MIRA: Multimodal Iterative Reasoning Agent for Image Editing
Abstract: Instruction-guided image editing offers an intuitive way for users to edit images with natural language. However, diffusion-based editing models often struggle to accurately interpret complex user instructions, especially those involving compositional relationships, contextual cues, or referring expressions, leading to edits that drift semantically or fail to reflect the intended changes. We tackle this problem by proposing MIRA (Multimodal Iterative Reasoning Agent), a lightweight, plug-and-play multimodal reasoning agent that performs editing through an iterative perception-reasoning-action loop, effectively simulating multi-turn human-model interaction processes. Instead of issuing a single prompt or static plan, MIRA predicts atomic edit instructions step by step, using visual feedback to make its decisions. Our 150K multimodal tool-use dataset, MIRA-Editing, combined with a two-stage SFT + GRPO training pipeline, enables MIRA to perform reasoning and editing over complex editing instructions. When paired with open-source image editing models such as Flux.1-Kontext, Step1X-Edit, and Qwen-Image-Edit, MIRA significantly improves both semantic consistency and perceptual quality, achieving performance comparable to or exceeding proprietary systems such as GPT-Image and Nano-Banana.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
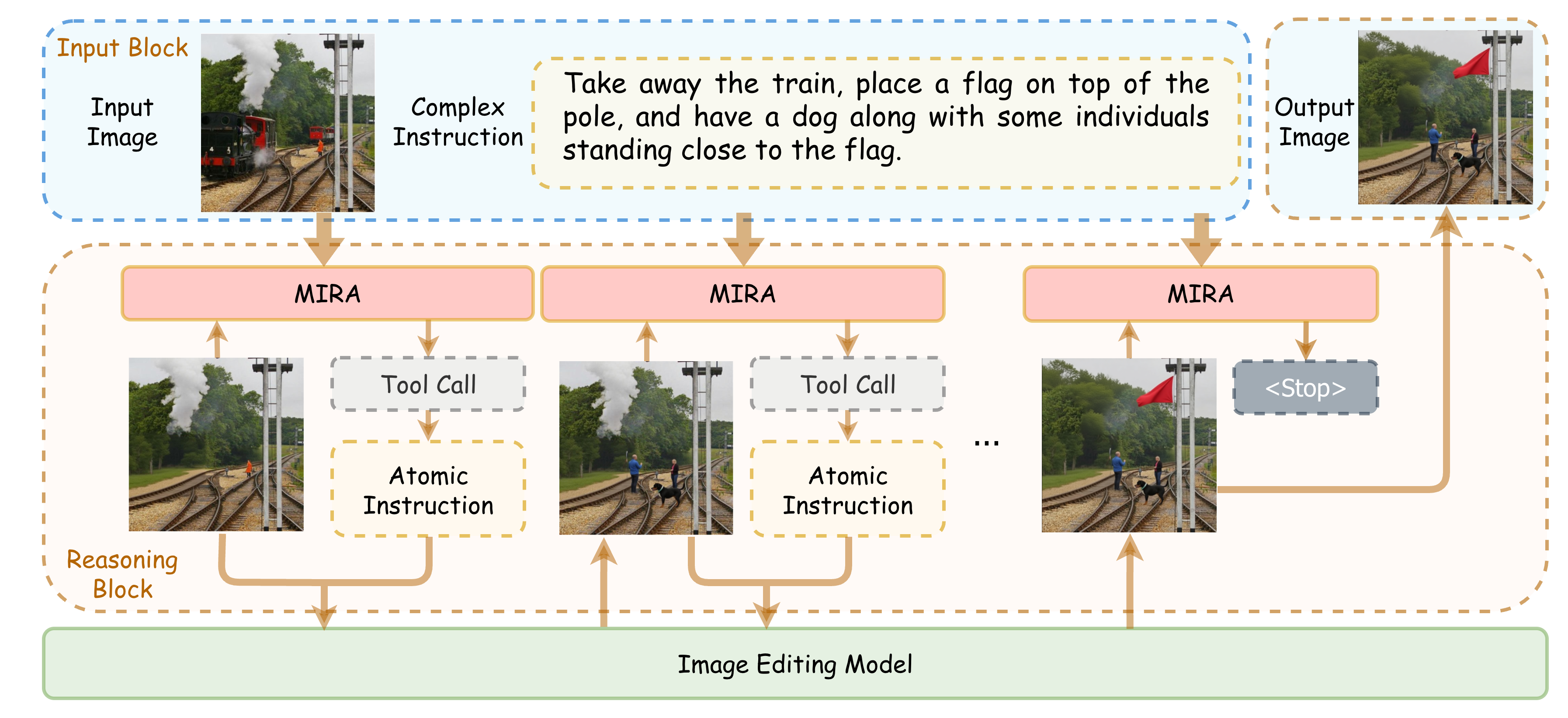
This paper introduces MIRA, a smart helper for editing images using written instructions. Instead of trying to change a picture all at once, MIRA edits step by step. After each small change, it looks at the picture again, thinks about what still needs to be done, and then decides the next small change. This “see–think–act” loop helps MIRA follow complex instructions more accurately and make better-looking edits.
