- The paper introduces ReAd, a retrieval-augmented test-time adaptation framework that dynamically fuses collaborative signals with model predictions to handle evolving user preferences.
- It employs a cross-attention module and dual loss functions to optimize fusion of offline memory and live sequence data, improving ranking metrics by over 10% in sparse settings.
- The method is model-agnostic, computationally efficient, and scalable, offering a robust solution for real-world sequential recommendation challenges.
Retrieve-then-Adapt: Retrieval-Augmented Test-Time Adaptation for Sequential Recommendation
Introduction and Motivation
The paper introduces ReAd, a retrieval-augmented test-time adaptation framework tailored for the sequential recommendation (SR) scenario, where the prediction of a user's next interaction is conditioned on their historical behavioral sequence. The core motivation is the challenge of preference shift at inference: while SR models are trained on historical logs, actual user preferences in deployment rapidly evolve due to distributional divergence and temporal dynamics, leading to degraded ranking performance. Conventional strategies—test-time training (TTT), test-time augmentation (TTA), and retrieval-augmented fine-tuning—either impose significant computational or design constraints, are limited by non-systematic augmentation, or require complex multi-stage pretraining. ReAd is proposed as a model-agnostic, scalable mechanism that augments deployed SR models by dynamically retrieving collaborative signals from a memory database, constructing an informative augmentation embedding, and fusing this into the final prediction in a confidence-aware manner.

Figure 1: An overview of the sequential recommendation model, depicting the static nature of model parameters from training to inference and the exposure of the input sequence to preference shift at test time.
Architecture and Methodology
ReAd comprises two principal components: offline preparation and online adaptation. The offline phase entails constructing a collaborative memory database D from training data, in which each entry records the representation of a user sequence (computed by the trained SR encoder Mθ) paired with the embedding of its sequentially next item. This repository of collaborative signals serves as the retrieval base accessible at test time.
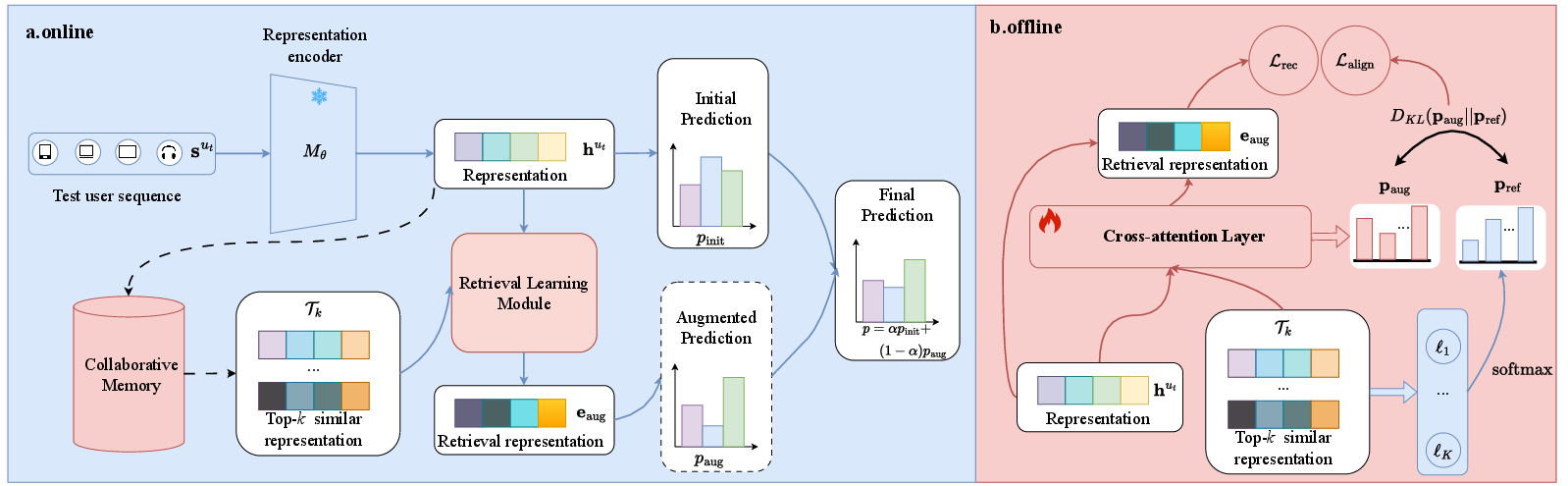
Figure 2: The ReAd framework: (a) Online—encoding the test sequence, retrieving top-k collaborative representations, fusing via retrieval learning, and refining the initial prediction. (b) Offline—retrieval learning using cross-attention and dual loss supervision.
