- The paper introduces a novel framework, TOOLCAD, that frames text-to-CAD modeling as a sequential decision process using reinforcement learning and iterative tool invocation.
- It integrates Chain-of-Thought prompting, a Model Context Protocol for tool calls, and hybrid feedback methods to boost CAD modeling success to over 60% in complex tasks.
- Evaluation shows that TOOLCAD enhances geometric precision and reduces error rates, outperforming conventional text-to-code techniques on expert-level CAD tasks.
TOOLCAD: Tool-Using LLM Agents for Text-to-CAD Generation via Reinforcement Learning
Motivation and Problem Setting
The conversion of expert-level natural language instructions to Computer-Aided Design (CAD) models involves intricate, multi-step reasoning and precise manipulation of geometry via specialized modeling tools. Despite the rapid advancements of LLMs and VLMs in automating structured decision-making tasks, their integration for tool-augmented, end-to-end CAD modeling remains underexplored. Previous approaches largely generate CAD sequences or code from prompts, which suffer from insufficient grounding in CAD engine feedback and limited capacity for complex, long-horizon modeling workflows.
TOOLCAD is introduced to bridge this gap by casting the text-to-CAD modeling process as a sequential reasoning and acting problem, formalized as a Markov Decision Process (MDP) where LLM agents iteratively plan, invoke CAD tools, and reflect on feedback to construct geometry. Unlike prompt-to-code paradigm, TOOLCAD emphasizes direct, iterative interaction with the CAD engine, leveraging RL and curriculum-based task scheduling for agent policy evolution. Figure 1 highlights the difference between conventional code generation and the tool-using agent mechanism implemented in TOOLCAD.
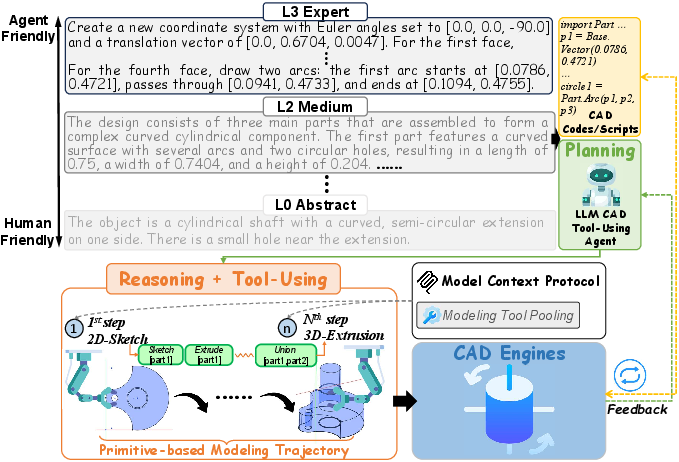
Figure 1: Prompt-to-Tool vs. Prompt-to-Code. L3 expert-level modeling text enables CAD tool-using agents to plan, reason, call tools, and complete modeling tasks via iterative CAD-engine feedback.
The TOOLCAD framework operationalizes LLM-based tool-using CAD agents through three core components:
- CAD Modeling Decision-Making: Using Chain-of-Thought (CoT) prompting, TOOLCAD elicits step-level reasoning for decomposing complex CAD tasks. The agent produces structured, explicit reasoning interleaved with tool-calling instructions responding to L3 expert prompts, ensuring interpretability and action traceability.
- Modeling Tool Integration: Agents are equipped with a library of parameterized CAD operations exposed via a Model Context Protocol (MCP) server within FreeCAD, standardizing tool invocation and facilitating robust environment coupling for language-guided modeling.
- Reflective Automatic Modeling: The agent receives hybrid feedback (step-level, human-augmented, and trajectory-level signals). Reflective policy optimization leverages these signals, updating modeling plans and tool usage in response to real-time outcomes.