Key Objectives
The paper sets out to:
- Make image editing with natural language more reliable when instructions are complex (like “make the floor wooden, turn the white stove black, and change the cabinets to brown”).
- Teach an AI to break down big requests into small, clear steps and adjust its plan based on the picture it sees after each step.
- Build a large training set so the AI can learn how to make and check edits properly.
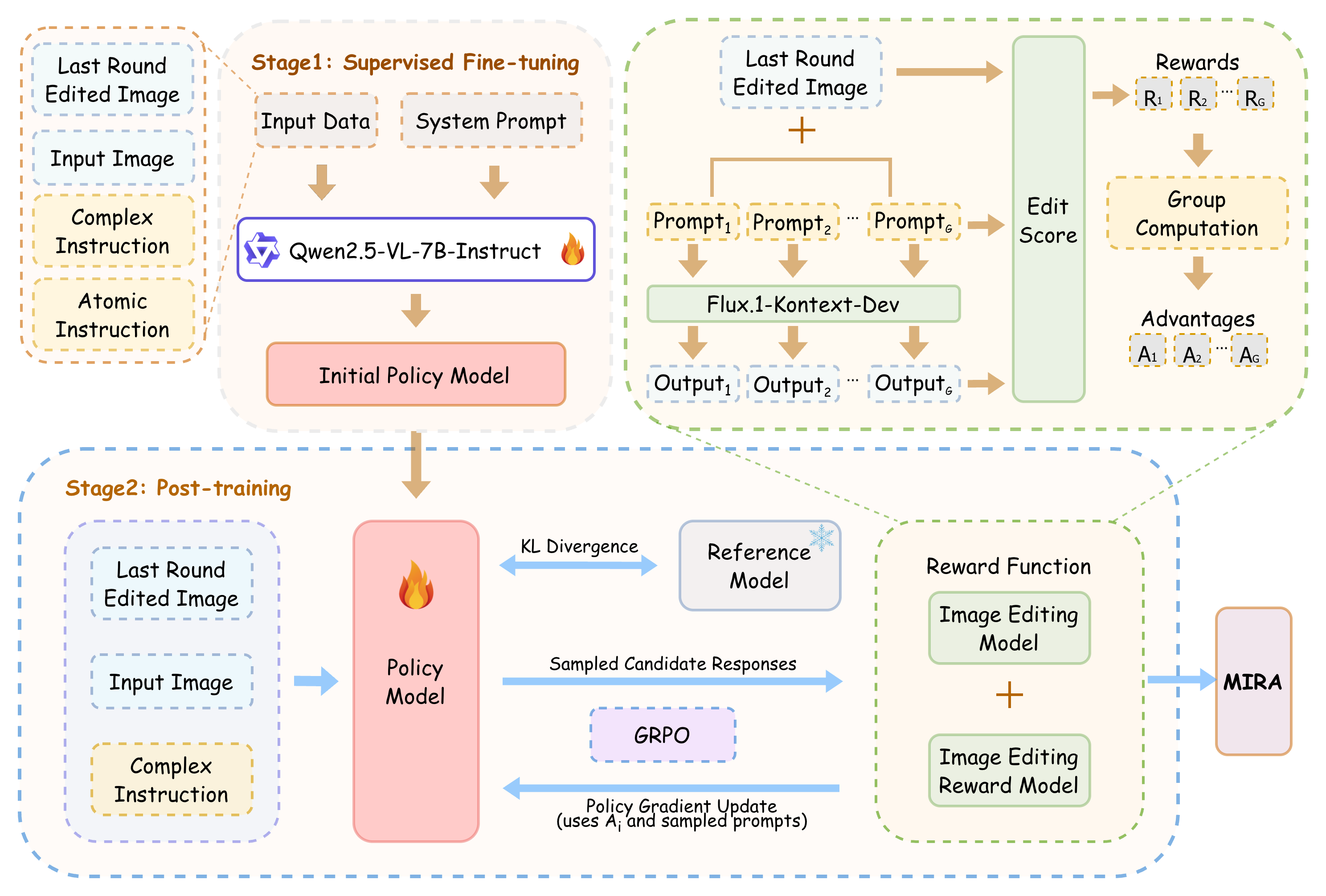
- Train the AI in two phases: first by imitation (learning from examples), then by practice with feedback (rewarded training), so it gets better at choosing the right next step.