For a test user sequence sut, ReAd proceeds by:
- Computing its sequence representation hut.
- Retrieving the top-k most similar sequence representations and their associated item embeddings from D via cosine similarity (efficiently indexed, e.g., with FAISS).
- Fusing the retrieved embeddings TK into an augmentation embedding eaug with a cross-attention module, which learns to emphasize items not only by collaborative proximity but also by individual predictive utility.
This fusion is optimized by two losses: Lrec, a recommendation loss to ensure prediction fidelity, and Mθ0, a KL divergence that aligns the learned fusion weights with a reference utility-aware distribution. The final test-time prediction is then a confidence-weighted mixture of the original model output and the augmentation-based prediction, where the mixing coefficient is adaptively computed by the entropy of each predictive distribution (focused only on the top-ranked items to mitigate long-tail dilution).
Experimental Results
Extensive evaluation is conducted on five public datasets representing varying sparsity and domains (Amazon Office, Beauty, Sports, Home; ML-1M). Remarkably, ReAd consistently and statistically outperforms a wide range of baselines, including standard SR architectures (GRU4Rec, SASRec, BERT4Rec), contrastive/SSL-based models, and recent test-time and retrieval-augmented approaches such as RaSeRec and TTA. The gains are most pronounced in sparser settings, establishing that ReAd is highly effective where model adaptation to preference drift is most needed.
Numerical Observations
Across all major ranking metrics (HR@K, NDCG@K), ReAd equipped with a contrastive backbone (DuoRec) sets new SOTA numbers. On the Office dataset, for example, ReAd(+DuoRec) achieves HR@10 of 0.1090, compared to 0.1042 (RaSeRec), 0.1011 (DuoRec), and 0.0896 (TTA). These advantages are consistent across domains and backbones, with average improvements often Mθ110% relative over the strongest non-ReAd alternatives.
Ablation studies reveal that both the cross-attention (trainable fusion) and dynamic entropy-based fusion mechanism are indispensable—removal of either yields a notable reduction in accuracy. The dual loss functions, while complementary, show the KL divergence confers slight but consistent improvement, particularly for non-trivial retrieval set sizes.
Analysis
Hyperparameter Sensitivity
Performance is robust to the fusion and loss hyperparameters, with retrieval set size Mθ2 showing a non-monotonic relationship—intermediate values balance richness of the augmentation against injected noise. The fraction of top items to compute entropy (used for confidence-based mixing) must avoid coverage of the extreme long-tail for effective discrimination.
