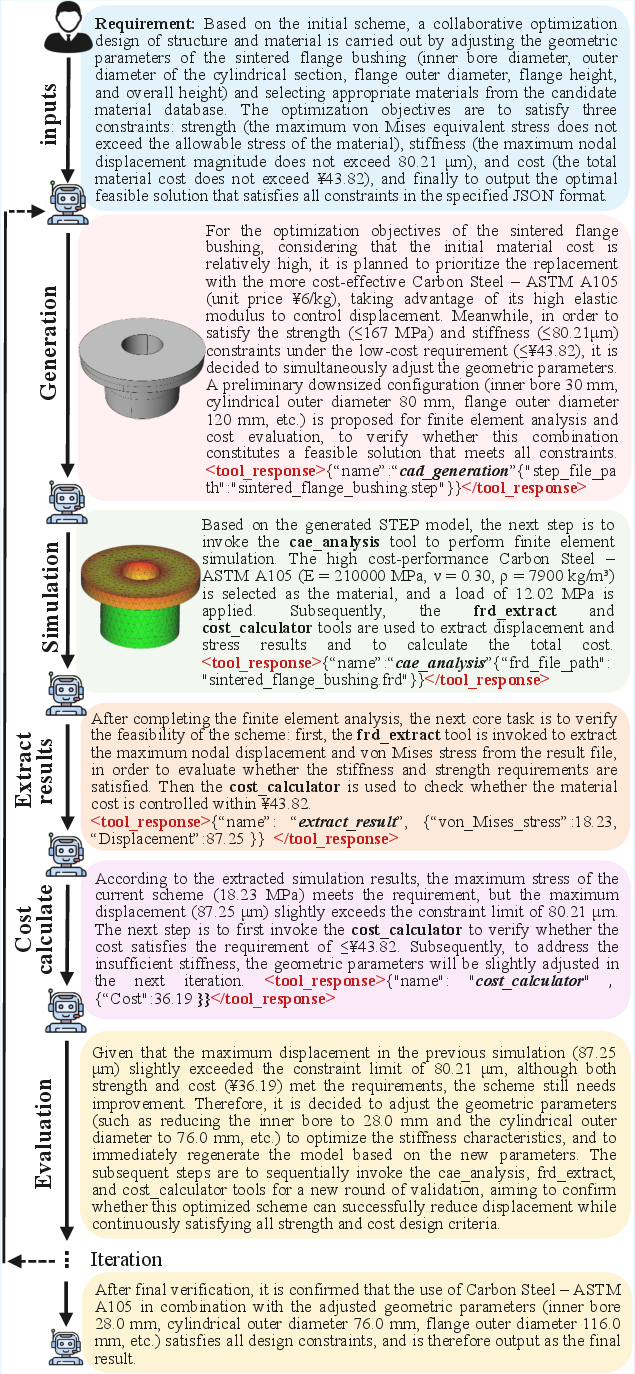
Figure 2: Visual examples demonstrating COSMO-Agent’s iterative workflow and design adjustments based on surrogate and simulation responses.
Theoretical and Practical Implications
The incorporation of explicit toolchain failures and hard constraints as central to the optimization state marks a shift in RL agent design for engineering pipelines. COSMO-Agent’s architecture and reward structure are directly transferable to other settings with stochastic non-differentiable feedback, such as coupled multiphysics, assembly, or cost-driven manufacturing workflows. The framework enables systematic scaling to larger libraries, alternative tool backends, and more complex coupling of design and simulation states.
On the practical side, high rates of feasible, reproducible solutions combined with sample efficiency and format robustness indicate immediate applicability to human-in-the-loop or fully autonomous design acceleration platforms. The closed-loop, tool-augmented RL paradigm generalizes beyond industrial CAD–CAE to other scientific and engineering domains characterized by non-ideal, failure-prone computational pipelines.
Conclusion
COSMO-Agent establishes a new standard for LLM-based closed-loop optimization in complex engineering environments (2604.05547). By combining tool-augmented RL, a multi-constraint reward rooted in actual pipeline execution, and an industry-scale benchmark, the system delivers superior rates of feasible, reproducible, and interaction-efficient design completions. Its demonstrated generalization and ablation insights provide a blueprint for future work in tool-agents acting over non-differentiable, multi-objective, failure-prone domains. Extensions to broader constraints (contact, multi-part, multi-physics), backends, and training curricula are suggested as immediate avenues for advancing reliability and transfer in real-world pipelines.