- Work as a lightweight “plug-and-play” reasoning layer that can sit on top of popular open-source image editors and improve them without needing a complicated system.
Methods and How It Works
Think of MIRA like a careful art assistant:
- You give it a picture and a detailed instruction.
- It doesn’t try to do everything at once. Instead, it:
- Sees the current image and the instruction,
- Thinks about the difference between “what the picture looks like now” and “what the instruction wants,”
- Acts by sending a tiny, precise edit (an “atomic instruction” like “turn the stove black”),
- Then checks the updated image and repeats until it’s done.
In simple terms, MIRA follows a loop: state (the current picture) → reasoning (think) → action (make a small change) → feedback (see results). It also decides when to stop, so it doesn’t over-edit.
To make MIRA smart:
- The authors built a large training dataset (about 150,000 examples) that teaches the AI step-by-step editing. They:
- Combined multiple simple edits into one complex instruction.
- Rewrote instructions in different ways to teach the model to understand varied language.
- Generated multiple candidate edited results and kept the best one (the one that matched the instruction best).
- They trained MIRA in two stages:
- Supervised Fine-Tuning (SFT): like learning by example. The model sees “picture + instruction → small edit” pairs and learns to imitate.
- Reinforcement Learning (GRPO): like practicing with scores. The model tries several possible small edits at each step, and an automatic “reward” judges how well each edit matches the instruction and how good the image looks. The model learns to prefer edits that score higher.
A few helpful definitions in everyday language:
- Multimodal vision–LLM: an AI that understands both pictures and text.
- Diffusion-based editor: a type of image tool that changes pictures by gradually adding or removing digital “noise,” helping it reach the desired look.
- Atomic edit: a single, clear, small change (e.g., “make the cabinets brown”).
MIRA doesn’t replace image editors; it guides them. It can sit on top of open-source tools like Flux.1-Kontext, Step1X-Edit, or Qwen-Image-Edit and tell them what small change to make next.
Main Findings and Why They Matter
What the authors found:
- MIRA helps open-source image editors follow complex instructions more faithfully (“semantic consistency”) and produce better-looking pictures (“perceptual quality”).
- When combined with popular open-source editors, MIRA often matches or beats the results of proprietary systems (paid, closed tools).
- MIRA is robust to mistakes: if an edit goes a bit wrong—say, the refrigerator turns brown when it should be white—MIRA notices this in the next step and issues a corrective instruction. It checks the picture after every change and fixes issues before moving on.
- MIRA generally needs only around four steps per image, and it knows when to stop, reducing over-editing.
- Although editing step-by-step takes extra time compared to one-shot editing, the gains in accuracy and image quality make it worthwhile—especially since the whole system is open-source.
In short: breaking big tasks into small steps, with feedback after each, makes image editing smarter and more dependable.
Implications and Potential Impact
MIRA shows that an “iterate with feedback” approach can make complex image editing much better, even using free, open-source tools. This could:
- Help creative apps and photo editors understand and execute multi-part requests without confusion.
- Make professional and hobby workflows more controllable and transparent, because you can see each step and understand what the AI is doing.
- Inspire similar “see–think–act” agents for other tasks, like video editing, graphic design, or even robotics, where checking progress after each step is crucial.
- Narrow the gap between open-source and proprietary systems, making high-quality editing more accessible to everyone.
Overall, MIRA demonstrates that careful, iterative reasoning—rather than a single, static prompt—leads to clearer, more accurate, and more beautiful image edits.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, written to guide future research directions.
- Lack of human evaluations: all alignment metrics rely on VLM/LLM judges (GPT-SC, Gemini-SC, Qwen3VL-SC) and open-source proxies (EditScore, ARNIQA, TOPIQ); no controlled human preference studies or user trials quantify perceived edit faithfulness, usability, or satisfaction.
- Judge bias and metric validity: no analysis of how VLM-based scoring biases influence reported gains (e.g., favoring models trained on similar distributions), nor cross-validation against orthogonal human-centric metrics; robustness of conclusions to different judging prompts is unexamined.
- Dataset curation dependencies: MIRA-Editing’s “top-1” trajectory selection uses proprietary rankers (Gemini-2.5-Flash) and large open-source VLMs (Qwen2.5/3); the impact of these choices on dataset bias, reproducibility, and public accessibility (e.g., closed models or changing APIs) is not assessed.
- Dataset coverage and diversity: no quantitative characterization of instruction types (e.g., referring expressions, spatial relations, compositional logic, style edits, identity preservation), domain breadth (e.g., faces, indoor/outdoor, object categories), or multilingual support; generalization to non-English instructions is unstudied.