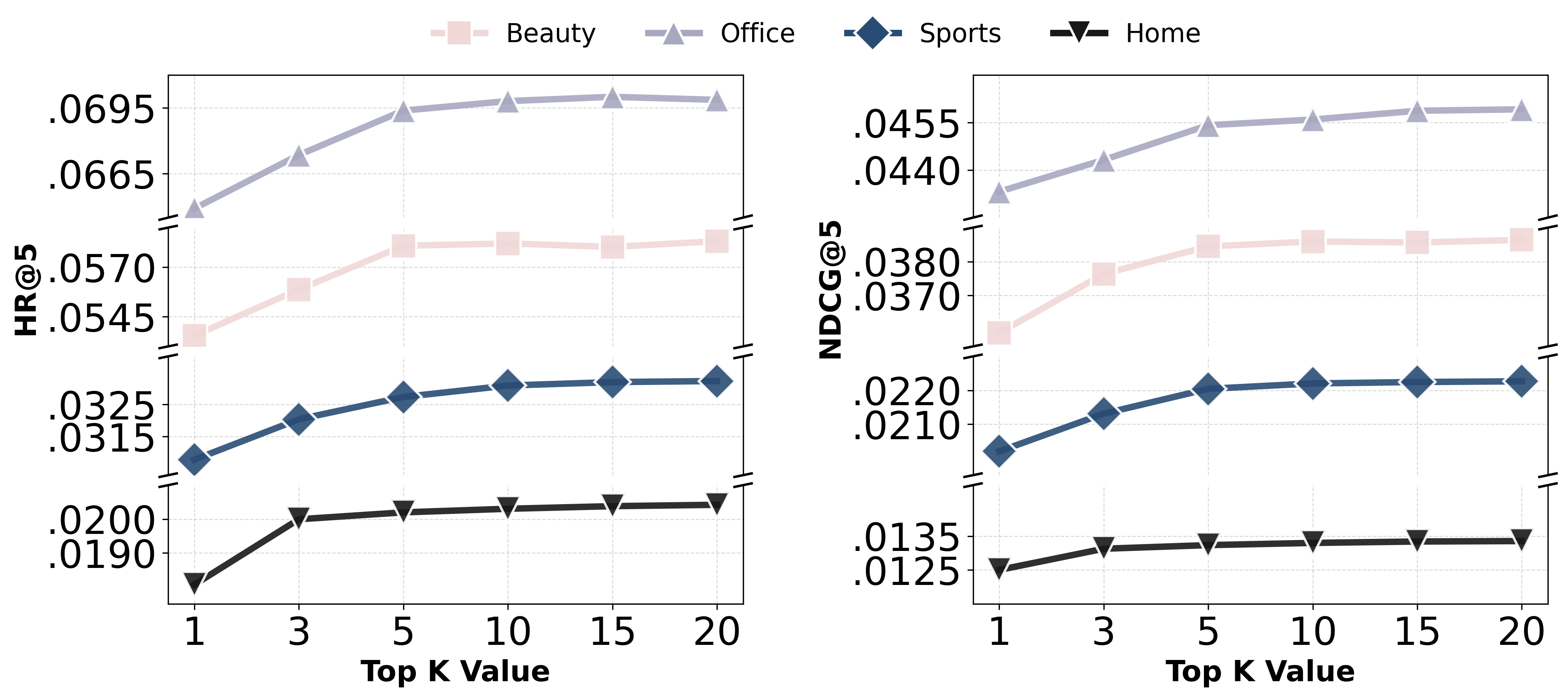
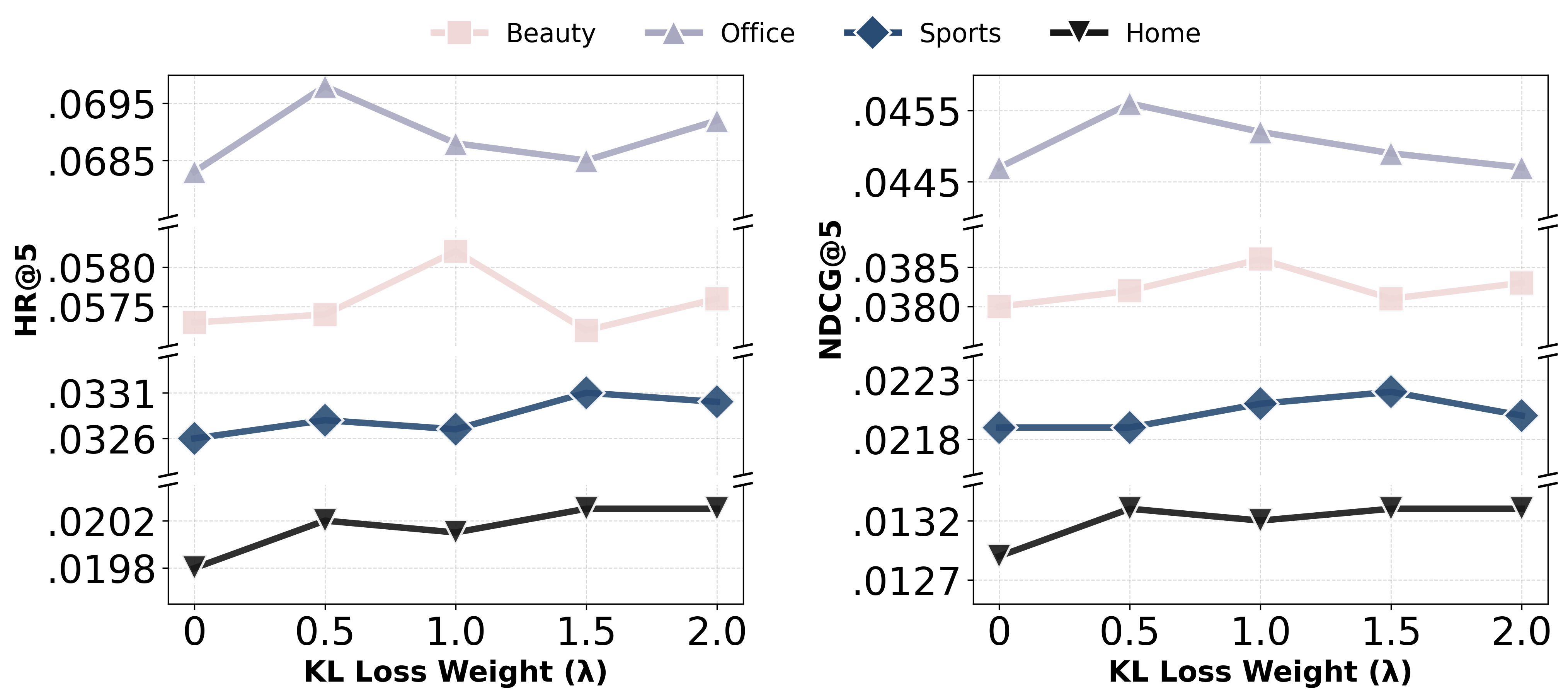
Figure 3: Impact of retrieval hyperparameters Mθ3 and KL loss weight Mθ4 on performance (HR@10, NDCG@10).
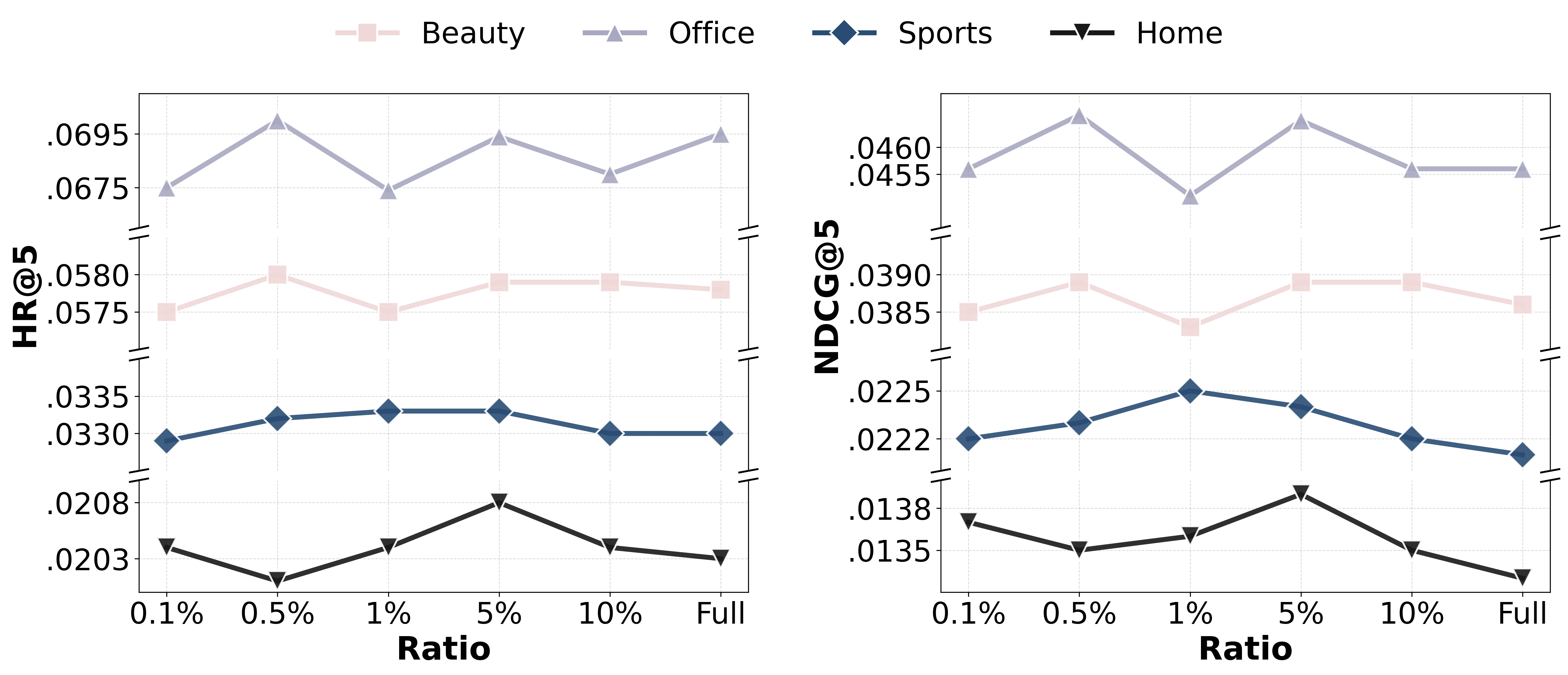