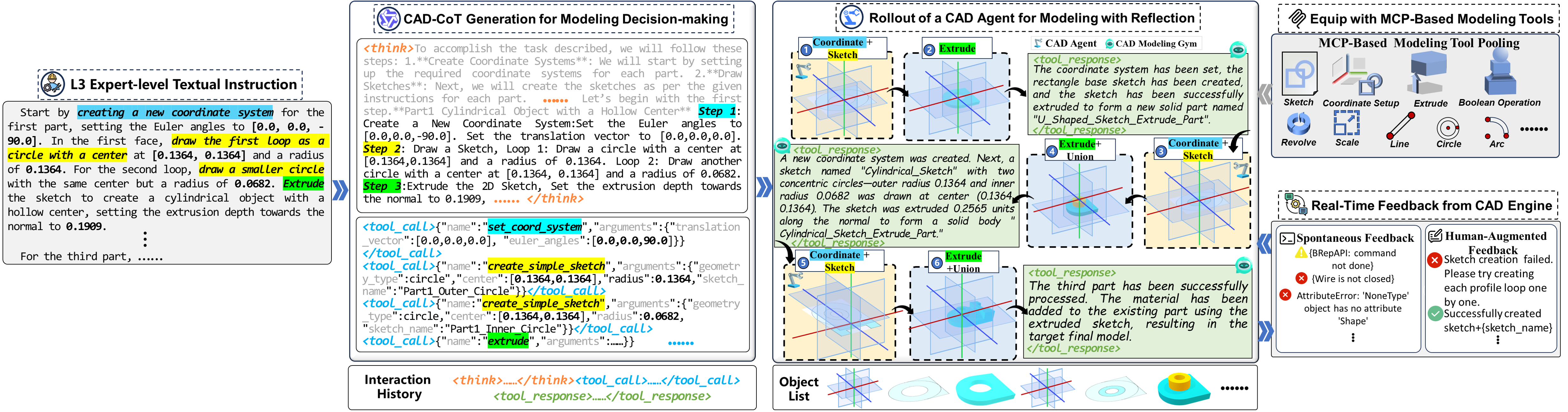
Figure 2: CAD-specific Tool-Using Agent Workflow for Text-to-CAD Generation: decision making, tool/environment selection, and automatic modeling with feedback/reflection.
The agent thus operates in an iterative, closed-loop fashion: extracting reasoning chains, invoking tool procedures, and dynamically adjusting based on environmental and outcome feedback at each step.
Reinforcement Learning Curriculum and Reward Modeling
TOOLCAD introduces an online RL learning gym purpose-built for CAD agents. Two principal reward pathways drive policy improvement:
- Outcome Reward Modeling (ORM): An LLM-based outcome referee is fine-tuned using human-verified demonstrations to assign binary success/failure labels to trajectory completions. This facilitates automated, scalable trajectory-level supervision and objective assessment of CAD modeling correctness, especially for complex or multi-part geometries.
- Stepwise and Format Rewards: Coarse-grained labels (success/failure) and strict template adherence checks are provided after each tool call, promoting action reliability, error detection (e.g., geometric constraint violations, Boolean errors), and reducing hallucinations in both tool usage and spatial reasoning.
To address instability from long-horizon tasks and trajectory length variability, TOOLCAD employs a part-wise curriculum learning strategy. Task complexity (determined by number of parts per model) increases adaptively as the agent’s average perplexity on held-in tasks falls below a threshold, balancing exploration and exploitation for improved generalization. The RL phase uses Group Relative Policy Optimization (GRPO) for stable, critic-free optimization, outperforming SFT and classic RL methods on all benchmarks.