- Atomic edit taxonomy and interface: the paper assumes natural-language atomic edits but does not formalize a schema (parameters, constraints, object references, masks) that would enable standardized tool APIs, reproducibility, and cross-editor comparability.
- Localization and masking: MIRA does not integrate explicit object localization/segmentation/inpainting tools; handling edits that require precise spatial targeting (small objects, occlusions, complex layouts) without masks remains uncertain.
- Multi-tool orchestration vs. single-editor reliance: despite theoretical support for interchangeable editors, MIRA’s training and inference appear to use a single editor per run; dynamic per-step tool selection, multi-tool coordination, and conditions under which multi-tool pipelines outperform single-editor loops are unexplored.
- Cross-editor transfer: it is unclear whether a policy trained with one editor transfers to others without degradation; there is no systematic study of training-on-editor-A and deploying-on-editor-B (including edit interfaces that differ in capabilities or failure modes).
- Convergence and termination guarantees: beyond average step counts, there is no formal criterion or proof of convergence; the false-stop and over-edit rates, and their impact on final quality, are not quantified.
- Error mitigation efficacy: qualitative examples show corrective behavior, but no quantitative measurement of how often MIRA detects and repairs editor-induced errors, nor analysis of failure patterns (irrecoverable drifts, compounding artifacts).
- Iteration necessity: while iterative reasoning improves results, the paper does not compare MIRA’s multi-step loop against its own one-shot variant on the same benchmark to isolate the contribution of iteration.
- Reward design clarity and robustness: the composite reward equation in the paper is malformed/underspecified (weights, normalization, components); sensitivity analyses (e.g., λ_sc vs. λ_pq), reward hacking, and overfitting to specific metrics are not investigated.
- Credit assignment across long horizons: GRPO is applied step-wise, but how rewards propagate for instructions whose payoffs appear only after several steps is unaddressed; alternative RL algorithms or sequence-level rewards could improve long-horizon planning.
- Benchmark scale and representativeness: the main benchmark includes 500 test instructions; statistical power, category balance, and representativeness for “complex edits” across real-world use cases (e.g., product imagery, portraits, scenes) are not documented.
- Identity and content preservation: edits involving faces, brand logos, or culturally sensitive content require identity/style preservation; the paper does not evaluate identity drift or introduce safeguards.
- Safety, ethics, and provenance: no treatment of misuse risks (deepfakes, non-consensual edits), content safety filters, watermarking, or edit traceability is provided; policy and tooling for responsible deployment are absent.
- Latency and compute trade-offs: while latency is reported, there is no breakdown of cost drivers (VLM vs. editor), no exploration of batching, caching, or approximate reasoning, and no evaluation of memory footprint and scaling to higher resolutions (>1024×1024).
- Multimodal and multi-asset edits: tasks requiring external asset insertion (e.g., paste an object from another image), multi-image composition, or layout synthesis are not addressed; how MIRA handles cross-image references remains open.
- Real interactive settings: the loop simulates multi-turn interaction but does not incorporate real user feedback between steps; how human-in-the-loop guidance (approvals, corrections) affects quality and efficiency is unknown.
- Robustness to adversarial/ambiguous instructions: the system’s behavior under adversarial prompts, conflicting constraints, or underspecified references is not tested; uncertainty estimation or confidence scores for stop decisions are missing.
- Multilingual and cross-cultural generalization: all experiments appear in English; performance on multilingual instructions (including languages with different morphology or spatial expressions) is unexplored.
- Structured API outputs vs. free text: editors often benefit from parameterized commands (object ID, region, color space); mapping MIRA’s reasoning outputs to structured edit APIs and quantifying gains over free-text prompts is not studied.
- Comparison to heavy agentic pipelines: claims of efficiency over multi-tool orchestration are not paired with controlled trade-off studies (quality vs. compute vs. latency); when complex toolchains (e.g., localization + inpainting) are beneficial is not delineated.
- Failure case catalog and diagnostics: the paper lacks a taxonomy of failure modes (e.g., mislocalized edits, attribute binding errors, temporal instability across steps), diagnostic tools, and guidelines for triaging errors.
- Video and 3D editing: extension to temporal (video) or spatial (3D) editing—where iterative reasoning and state consistency are more challenging—is unaddressed; scalability of the loop to sequential frames or meshes is an open question.
- Reproducibility details: training hyperparameters, seed control, and full reward pipelines (versions of EditScore/VieScore, exact prompts, and configurations) are not fully specified to enable faithful reproduction.
- Dynamic step budgeting: the minor gains with more steps suggest diminishing returns; adaptive budgeting policies (decide-on-the-fly maximum steps) and their impact on latency/quality trade-offs are not explored.
