- The paper introduces OntoTKGE, a novel ontology-guided framework that mitigates data sparsity in temporal knowledge graphs.
- It leverages dual global and local encoders, incorporating hierarchical entailment and contrastive losses for robust embedding learning.
- Empirical evaluations show significant improvements in MRR and Hits@ metrics across multiple TKG benchmarks for sparse entities.
Introduction
Temporal Knowledge Graph Extrapolation (TKGE) targets the prediction of future facts given temporal knowledge graphs (TKGs) by reasoning over historical interactions embedded within dynamic knowledge structures. A persistent challenge in TKG extrapolation is effectively modeling entities with sparse interaction histories, which significantly impairs the predictive accuracy of state-of-the-art (SOTA) TKG models. Ontological knowledge, which encodes domain-specific hierarchical relations among abstract concepts and entities, is an underexploited resource for addressing this sparsity, offering an inductive bias by allowing sparse entities to inherit behavioral patterns from popular entities sharing the same conceptual categories.
The OntoTKGE framework introduces an ontology-guided encoder-decoder architecture that tightly integrates ontological and temporal signals, resulting in significant advances in mitigating data sparsity and yielding substantial performance improvements across several benchmarks.
Ontology-View KG Construction
At the core of OntoTKGE is a constructed ontology-view KG, modeling hierarchical concept relations and entity-concept linkages. The pipeline leverages an LLM (GPT-4o-mini) in tandem with entity linking through ReFinED and retrieval from an external static KG (Wikidata). For each entity, historical facts are aggregated and summarized, and the LLM assigns a disambiguated type. Entities are linked to Wikidata, while unlinked entities are typed via coarse retrieval and LLM reranking strategies. Three-hop neighborhoods are extracted for each entity, focusing on ontological and attribute relations, generating a comprehensive ontology-view KG.
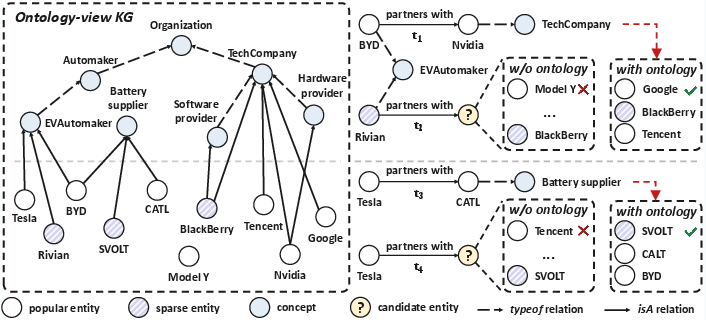
Figure 1: An illustration of the ontology-view KG, depicting concept hierarchies and entity-to-concept relationships utilized for embedding enhancement.
This ontology-view KG enables behavioral and contextual inheritance by sparse entities, offering two key benefits: improved search space for candidate predictions and explicit inclusion of valid, albeit rarely observed, entities in reasoning tasks.
OntoTKGE Framework Overview
OntoTKGE consists of four main components: (1) global ontology-aware evolutionary encoder, (2) local ontology-aware relevance encoder, (3) contrastive-enhanced gated fusion, and (4) the TKG extrapolation model decoder. The framework is flexible and applicable to a variety of state-of-the-art TKGR architectures including RE-GCN, TiRGN, RETIA, LogCL, and HisRES.
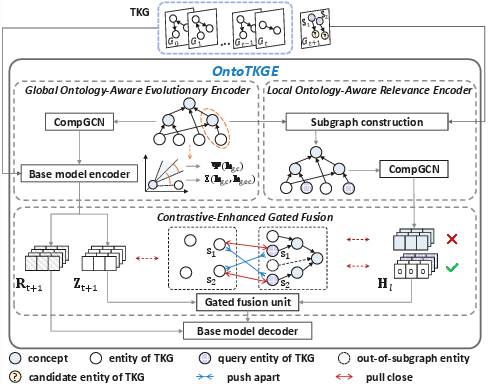
Figure 2: Overview of the OntoTKGE framework, detailing the flow from ontology-view KG construction, dual encoders, fusion via gated contrastive learning, to final TKG extrapolation.