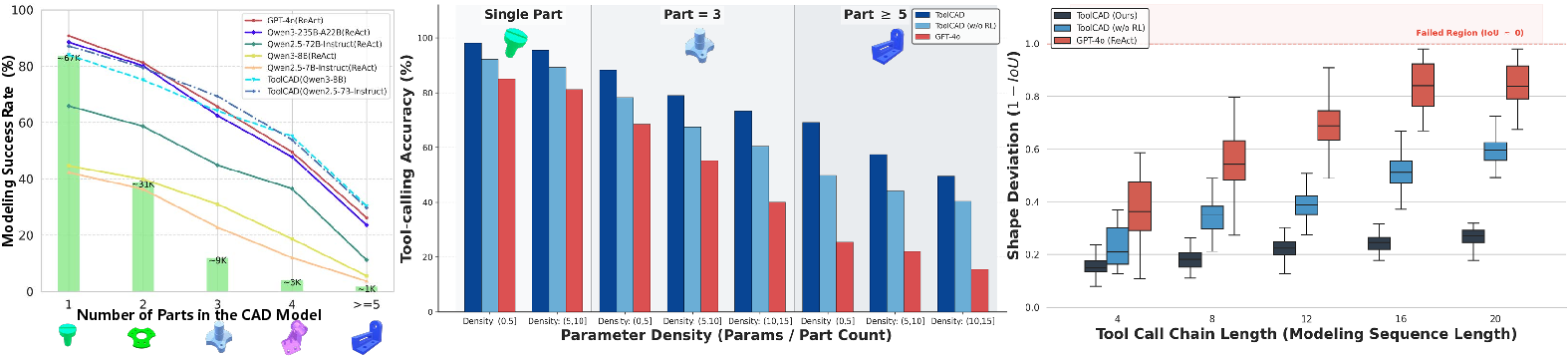
Figure 3: Evaluation of ToolCAD with RL. Modeling success rate, tool-calling accuracy, and geometric precision (1−IoU) are evaluated to comprehensively measure the tool-using agent's modeling behavior and performance.
Empirical Evaluation
Dataset, Baselines, and Protocol
ToolCAD is evaluated on L3-level expert CAD instructions derived from DeepCAD and Text2CAD datasets, which are augmented with 982 human-audited demonstration trajectories and a stratified test suite spanning a range of part counts (model complexities). Comparison baselines encompass:
- SOTA closed and open-source LLMs (GPT-4o, Qwen3-235B, Qwen2.5-7B, Qwen3-8B) evaluated in prompt-based and RL-upgraded regimes.
- Prior transformer and VLM-based CAD generation models (DeepCAD, Text2CAD, CAD-Assistant, CAD-Llama, SkexGen, HNC-CAD) using diverse prompt/coding strategies.
Metrics include Invalidity Ratio (IR), median Chamfer Distance (MCD), tool-calling accuracy, geometric precision (1-IoU), and instruction-level operation F1.
Main Results
ToolCAD-trained models (Qwen2.5-7B-Instruct, Qwen3-8B) achieve success rates of 63.9% and 61.8%—matching or surpassing much larger proprietary LLMs—with significantly lower geometric error and invalidity rates across tasks of varying complexity. RL-based post-training via the ToolCAD framework yields ~20% higher success rates versus SFT and offline RL baselines, with pronounced improvements for multi-part (long-horizon) modeling.
Performance decays in prompt-based LLMs and VLM-integrated methods are evident as the number of modeled units increases; in contrast, ToolCAD exhibits robust scaling due to its reflective RL design and dense feedback integration. Case analyses also demonstrate that ORM supervision captures subtle, step-level agent failures (e.g., missing units, silent Boolean errors) that are missed by VLM visual baselines, confirming the necessity of highly-structured textual evaluation.
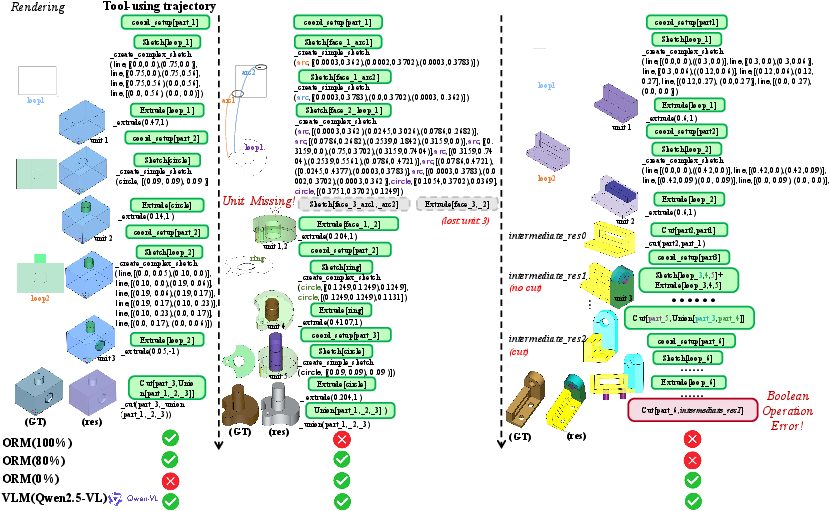
Figure 4: Case study of tool-using agent modeling trajectories. ORM detects subtle step-level failures such as "Unit Missing" and "Boolean Error" that are not resolved with baseline VLM supervision.