- Editor capability detection: the agent does not model per-editor strengths/weaknesses (e.g., texture edits vs. geometry changes); learning to route or adapt instructions based on editor affordances remains an open design problem.
Practical Applications
Practical Applications of MIRA: Multimodal Iterative Reasoning Agent for Image Editing
Below are actionable, real-world applications directly derived from the paper’s findings, methods, and innovations. Each item specifies sectors, potential tools/workflows, and feasibility assumptions or dependencies.
Immediate Applications
The following applications can be deployed now, leveraging MIRA’s plug-and-play design with open-source editors, its iterative perception–reasoning–action loop, its termination controller, and the MIRA-Editing dataset plus SFT+GRPO training pipeline.
- MIRA-enhanced editing in existing open-source tools
- Description: Wrap MIRA around Flux.1-Kontext, Step1X-Edit, or Qwen-Image-Edit to improve semantic consistency and reduce artifacts for complex, multi-step edits (as demonstrated by quantitative gains across GPT-SC, Gemini-SC, Qwen3VL-SC, ARNIQA, and TOPIQ).
- Sector(s): Software, Creative industries
- Tools/workflows: MIRA SDK/API as middleware; CLI for batch edits; server-side microservice
- Assumptions/dependencies: Access to GPU/accelerators; compatible editor backends; acceptable latency (~48s per 1024×1024 image in reported setup); governance for edited content
- Chat-based consumer photo editing copilot
- Description: Add an iterative “edit assistant” to mobile/desktop photo apps that decomposes user requests (“make cabinets wooden brown, replace floor with oak, keep stove black”) into atomic steps, self-corrects, and stops when done.
- Sector(s): Consumer software, Accessibility
- Tools/workflows: App plugin; voice-to-edit interface; UI for step-by-step previews and rollback
- Assumptions/dependencies: On-device or cloud inference; guardrails to prevent deceptive deepfakes; UX for exposing intermediate steps
- E-commerce catalog retouching and variant generation
- Description: Batch colorway changes, background replacement, lighting normalization, and brand-guideline enforcement with iterative correction and reliable stopping to prevent over-editing.
- Sector(s): E-commerce, Retail, Marketing
- Tools/workflows: DAM integration; pipeline jobs producing SKU variants; brand rules encoded as editable instruction templates
- Assumptions/dependencies: High-throughput GPU queues; QA loop using EditScore or similar; legal/compliance review for generative edits
- Creative marketing asset production and A/B testing
- Description: Generate semantically faithful variations of hero images, banners, and social posts; MIRA’s atomic logs enable auditability and reproducibility for campaign approvals.
- Sector(s): Advertising, Digital marketing
- Tools/workflows: DCO (Dynamic Creative Optimization) systems; asset versioning with step logs; “semantic edit QA” gate before publishing
- Assumptions/dependencies: Content provenance practices; storage for step trajectories; integration with ad platforms’ creative pipelines
- Instruction-refinement preprocessor for image editors
- Description: Use MIRA’s single-turn instruction rewriting to clarify ambiguous requests before editing, reducing misalignment and retries.
- Sector(s): Software, Education
- Tools/workflows: Prompt “lint” service; editor-side rewrite button; API that outputs concise executable edit instructions
- Assumptions/dependencies: Stable rewrite quality for diverse domains; user approval loop to confirm intent
- Visual edit QA assistant
- Description: Automatically check whether an edited image matches the original instruction, flag inconsistencies, and propose corrective atomic actions (leveraging the agent’s discrepancy analysis).
- Sector(s): Software, Quality assurance
- Tools/workflows: EditScore-based scoring; suggestion UI; auto-correction modes with rollback
- Assumptions/dependencies: Reliable semantic consistency scoring; human-in-the-loop approvals for corrections
- Privacy redaction and de-identification workflows
- Description: Iteratively blur faces, remove license plates, redact sensitive regions, and stop when the privacy objective is met; maintain an auditable record of changes.
- Sector(s): Policy, Public sector, Compliance, Enterprise
- Tools/workflows: Redaction presets; C2PA content credentials embedding for provenance; audit logs of atomic edits
- Assumptions/dependencies: Robust detection of sensitive regions via auxiliary models; compliance with local privacy laws; clear labeling of edited content
- Post-production editing copilot for agencies and studios
- Description: Assist designers with iterative corrections on complex composites (product in-scene swaps, multi-object recolors) while minimizing drift via feedback-driven actions.