Figure 4: Effect of entropy computed over varying top-Mθ5 fractions of the ranked list on adaptive fusion quality.
Efficiency
ReAd incurs minimal overhead in both memory and latency. The test-time retrieval and fusion operations parallelize efficiently and remain suitable for real-time deployments, with negligible incremental inference cost compared to baseline SR models.
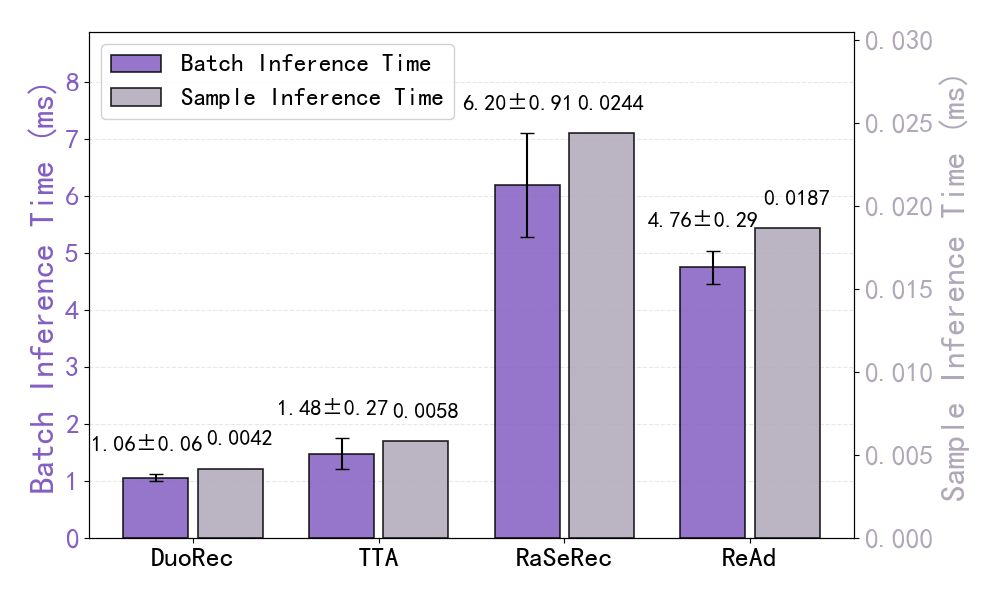
Figure 5: Inference time analysis for batch and sample-wise modes, demonstrating ReAd’s practical efficiency.