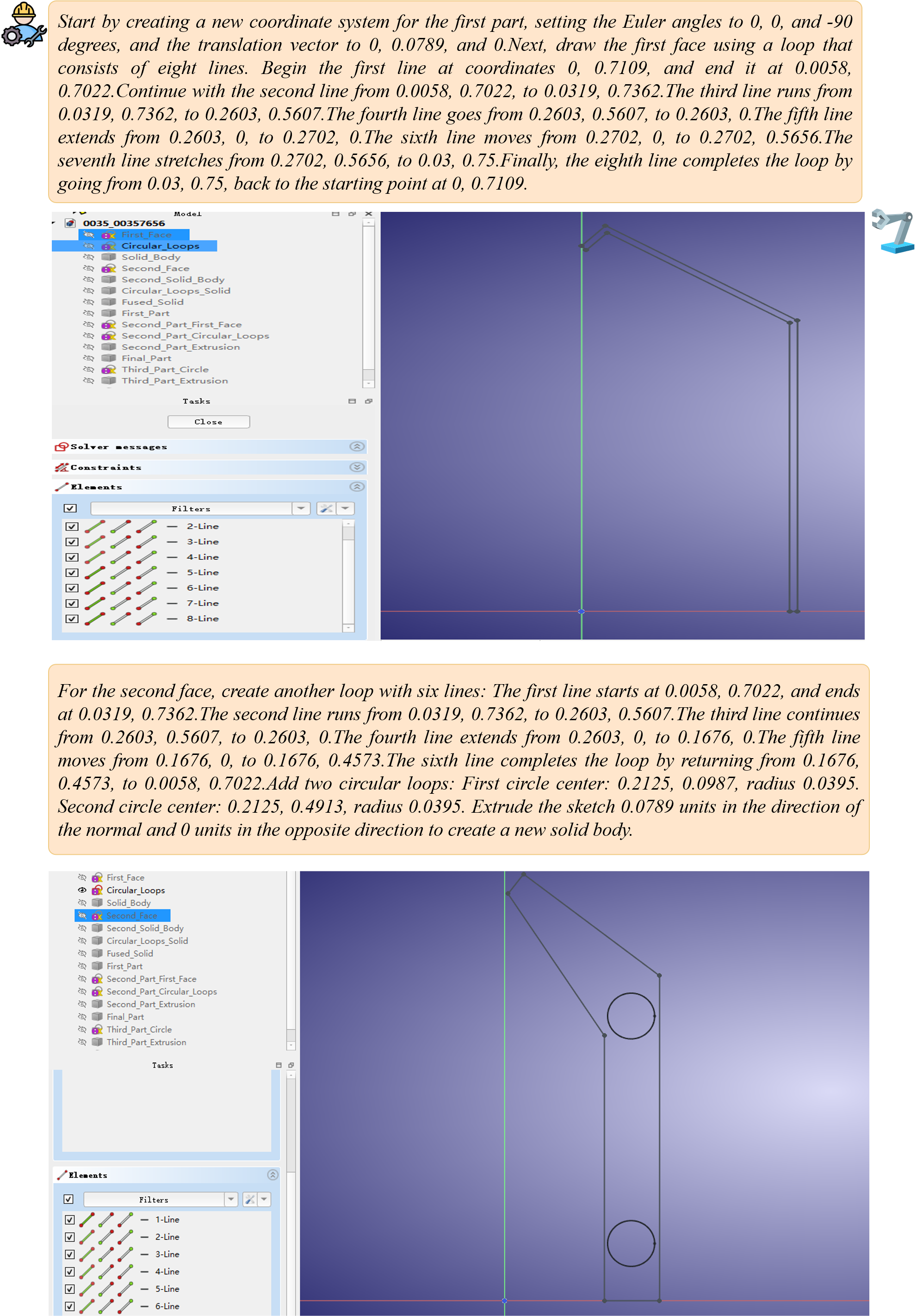
Figure 5: ToolCAD's Agent Modeling Examples—demonstrating the full trajectory of part- and operation-level reasoning, tool invocation, and resulting CAD entities.