- Sector(s): Media, Design, Entertainment
- Tools/workflows: Photoshop/GIMP/Figma plugin; step history and revert; collaboration features showing per-step previews
- Assumptions/dependencies: Plugin APIs; acceptable latency in workflows; licensing compatibility with creative suites
- Brand-compliant enterprise DAM and content credentials
- Description: Enforce brand colors, typography, and background policies through semantically grounded edits; attach stepwise provenance (C2PA) for compliance and trust.
- Sector(s): Enterprise software, Compliance, Marketing
- Tools/workflows: Policy-as-instructions; DAM integrations; automated credentials/watermarks and logs
- Assumptions/dependencies: Organizational buy-in for policy encoding; content authenticity infrastructure; governance over edited media
- Academic use of MIRA-Editing dataset and training pipeline
- Description: Use the 150K step-wise trajectories to study multimodal tool-use, agentic reasoning, and RL reward modeling for image editing; reproduce SFT+GRPO results and extend reward functions.
- Sector(s): Academia, Research
- Tools/workflows: Open-source checkpoints; GRPO training scripts; benchmarking on MagicBrush/CompBench-like suites
- Assumptions/dependencies: Dataset and code availability; compute for RL post-training; ethics review for generative experiments
Long-Term Applications
These applications require further research, scaling, or engineering (e.g., efficiency improvements, multi-tool orchestration, domain-specific robustness, safety and provenance standards).
- Video editing with iterative, frame-aware reasoning
- Description: Extend the agentic loop to temporal consistency, performing atomic actions across frames (object recolor, insertion, scene cleanup) with stop decisions per segment.
- Sector(s): Media, Entertainment, Education
- Tools/workflows: Video segmentation/backbones; temporal reward models; streaming inference
- Assumptions/dependencies: Robust multi-frame consistency; compute and latency optimization; camera motion handling
- AR/3D interior and product visualization
- Description: Voice-guided iterative adjustments of colors, materials, and textures in AR/3D scenes for furniture, rooms, or industrial products; error-correcting steps simulate design iterations.
- Sector(s): Real estate, Retail, Industrial design
- Tools/workflows: 3D/AR engines; material libraries; policy encoding for brand or safety constraints; multimodal reward functions
- Assumptions/dependencies: Reliable 3D asset editing backends; spatial reasoning beyond 2D; user acceptance testing
- On-device or edge deployment via distillation and acceleration
- Description: Compress MIRA and editor backends for mobile/offline scenarios with acceptable latency and energy, enabling privacy-preserving local edits.
- Sector(s): Consumer software, Edge computing
- Tools/workflows: Model distillation/quantization; low-latency editors; caching and incremental inference
- Assumptions/dependencies: Hardware capabilities; quality retention under compression; robust termination under resource constraints
- Multi-tool orchestration for fine-grained control
- Description: Integrate specialized tools (localization/segmentation/inpainting/composition/global transforms) under MIRA’s reasoning loop to boost precision in tough cases.
- Sector(s): Software, Robotics (perception tooling), Creative suites
- Tools/workflows: Tool registry; plan-and-act controllers; tool confidence weighting; fallback strategies
- Assumptions/dependencies: Tool APIs and interoperability; cost management for tool calls; evaluation frameworks for multi-tool trajectories
- Safety- and policy-aware editing with guardrails
- Description: Encode editorial policies (e.g., anti-deceptive manipulation, age-appropriate editing, sensitive content handling) and integrate automatic watermarking/provenance (C2PA) by default.
- Sector(s): Policy, Public sector, Platforms
- Tools/workflows: Safety classifiers; rule-based filters; credentials embedding; reviewer workflows
- Assumptions/dependencies: Reliable detection of policy violations; standards adoption; handling jurisdictional differences
- Domain-specific medical and scientific image workflows (non-diagnostic)
- Description: Use iterative edits for anonymization, educational visualizations, and dataset curation (e.g., masking identifiers), with strict provenance and disclaimers to avoid diagnostic misuse.
- Sector(s): Healthcare (education/compliance), Scientific publishing
- Tools/workflows: Redaction presets; provenance logs; instruction templates for common tasks (de-identification)
- Assumptions/dependencies: Clear non-diagnostic scope; compliance processes; domain review boards
- Large-scale personalized advertising pipelines
- Description: Programmatically tailor imagery per audience segment while maintaining brand rules; MIRA’s stop controller and error mitigation reduce QA overhead at scale.
- Sector(s): Advertising, MarTech, Retail
- Tools/workflows: Batch orchestration; audience rule engines; continuous preference learning in reward models
- Assumptions/dependencies: High-throughput infrastructure; brand-safe guardrails; robust preference modeling
- Synthetic data generation for CV/ML with provenance
- Description: Create controllable, step-logged image variants to augment training datasets (e.g., object appearance/placement changes) and study model robustness.