Qualitative Interpretability
A case study illustrates ReAd’s retrievals for a session exhibiting a genre shift (e.g., drama to thriller). Retrieved sequences provide not simply overlapping but also complementary collaborative transitions, contributing substantively to the refined prediction.
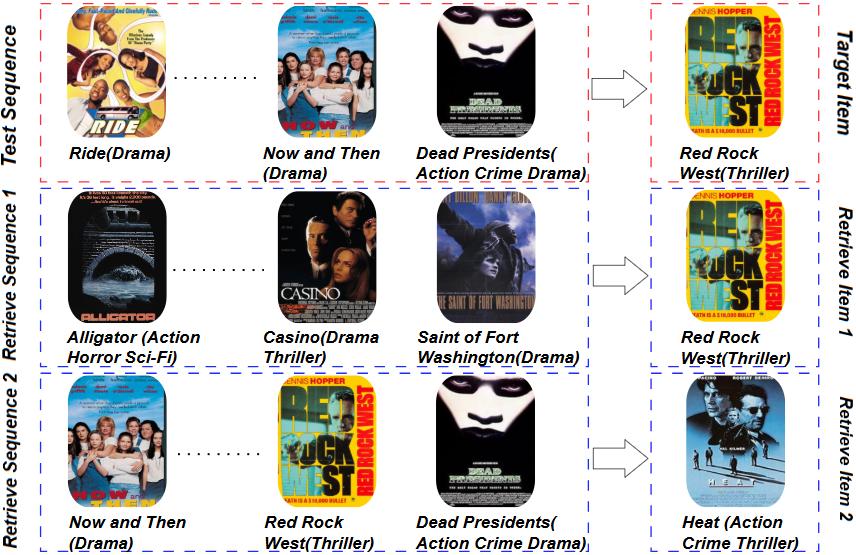
Figure 6: MovieLens case study—retrieval augments recommendation by providing sequences that reflect current and emergent user interests.
Implications and Theoretical Significance
The results of ReAd have salient implications:
- Model-agnostic test-time adaptation: The framework decouples retrieval augmentation from the underlying backbone, providing a modular improvement applicable to any SR architecture, including those based on RNNs, Transformers, or contrastive SSL paradigms.
- Mitigating distributional shift: Dynamic retrieval and adaptation explicitly address inference-time covariate shift and preference evolution, outperforming post-training fine-tuning and random augmentation.
- Augmentation without external knowledge: Unlike RAG paradigms in NLP, ReAd constructs the retrieval base from collaborative data, enabling use in recommendation domains lacking structured external corpora.
- Efficient, scalable implementation: The introduced cross-attention retrieval learning converges with negligible additional cost and is feasible for industrial deployment.
From a theoretical perspective, the dual-objective retrieval learning tightly couples representation similarity with individual predictive utility, aligning the SR adaptation objective with both collaborative and discriminative signals.
Future Directions
Open avenues include extending ReAd with continual/lifelong update of the retrieval base, integration of content and multimodal signals where available, exploration for session-based/domain-transfer recommendation, and application in online learning contexts where user feedback is rapidly assimilated.
Conclusion
ReAd presents a principled, retrieval-augmented test-time adaptation paradigm for sequential recommender systems, fusing collaborative historical signals with dynamic, confidence-aware inference. Its strong empirical performance, architectural generality, and operational efficiency establish it as a new standard for tackling preference shift in deployment. The approach informs ongoing research in adaptation for recommendation under real-world distributional dynamics, robust augmentation, and memory-based learning architectures.