Ablation and Scaling Analysis
Ablation studies indicate that both the step-level reward shaping and the curriculum scheduler are critical for RL training stability and final task success rates. The absence of step-level rewards leads to poor credit assignment, while dropping curriculum induces slow learning and poor generalization on higher-complexity tasks.
ORM efficacy is benchmarked against major LLM and VLM baselines, with the ToolCAD ORM outperforming others by up to 12 percentage points on hard (≥5 part) tasks.
Scaling experiments across model size and RL data budget reveal that RL exploration scale is the dominant bottleneck, rather than raw parameter count, for complex, tool-augmented CAD agent performance.
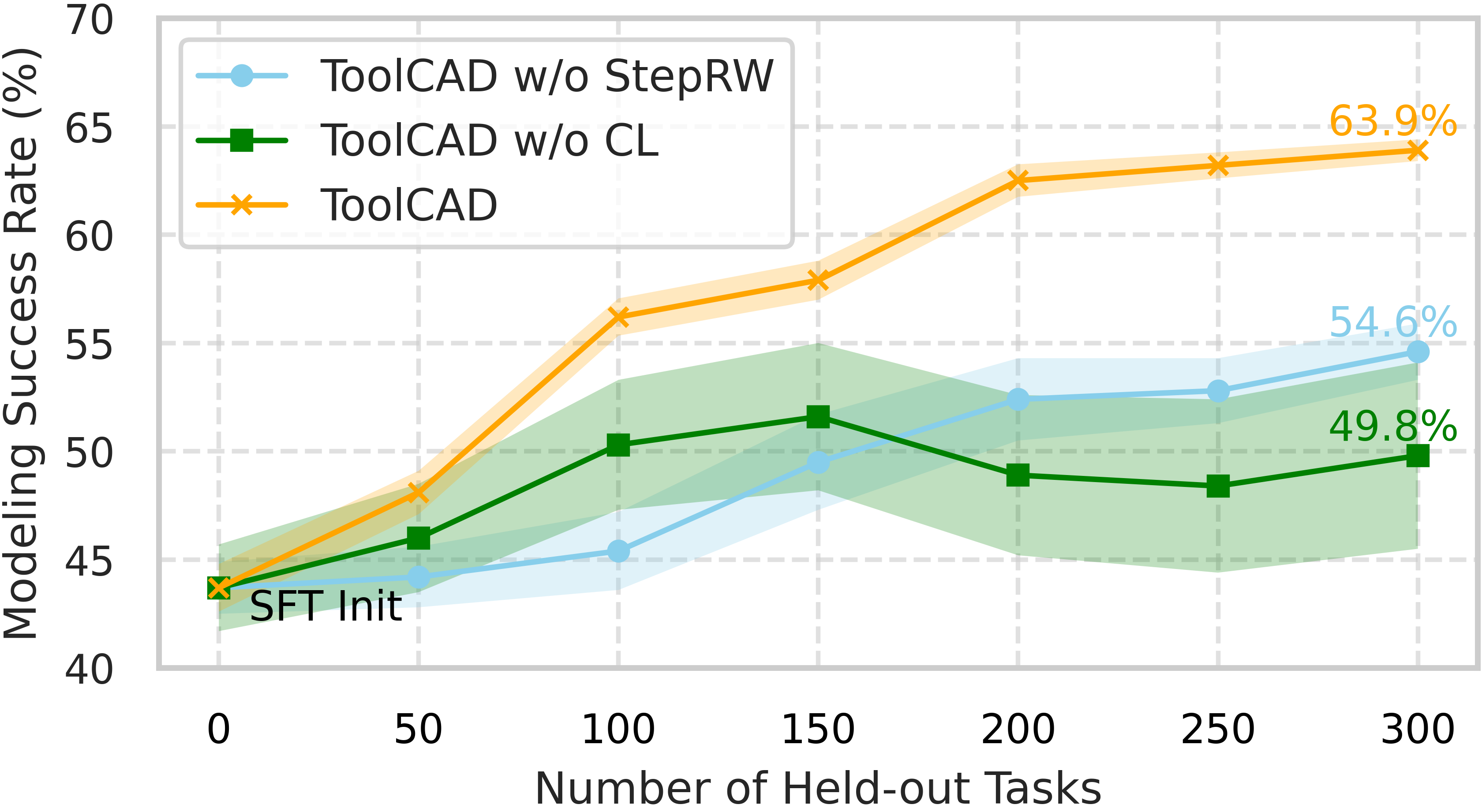
Figure 6: Ablation study of RL framework on step-level feedback and curriculum learning. Both components are essential for stable agent online exploration and ultimate success rate.