- Sector(s): AI/ML, Autonomous systems (perception)
- Tools/workflows: Scenario templating; label preservation checks; edit trajectory exports for audit
- Assumptions/dependencies: Label integrity under edits; domain generalization; licensing of source assets
- Accessibility-first voice/image assistants for creative learning
- Description: Teach compositional editing via narrations and iterative feedback, helping novices understand visual transformations and stop when goals are met.
- Sector(s): Education, Accessibility
- Tools/workflows: Curriculum templates; step visualizations; assistive UI/UX
- Assumptions/dependencies: Inclusive design; multilingual support; pedagogy validation
- Standardized edit provenance and audit ecosystems
- Description: Industry-wide adoption of stepwise edit logs and credentials (e.g., C2PA) to increase transparency in media supply chains and platform trust signals.
- Sector(s): Policy, Platforms, Media
- Tools/workflows: Metadata standards; validator services; UI for visualizing edit histories
- Assumptions/dependencies: Cross-industry agreement; regulation or platform incentives; consumer education
Notes on Feasibility and Dependencies
- Compute and latency: Reported end-to-end latency (~48s per 1024×1024 image with MIRA 7B + Flux.1-Kontext, ~4.1 steps) is practical for batch/desktop workflows; mobile/on-device use likely requires distillation and acceleration.
- Backends: Performance depends on the quality and stability of the paired editor (Flux.1-Kontext, Step1X-Edit, Qwen-Image-Edit). Swapping backends is supported but can affect visual fidelity and speed.
- Reward models: RL improvements hinge on reliable semantic consistency and perceptual quality scoring (e.g., EditScore); domain-specific rewards may be needed for specialized sectors (medical, industrial).
- Safety/provenance: Transparent step logs and content credentials (C2PA) are recommended to mitigate misuse (e.g., deceptive edits), support compliance, and build trust.
- Data/domain coverage: MIRA-Editing (150K) provides strong supervision for complex edits, but out-of-distribution domains (e.g., scientific imagery, ultra-high resolution) may require fine-tuning and curated data.
- Human-in-the-loop: For regulated or high-stakes contexts, integrate approval steps, policy filters, and rollback mechanisms to ensure responsible deployment.
Glossary
- Agentic frameworks: Architectures where a model actively plans and coordinates steps and tools to accomplish complex tasks. "These agentic frameworks, characterized by programmatic decomposition, iterative reasoning, and multi-tool collaboration, achieve notable improvements on compositional, multi-step, and context-dependent editing tasks"
- Agentic loop: A closed cycle of observe–reason–act–feedback used to iteratively refine decisions. "This cycle defines a simple yet effective agentic loop: state → multimodal reasoning → action → environment feedback"
- ARNIQA: An image quality assessment metric that models human preference for evaluating visual quality. "ARNIQA and TOPIQ assess perceptual quality via human preference modeling and traditional IQA metrics"
- Atomic edit instruction: A minimal, self-contained edit operation predicted and executed step-by-step. "Instead of issuing a single prompt or static plan, MIRA predicts atomic edit instructions step by step, using visual feedback to make its decisions"
- Backbone (image-editing backbone): The primary model architecture that performs core image-editing computations. "a novel composite reward model that couples an image-editing backbone with an image-editing reward model"
- Closed-loop: A control paradigm where outputs are fed back into the system to guide subsequent actions. "At inference time, MIRA performs instruction-guided editing in a strictly iterative and closed-loop manner"
- Composite reward model: A combined scoring mechanism that integrates multiple evaluators to guide learning. "we incorporate a novel composite reward model that couples an image-editing backbone with an image-editing reward model to assess the quality and fidelity of edit instructions"
- Compositional reasoning: The ability to understand and manipulate instructions that involve multiple interrelated components. "these architectures exhibit strong compositional reasoning and interpretability"
- Compositing: Combining visual elements (objects, edits) into a coherent image. "as well as precise object-level manipulation and compositing"
- Diffusion-based editing models: Image editors built on diffusion processes that iteratively refine noise into images. "diffusion-based editing models often struggle to accurately interpret complex user instructions—especially those involving compositional relationships, contextual cues, or referring expressions"
- EditScore: An open-source metric suite scoring semantic consistency, perceptual quality, and overall alignment of edits. "EditScore-SC, EditScore-PQ, and EditScore-OA provide open-source semantic consistency, perceptual quality, and overall alignment scores"
- Edited trajectory: The sequence of intermediate images and actions produced during multi-step editing. "producing x candidate edited trajectories"
- Global transformation: Large-scale image changes affecting the whole image (e.g., color tone, geometry). "such as localization, inpainting, editing, composition, and global transformation"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm optimizing policies via relative group advantages. "we apply Group Relative Policy Optimization (GRPO) in a step-wise manner"