Global Ontology-Aware Evolutionary Encoder
The global encoder applies a modified CompGCN over the ontology-view KG, initializing rich entity and concept embeddings. Key modifications involve independently learned relational embeddings at each GCN layer, enhancing hierarchical information transfer. Hierarchical entailment loss enforces geometric containment, preserving complex ontological partial orders. Embeddings are evolved temporally across TKG snapshots using any base TKG extrapolation encoder, maintaining dynamic consistency.
Local Ontology-Aware Relevance Encoder
To address ontological signal attenuation across temporal evolution—an acute challenge for sparse entities—a local encoder constructs and encodes N-hop subgraphs from the ontology-view KG relevant to each query entity. This component models local hierarchical and semantic context via an independent CompGCN, which is critical for effective representation when historical evidence is limited.
Contrastive-Enhanced Gated Fusion
A gated fusion mechanism combines global (temporal) and local (ontological) embeddings, regulated by a sigmoid gate. To enforce view consistency, contrastive loss is employed, aligning representations for the same entity across both encoders while repelling embeddings for distinct entities, leading to a unified and robust embedding space.
Decoding and Optimization
The final prediction step uses the base TKG extrapolation model’s decoder applied over the fused entity representations. The end-to-end loss is a weighted sum of TKG extrapolation, hierarchical entailment, and contrastive losses.
Empirical Evaluation
Main Results
Extensive experiments on four TKG benchmarks (ICEWS14, ICEWS18, ICEWS05-15, GDELT) show that OntoTKGE delivers substantial gains in Mean Reciprocal Rank (MRR) and Hits@1/10 metrics over base models and all competitive baselines (JOIE, HyperCL, LLM-DA, ANEL). For example, OntoTKGE boosts RE-GCN's MRR from 0.422 to 0.541 on ICEWS14 and LogCL's MRR from 0.485 to 0.597, with corresponding improvements on denser datasets as well.
Contrary to static ontology-enhanced baselines, which often degrade TKG model generalization, OntoTKGE's two-stage encoder and adaptive fusion preserve both conceptual and temporal distinctions.
Ablation and Variant Analysis
Removing either the global or local encoder leads to drastic performance drops, indicating the necessity of hierarchical initialization and contextual supplementation. Hierarchical entailment and contrastive losses are critical; their removal consistently decreases performance, underlining their role in structuring the embedding space.
Variants with standard CompGCN, RGCN, KRAT, or ablated ontology-guided initialization are consistently outperformed by the full OntoTKGE pipeline, establishing the effectiveness of component selection and integration.
Scalability, Sparse Entity Robustness, and Efficiency
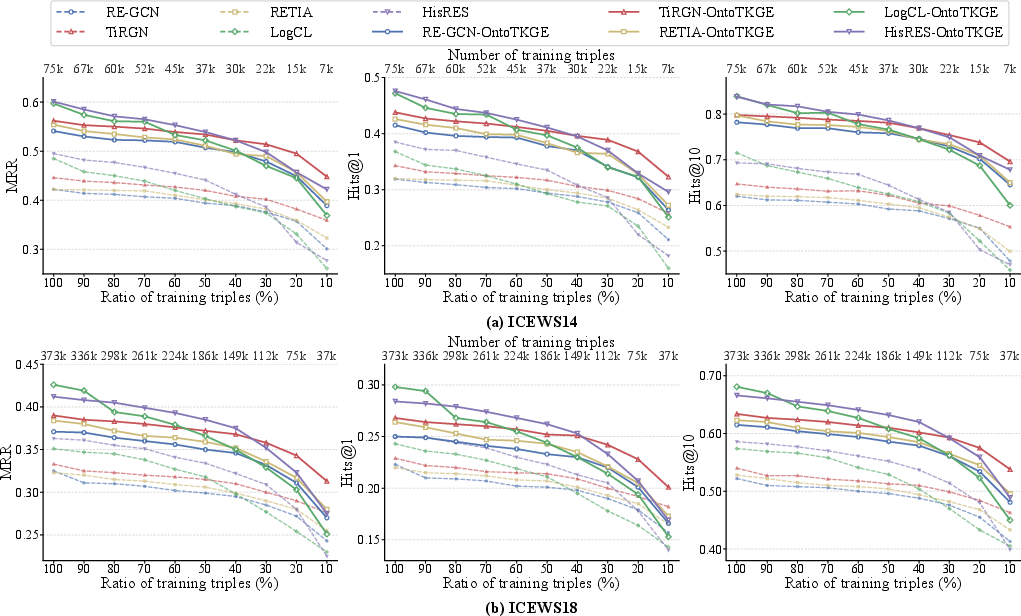
Figure 3: Scalability evaluation over ICEWS14 and ICEWS18, showing OntoTKGE maintains SOTA robustness even as training data size decreases.