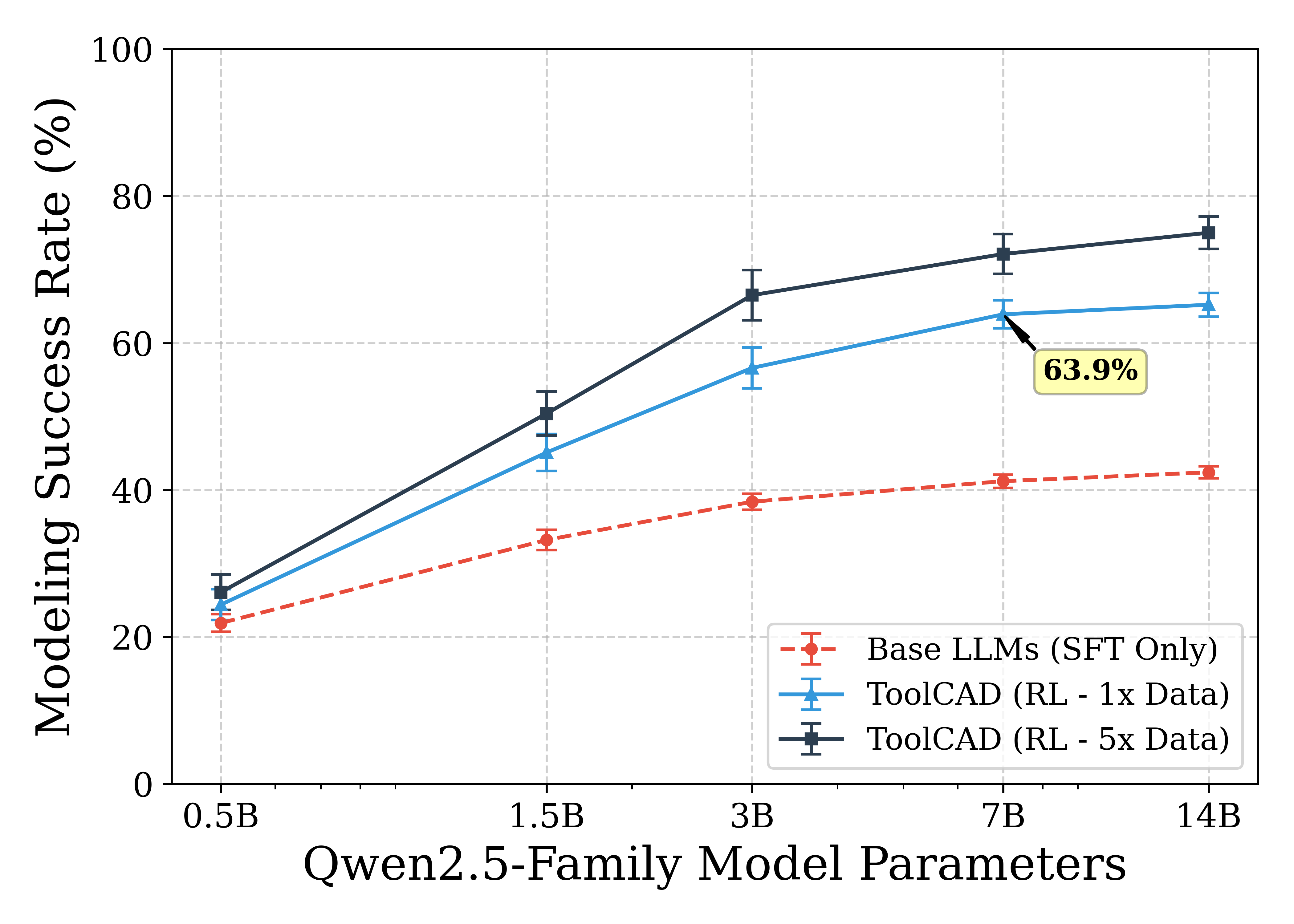
Figure 7: Scaling Laws of CAD Tool-using Agents—demonstrating that RL data scale is a stronger driver of performance than LLM parameter scaling.