- Hierarchical instruction aggregation: Combining multiple atomic edits into a structured, complex instruction. "generated through hierarchical instruction aggregation, semantic rewriting, and ranking-based filtering"
- Image Quality Assessment (IQA): The quantitative evaluation of visual quality using established metrics. "traditional IQA metrics"
- Inpainting: Filling in or reconstructing missing or masked regions in an image. "a suite of specialized expert models such as localization, inpainting, editing, composition, and global transformation"
- Iterative perception–reasoning–action loop: A repeated cycle where the agent observes, reasons, acts, and updates based on feedback. "MIRA engages in an iterative perception–reasoning–action loop"
- Latent diffusion: Diffusion modeling performed in a compressed latent space for efficiency and quality. "combining high-resolution latent diffusion frameworks with robust controllability"
- Localization: Identifying and isolating specific regions or objects in an image for targeted editing. "a suite of specialized expert models such as localization, inpainting, editing, composition, and global transformation"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities, such as text and images. "Multimodal LLMs (MLLMs) have recently emerged as powerful engines for reasoning-driven image generation and editing"
- Multi-tool collaboration: Coordinated use of multiple specialized tools within an agentic workflow. "programmatic decomposition, iterative reasoning, and multi-tool collaboration"
- Open-loop: A planning approach that does not reconsider outputs during execution, lacking feedback integration. "Unlike other agentic frameworks that generate a static and open-loop plan, MIRA performs stateful and closed-loop reasoning"
- Orchestration: The coordinated scheduling and management of tools and steps by a reasoning agent. "recent research has moved beyond purely text-to-edit systems and explored embedding reasoning and orchestration via vision–LLMs"
- Perceptual quality: Human-perceived visual fidelity and attractiveness of an edited image. "significantly improves both semantic consistency and perceptual quality"
- Plug-and-play: Easily integrable components that work with existing systems without heavy modification. "A lightweight, agentic, and plug-and-play vision–LLM that can be seamlessly paired with existing open-source image editing backbones"
- Programmatic decomposition: Breaking complex tasks into structured, executable sub-programs or steps. "These agentic frameworks, characterized by programmatic decomposition, iterative reasoning, and multi-tool collaboration"
- Ranking-based filtering: Selecting top-quality candidates by comparing and ordering them using scoring models. "generated through hierarchical instruction aggregation, semantic rewriting, and ranking-based filtering"
- Receding-horizon approach: Planning only the next step(s) based on current state and goals, then replanning iteratively. "This receding-horizon approach naturally yields a sequence of semantically atomic operations"
- Referring expressions: Linguistic phrases that point to specific objects or regions in an image. "compositional relationships, contextual cues, or referring expressions"
- Reinforcement learning post-training: RL applied after supervised training to refine behavior via rewards. "trained through supervised fine-tuning (SFT) followed by reinforcement learning post-training"
- Reward-driven optimization: Improving a model by maximizing reward signals tied to task performance. "to improve semantic consistency and perceptual quality through reward-driven optimization"
- Reward model: A model that scores outputs to provide feedback signals for learning. "the quality of the edit is assessed by a fixed reward model, such as EditScore"
- Semantic consistency: How well the edited image matches the meaning of the instruction. "MIRA significantly improves both semantic consistency and perceptual quality"
- Semantic Consistency Ranking: A specific step that orders candidates by how well they match the instruction’s meaning. "Semantic Consistency Ranking."
- Semantic rewriting: Rephrasing instructions while preserving their meaning to enhance diversity and clarity. "generated through hierarchical instruction aggregation, semantic rewriting, and ranking-based filtering"
- Supervised Fine-Tuning (SFT): Further training a model on labeled data to specialize it for a task. "A two-stage training pipeline combining SFT and GRPO"
- Termination controller: A component that decides whether to continue editing or stop. "After each step, a lightweight termination controller determines whether the process should continue"
- Termination mechanism: The overall strategy ensuring the agent stops when goals are met. "Reliability of the Termination Mechanism"
- Tool-use dataset: A dataset designed to teach agents how to select and use external tools. "Our 150K multimodal tool-use dataset, MIRA-Editing"
- TOPIQ: An image quality assessment metric for evaluating perceptual fidelity. "ARNIQA and TOPIQ assess perceptual quality via human preference modeling and traditional IQA metrics"
- Vision–LLMs (VLM): Models that jointly process visual and textual inputs for reasoning and generation. "a vision-LLM (VLM) observes the original image, the user instruction, and the intermediate editing state"
- VieScore: A protocol and prompt-based evaluation method for scoring semantic alignment. "we evaluate all x candidates using VieScore"
Collections
Sign up for free to add this paper to one or more collections.