OntoTKGE features minimal inference and training overhead compared to baselines, as shown by timing evaluations. Performance on sparse entities—measured over entities with low historical degree—demonstrates the most pronounced MRR/Hits@1/10 improvements, validating the ontological inheritance mechanism.
Parameter Sensitivity
Parameter studies indicate:
- Hop Number N: Optimal contextualization occurs at moderate subgraph sizes (N in {1,2,3}), with performance degradation when excessive, noisy context from the full ontology is incorporated.

Figure 4: Parameter sensitivity with different hop number N for local encoder subgraphs.
- Number of GNN layers J: Two-layer GNNs offer maximal performance, with deeper stacks leading to oversmoothing.

Figure 5: Parameter sensitivity with different number of GNN layers J.
- Entailment cone parameter K: The framework shows insensitivity to wide ranges of K, making it readily adaptable across scenarios.
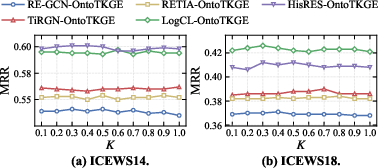
Figure 6: Parameter sensitivity with K over ICEWS14 and ICEWS18.
Case Study
A qualitative case confirms the ability of OntoTKGE-augmented models to surface correct answers for sparse queries, which are ranked orders of magnitude lower by base TKG models. The incorporation of related behaviors from the ontology-view KG allows successful inference even when the requisite historical interaction is absent in the TKG.
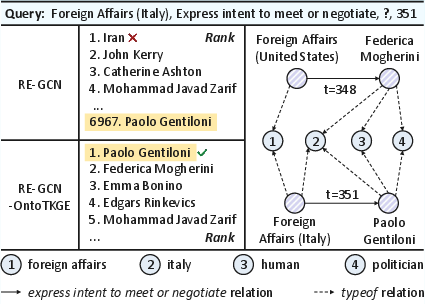
Figure 7: Case study highlighting ontological signal transfer enabling correct ranking of sparse factual candidates.
Practical and Theoretical Implications
Practically, OntoTKGE provides an extensible template for integrating ontological priors with temporal inductive biases, directly addressing long-standing data sparsity issues in TKG extrapolation tasks. Its modular design allows rapid adaptation to evolving SOTA TKG encoders and decoders.
Theoretically, the adoption of hierarchical entailment mechanisms and contrastively aligned dual views sets a paradigm for future research in multi-view KG embedding, providing tools for both enhanced generalization and interpretability. The results strongly support the position that explicit ontological priors are a superior alternative to purely data-driven extrapolation for out-of-distribution and sparse entity generalization scenarios.
Future developments include scaling the approach to even larger or more complex ontologies, integration with open-domain LLM-based reasoning for KG completion, and adaptation for multimodal or multi-relational temporal inference tasks.
Conclusion
OntoTKGE establishes a new state-of-the-art in TKG extrapolation by synergistically combining ontological and temporal signals. Its encoder-decoder architecture and robust dual-view contrastive learning yield pronounced improvements across all tested scenarios, particularly for sparse entities, and its computational footprint remains minimal. By highlighting the untapped value of ontological priors for temporal inference, OntoTKGE redefines best practice for real-world knowledge graph reasoning and opens promising avenues for AI research in temporal relational domains.