Implications and Future Directions
TOOLCAD advances LLM-based, tool-using agent research by demonstrating that open-source LLMs can be transformed into proficient CAD operators via hybrid RL, dense feedback, and carefully designed task curricula. The framework makes a strong claim that tool-augmented, RL-evolved LLM agents can match or even outperform proprietary, much larger models on expert-grade, long-horizon modeling tasks. It also establishes that VLM-based visual feedback, while serviceable for simple geometries, is fundamentally insufficient as task complexity scales and must be replaced by explicit, structured trajectory supervision.
Practically, TOOLCAD provides the backbone for generalizing autonomous text-to-CAD systems beyond toy domains, with extensibility through MCP for new tool libraries and environments. Theoretically, it provides a testbed and benchmark for further research on agentic RL, tool use, scaling laws, and error diagnosis in semantic-to-geometry translation.
Immediate research trajectories include integrating richer geometric perception for upstream guidance, augmenting self-correction/reflection mechanisms, expanding the tool library, and refining ORM for even greater reliability in high-complexity CAD scenarios. The code and environment are released for reproducibility and further community advances.
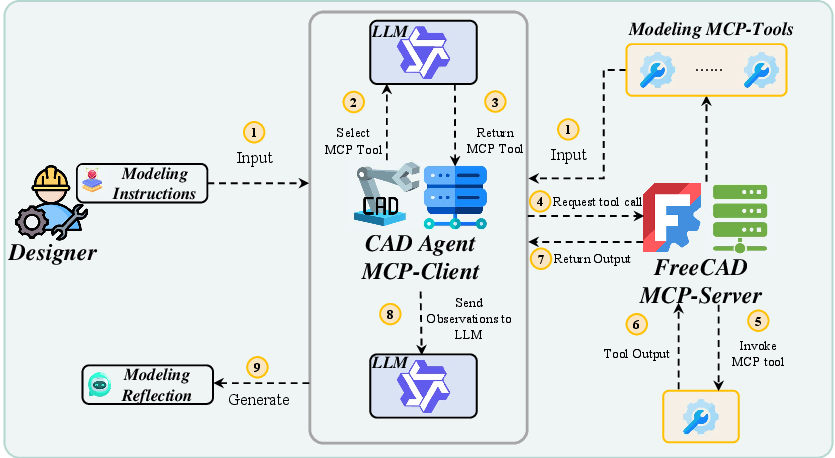
Figure 8: Integration of MCP provides structured environment and tool management, which enhances the extensibility and flexibility of CAD modeling tools.
Conclusion
ToolCAD demonstrates that LLMs post-trained via RL in a feedback-rich, curriculum-guided interactive CAD environment can act as robust, high-accuracy tool-using agents for text-to-CAD modeling. The introduced framework advances the field towards practical, scalable, open-source agentic CAD design systems and sets a foundation for future research at the intersection of language reasoning, tool-augmented decision making, and industrial automation.
Reference: "TOOLCAD: Exploring Tool-Using LLMs in Text-to-CAD Generation with Reinforcement Learning" (2604.07960).